Distributed Transactions between RabbitMQ and MS SQL
To implement asynchronous communication between the two systems, it is very beneficial to use message queues. Even if one of the systems lies, the other does not notice it and calmly continues to send messages to it, which will be processed when the second system is lifted. You can use the MS SQL table as a message queue, but this is not a particularly scalable solution.
However, as soon as we have a separate system for storing the message queue (we use RabbitMQ), problems with transactionality immediately arise. For example, if we want to save a mark in the database that we sent a message to Rabbit, it is not so simple to guarantee that the mark was saved only if the message was sent successfully. Read about how we dealt with this problem under the cat.
In some scenarios, you can simply send messages to RabbitMQ after the SQL transaction is completed. For example, if we need to send an email with a password during registration and there is a “resend email” button on the page that appears after registration, then we can quite afford to do without any transactionality and, in case of an error in sending a message, simply display a notification to the user .
You can send a message right before committing an SQL transaction. In this case, we can roll back the SQL transaction if the message sending fails, but there is a possibility that after successful sending the message the SQL transaction commit will fall. But if a situation is acceptable for you when rare messages will be delivered to the recipient system, but the sending system will forget about it, I would recommend using this method, since it is very simple to implement.
In scenarios when a fallen transaction is necessarily repeated, you can not be afraid that the sending system will not have a record of sending (and moreover, you can send a message at any time of the transaction, and not just before the commit). However, it is necessary to make the message processing operation idempotent so that the same message from the point of view of the sending system is not processed twice in the receiving system.
For example, we need to send an email to the consumer and put a note about it in the database. Consumer data is stored in the CRM system. The CRM system communicates with the email gateway through a queue in RabbitMQ. Sending a message is performed by a task that has a unique identifier and a list of consumers to whom the message should be sent. If the processing of sending a letter to the consumer falls (for example, by SQL timeout), then after a while the task will again try to send the message. In this scenario, we can send a message to RabbitMQ before the transaction is completed, but when processing the message in the email gateway, we must save the unique task identifier and consumer number in the list. If there is already a message in the email gateway database with this task identifier and consumer number, then we will not send it again.
In order for the email gateway to abstract away from exactly how CRM sends messages, CRM should not transmit the task identifier and consumer number in the list, but the idempotency key - a unique value generated on the basis of this data. With other methods of sending email, the idempotency key will be generated differently. With this approach, the email gateway does not need to know anything about how messages can be sent to it - the main thing is that the sender sends a key that uniquely identifies the message.
Not in all cases it can be guaranteed that in the event of a SQL transaction crash, it will be repeated after some time. Also, there is not always data on the basis of which a unique idempotency key can be generated. And it is advisable to always do the message processing operation from the queue idempotent, since even in the absence of duplicate messages, one message can be processed several times if the call to the Ack RabbitMQ method drops. To solve the problem in the general case, we need something like a distributed transaction between RabbitMQ and MS SQL and an automatically generated idempotency key. Both of these tasks can be solved as follows:
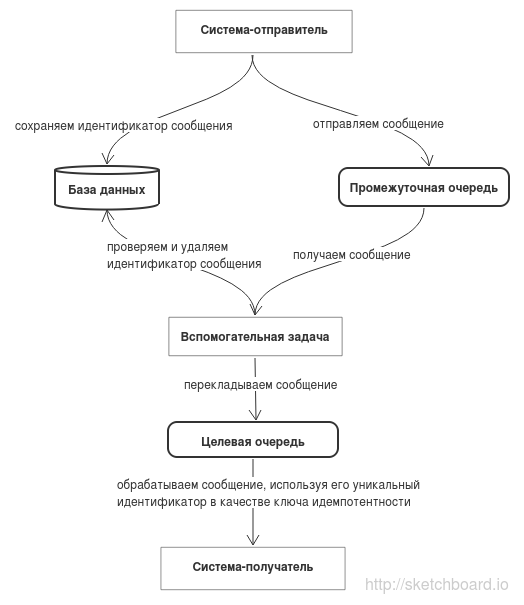
With this approach, it is guaranteed that information about the sent message is stored in the sending system. If a record with a unique identifier is created in a message sending transaction, then you can use it and do without an auxiliary table.
The question may arise here: “And what is better than using a plate in the database as a queue? Anyway, you have to do auxiliary queries to the database. ” The fact is that if you use the table in the database as a queue, then for receiving the last raw message, queries like “SELECT TOP 1 * FROM Messages WHERE Status = 'New'” will be executed. If we want to process messages in several threads, then in order to guarantee that one message will not be processed by two different threads, we will have to use a Serializable transaction to receive the last message and change its status. When using a Serializable transaction, a request to receive the last unprocessed message will block all records with the 'New' status and no one will be able to add new messages,
But in such a transaction, deadlock will constantly occur, since two threads will be able to read the last unprocessed message at the same time, imposing a shared lock, and then, when trying to update the status of the message, they will not be able to raise this lock level to exclusive, and one of the transactions will be rejected. Therefore, when reading a message, you need to impose an update lock. As a result, the queue will become a bottleneck, since only one thread can get access to it (both for writing and reading) at a time.
If we use the approach described above, then all queries to the auxiliary table (insert, search and delete) are performed using the well-known unique key and block only one record in the database. Therefore, with multi-threaded processing of messages, there is no bottleneck in which several threads will wait until the lock is released to add or receive a message.
However, as soon as we have a separate system for storing the message queue (we use RabbitMQ), problems with transactionality immediately arise. For example, if we want to save a mark in the database that we sent a message to Rabbit, it is not so simple to guarantee that the mark was saved only if the message was sent successfully. Read about how we dealt with this problem under the cat.
In some scenarios, you can simply send messages to RabbitMQ after the SQL transaction is completed. For example, if we need to send an email with a password during registration and there is a “resend email” button on the page that appears after registration, then we can quite afford to do without any transactionality and, in case of an error in sending a message, simply display a notification to the user .
You can send a message right before committing an SQL transaction. In this case, we can roll back the SQL transaction if the message sending fails, but there is a possibility that after successful sending the message the SQL transaction commit will fall. But if a situation is acceptable for you when rare messages will be delivered to the recipient system, but the sending system will forget about it, I would recommend using this method, since it is very simple to implement.
In scenarios when a fallen transaction is necessarily repeated, you can not be afraid that the sending system will not have a record of sending (and moreover, you can send a message at any time of the transaction, and not just before the commit). However, it is necessary to make the message processing operation idempotent so that the same message from the point of view of the sending system is not processed twice in the receiving system.
For example, we need to send an email to the consumer and put a note about it in the database. Consumer data is stored in the CRM system. The CRM system communicates with the email gateway through a queue in RabbitMQ. Sending a message is performed by a task that has a unique identifier and a list of consumers to whom the message should be sent. If the processing of sending a letter to the consumer falls (for example, by SQL timeout), then after a while the task will again try to send the message. In this scenario, we can send a message to RabbitMQ before the transaction is completed, but when processing the message in the email gateway, we must save the unique task identifier and consumer number in the list. If there is already a message in the email gateway database with this task identifier and consumer number, then we will not send it again.
In order for the email gateway to abstract away from exactly how CRM sends messages, CRM should not transmit the task identifier and consumer number in the list, but the idempotency key - a unique value generated on the basis of this data. With other methods of sending email, the idempotency key will be generated differently. With this approach, the email gateway does not need to know anything about how messages can be sent to it - the main thing is that the sender sends a key that uniquely identifies the message.
Not in all cases it can be guaranteed that in the event of a SQL transaction crash, it will be repeated after some time. Also, there is not always data on the basis of which a unique idempotency key can be generated. And it is advisable to always do the message processing operation from the queue idempotent, since even in the absence of duplicate messages, one message can be processed several times if the call to the Ack RabbitMQ method drops. To solve the problem in the general case, we need something like a distributed transaction between RabbitMQ and MS SQL and an automatically generated idempotency key. Both of these tasks can be solved as follows:
- As part of the SQL transaction, a unique message identifier is stored in a special table in the database.
- After executing an INSERT query, but before the SQL transaction is completed, the message is saved in an intermediate queue. In this message, among other things, a unique identifier is transmitted, which was stored in the database.
- A separate task processes the intermediate queue and verifies that the message has a unique identifier in the database.
- If there is, the message is transferred to the queue that the recipient system is already processing. In order not to store old identifiers in the auxiliary table, after the message has been moved, its identifier is deleted from the database (even if deleting the identifier falls, this will not affect the system’s performance - it will simply leave an extra record in the database).
- If the transaction was not completed at the time of the request to write to the database with a unique identifier, the request will wait for this transaction to complete, and only after that will return the record. That is, no additional logic is needed to wait for the completion of the transaction.
- If a unique identifier is not in the database, this means that the transaction was rejected and the message is thrown.
- The unique identifier of the message is used in the recipient system as the idempotency key.
With this approach, it is guaranteed that information about the sent message is stored in the sending system. If a record with a unique identifier is created in a message sending transaction, then you can use it and do without an auxiliary table.
The question may arise here: “And what is better than using a plate in the database as a queue? Anyway, you have to do auxiliary queries to the database. ” The fact is that if you use the table in the database as a queue, then for receiving the last raw message, queries like “SELECT TOP 1 * FROM Messages WHERE Status = 'New'” will be executed. If we want to process messages in several threads, then in order to guarantee that one message will not be processed by two different threads, we will have to use a Serializable transaction to receive the last message and change its status. When using a Serializable transaction, a request to receive the last unprocessed message will block all records with the 'New' status and no one will be able to add new messages,
But in such a transaction, deadlock will constantly occur, since two threads will be able to read the last unprocessed message at the same time, imposing a shared lock, and then, when trying to update the status of the message, they will not be able to raise this lock level to exclusive, and one of the transactions will be rejected. Therefore, when reading a message, you need to impose an update lock. As a result, the queue will become a bottleneck, since only one thread can get access to it (both for writing and reading) at a time.
If we use the approach described above, then all queries to the auxiliary table (insert, search and delete) are performed using the well-known unique key and block only one record in the database. Therefore, with multi-threaded processing of messages, there is no bottleneck in which several threads will wait until the lock is released to add or receive a message.