This Is Not Forget - Oracle Database In-Memory
The volume of databases and the complexity of queries to them have always grown faster than the speed of their processing. Therefore, the best minds of mankind have for many years been thinking about what will happen when there is so much RAM that it will be possible to take the entire database and put it into the RAM cache.
In recent years, a logical moment for this, it would seem, has come. The cost of RAM fell, fell, and fell completely. At the beginning of the century, it seemed that 256 MB of memory for the server was normal, and even a lot. Today, we won’t surprise you with the 256 GB RAM option on an entry-level server, and with industrial servers it’s completely communism, any noble don can get at least a terabyte of RAM on the server if he wants.
But this is not only the case - new data indexing technologies have appeared, new data compression technologies - OLTP compression, unstructured data compression
(LOB Compression). Oracle Database 11g, for example, introduced Result Cache technology, which allows you to cache not just table rows or indexes, but also the results of queries and subqueries themselves.
That is, on the one hand, it is finally possible to use RAM for its intended purpose, but on the other hand, it is not so simple. The larger the cache, the greater the overhead for maintaining it, including processor time. You put more memory, increase the cache size, and the system runs slower, and this, in general, is logical, because the memory management algorithms developed by our great-grandfathers in the Early Middle Ages are simply not suitable for the Renaissance, and that’s all. What to do?
And here is what. Let's recall that, in fact, there are two categories of databases: lowercase databases, which both in the buffer cache in RAM and on disk store information in the lower case - Oracle Database, Microsoft SQL Server, IBM DB / 2 , MySQL, etc .; and column DBMS, in which information is stored in columns, and which, unfortunately, are not widely used in the industry. Lowercase databases handle OLTP operations well, but analytics are more suitable for processing, you will laugh, columned databases - but DML operations are a problem for them, well, you understand why. Industry, as you know, has taken the path of lowercase databases, onto which analytical possibilities are hung in the form of a compromise.
And so, Oracle Database In-Memory technology appeared, in which the advantages of both approaches are finally combined.
It turns out fantastic. Transaction processing is accelerated twice, insertion of rows occurs 3-4 times faster, queries for analytics are executed in real time, almost instantly! Marketers say that analytics has become a hundred times faster, but they are modest not to scare the market, the real results are much more impressive.
Now let's figure out how and in what it works.
So, the technology appeared in version Oracle Database 12.1.0.2, and its meaning is that next to our usual buffer cache, which stores table rows and index blocks, there is a new cache, more precisely, a new shared area for data in RAM, in which data from tables is stored in column format! You got it, huh? Both a row and column format of storage in memory for the same data and tables! Moreover, the data is simultaneously active and transactionally consistent. All changes, as usual, are first made in the regular buffer cache, after which they are reflected in the column cache, or, as our English-speaking friends call it, a “columnar” cache.
A few important details. Firstly, only tables are reflected in the columnar cache, that is, indexes are not cached - this is the first. Secondly, technology does not do unnecessary work. If the data is read but not changed, then there is no need to store them in the usual, that is, in the line buffer cache. But if the data changes, then they must be stored in both caches, buffer and column. Well, and accordingly, analytics works faster because it is more efficient for it precisely the column representation of information. This is the second. And thirdly, once again, to make it clear. The column cache does not store data blocks from disk. In blocks on the disk, information is stored line by line. The information is stored in a columnar cache in columns, in its own representation, in the so-called In-Memory “compress units”. This is the third.
We realized that analytics works hundreds of times faster, because the column representation is more efficient for it - and, in fact, why?
In a regular buffer cache, information is stored line by line. Here is an example - you need to extract column No. 4 from a four-column table. To do this, you will have to completely scan this entire plate in RAM:
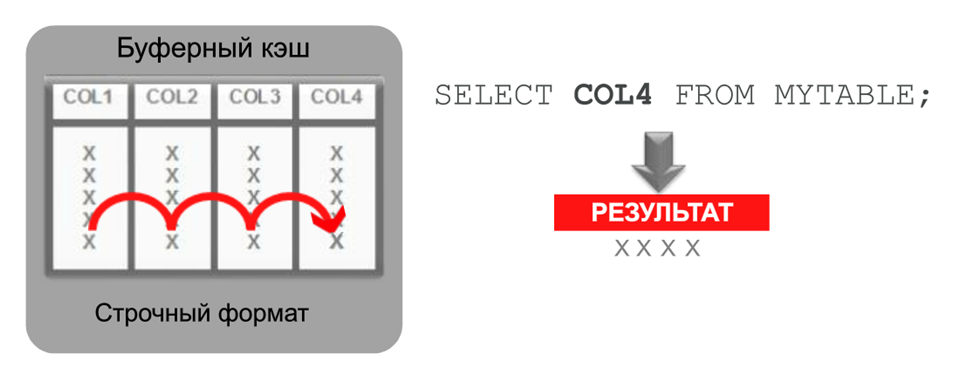
And what happens if the same table is stored in column format? The entire fourth column of our plate is in one extent, i.e. in one block of memory. We can immediately select it, immediately read it and return it to the application. The costs of scanning, sending these data to the processor are reduced, and processor load is reduced. Everything works much faster.
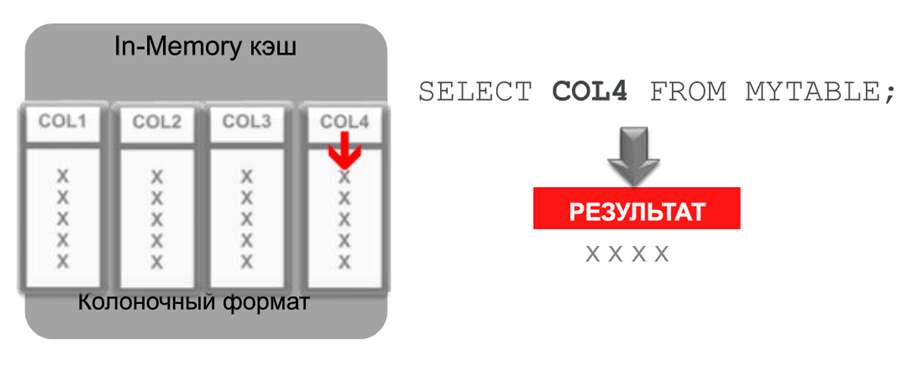
Such scanning operations are very characteristic for ERP applications, for data warehouses in analytical systems. Agree, the right thing for the progress of mankind.
Technically, to run this, you need to enable caching for the desired columns in the table. A special extension of the syntax of the ALTER TABLE command is intended for this:
This is done once, the information is recorded in the Oracle DBMS system dictionary, after which it is automatically used by the database in the process of its work. In the above example, service columns are not included in reports, they are needed only for internal audit of the application, and therefore we do not cache them.
You can specify caching for all columns for a materialized view:
SQL> ALTER MATERIALIZED VIEW cities_mv INMEMORY
Materialized view altered.
You can enable caching at the entire tablespace level:
And you can flexibly cache tables by columns at the section level to align the caching strategy with business rules:
For example, we have historical data, and they are partitioned by date. When y closes a period of, say, an operational day, the data in this section of the table no longer changes, and analytics can begin to work on them. For this, caching is needed for sections of the table for which the period is closed. And for data that is undergoing intensive changes and deletions, there is no need to enable caching so far.
What happens when we turn on caching and the information is written to the Oracle DBMS dictionary? The magic happens - the SQL optimizer rebuilds the query plan. For the first time, when the request comes from the application, at the stage of the so-called hard parsing (hard parse), a query execution plan is generated.

In this example, the total number of lines in the plate of the CITIES city directory is calculated. The optimizer sees that it is profitable to perform a query on a column view, and performs a TABLE ACCESS INMEMORY FULL scan. This is completely transparent for the application, no rewriting or modification of the application is required!
The Oracle database itself uses a number of interesting optimization techniques:
1. Each processor core scans its own column. In this case, fast vector SIMD instructions are used, i.e. special processor commands that use not a scalar value as arguments, but a vector of values. This provides a scan of billions of lines per second.
2. We do not just scan data. It scans and joins data from several tables. On a column view, this is much more efficient than regular joins. These joins run an average of 10 times faster .
3. In the process of query execution, In-Memory Aggregation technology is used: a dynamic object is created in the memory - an interim report. The object is filled during table scanning and allows you to speed up the query. As a result, reports are built 20 times faster without analytic cubes created in advance.
4. In order not to clutter up the RAM, column compression in memory is used. There are six options:
• NO MEMCOPRESS - without compression
• MEMCOMPRESS FOR DML - optimized for DML operations
• MEMCOMPRESS FOR QUERY LOW - the optimal option, which is used by default
• MEMCOMPRESS FOR QUERY HIGH - optimized for query execution speed and to save memory
• MEMCOMPRESS FOR CAPACITY LIGH - optimized for query speed
• MEMCOMPRESS FOR CAPACITY LOW - optimized for memory saving
For example:
In this example, the columns in which data is often repeated are selected for compression; unique columns are not compressed.
A new attribute of the INMEMORY segment has appeared in the system table of the USER_TABLES dictionary. The INMEMORY column also appeared in the * _TAB_PARTITIONS system tables. To find out what and in what volume is in the cache, you need to use the special system representation V $ IM_SEGMENTS:
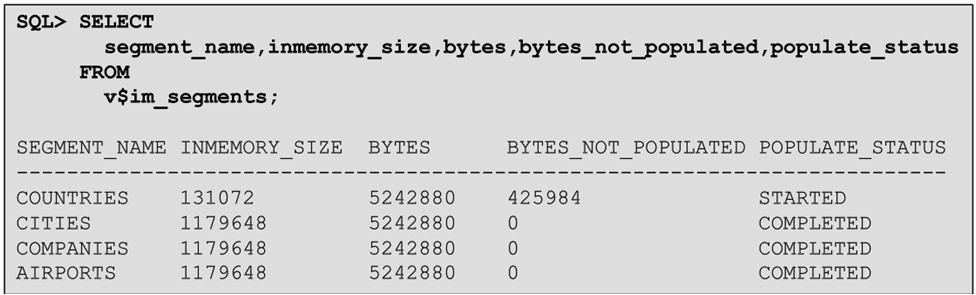
In this example, we see that there are four tables in the cache, with each table on the disk occupying approximately 5 MB each, and in memory, due to compression, from 100 KB to 1 MB. The POPULATE_STATUS column indicates the status of the information. We see that the CITIES, COMPANIES, and AIRPORTS tables are already fully loaded into the In-Memory cache, and COUNTRIES are not yet fully loaded, 400 KB remains to be loaded. That is, right now, this table is transposed into the format in columns and loaded into the cache.
From a technical point of view, reading into memory from disk can occur in two ways:
• When you first access the data. This is the default feature.
• Automatically after starting the database instance. This feature is enabled by setting the attribute of the PRIORITY segment.
In the second version, background processes ORA_W001_orcl (W001 is the instance number) read, the number of background processes is adjusted using the new parameter INMEMORY_MAX_POPULATE_SERVERS. As a result, after the restart, the instance is immediately available for working in the background, and the start time of the instance does not increase. Of course, in the beginning the load on the processor increases, where can I go. But then analytical queries will work faster.
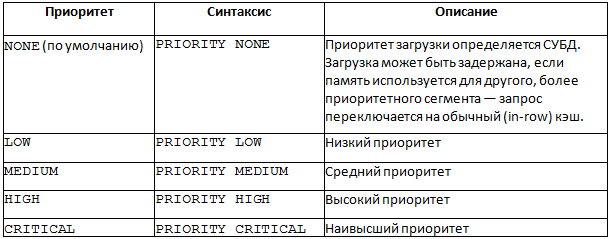
You can control the priority of loading into the cache, here are the options for priority values:
Suppose we keep a directory of cities in the cities table, and this directory is constantly needed by all users, it constantly participates in reports. In this case, we must specify a critical priority for this table, thereby we will force the system to automatically read an instance of this table into the cache when the database starts:
As you well know, there are practically no pure OLTP systems. Any OLTP application has reporting support, and reporting requires additional indexes. And what are additional indexes? This is nothing more than the extra overhead of inserting data.
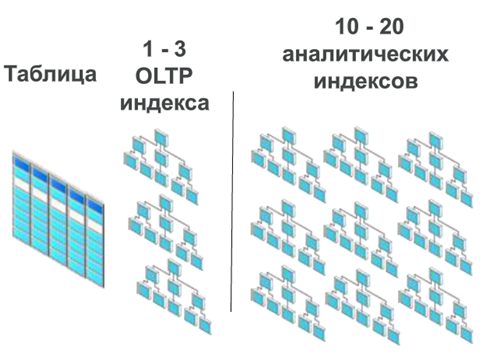
And now let me proudly inform you that when switching to Oracle Database In-Memory, this problem is also solved, because in this technology it’s right! - indexes are not used. Those. we can simply remove the indexes that we need for analytics, and we get a paradoxical effect - a system designed to increase the speed of data warehousing perfectly accelerates OLTP applications.

At the same time, the Oracle Database In-Memory technology does not interfere and does not try to help those operations that previously worked well (the principle “do not repair what did not break” is in action!), Because it is located in the database core, so say aside. That is, this technology does not affect the data format on disk, everything works exactly the same as before, no matter what file system you use. Data files do not change, log, backup, data recovery work as before. All technologies, including ASM, RAC, DataGuard, GoldenGate - work transparently.
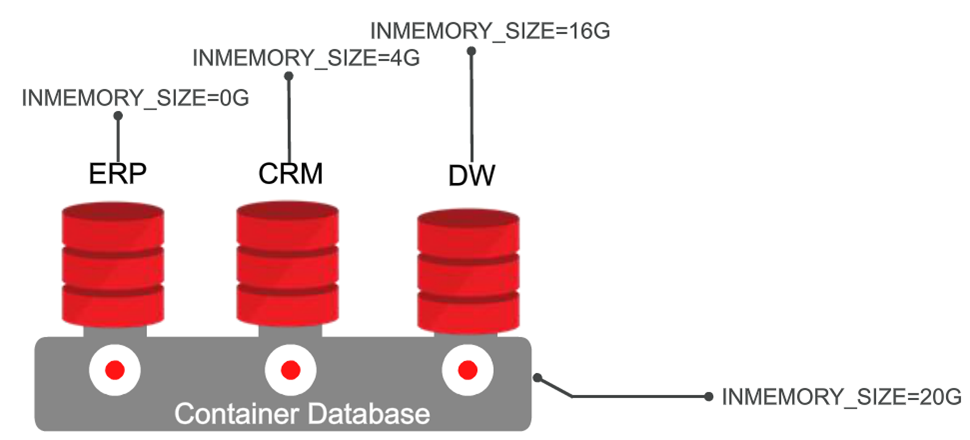
The main architectural innovation in Oracle Database 12c is container architecture. Oracle Database In-Memory fully supports this architecture. The INMEMORY_SIZE parameter is set at the level of the entire container database, and at the level of specific databases it can be varied depending on the specific application. For example, at the container database level you can set INMEMORY_SIZE to 20 GB, and at the container level you can not enable the cache for ERP, for CRM set the cache size to 4 GB, for data storage - 16 GB.
Yes, and in Oracle Real Application Cluster clusters this also works. You can control the distribution of objects in the In-Memory cache between nodes in the cluster. For example, you can specify the DUPLICATE option, then when you change the cache on one of the cluster nodes, they will automatically synchronize with the second node, this is necessary so that there always exists an available copy of the cache with "heated" columnar data:
Other options:
• AUTO DISTRIBUTE - DBMS controls the cache synchronization (used by default);
• DUPLICATE ALL - the same cache is synchronized on all nodes of the cluster;
• DISTRIBUTE BY ROWID RANGE;
• DISTRIBUTE BY PARTITION;
• DISTRIBUTE BY SUBPARTITION.
The DUPLICATE and DUPLICATE ALL options only work on Oracle Exadata and Oracle SuperCluster; on a regular server, this option is ignored. The remaining options are needed for more flexible control - for example, using the DISTRIBUTE BY ROWID RANGE parameter, you can specify that part of the sections should be in column form on one node, and the rest on another node.
I can no longer hide the full syntax of the ALTER TABLE INMEMORY command from you. There he is:
You can specify the priority of loading into the cache, the method of synchronizing the cache between cluster nodes, the names of the columns that you need and do not need to cache in memory, the compression ratio. The command, as I already wrote, is executed once, then the information is stored.
For real engineers, they can fine-tune their queries using the SQL optimizer hints: INMEMORY, NO_INMEMORY, INMEMORY_PRUNING and NO_INMEMORY_PRUNING.
NO_INMEMORY, as you can see, is the simplest hint here. For example, you can explicitly instruct the optimizer not to use In-Memory technology - if you are sure that this is simply not necessary, because you have a good query, indexes are built, etc. Two more interesting hints - INMEMORY_PRUNING and NO_INMEMORY_PRUNING, they control the use of storage indexes. The storage index stores the minimum and maximum values of the column in each extent of the cache memory and transparently eliminates unnecessary column scans, for example: WHERE prod_id> 14 AND prod_id <29.
New parameters have appeared in the INIT.ORA initialization file, I give them for free, that is, for free :
• INMEMORY_SIZE
• INMEMORY_FORCE = {DEFAULT | OFF}
• INMEMORY_CLAUSE_DEFAULT = [INMEMORY] [NO INMEMORY] [compression-clauses] [priority-clauses]
• INMEMORY_QUERY = {ENABLE | DISABLE}
• INMEMORY_MAX_POPULATE_SERVERS
• OPTIMIZER_INMEMORY_AWARE
• INMEMORY TRICKLE REPOPULATE SERVERS PERCENT
INMEMORY_SIZE allows you to specify the size of the memory area for columnar data, the default value is zero. For example, INMEMORY_MAX_POPULATE_SERVERS is the number of background processes that read data from the disk to the cache, by default it is equal to the number of processors that the Oracle Database “sees”. Another interesting parameter is OPTIMIZER_INMEMORY_AWARE, with its help you can specify whether the optimizer sees or does not see the In-Memory cache. For example, this is necessary if you need to evaluate the overhead. I suggest you find the details in the documentation.
Oracle Database In-Memory is most suitable for applications in which there are a lot of queries scanning a lot of rows with filters such as: "=", "<", ">", "IN". The technology is very effective when the application queries only a few columns from a large number (typical for SAP), connects large factor tables with dimension tables, with filters on dimension tables. Accordingly, these are applications such as data warehouses, information and analytical systems, including OLTP applications. By the way, there is a useful additional product - Oracle Database In-Memory Advisor, it helps to evaluate the applicability of Oracle Database In-Memory technology to specific applications. Oracle Database In-Memory Adviser analyzes the statistics of the database and gives recommendations on the size of memory, according to the type of tables,
It is important to understand that unlike competitors, Oracle Database In-Memory does not require rewriting applications. There are no restrictions on SQL, no data migration is needed, the technology is ready for the cloud.
Do not confuse Oracle Database In-Memory and Oracle TimesTen In-Memory Database, these are different technologies. TimesTen is an embedded database for applications, it is designed for clean, not mixed OLTP systems, for cases where the application should work in real time, and the response time should be literally seconds, not seconds and not milliseconds. TimesTen fully loads all the data into RAM. In contrast, Oracle Database In-Memory is an extension of the classic Oracle DBMS, located inside its core and expands its capabilities in terms of accelerating analytical queries due to the column representation.
It seems to me that I have written enough to arouse in you an irresistible desire to read the documentation for Oracle Database In-Memory. But here it is - the technology is new, there is little expertise on it; I alone cannot answer all your questions. Therefore, friends, sign up for our online training. We will be sure to announce them right here. But for now I have everything.
In recent years, a logical moment for this, it would seem, has come. The cost of RAM fell, fell, and fell completely. At the beginning of the century, it seemed that 256 MB of memory for the server was normal, and even a lot. Today, we won’t surprise you with the 256 GB RAM option on an entry-level server, and with industrial servers it’s completely communism, any noble don can get at least a terabyte of RAM on the server if he wants.
But this is not only the case - new data indexing technologies have appeared, new data compression technologies - OLTP compression, unstructured data compression
(LOB Compression). Oracle Database 11g, for example, introduced Result Cache technology, which allows you to cache not just table rows or indexes, but also the results of queries and subqueries themselves.
That is, on the one hand, it is finally possible to use RAM for its intended purpose, but on the other hand, it is not so simple. The larger the cache, the greater the overhead for maintaining it, including processor time. You put more memory, increase the cache size, and the system runs slower, and this, in general, is logical, because the memory management algorithms developed by our great-grandfathers in the Early Middle Ages are simply not suitable for the Renaissance, and that’s all. What to do?
And here is what. Let's recall that, in fact, there are two categories of databases: lowercase databases, which both in the buffer cache in RAM and on disk store information in the lower case - Oracle Database, Microsoft SQL Server, IBM DB / 2 , MySQL, etc .; and column DBMS, in which information is stored in columns, and which, unfortunately, are not widely used in the industry. Lowercase databases handle OLTP operations well, but analytics are more suitable for processing, you will laugh, columned databases - but DML operations are a problem for them, well, you understand why. Industry, as you know, has taken the path of lowercase databases, onto which analytical possibilities are hung in the form of a compromise.
And so, Oracle Database In-Memory technology appeared, in which the advantages of both approaches are finally combined.
And what happens?
It turns out fantastic. Transaction processing is accelerated twice, insertion of rows occurs 3-4 times faster, queries for analytics are executed in real time, almost instantly! Marketers say that analytics has become a hundred times faster, but they are modest not to scare the market, the real results are much more impressive.
Now let's figure out how and in what it works.
So, the technology appeared in version Oracle Database 12.1.0.2, and its meaning is that next to our usual buffer cache, which stores table rows and index blocks, there is a new cache, more precisely, a new shared area for data in RAM, in which data from tables is stored in column format! You got it, huh? Both a row and column format of storage in memory for the same data and tables! Moreover, the data is simultaneously active and transactionally consistent. All changes, as usual, are first made in the regular buffer cache, after which they are reflected in the column cache, or, as our English-speaking friends call it, a “columnar” cache.
A few important details. Firstly, only tables are reflected in the columnar cache, that is, indexes are not cached - this is the first. Secondly, technology does not do unnecessary work. If the data is read but not changed, then there is no need to store them in the usual, that is, in the line buffer cache. But if the data changes, then they must be stored in both caches, buffer and column. Well, and accordingly, analytics works faster because it is more efficient for it precisely the column representation of information. This is the second. And thirdly, once again, to make it clear. The column cache does not store data blocks from disk. In blocks on the disk, information is stored line by line. The information is stored in a columnar cache in columns, in its own representation, in the so-called In-Memory “compress units”. This is the third.
And now the details
We realized that analytics works hundreds of times faster, because the column representation is more efficient for it - and, in fact, why?
In a regular buffer cache, information is stored line by line. Here is an example - you need to extract column No. 4 from a four-column table. To do this, you will have to completely scan this entire plate in RAM:
And what happens if the same table is stored in column format? The entire fourth column of our plate is in one extent, i.e. in one block of memory. We can immediately select it, immediately read it and return it to the application. The costs of scanning, sending these data to the processor are reduced, and processor load is reduced. Everything works much faster.
Such scanning operations are very characteristic for ERP applications, for data warehouses in analytical systems. Agree, the right thing for the progress of mankind.
Technically, to run this, you need to enable caching for the desired columns in the table. A special extension of the syntax of the ALTER TABLE command is intended for this:
SQL> ALTER TABLE cities INMEMORY INMEMORY (Id, Name, Country_Id, Time_Zone) NO INMEMORY (Created, Modified, State); Table altered.
This is done once, the information is recorded in the Oracle DBMS system dictionary, after which it is automatically used by the database in the process of its work. In the above example, service columns are not included in reports, they are needed only for internal audit of the application, and therefore we do not cache them.
You can specify caching for all columns for a materialized view:
SQL> ALTER MATERIALIZED VIEW cities_mv INMEMORY
Materialized view altered.
You can enable caching at the entire tablespace level:
SQL> ALTER TABLESPACE tbs_data DEFAULT INMEMORY MEMCOMPRESS FOR CAPACITY HIGH PRIORITY LOW; Tablespace altered.
And you can flexibly cache tables by columns at the section level to align the caching strategy with business rules:
SQL> CREATE TABLE customers ....... PARTITION BY LIST PARTITION p1 ....... INMEMORY, PARTITION p2 ....... NO INMEMORY);
For example, we have historical data, and they are partitioned by date. When y closes a period of, say, an operational day, the data in this section of the table no longer changes, and analytics can begin to work on them. For this, caching is needed for sections of the table for which the period is closed. And for data that is undergoing intensive changes and deletions, there is no need to enable caching so far.
Behind the scenes
What happens when we turn on caching and the information is written to the Oracle DBMS dictionary? The magic happens - the SQL optimizer rebuilds the query plan. For the first time, when the request comes from the application, at the stage of the so-called hard parsing (hard parse), a query execution plan is generated.
In this example, the total number of lines in the plate of the CITIES city directory is calculated. The optimizer sees that it is profitable to perform a query on a column view, and performs a TABLE ACCESS INMEMORY FULL scan. This is completely transparent for the application, no rewriting or modification of the application is required!
The Oracle database itself uses a number of interesting optimization techniques:
1. Each processor core scans its own column. In this case, fast vector SIMD instructions are used, i.e. special processor commands that use not a scalar value as arguments, but a vector of values. This provides a scan of billions of lines per second.
2. We do not just scan data. It scans and joins data from several tables. On a column view, this is much more efficient than regular joins. These joins run an average of 10 times faster .
3. In the process of query execution, In-Memory Aggregation technology is used: a dynamic object is created in the memory - an interim report. The object is filled during table scanning and allows you to speed up the query. As a result, reports are built 20 times faster without analytic cubes created in advance.
4. In order not to clutter up the RAM, column compression in memory is used. There are six options:
• NO MEMCOPRESS - without compression
• MEMCOMPRESS FOR DML - optimized for DML operations
• MEMCOMPRESS FOR QUERY LOW - the optimal option, which is used by default
• MEMCOMPRESS FOR QUERY HIGH - optimized for query execution speed and to save memory
• MEMCOMPRESS FOR CAPACITY LIGH - optimized for query speed
• MEMCOMPRESS FOR CAPACITY LOW - optimized for memory saving
For example:
SQL> ALTER TABLE cities INMEMORY INMEMORY MEMCOMPRESS FOR CAPACITY HIGH (Country_Id, Time_Zone) INMEMORY NO MEMCOMPRESS (Id, Name, Name_Eng); Table altered.
In this example, the columns in which data is often repeated are selected for compression; unique columns are not compressed.
A new attribute of the INMEMORY segment has appeared in the system table of the USER_TABLES dictionary. The INMEMORY column also appeared in the * _TAB_PARTITIONS system tables. To find out what and in what volume is in the cache, you need to use the special system representation V $ IM_SEGMENTS:
In this example, we see that there are four tables in the cache, with each table on the disk occupying approximately 5 MB each, and in memory, due to compression, from 100 KB to 1 MB. The POPULATE_STATUS column indicates the status of the information. We see that the CITIES, COMPANIES, and AIRPORTS tables are already fully loaded into the In-Memory cache, and COUNTRIES are not yet fully loaded, 400 KB remains to be loaded. That is, right now, this table is transposed into the format in columns and loaded into the cache.
First priority
From a technical point of view, reading into memory from disk can occur in two ways:
• When you first access the data. This is the default feature.
• Automatically after starting the database instance. This feature is enabled by setting the attribute of the PRIORITY segment.
In the second version, background processes ORA_W001_orcl (W001 is the instance number) read, the number of background processes is adjusted using the new parameter INMEMORY_MAX_POPULATE_SERVERS. As a result, after the restart, the instance is immediately available for working in the background, and the start time of the instance does not increase. Of course, in the beginning the load on the processor increases, where can I go. But then analytical queries will work faster.
You can control the priority of loading into the cache, here are the options for priority values:
Suppose we keep a directory of cities in the cities table, and this directory is constantly needed by all users, it constantly participates in reports. In this case, we must specify a critical priority for this table, thereby we will force the system to automatically read an instance of this table into the cache when the database starts:
SQL> ALTER TABLE cities INMEMORY PRIORITY CRITICAL INMEMORY MEMCOMPRESS FOR CAPACITY HIGH (Country_Id, Time_Zone) INMEMORY MEMCOMPRESS NO (Id, Name, Name_Eng); Table altered.
But what about OLTP?
As you well know, there are practically no pure OLTP systems. Any OLTP application has reporting support, and reporting requires additional indexes. And what are additional indexes? This is nothing more than the extra overhead of inserting data.
And now let me proudly inform you that when switching to Oracle Database In-Memory, this problem is also solved, because in this technology it’s right! - indexes are not used. Those. we can simply remove the indexes that we need for analytics, and we get a paradoxical effect - a system designed to increase the speed of data warehousing perfectly accelerates OLTP applications.
At the same time, the Oracle Database In-Memory technology does not interfere and does not try to help those operations that previously worked well (the principle “do not repair what did not break” is in action!), Because it is located in the database core, so say aside. That is, this technology does not affect the data format on disk, everything works exactly the same as before, no matter what file system you use. Data files do not change, log, backup, data recovery work as before. All technologies, including ASM, RAC, DataGuard, GoldenGate - work transparently.
Container architecture
The main architectural innovation in Oracle Database 12c is container architecture. Oracle Database In-Memory fully supports this architecture. The INMEMORY_SIZE parameter is set at the level of the entire container database, and at the level of specific databases it can be varied depending on the specific application. For example, at the container database level you can set INMEMORY_SIZE to 20 GB, and at the container level you can not enable the cache for ERP, for CRM set the cache size to 4 GB, for data storage - 16 GB.
Cluster architecture
Yes, and in Oracle Real Application Cluster clusters this also works. You can control the distribution of objects in the In-Memory cache between nodes in the cluster. For example, you can specify the DUPLICATE option, then when you change the cache on one of the cluster nodes, they will automatically synchronize with the second node, this is necessary so that there always exists an available copy of the cache with "heated" columnar data:
SQL> ALTER TABLE cities INMEMORY DUPLICATE Table altered.
Other options:
• AUTO DISTRIBUTE - DBMS controls the cache synchronization (used by default);
• DUPLICATE ALL - the same cache is synchronized on all nodes of the cluster;
• DISTRIBUTE BY ROWID RANGE;
• DISTRIBUTE BY PARTITION;
• DISTRIBUTE BY SUBPARTITION.
The DUPLICATE and DUPLICATE ALL options only work on Oracle Exadata and Oracle SuperCluster; on a regular server, this option is ignored. The remaining options are needed for more flexible control - for example, using the DISTRIBUTE BY ROWID RANGE parameter, you can specify that part of the sections should be in column form on one node, and the rest on another node.
Summary
I can no longer hide the full syntax of the ALTER TABLE INMEMORY command from you. There he is:
SQL> ALTER TABLE cities INMEMORY PRIORITY CRITICAL Duplicate INMEMORY MEMCOMPRESS FOR CAPACITY HIGH (Country_Id, Time_Zone) INMEMORY MEMCOMPRESS NO (Id, Name, Name_Eng) NO INMEMORY (Created, Modified, State); Table altered.
You can specify the priority of loading into the cache, the method of synchronizing the cache between cluster nodes, the names of the columns that you need and do not need to cache in memory, the compression ratio. The command, as I already wrote, is executed once, then the information is stored.
For real engineers, they can fine-tune their queries using the SQL optimizer hints: INMEMORY, NO_INMEMORY, INMEMORY_PRUNING and NO_INMEMORY_PRUNING.
NO_INMEMORY, as you can see, is the simplest hint here. For example, you can explicitly instruct the optimizer not to use In-Memory technology - if you are sure that this is simply not necessary, because you have a good query, indexes are built, etc. Two more interesting hints - INMEMORY_PRUNING and NO_INMEMORY_PRUNING, they control the use of storage indexes. The storage index stores the minimum and maximum values of the column in each extent of the cache memory and transparently eliminates unnecessary column scans, for example: WHERE prod_id> 14 AND prod_id <29.
New parameters have appeared in the INIT.ORA initialization file, I give them for free, that is, for free :
• INMEMORY_SIZE
• INMEMORY_FORCE = {DEFAULT | OFF}
• INMEMORY_CLAUSE_DEFAULT = [INMEMORY] [NO INMEMORY] [compression-clauses] [priority-clauses]
• INMEMORY_QUERY = {ENABLE | DISABLE}
• INMEMORY_MAX_POPULATE_SERVERS
• OPTIMIZER_INMEMORY_AWARE
• INMEMORY TRICKLE REPOPULATE SERVERS PERCENT
INMEMORY_SIZE allows you to specify the size of the memory area for columnar data, the default value is zero. For example, INMEMORY_MAX_POPULATE_SERVERS is the number of background processes that read data from the disk to the cache, by default it is equal to the number of processors that the Oracle Database “sees”. Another interesting parameter is OPTIMIZER_INMEMORY_AWARE, with its help you can specify whether the optimizer sees or does not see the In-Memory cache. For example, this is necessary if you need to evaluate the overhead. I suggest you find the details in the documentation.
Oracle Database In-Memory is most suitable for applications in which there are a lot of queries scanning a lot of rows with filters such as: "=", "<", ">", "IN". The technology is very effective when the application queries only a few columns from a large number (typical for SAP), connects large factor tables with dimension tables, with filters on dimension tables. Accordingly, these are applications such as data warehouses, information and analytical systems, including OLTP applications. By the way, there is a useful additional product - Oracle Database In-Memory Advisor, it helps to evaluate the applicability of Oracle Database In-Memory technology to specific applications. Oracle Database In-Memory Adviser analyzes the statistics of the database and gives recommendations on the size of memory, according to the type of tables,
It is important to understand that unlike competitors, Oracle Database In-Memory does not require rewriting applications. There are no restrictions on SQL, no data migration is needed, the technology is ready for the cloud.
Do not confuse Oracle Database In-Memory and Oracle TimesTen In-Memory Database, these are different technologies. TimesTen is an embedded database for applications, it is designed for clean, not mixed OLTP systems, for cases where the application should work in real time, and the response time should be literally seconds, not seconds and not milliseconds. TimesTen fully loads all the data into RAM. In contrast, Oracle Database In-Memory is an extension of the classic Oracle DBMS, located inside its core and expands its capabilities in terms of accelerating analytical queries due to the column representation.
It seems to me that I have written enough to arouse in you an irresistible desire to read the documentation for Oracle Database In-Memory. But here it is - the technology is new, there is little expertise on it; I alone cannot answer all your questions. Therefore, friends, sign up for our online training. We will be sure to announce them right here. But for now I have everything.