GOST 28147-89 encryption on x86 and GPU processors
The article presents the test results of the optimized GOST encryption algorithms obtained in September and March 2014 by the Security Code company on new Intel server processors, as well as on graphic processors of various manufacturers.
With the development of IT technology, the volume of data transmitted over the global Internet, located in networked storages and processed in the "clouds" has increased dramatically. Some of this data is confidential, therefore, it is necessary to ensure their protection against unauthorized access. Encryption is traditionally used to protect confidential data, and symmetric encryption algorithms, such as the well-known block algorithm, AES, are used when encrypting large volumes. To comply with Russian law when encrypting such information as personal data, it is necessary to use the national symmetric block encryption algorithm GOST 28147–89. The data encryption operation is quite expensive and requires additional time for data processing, resulting in reduced performance and increased latency. To reduce this negative effect when protecting data, it is necessary to increase the encryption speed. Basically, encryption algorithms are implemented in software, but they use hardware methods to achieve high speeds. Unfortunately, in modern x86 architecture processors, hardware-based encryption acceleration is implemented only for the AES standard (AES-NI instruction set). This standard is based on a special algebraic structure, and other encryption standards can be accelerated using AES-NI instructions only if their structure matches AES (for example, Camellia).
To reduce this negative effect when protecting data, it is necessary to increase the encryption speed. Basically, encryption algorithms are implemented in software, but they use hardware methods to achieve high speeds. Unfortunately, in modern x86 architecture processors, hardware-based encryption acceleration is implemented only for the AES standard (AES-NI instruction set). This standard is based on a special algebraic structure, and other encryption standards can be accelerated using AES-NI instructions only if their structure matches AES (for example, Camellia).
When implementing GOST 28147–89, AES-NI instructions cannot be used, but other approaches can be used to accelerate encryption. For example, multi-block encryption - one encryption software stream processes several blocks in parallel. But to parallelize the processing of a single data array (Fig. 1) only in those encryption modes GOST 28147–89, where there is no feedback between the processed blocks (gamming, ECB). For modes with feedback between the blocks (CFB, MAC), you can use parallel processing of several blocks from different encryption streams (Fig. 2). With this approach, the encryption speed of GOST 28147–89 can be measured in ECB mode without loss of generality. At the same time, it is worth noting the buffer size for each such encryption stream - it should not exceed 4 KB (sector size on the HDD).
Modern x86 architecture processors (as well as ARM, PowerPC, etc.) contain a vector computing unit for parallel processing of several data streams using SIMD technology (single instruction, multiple data). This CPU unit can be effectively used for multiblock encryption GOST 28147–89. The greatest effect is achieved due to the hardware instruction for mixing PSHUFB data (Fig. 3), which allows one to significantly accelerate the nonlinear transformation (hereinafter S-box) in the algorithm. In combination with the extensions of the AVX (or AVX2) commands and the ability of x86 architecture processors to execute several commands in parallel (out-of-order execution), multi-block encryption provides high speed even for one processor core. Implementation of the GOST 28147–89 algorithm using AVX instructions (Intel processor architecture Sandy Bridge / Ivy Bridge) allows you to process data at a speed of 8.5 clocks / bytes for one processor core (the same speed for the AES-256 algorithm without using AES instructions NI). For Intel Haswell architecture with AVX2 support, performance rises to 6.7 clocks / bytes. If the target encryption system uses only the CPU, then its performance will increase linearly from the total number of CPU cores (Fig. 4) in the system and their frequency. On the Intel Xeon 2 x E5-2697 v3 platform, when processing 16 GOST 28147–89 encryption streams on one CPU core (AVX, Fig. 4), the maximum speed was 9425 MB / s (10.5 MB / s per 1 stream). When using the AVX2 instructions (32 encryption streams) on the test platform, the speed was 13133 MB / s (7, 3 MB / s per stream) or more than 100 Gbit / s. The low encryption speed of a single stream needs to be clarified. For example, we need to encrypt 128 sectors on the hard disk (sector size 512 bytes). Since the sectors can be encrypted in parallel, the encryption speed on 1 CPU core in this case will be 10.5 MB / s × 16 streams = 168 MB / s and 7.3 MB / s × 32 streams = 233.3 MB / s for AVX and AVX2 respectively. It is worth noting that Intel Hyper-threading technology allows you to increase the total platform speed by 30% with a 50% decrease in speed per thread (Fig. 4). then the encryption speed on 1 CPU core in this case will be 10.5 MB / s × 16 streams = 168 MB / s and 7.3 MB / s × 32 streams = 233.3 MB / s for AVX and AVX2, respectively. It is worth noting that Intel Hyper-threading technology allows you to increase the total platform speed by 30% with a 50% decrease in speed per thread (Fig. 4). then the encryption speed on 1 CPU core in this case will be 10.5 MB / s × 16 streams = 168 MB / s and 7.3 MB / s × 32 streams = 233.3 MB / s for AVX and AVX2, respectively. It is worth noting that Intel Hyper-threading technology allows you to increase the total platform speed by 30% with a 50% decrease in speed per thread (Fig. 4).
Implementation of the GOST 28147–89 algorithm using AVX instructions (Intel processor architecture Sandy Bridge / Ivy Bridge) allows you to process data at a speed of 8.5 clocks / bytes for one processor core (the same speed for the AES-256 algorithm without using AES instructions NI). For Intel Haswell architecture with AVX2 support, performance rises to 6.7 clocks / bytes. If the target encryption system uses only the CPU, then its performance will increase linearly from the total number of CPU cores (Fig. 4) in the system and their frequency. On the Intel Xeon 2 x E5-2697 v3 platform, when processing 16 GOST 28147–89 encryption streams on one CPU core (AVX, Fig. 4), the maximum speed was 9425 MB / s (10.5 MB / s per 1 stream). When using the AVX2 instructions (32 encryption streams) on the test platform, the speed was 13133 MB / s (7, 3 MB / s per stream) or more than 100 Gbit / s. The low encryption speed of a single stream needs to be clarified. For example, we need to encrypt 128 sectors on the hard disk (sector size 512 bytes). Since the sectors can be encrypted in parallel, the encryption speed on 1 CPU core in this case will be 10.5 MB / s × 16 streams = 168 MB / s and 7.3 MB / s × 32 streams = 233.3 MB / s for AVX and AVX2 respectively. It is worth noting that Intel Hyper-threading technology allows you to increase the total platform speed by 30% with a 50% decrease in speed per thread (Fig. 4). then the encryption speed on 1 CPU core in this case will be 10.5 MB / s × 16 streams = 168 MB / s and 7.3 MB / s × 32 streams = 233.3 MB / s for AVX and AVX2, respectively. It is worth noting that Intel Hyper-threading technology allows you to increase the total platform speed by 30% with a 50% decrease in speed per thread (Fig. 4). then the encryption speed on 1 CPU core in this case will be 10.5 MB / s × 16 streams = 168 MB / s and 7.3 MB / s × 32 streams = 233.3 MB / s for AVX and AVX2, respectively. It is worth noting that Intel Hyper-threading technology allows you to increase the total platform speed by 30% with a 50% decrease in speed per thread (Fig. 4).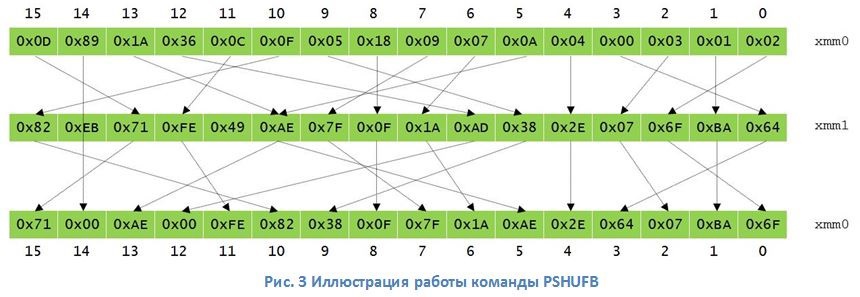
When implementing GOST 28147–89 on general-purpose registers for the S-box operation, a 4 KB pre-calculation table is compiled (A. Vinokurov was the first to propose). Such an approach requires many operations of non-linear memory access, and the speed of such an implementation of the encryption algorithm depends on the CPU memory subsystem. For the Intel Sandy Bridge / Ivy Bridge architecture, the encryption performance in this case is 60 cycles / byte. In this architecture, there are 2 ports for loading data (LD - load data) in each CPU core, which allows multi-block encryption and, in this case, to encrypt 2 blocks in parallel. Then the encryption speed increases to 30 clocks / bytes. For the platform under test, the total encryption speed of GOST 28147–89 on general registers was 2682 MB / s (23.9 MB / s per stream) or 21.97 Gbit / s (GPR, Fig. 4). SIMD multi-block encryption provides maximum processing performance from 4 encryption streams. At the same time, the encryption speed of one stream on SIMD is lower than the speed of one stream on general registers. The CPU encryption parallelization coefficient was 0.99 without Intel Hyper-threading technology. When using this technology, the coefficient decreased to 0.65.
Then the encryption speed increases to 30 clocks / bytes. For the platform under test, the total encryption speed of GOST 28147–89 on general registers was 2682 MB / s (23.9 MB / s per stream) or 21.97 Gbit / s (GPR, Fig. 4). SIMD multi-block encryption provides maximum processing performance from 4 encryption streams. At the same time, the encryption speed of one stream on SIMD is lower than the speed of one stream on general registers. The CPU encryption parallelization coefficient was 0.99 without Intel Hyper-threading technology. When using this technology, the coefficient decreased to 0.65.
To further accelerate encryption according to GOST 28147–89, we investigated heterogeneous systems (CPU + GPU). The development of the GPU architecture has led them to come closer to the CPU in terms of their capabilities, both in programming methods and in hardware. But using the GPU as an encryption accelerator is fraught with a number of technical problems. Typically, a graphics accelerator is a peripheral device that connects to the CPU via the PCI Express data bus. This brings to the implementation of any algorithm using the technology of general computing on graphic accelerators (GPGPU) additional operations for copying data from the CPU memory to the GPU memory and vice versa, but this effect can be reduced by pipelining data processing (Fig. 5). Kernels in modern GPUs are similar in structure to blocks of vector computing in CPUs. Architecturally, GPUs are designed to perform a large number of parallel threads of programs that perform many arithmetic operations. A modern graphics accelerator incorporates a large number of arithmetic logic devices (ALUs) and a memory architecture oriented towards the transfer of large data blocks. In the GOST 28147–89 algorithm, the S-box operation for general-purpose processors requires many non-linear operations of accessing the memory where replacement tables are stored. Non-linear memory reads for the GPU are performed with longer delays than for the CPU. Therefore, we implemented the S-box operation in the GOST 28147–89 algorithm using a Boolean function in order to optimally use the computing capabilities provided by the GPU. At the same time, we managed to get the encryption speed on the Nvidia GeForce GTX 750 GPU (Maxwell architecture) 2588 MB / s (161.8 KB / s per stream) or 21.2 Gbit / s (Fig. 6). For the AMD HD 7790 GPU (GCN 1.1 architecture), the encryption speed is ~ 1700 MB / s. Intel's graphics accelerator, although it did not show outstanding results (295 MB / s), but in terms of prevalence it has no equal. Its speed will be enough to encrypt one hard drive. It is worth noting that not the most productive GPUs were tested, Nvidia and AMD have more productive solutions on similar architectures: GeForce GTX 980 and FirePro W9100. We assume that the speed in this case will increase in proportion to the number of ALUs of these GPUs. 4 times for the GTX 980 and 3 times for the FirePro W9100.
Architecturally, GPUs are designed to perform a large number of parallel threads of programs that perform many arithmetic operations. A modern graphics accelerator incorporates a large number of arithmetic logic devices (ALUs) and a memory architecture oriented towards the transfer of large data blocks. In the GOST 28147–89 algorithm, the S-box operation for general-purpose processors requires many non-linear operations of accessing the memory where replacement tables are stored. Non-linear memory reads for the GPU are performed with longer delays than for the CPU. Therefore, we implemented the S-box operation in the GOST 28147–89 algorithm using a Boolean function in order to optimally use the computing capabilities provided by the GPU. At the same time, we managed to get the encryption speed on the Nvidia GeForce GTX 750 GPU (Maxwell architecture) 2588 MB / s (161.8 KB / s per stream) or 21.2 Gbit / s (Fig. 6). For the AMD HD 7790 GPU (GCN 1.1 architecture), the encryption speed is ~ 1700 MB / s. Intel's graphics accelerator, although it did not show outstanding results (295 MB / s), but in terms of prevalence it has no equal. Its speed will be enough to encrypt one hard drive. It is worth noting that not the most productive GPUs were tested, Nvidia and AMD have more productive solutions on similar architectures: GeForce GTX 980 and FirePro W9100. We assume that the speed in this case will increase in proportion to the number of ALUs of these GPUs. 4 times for the GTX 980 and 3 times for the FirePro W9100.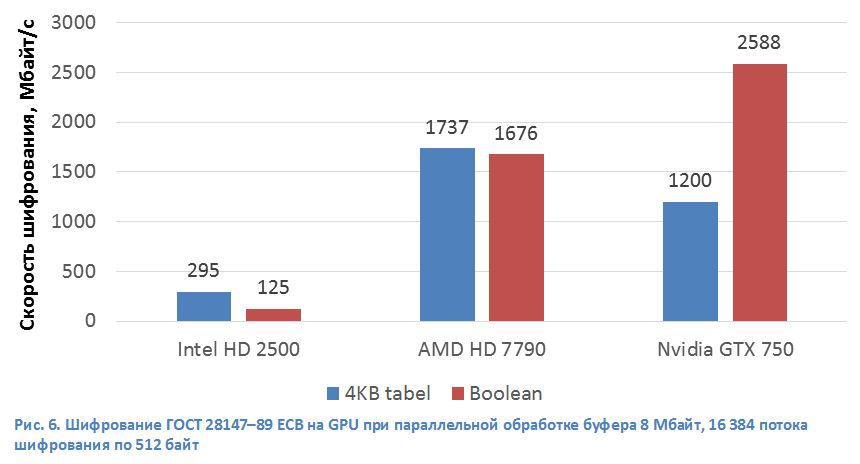
According to its high-speed characteristics, GOST 28147–89 encryption approaches AES and can become a good alternative to it. If you combine encryption on the CPU and GPU, you can achieve encryption speed per node at 53 GB / s (platform 2 CPU Intel Xeon E5-2697 v3 + 4 GPU Nvidia GeForce GTX 980). We briefly list the areas where such encryption speeds may be in demand. Firstly, for encryption of networks of the standard 40 Gbit / s and 80 Gbit / s, which will be implemented in the next versions of Continental software complex. Secondly, in the distributed network disk storages. Currently, the Security Code is developing a pass-through encryptor for the iSCSI protocol. Thirdly, the encryption operation itself can be sold as a service in cloud services - the cloud client pays extra for encrypting his data or connection.
Encryption acceleration GOST 28147–89
With the development of IT technology, the volume of data transmitted over the global Internet, located in networked storages and processed in the "clouds" has increased dramatically. Some of this data is confidential, therefore, it is necessary to ensure their protection against unauthorized access. Encryption is traditionally used to protect confidential data, and symmetric encryption algorithms, such as the well-known block algorithm, AES, are used when encrypting large volumes. To comply with Russian law when encrypting such information as personal data, it is necessary to use the national symmetric block encryption algorithm GOST 28147–89. The data encryption operation is quite expensive and requires additional time for data processing, resulting in reduced performance and increased latency.
To reduce this negative effect when protecting data, it is necessary to increase the encryption speed. Basically, encryption algorithms are implemented in software, but they use hardware methods to achieve high speeds. Unfortunately, in modern x86 architecture processors, hardware-based encryption acceleration is implemented only for the AES standard (AES-NI instruction set). This standard is based on a special algebraic structure, and other encryption standards can be accelerated using AES-NI instructions only if their structure matches AES (for example, Camellia).When implementing GOST 28147–89, AES-NI instructions cannot be used, but other approaches can be used to accelerate encryption. For example, multi-block encryption - one encryption software stream processes several blocks in parallel. But to parallelize the processing of a single data array (Fig. 1) only in those encryption modes GOST 28147–89, where there is no feedback between the processed blocks (gamming, ECB). For modes with feedback between the blocks (CFB, MAC), you can use parallel processing of several blocks from different encryption streams (Fig. 2). With this approach, the encryption speed of GOST 28147–89 can be measured in ECB mode without loss of generality. At the same time, it is worth noting the buffer size for each such encryption stream - it should not exceed 4 KB (sector size on the HDD).
Acceleration of GOST 28147–89 on the central processor (CPU) using SIMD technologies
Modern x86 architecture processors (as well as ARM, PowerPC, etc.) contain a vector computing unit for parallel processing of several data streams using SIMD technology (single instruction, multiple data). This CPU unit can be effectively used for multiblock encryption GOST 28147–89. The greatest effect is achieved due to the hardware instruction for mixing PSHUFB data (Fig. 3), which allows one to significantly accelerate the nonlinear transformation (hereinafter S-box) in the algorithm. In combination with the extensions of the AVX (or AVX2) commands and the ability of x86 architecture processors to execute several commands in parallel (out-of-order execution), multi-block encryption provides high speed even for one processor core.
Acceleration of GOST 28147–89 on the central processor (CPU) on general purpose registers
When implementing GOST 28147–89 on general-purpose registers for the S-box operation, a 4 KB pre-calculation table is compiled (A. Vinokurov was the first to propose). Such an approach requires many operations of non-linear memory access, and the speed of such an implementation of the encryption algorithm depends on the CPU memory subsystem. For the Intel Sandy Bridge / Ivy Bridge architecture, the encryption performance in this case is 60 cycles / byte. In this architecture, there are 2 ports for loading data (LD - load data) in each CPU core, which allows multi-block encryption and, in this case, to encrypt 2 blocks in parallel.
Acceleration of GOST 28147–89 on the graphic processor (GPU)
To further accelerate encryption according to GOST 28147–89, we investigated heterogeneous systems (CPU + GPU). The development of the GPU architecture has led them to come closer to the CPU in terms of their capabilities, both in programming methods and in hardware. But using the GPU as an encryption accelerator is fraught with a number of technical problems. Typically, a graphics accelerator is a peripheral device that connects to the CPU via the PCI Express data bus. This brings to the implementation of any algorithm using the technology of general computing on graphic accelerators (GPGPU) additional operations for copying data from the CPU memory to the GPU memory and vice versa, but this effect can be reduced by pipelining data processing (Fig. 5). Kernels in modern GPUs are similar in structure to blocks of vector computing in CPUs.
Conclusion
According to its high-speed characteristics, GOST 28147–89 encryption approaches AES and can become a good alternative to it. If you combine encryption on the CPU and GPU, you can achieve encryption speed per node at 53 GB / s (platform 2 CPU Intel Xeon E5-2697 v3 + 4 GPU Nvidia GeForce GTX 980). We briefly list the areas where such encryption speeds may be in demand. Firstly, for encryption of networks of the standard 40 Gbit / s and 80 Gbit / s, which will be implemented in the next versions of Continental software complex. Secondly, in the distributed network disk storages. Currently, the Security Code is developing a pass-through encryptor for the iSCSI protocol. Thirdly, the encryption operation itself can be sold as a service in cloud services - the cloud client pays extra for encrypting his data or connection.