False identification of electric cello
- Tutorial
When Alexey TheShade Shipilev talked about the behavior of Java strings with a zero hashcode value, he cited the string as an example
There are 2 32 different hash codes- a little more than four billion, and the words in the human language - about one hundred thousand. Finding one word with the desired hashcode is almost impossible, but a combination of two words is quite possible. If you add more variations like prepositions, a choice will appear.
Iterate over all possible combinations for a long time, but you can optimize the process by performing simple conversions over the string hash code formula. Let's write a phrase generator with a given hashcode. We will write in pure Java 8, in the now fashionable functional style.
So, the hash code formula is h from the string s , where l (s) is its length, and s [i] is the i- th character:
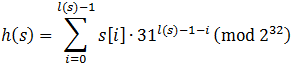
Calculations are done modulo 2 32, since overflow of an integer here is a common thing. Note that if we have two lines s 1 and s 2 with known hash codes, then the hash code of the concatenation of these lines will be equal.
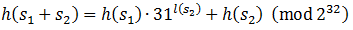
Here the algorithm is already pecking. If we want to make a line with a given hashcode in two parts, the second part can be selected so that it complements the hashcode to the desired value. We'll have to go over all the possible lengths of the second part, but it's still much faster than sorting through all the pairs.
We will generate phrases in this form: An
excuse with spaces around it or just a space will be called an infix. The first word will be s 1 , and the infix and the second will be s 2. Take the base of words, for example, here (litf-win.txt file). The file looks something like this:
The number does not interest us, and we cut it off. In addition, throw out words shorter than three characters:
We fill in the prepositions manually:
Create a list of infixes: add spaces around prepositions and a separate space:
We compose a stream of various combinations of infixes and words (lines s 2 ):
Now we will form an associative array from this stream (string length -> (hashcode -> string)). In Java 8, this is significantly simpler than in previous versions:
Let's make a stream for s 1 - capitalized letters (alas, there is still no ready-made method for this):
To match s 1 all sorts of options s 2 , you can use
Denote the target hashcode by target. Then, for each record
It remains to glue s 1 and s 2 , sort alphabetically and display on the console:
That's the whole program.
The program works out in ten seconds and produces more than a hundred options. Of course, most of them are not grammatically consistent or just boring. But good also come across.
So, if you want to make a report that the hash code for certain lines is recalculated every time, it can be illustrated with the following examples (target = 0):
If you are going to tell your colleagues why it is harmful to calculate
By changing the target value, you can generate phrases for any other hashcode.
"лжеотождествление электровиолончели". When FindBugs warns you of problems calculating the absolute value of the hashcode equal to Integer.MIN_VALUE, it gives examples of strings that have such a hashcode - "polygenelubricants"or "DESIGNING WORKHOUSES". Where did these examples come from? How to make a beautiful line with a given hashcode yourself? There are 2 32 different hash codes- a little more than four billion, and the words in the human language - about one hundred thousand. Finding one word with the desired hashcode is almost impossible, but a combination of two words is quite possible. If you add more variations like prepositions, a choice will appear.
Iterate over all possible combinations for a long time, but you can optimize the process by performing simple conversions over the string hash code formula. Let's write a phrase generator with a given hashcode. We will write in pure Java 8, in the now fashionable functional style.
So, the hash code formula is h from the string s , where l (s) is its length, and s [i] is the i- th character:
Calculations are done modulo 2 32, since overflow of an integer here is a common thing. Note that if we have two lines s 1 and s 2 with known hash codes, then the hash code of the concatenation of these lines will be equal.
Here the algorithm is already pecking. If we want to make a line with a given hashcode in two parts, the second part can be selected so that it complements the hashcode to the desired value. We'll have to go over all the possible lengths of the second part, but it's still much faster than sorting through all the pairs.
We will generate phrases in this form: An
"<Слово_с_большой_буквы> [<предлог/союз>] <слово_с_маленькой_буквы>"excuse with spaces around it or just a space will be called an infix. The first word will be s 1 , and the infix and the second will be s 2. Take the base of words, for example, here (litf-win.txt file). The file looks something like this:
а 21715
аарона 2
ааронов 1
аб 1
аба 2
абажур 1
абажуром 7
...The number does not interest us, and we cut it off. In addition, throw out words shorter than three characters:
List words = Files.readAllLines(Paths.get("litf-win.txt"), Charset.forName("cp1251")).stream()
.map(s -> s.substring(0, s.indexOf(' ')))
.filter(s -> s.length() > 2)
.collect(Collectors.toList()); We fill in the prepositions manually:
String[] preps = { "в", "и", "с", "по", "на", "под", "над", "от", "из",
"через", "перед", "за", "до", "о", "не", "или", "у", "про", "для" };Create a list of infixes: add spaces around prepositions and a separate space:
List infixes = Stream.concat(Stream.of(" "), Arrays.stream(preps).map(p -> ' '+p+' '))
.collect(Collectors.toList()); We compose a stream of various combinations of infixes and words (lines s 2 ):
words.stream().flatMap(s -> infixes.stream().map((String infix) -> infix+s))Now we will form an associative array from this stream (string length -> (hashcode -> string)). In Java 8, this is significantly simpler than in previous versions:
Map>> lenHashSuffix = words.stream()
.flatMap(s -> infixes.stream().map((String infix) -> infix+s))
.collect(Collectors.groupingBy(String::length, Collectors.groupingBy(String::hashCode))); Let's make a stream for s 1 - capitalized letters (alas, there is still no ready-made method for this):
words.stream().map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1))To match s 1 all sorts of options s 2 , you can use
flatMap. It remains to lenHashSuffixiterate over all the lengths from , calculate the appropriate hashcode for s 2 and extract the lines with this hashcode. This raises the question: how for a given length len calculate h ( s 1 ) · 31 len ? The method Math.powwill not work: it works with fractional numbers. It would be possible to write a cycle for, but this is not modern! Fortunately, we have reduce!int hash = IntStream.range(0, len).reduce(s.hashCode(), (a, i) -> a*31);Denote the target hashcode by target. Then, for each record
entryfrom the lenHashSuffixstream of lines s 2 that suit us, we can get this:entry.getValue().getOrDefault(
target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31),
Collections.emptyList()).stream()It remains to glue s 1 and s 2 , sort alphabetically and display on the console:
words.stream()
.map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1))
.flatMap(s -> lenHashSuffix.entrySet().stream()
.flatMap(entry -> entry.getValue().getOrDefault(
target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31),
Collections.emptyList()).stream().map(suffix -> s+suffix)))
.sorted().forEach(System.out::println);
That's the whole program.
Full source
import java.nio.charset.Charset;
import java.nio.file.*;
import java.util.*;
import java.util.stream.*;
public class PhraseHashCode {
public static void main(String[] args) throws Exception {
int target = Integer.MIN_VALUE;
String[] preps = { "в", "и", "с", "по", "на", "под", "над", "от", "из",
"через", "перед", "за", "до", "о", "не", "или", "у", "про", "для" };
List infixes = Stream.concat(Stream.of(" "), Arrays.stream(preps).map(p -> ' '+p+' '))
.collect(Collectors.toList());
List words = Files.readAllLines(Paths.get("litf-win.txt"), Charset.forName("cp1251")).stream()
.map(s -> s.substring(0, s.indexOf(' ')))
.filter(s -> s.length() > 2)
.collect(Collectors.toList());
Map>> lenHashSuffix = words.stream()
.flatMap(s -> infixes.stream().map((String infix) -> infix+s))
.collect(Collectors.groupingBy(String::length, Collectors.groupingBy(String::hashCode)));
words.stream()
.map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1))
.flatMap(s -> lenHashSuffix.entrySet().stream()
.flatMap(entry -> entry.getValue().getOrDefault(
target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31),
Collections.emptyList()).stream().map(suffix -> s+suffix)))
.sorted().forEach(System.out::println);
}
} results
The program works out in ten seconds and produces more than a hundred options. Of course, most of them are not grammatically consistent or just boring. But good also come across.
So, if you want to make a report that the hash code for certain lines is recalculated every time, it can be illustrated with the following examples (target = 0):
"Бегавшая через бары"
"Издержки экономического"
"Почувствовалось под безотчетной"
"Принесенного в тридцатые"
"Пулею по должностному"
"Посмотрел про право"If you are going to tell your colleagues why it is harmful to calculate
Math.absfrom a hashcode, the following lines are useful to you (target = Integer.MIN_VALUE):"Вельможи у сообщества"
"Объезд и интимное"
"Советовались и подождали"
"Отводит от ноздри"
"Рельсами через тяготенье"By changing the target value, you can generate phrases for any other hashcode.