Analysis of the quality of educational materials, or as we did not work

Good day.
Today I will tell you about the attempts to master the analysis of educational materials, the struggle for the quality of these documents and the disappointment that we have learned. "We" is a pair of students from MSTU. N. E. Bauman. If you're interested, welcome under the cat!
Task
We were going to assess the quality of educational materials (guidelines, textbooks, etc.) by statistical indicators. There were quite a few such indicators, here are some of them: the deviation of the number of chapters from the “ideal” (equal to five), the average number of characters per page, the average number of schemes per page, and so on in the list. Not so difficult, huh? But this was only the beginning, because further, if successful, we were waiting for the construction of ontology and semantic analysis.
Tools and raw data
The problem was in the source materials, and they were all sorts of manuals / textbooks in PDF. Rather, the problem was not even in the materials themselves, but in PDF and the quality of the conversion.
To work with PDF, it was decided to use Python and some fashionable youth library for the role of which pdfminer.six was chosen .
Story
In general, at first we tried different python libraries, but they were not very friendly with the Cyrillic alphabet, and our literature was written in Russian. In addition, the most simple libraries were able only to pull out the text, which was not enough for us. Having stopped on pdfminer.six, we began to prototype, experiment and have fun. Fortunately, there were enough examples for us to begin with.
We created our PDF documents with text, images, tables, and more. Everything was going well with us, we could easily pull out any element from our document.
Here's what the document page looks like in our presentation.
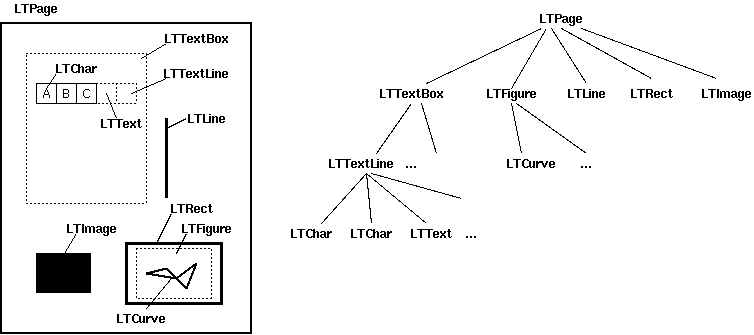
Let me give you a small example of interaction with the document: getting the text of the document.
file = open(path, 'rb')
parser = PDFParser(file)
document = PDFDocument(parser)
output = StringIO()
manager = PDFResourceManager()
converter = TextConverter(manager, output, laparams=LAParams())
interpreter = PDFPageInterpreter(manager, converter)
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
converter.close()
text = output.getvalue()
output.close()
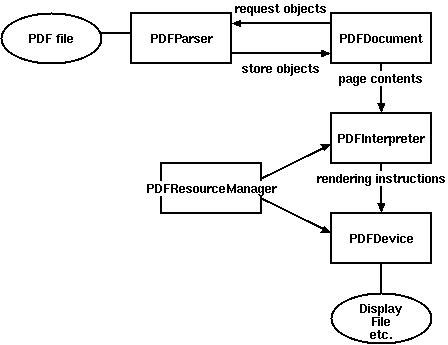
As you can see, getting the text from the document is quite simple. Any interaction is carried out according to the scheme below.
Why didn't it work out?
All experiments were successful and on the test PDF files everything was fine. As it turned out, breaking everything is a trivial task and the idea has broken about the harsh reality.
After the experiments, we took a few real textbooks and found that anything could go wrong.
The first thing we noticed: the number of images counted by the program is not true, and parts of the text are simply lost.
It turned out that some (sometimes even many) parts of the text in the document were not presented as text and it is not known how this happened. This fact immediately dismissed the analysis of the frequency distribution of symbols / words / phrases, semantics, and indeed any other type of text analysis.
It is possible that something unexpected happened while converting or creating these documents, and it is possible that no one needed them to be formed “correctly”. Unfortunately, there was a majority of such materials, which led to disappointment in the idea of such an analysis.
Literature
The documentation section of the pdfminer.six repository was used to write the article and as a reference.