Machine Learning - 1. Correlation and regression. Example: site visitors conversion
- Tutorial
As promised, I’m starting a series of articles on “machine learning”. This will be devoted to such concepts from statistics as the correlation of random variables and linear regression. Consider both real data and model data (Monte Carlo simulation).
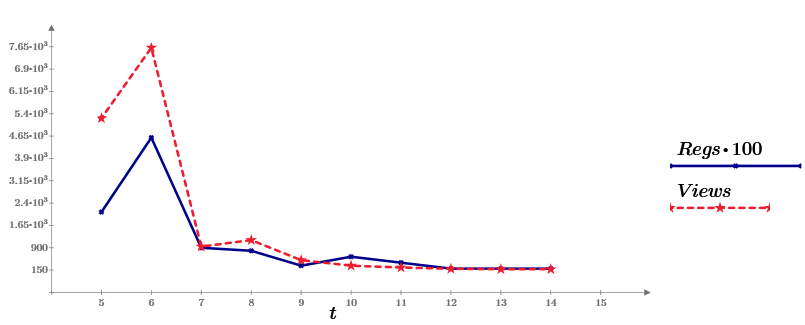
To make it more interesting, the story is built on examples, and as a data (in this and in the following articles) I will try to take statistics directly from here, from Habr. Namely, a week ago I wrote my first article on Habré (about Mathcad Express, in which we’ll count everything). And now, statistics on its views over 10 days and offer as source data. On the graph, this is a series of Views, a blue line. The second row of data (Regs, with a coefficient of 100) shows the number of readers who performed a specific action after reading (registering and downloading the Mathcad Prime distribution kit).
It just so happened that, in addition to the statistics for viewing the article (from Habr), I had access to the statistics of downloads of Mathcad (using the link that I gave inside the article text). Thus, we have everything in order to deal with such a concept of Internet marketing as conversion . A conversion is usually referred to as the ratio of the number of site visitors who completed a purchase, registration, or the like to the total number of visitors. For example: on the first day of publication, my article was viewed 5 thousand times, and there were 20 downloads, i.e. the conversion was 0.4%.
All pictures are screenshots of Mathcad Express (the calculations themselves can be taken here , repeated, and if desired, changed and used for your needs). I entered the initial data (three vectors) with my hands:

Here are the conversion calculations (in%): “instant” (for each day) and “average” (for 10 days). It is curious that the conversion value “floats” a little over time (from 0.4% on the first day to the quasi-stationary 1% in recent days), which, in itself, is worth discussing (which we postpone to the next articles - about random processes and correlation time )
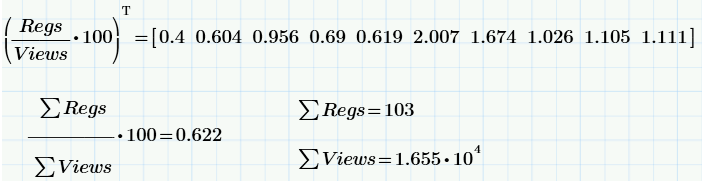
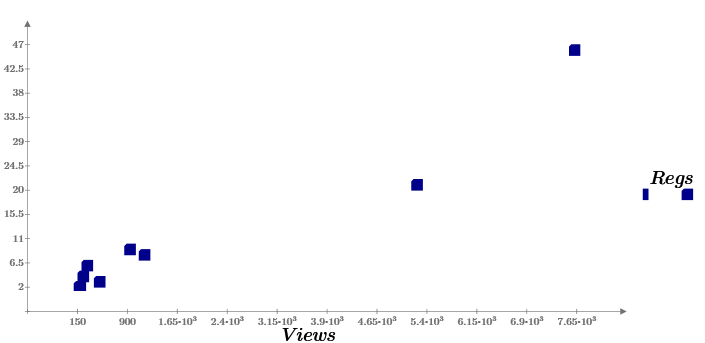
The obvious fact that the number of targeted actions (downloads) depends on the number of views will be clearly demonstrated by the Regs (Views) chart. We see that, although the number of views and the number of downloads are random, they are nevertheless related by an (almost) linear relationship.
Now a little "school" statistics: the calculation (by definition) of the average value, variance and correlation coefficient of the two samples Views and Regs.
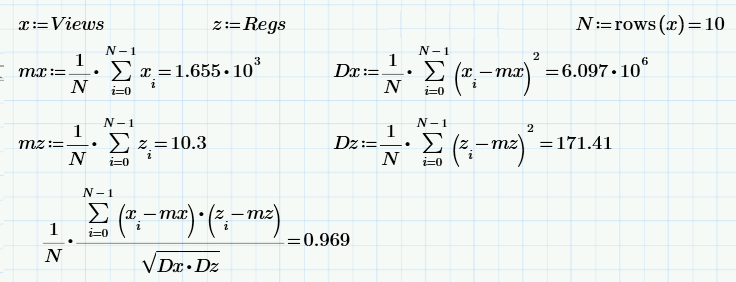
The last formula is the calculation of the correlation coefficient - a measure of how dependent two random variables are (more precisely, measures of linear dependence). It turns out that the sample value of the correlation coefficient is 0.97. This is a lot (which, incidentally, is not surprising, by the very statement of the problem).
Finally, we solve the problem of mathematical regression — approximation, in the general case, of data sampling (x, z) by a certain function f (x), which in a certain way minimizes the set of errors f (x) -z. The simplest and most commonly used type of regression is linear, when f (x) = A * x + B. Another linear regression is often called the least squares method, since the coefficients A and B are usually calculated from the condition of minimizing the sum of the squared errors:
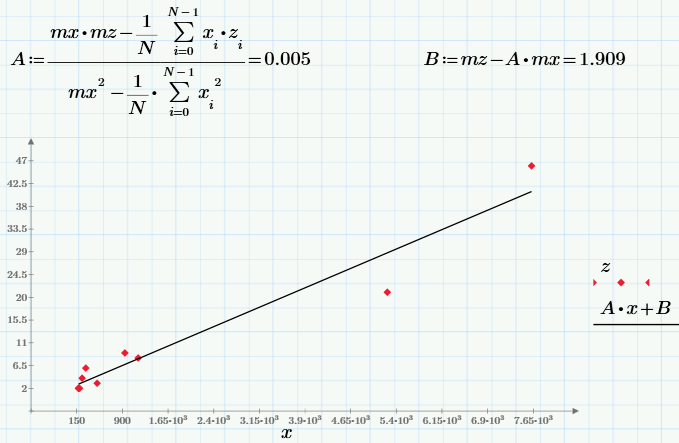
By the way, the least squares method (minimizing the sum of the squared errors) is not the only possible option for constructing a regression. For example, median-median linear regression is sometimes used.
Finally, about why regression is needed in our problem. If we take the linear nature of the dependence of downloads on views, then coefficient A will just characterize the conversion. Judging by it, the conversion is 0.005 = 0.5%, that is, if, for example, we have a marketing goal - to reach 100 downloads, then, based on the linear regression model, we need to “upload” 100 / 0.005 to the website = 20 thousand views.
While in the last part we operated on random data obtained during the experiment, in conclusion we will repeat the same calculations using the pseudo-random number sensor. In Monte Carlo methods, it is often required to create random numbers with a certain correlation. First, we generate three pseudo-random arrays: x and y are independent, and z is x-dependent (with the “general” value of the correlation coefficient r):
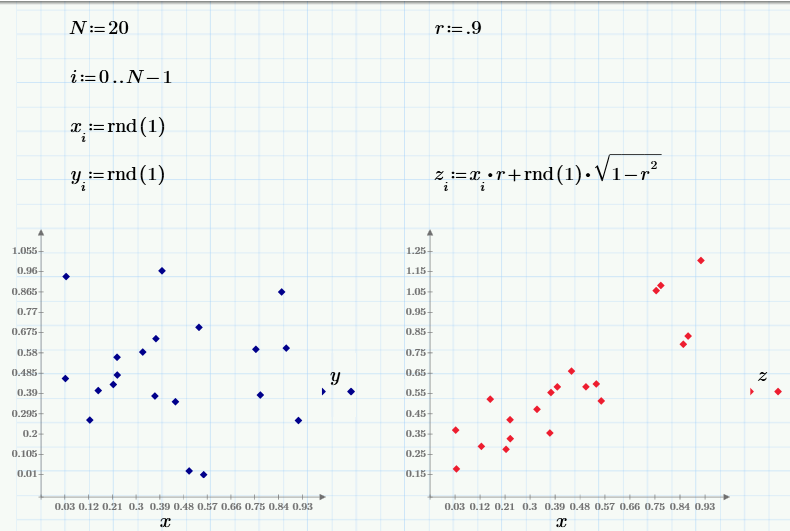
The graph on the left shows the dependence of uncorrelated random values of x and y, and on the right - the dependence of correlated z and x .
Using the same formulas as in the previous section, we obtain the statistical characteristics of the samples x, y, and z (including the sample value of the correlation coefficient):
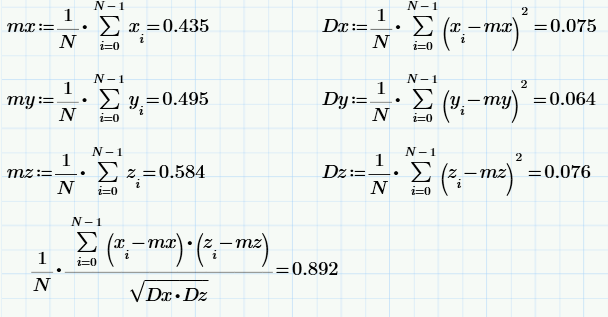
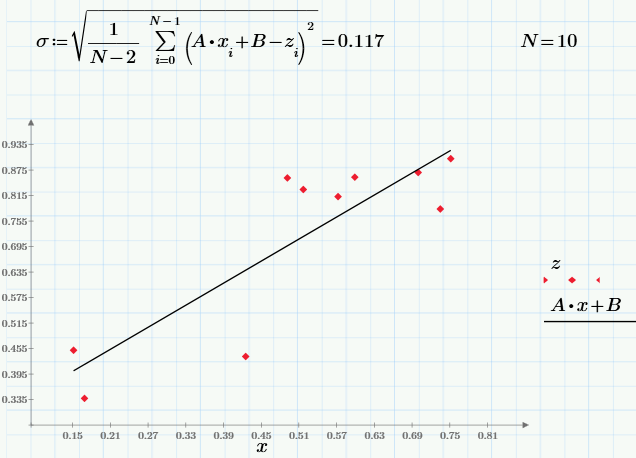
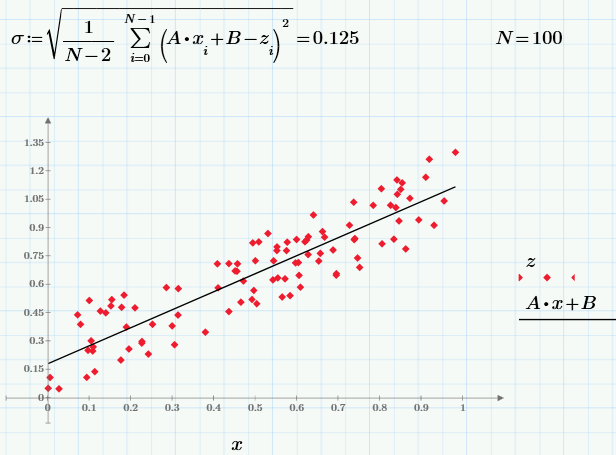
Well, and finally, using the least squares method, we construct a linear regression z = A * x + B:
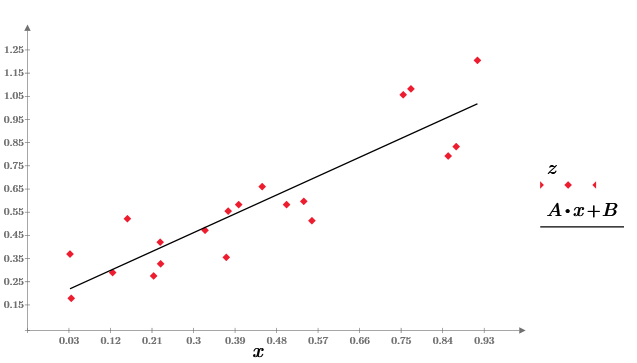
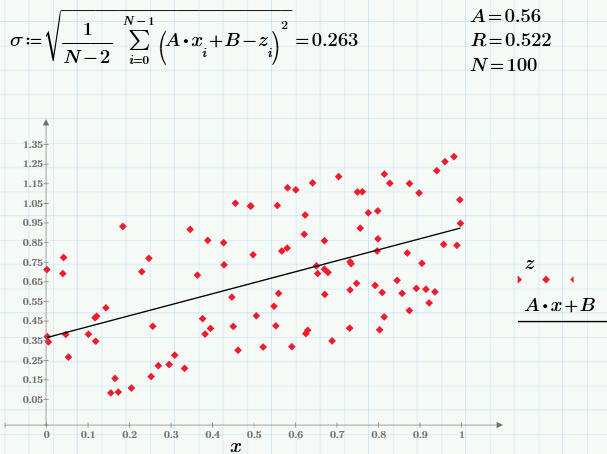
I leave the interested readers to experiment with the parameter r and see how its change will affect the dependence z (x). Still curious, changing the sample size N, follow the result of calculating statistical characteristics.
References:
Part 1. Real data
To make it more interesting, the story is built on examples, and as a data (in this and in the following articles) I will try to take statistics directly from here, from Habr. Namely, a week ago I wrote my first article on Habré (about Mathcad Express, in which we’ll count everything). And now, statistics on its views over 10 days and offer as source data. On the graph, this is a series of Views, a blue line. The second row of data (Regs, with a coefficient of 100) shows the number of readers who performed a specific action after reading (registering and downloading the Mathcad Prime distribution kit).
It just so happened that, in addition to the statistics for viewing the article (from Habr), I had access to the statistics of downloads of Mathcad (using the link that I gave inside the article text). Thus, we have everything in order to deal with such a concept of Internet marketing as conversion . A conversion is usually referred to as the ratio of the number of site visitors who completed a purchase, registration, or the like to the total number of visitors. For example: on the first day of publication, my article was viewed 5 thousand times, and there were 20 downloads, i.e. the conversion was 0.4%.
All pictures are screenshots of Mathcad Express (the calculations themselves can be taken here , repeated, and if desired, changed and used for your needs). I entered the initial data (three vectors) with my hands:
Here are the conversion calculations (in%): “instant” (for each day) and “average” (for 10 days). It is curious that the conversion value “floats” a little over time (from 0.4% on the first day to the quasi-stationary 1% in recent days), which, in itself, is worth discussing (which we postpone to the next articles - about random processes and correlation time )
The obvious fact that the number of targeted actions (downloads) depends on the number of views will be clearly demonstrated by the Regs (Views) chart. We see that, although the number of views and the number of downloads are random, they are nevertheless related by an (almost) linear relationship.
Now a little "school" statistics: the calculation (by definition) of the average value, variance and correlation coefficient of the two samples Views and Regs.
The last formula is the calculation of the correlation coefficient - a measure of how dependent two random variables are (more precisely, measures of linear dependence). It turns out that the sample value of the correlation coefficient is 0.97. This is a lot (which, incidentally, is not surprising, by the very statement of the problem).
Finally, we solve the problem of mathematical regression — approximation, in the general case, of data sampling (x, z) by a certain function f (x), which in a certain way minimizes the set of errors f (x) -z. The simplest and most commonly used type of regression is linear, when f (x) = A * x + B. Another linear regression is often called the least squares method, since the coefficients A and B are usually calculated from the condition of minimizing the sum of the squared errors:
By the way, the least squares method (minimizing the sum of the squared errors) is not the only possible option for constructing a regression. For example, median-median linear regression is sometimes used.
Finally, about why regression is needed in our problem. If we take the linear nature of the dependence of downloads on views, then coefficient A will just characterize the conversion. Judging by it, the conversion is 0.005 = 0.5%, that is, if, for example, we have a marketing goal - to reach 100 downloads, then, based on the linear regression model, we need to “upload” 100 / 0.005 to the website = 20 thousand views.
Part 2. Monte Carlo Modeling
While in the last part we operated on random data obtained during the experiment, in conclusion we will repeat the same calculations using the pseudo-random number sensor. In Monte Carlo methods, it is often required to create random numbers with a certain correlation. First, we generate three pseudo-random arrays: x and y are independent, and z is x-dependent (with the “general” value of the correlation coefficient r):
The graph on the left shows the dependence of uncorrelated random values of x and y, and on the right - the dependence of correlated z and x .
Using the same formulas as in the previous section, we obtain the statistical characteristics of the samples x, y, and z (including the sample value of the correlation coefficient):
Well, and finally, using the least squares method, we construct a linear regression z = A * x + B:
I leave the interested readers to experiment with the parameter r and see how its change will affect the dependence z (x). Still curious, changing the sample size N, follow the result of calculating statistical characteristics.
References:
- Video course "Machine Learning" (Yandex SHAD)
- Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. An Introduction to Statistical Learning in R (PDF)
- Trevor Hastie, Robert Tibshirani, Jerome Friedman. The Elements of Statistical Learning (PDF)
Only registered users can participate in the survey. Please come in.