What Every Programmer Should Know About Compiler Optimization
- Transfer
High-level programming languages contain many abstract programming constructs, such as functions, conditional statements, and loops - they make us surprisingly productive. However, one of the drawbacks of writing code in a high-level language is the potential significant decrease in the speed of the program. Therefore, compilers try to automatically optimize the code and increase the speed of work. These days, the optimization logic has become very complex: compilers transform loops, conditional expressions, and recursive functions; delete entire blocks of code. They optimize the code for the processor architecture to make it really fast and compact. And this is very cool, because it’s better to focus on writing readable code than doing manual optimizations that will be difficult to understand and maintain. Moreover, manual optimizations can prevent the compiler from performing additional and more efficient automatic optimizations. Instead of writing optimizations by hand, it would be better to focus on architecture design and efficient algorithms, including concurrency and the use of library features.
This article is about Visual C ++ compiler optimizations. I am going to discuss the most important optimization techniques and solutions that the compiler must apply to apply them correctly. My goal is not to tell you how to manually optimize the code, but to show why you should trust the compiler to optimize your code yourself. This article is by no means a description of the full set of optimizations that the Visual C ++ compiler makes, it will only show the really important ones that you should be aware of. There are other important optimizations that the compiler is unable to perform. For example, replacing an inefficient algorithm with an effective one or changing the alignment of the data structure. We will not discuss such optimizations in this article.
Compilers are constantly being improved; their approaches are being improved. Despite the fact that they are not perfect, often the most correct approach is still to leave low-level optimizations to the compiler than to try to do them manually.
There are four ways to help the compiler perform optimizations more efficiently:
The purpose of this article is to show you why you can trust the compiler to perform optimizations that apply to inefficient but readable code (first method). I will also give a brief overview of profile-guided optimizations and mention some compiler directives that will allow you to improve part of your source code.
There are many techniques for compiler optimizations, ranging from simple transformations, such as folding constants, to complex ones, such as command scheduling. In this article, we restrict ourselves to the most important optimizations that can significantly improve the performance of your code (by two-digit percentages) and reduce its size by substituting functions (function inlining), COMDAT optimizations, and loop optimizations. I will discuss the first two approaches in the next section, and then show how you can control the performance of optimizations in Visual C ++. In conclusion, I will briefly talk about those optimizations that are used in the .NET Framework. Throughout the article, I will use Visual Studio 2013 for all examples.
If LTCG is enabled (flag
The front end also performs some optimizations (for example, folding constants) regardless of whether optimizations are turned on or off. However, all important optimizations are performed by the back end, and they can be controlled using compilation keys.
LTCG allows the back end to perform many optimizations aggressively (using compiler keys
I will work with a program of two source code files (
The file
The code is very simple, but useful. We have several functions that do simple calculations, some of them contain loops. Function
Consider the result of the compiler under three different configurations. If you will deal with the example yourself, then you will need a assembler output file (obtained using the compiler key
If you look at the generated assembly listing file for
Now let's turn to assembly listing file for
While function inlining is enabled (a key
If you look at the assembly listing file for
As you can see, function inlining is important not only because function calls are optimized, but also because it allows the compiler to perform many additional optimizations. Inlining usually increases performance by increasing the size of the code. Excessive use of this optimization leads to a phenomenon called code bloat. Therefore, with each call to the function, the compiler calculates the costs and benefits, and then decides whether to inline the function.
Due to the importance of inlining, the Visual C ++ compiler provides great support for it. You can tell the compiler to never inline a set of functions using a directive
The key
The compiler cannot always inline a function. For example, during a virtual call to a virtual function: a function cannot be inlined, because the compiler does not know exactly which function will be called. Another example: a function is called through a pointer to a function instead of a call through its name. You should try to avoid such situations so that inlining is possible. A complete list of all such conditions can be found on MSDN.
Function inlining is not the only optimization that can be applied at the program level as a whole. Most optimizations work most effectively at this level. In the remainder of this article, I will discuss a specific class of optimizations called COMDAT optimizations.
By default, during compilation of the module, all code is stored in a single section of the resulting object file. The linker works at the section level: it can delete sections, join them, or reorder. This prevents him from performing three very important optimizations (two-digit percent) that help reduce the size of the executable file and increase its performance. The first removes unused functions and global variables. The second collapses identical functions and global constants. The third reorders functions and global variables so that, at runtime, transitions between physical memory fragments are shorter.
To enable these linker optimizations, you should ask the compiler to pack functions and variables in separate sections using compiler keys
You should use LTCG whenever possible. The only reason for abandoning LTCG is because you want to distribute the resulting object files and library files. Recall that they contain a CIL code instead of a machine code. CIL code can only be used by the compiler and linker of the same version with which they were generated, which is a significant limitation, because developers will have to use the same version of the compiler to use your files. In this case, if you do not want to distribute a separate version of object files for each version of the compiler, then you should use code generation instead. In addition to the version limit, the object files are many times larger than the corresponding assembler object files. However,
If you copy the code with the key
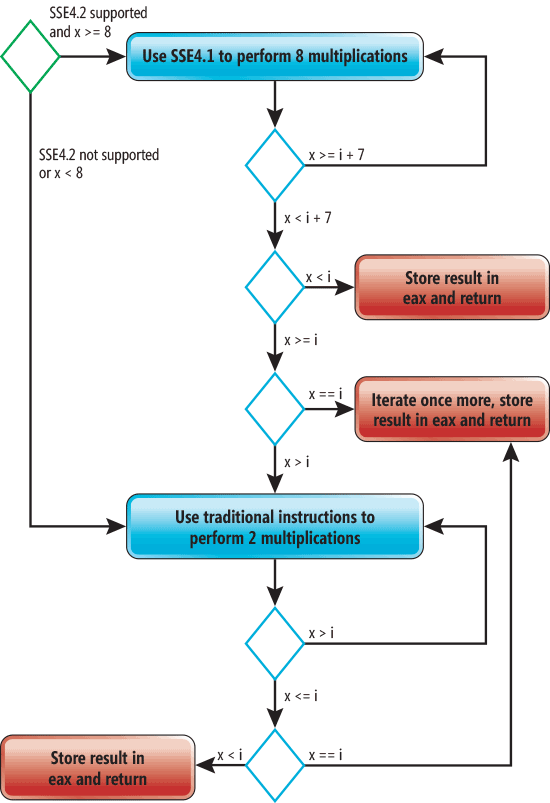
In this diagram, a green rhombus indicates an entry point, and red rectangles indicate an exit point. Blue rhombs represent conditional statements that will be executed when a function is executed
Unwinding of cycles is carried out by repeating the body of the cycle several times inside one iteration of a new (unwound) cycle. This increases productivity, because the operations of the cycle itself will be performed less frequently. In addition, it allows the compiler to perform additional optimizations (for example, vectorization). The disadvantage of unwinding loops is the increase in the amount of code and the load on the registers. But despite this, depending on the body of the cycle, such optimization can increase productivity by two-percent.
Unlike x86 processors, all x86-64 processors support SSE2. Moreover, you can take advantage of the AVX / AVX2 instructions on the latest x86-64 processors from Intel and AMD with a key
Currently, the Visual C ++ compiler does not allow you to control loop unwinding. But you can influence it with the help of the
If you look at the generated assembler code, you may notice that additional optimizations can be applied to it. But the compiler still did an excellent job anyway and there is no need to spend much more time analyzing to apply minor optimizations.
The function is
In conclusion, we look at such an optimization as the removal of cycle invariants. Take a look at the following code:
The only change we made is to add an additional variable, which is incremented at each iteration, and at the end it is displayed on the console. It is easy to see that this code is easily optimized by moving the incremented variable out of the loop: just assign a value to it
But here's the catch: if you apply this optimization manually, the resulting code may lose performance in certain conditions. Can you say why? Imagine a variable
In conclusion, I want to say that if you are not a compiler and not an expert on compiler optimizations, then you should avoid such transformations of your code that make it look like it works faster. Keep your hands clean and trust the compiler to optimize your code.
In this example, the optimization list may be empty or may contain one or more values of the set:
An empty list with a parameter
The key
Directive
What is the difference between RyuJIT and Visual C ++ in terms of optimization capabilities? Due to RyuJIT running at runtime, it can perform optimizations that Visual C ++ is not capable of. For example, right at runtime, he can understand that an expression in a conditional statement will never take value
To date, the ability to control optimized managed code is limited. C # and Visual Basic compilers only allow on or off optimizations using the key
This article is about Visual C ++ compiler optimizations. I am going to discuss the most important optimization techniques and solutions that the compiler must apply to apply them correctly. My goal is not to tell you how to manually optimize the code, but to show why you should trust the compiler to optimize your code yourself. This article is by no means a description of the full set of optimizations that the Visual C ++ compiler makes, it will only show the really important ones that you should be aware of. There are other important optimizations that the compiler is unable to perform. For example, replacing an inefficient algorithm with an effective one or changing the alignment of the data structure. We will not discuss such optimizations in this article.
Defining compiler optimizations
Optimization is the process of converting a piece of code into another piece that is functionally equivalent to the original, in order to improve one or more of its characteristics, of which the speed and size of the code are most important. Other characteristics include the amount of energy consumed per code execution and compilation time (as well as the JIT compilation time if the resulting code uses JIT).Compilers are constantly being improved; their approaches are being improved. Despite the fact that they are not perfect, often the most correct approach is still to leave low-level optimizations to the compiler than to try to do them manually.
There are four ways to help the compiler perform optimizations more efficiently:
- Write readable code that is easy to maintain. Do not think of the different OOP features of Visual C ++ as the worst enemy of performance. The latest version of Visual C ++ will be able to minimize OOP overhead to a minimum, and sometimes even completely get rid of them.
- Use compiler directives. For example, tell the compiler to use that function calling convention that will be faster than the default one.
- Use the functions built into the compiler. These are special functions whose implementation is automatically provided by the compiler. Remember that the compiler has a deep knowledge of how to efficiently arrange a sequence of machine instructions so that the code runs as quickly as possible on the specified software architecture. Currently, the Microsoft .NET Framework does not support built-in functions, so managed languages cannot use them. However, Visual C ++ has extensive support for such functions. However, do not forget that their use, although it will improve the performance of the code, will negatively affect readability and portability.
- Use profile-guided optimization (PGO). Thanks to this technology, the compiler knows more about how the code will behave during operation and optimizes it accordingly.
The purpose of this article is to show you why you can trust the compiler to perform optimizations that apply to inefficient but readable code (first method). I will also give a brief overview of profile-guided optimizations and mention some compiler directives that will allow you to improve part of your source code.
There are many techniques for compiler optimizations, ranging from simple transformations, such as folding constants, to complex ones, such as command scheduling. In this article, we restrict ourselves to the most important optimizations that can significantly improve the performance of your code (by two-digit percentages) and reduce its size by substituting functions (function inlining), COMDAT optimizations, and loop optimizations. I will discuss the first two approaches in the next section, and then show how you can control the performance of optimizations in Visual C ++. In conclusion, I will briefly talk about those optimizations that are used in the .NET Framework. Throughout the article, I will use Visual Studio 2013 for all examples.
Link-Time Code Generation
Link-Time Code Generation (LTCG) code generation is a technique for optimizing the entire program optimizations (WPO) for C / C ++ code. The C / C ++ compiler processes each source code file individually and issues the corresponding object file. In other words, the compiler can optimize only a single file, instead of optimizing the entire program. However, some important optimizations may only apply to the entire program. You can use these optimizations only during linking, and not during compilation, because the linker has a complete understanding of the program.If LTCG is enabled (flag
/GL), then the compiler driver ( cl.exe) will only call the front end ( c1.dllor c1xx.dll) and postpone the back end (c2.dll) until the moment of linking. The resulting object files contain C Intermediate Language (CIL), not machine code. Then the linker ( link.exe) is called. He sees that the object files contain CIL code, and calls the back end, which in turn executes WPO and generates binary object files so that the linker can connect them together and form an executable file. The front end also performs some optimizations (for example, folding constants) regardless of whether optimizations are turned on or off. However, all important optimizations are performed by the back end, and they can be controlled using compilation keys.
LTCG allows the back end to perform many optimizations aggressively (using compiler keys
/GLalong with /O1or /O2and /Gw, and also using linker keys/OPT:REFand /OPT:ICF). In this article I will discuss only inlining and COMDAT optimizations. A complete list of LTCG optimizations is provided in the documentation. It is useful to know that the linker can execute LTCG on native, natively managed and purely managed object files, as well as on safe managed object files and safe.netmodules. I will work with a program of two source code files (
source1.cand source2.c) and a header file ( source2.h). Files source1.cand source2.cshown in the listing below, and the header file containing prototypes of all functions source2.c, so simple that it cause I do not.// source1.c
#include // scanf_s and printf.
#include "Source2.h"
int square(int x) { return x*x; }
main() {
int n = 5, m;
scanf_s("%d", &m);
printf("The square of %d is %d.", n, square(n));
printf("The square of %d is %d.", m, square(m));
printf("The cube of %d is %d.", n, cube(n));
printf("The sum of %d is %d.", n, sum(n));
printf("The sum of cubes of %d is %d.", n, sumOfCubes(n));
printf("The %dth prime number is %d.", n, getPrime(n));
}
// source2.c
#include // sqrt.
#include // bool, true and false.
#include "Source2.h"
int cube(int x) { return x*x*x; }
int sum(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += i;
return result;
}
int sumOfCubes(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += cube(i);
return result;
}
static
bool isPrime(int x) {
for (int i = 2; i <= (int)sqrt(x); ++i) {
if (x % i == 0) return false;
}
return true;
}
int getPrime(int x) {
int count = 0;
int candidate = 2;
while (count != x) {
if (isPrime(candidate))
++count;
}
return candidate;
}
The file
source1.ccontains two functions: a function squarethat calculates the square of an integer, and the main function of the program main. The main function calls the square function and all functions source2.cexcept isPrime. The file source2.ccontains 5 functions: cubeto raise an integer to the third power, sumto calculate the sum of integers from 1 to a given number, sumOfCubesto calculate the sum of cubes of integers from 1 to a given number, isPrimeto check the number for simplicity, getPrimeto obtain a prime number with a given number. I skipped error handling because it is not of interest in this article. The code is very simple, but useful. We have several functions that do simple calculations, some of them contain loops. Function
getPrimeis the most complex, because it contains a loop whileinside which calls a function isPrimethat also contains a loop. I will use this code to demonstrate one of the important function inlining compiler optimizations and several additional optimizations. Consider the result of the compiler under three different configurations. If you will deal with the example yourself, then you will need a assembler output file (obtained using the compiler key
/FA[s]) and a map file (obtained using the linker key /MAP) to study the COMDAT optimizations performed (the linker will report them if you enable the keys /verbose:icfand /verbose:ref) . Make sure that all keys are correct and continue reading the article. I will use the C compiler (/TC) so that the generated code is easier to learn, but everything presented in the article is also applicable to C ++ code.Debug configuration
Debug configuration is used mainly because all back end optimizations are turned off if you specify a key/Odwithout a key /GL. In this configuration, the resulting object files contain binary code that exactly matches the source code. You can examine the resulting assembler output files and map file to verify this. The configuration is equivalent to the Debug configuration in Visual Studio.Compile-Time Code Generation Release Configuration
This configuration is similar to the Release configuration (which specifies the keys/O1, /O2or /Ox), but it does not include the key /GL. In this configuration, the resulting object files contain optimized binary code, but the optimization of the level of the entire program is not performed. If you look at the generated assembly listing file for
source1.c, you will notice that two important optimizations have been performed. The first call to the function square, square(n)was replaced by the calculated value during compilation. How did this happen? The compiler noticed that the body of the function is small, and decided to substitute its contents for a call. Then the compiler noticed that a local variable is present in the value calculationnwith a known initial value that did not change between the initial assignment and the function call. Thus, he came to the conclusion that it is safe to calculate the value of the multiplication operation and substitute the result ( 25). The second call function square, square(m)was also zainlaynen, t. E. Functions body was substituted for the call. But the value of the variable m is unknown at the time of compilation, so the compiler could not calculate the value of the expression in advance. Now let's turn to assembly listing file for
source2.c, it is much more interesting. The function call cubein the function sumOfCubeswas inline. This, in turn, allowed the compiler to perform loop optimization (more on this in the "Loop Optimization" section). In functionisPrimeSSE2 instructions were used to convert intto doublewhen calling sqrtand convert from doubleto intwhen getting the result from sqrt. In fact, she sqrtvolunteered once before the start of the cycle. Note that the key /archtells the compiler that x86 uses SSE2 by default (most x86 processors and x86-64 processors support SSE2).Link-Time Code Generation Release Configuration
This configuration is identical to Visiual Studio's Release configuration: optimizations are included and the compiler key/GLis specified (you can also explicitly specify /O1or /O2). Thus, we tell the compiler to generate object files with CIL code instead of assembly object files. This means that the linker will call the back end of the compiler to execute WPO, as described above. We will now discuss several WPOs to show the tremendous benefits of LTCG. The generated assembly code listings for this configuration are available online. While function inlining is enabled (a key
/Obthat is turned on if you turned on optimizations), the key /GLallows the compiler to inline functions defined in other files regardless of the key /Gy(we will discuss it a bit later). Linker Key/LTCGoptional and affects only the linker. If you look at the assembly listing file for
source1.c, you may notice that calls to all functions except scanf_swere inline. As a result, the compiler was able to perform a function calculation cube, sumand sumOfCubes. Only the function was isPrimenot inlined. However, if you manually inlined it in getPrime, then the compiler would still inline getPrimein main.As you can see, function inlining is important not only because function calls are optimized, but also because it allows the compiler to perform many additional optimizations. Inlining usually increases performance by increasing the size of the code. Excessive use of this optimization leads to a phenomenon called code bloat. Therefore, with each call to the function, the compiler calculates the costs and benefits, and then decides whether to inline the function.
Due to the importance of inlining, the Visual C ++ compiler provides great support for it. You can tell the compiler to never inline a set of functions using a directive
auto_inline. You can also tell the compiler the specified functions or methods with__declspec(noinline). You can also mark the function with a keyword inlineand advise the compiler to execute inline (although the compiler may decide to ignore this advice if it considers it bad). The keyword inlinehas been available since the first version of C ++; it appeared in C99. You can use the __inlineMicrosoft compiler keyword for both C and C ++: this is convenient if you want to use older versions of C that do not support this keyword. The keyword __forceinline(for C and C ++) forces the compiler to always inline the function, if possible. And last but not least, you can tell the compiler to deploy a recursive function of a specified or indefinite depth by inlining using the directiveinline_recursion. Note that at present the compiler does not have the ability to control inlining at the place of the function call, and not at the place of its declaration. The key
/Ob0disables inlining completely, which is useful during debugging (this key works in the Debug configuration in Visual Studio). The key /Ob1tells the compiler that as candidates for inlining should be considered only the functions that are marked by a inline, __inline, __forceinline. The key /Ob2works only when specified /O[1|2|x]and tells the compiler to consider all functions for inlining. In my opinion, the only reason to use keywords inlineand __inlineis to control inlining for the key /Ob1.The compiler cannot always inline a function. For example, during a virtual call to a virtual function: a function cannot be inlined, because the compiler does not know exactly which function will be called. Another example: a function is called through a pointer to a function instead of a call through its name. You should try to avoid such situations so that inlining is possible. A complete list of all such conditions can be found on MSDN.
Function inlining is not the only optimization that can be applied at the program level as a whole. Most optimizations work most effectively at this level. In the remainder of this article, I will discuss a specific class of optimizations called COMDAT optimizations.
By default, during compilation of the module, all code is stored in a single section of the resulting object file. The linker works at the section level: it can delete sections, join them, or reorder. This prevents him from performing three very important optimizations (two-digit percent) that help reduce the size of the executable file and increase its performance. The first removes unused functions and global variables. The second collapses identical functions and global constants. The third reorders functions and global variables so that, at runtime, transitions between physical memory fragments are shorter.
To enable these linker optimizations, you should ask the compiler to pack functions and variables in separate sections using compiler keys
/Gy(linking the level of functions) and /Gw(optimization of global data). These sections are called COMDATs. You can also mark a given global variable using __declspec( selectany)to tell the compiler to package the variable in COMDAT. Further, using the linker key, /OPT:REFyou can get rid of unused functions and global variables. The key /OPT:ICFwill help to collapse identical functions and global constants (ICF is Identical COMDAT Folding). The key /ORDERwill force the linker to place COMDATs in the resulting images in a specific order. Note that all linker optimizations do not need a key /GL. The keys /OPT:REFand /OPT:ICFshould be turned off during debugging for obvious reasons.You should use LTCG whenever possible. The only reason for abandoning LTCG is because you want to distribute the resulting object files and library files. Recall that they contain a CIL code instead of a machine code. CIL code can only be used by the compiler and linker of the same version with which they were generated, which is a significant limitation, because developers will have to use the same version of the compiler to use your files. In this case, if you do not want to distribute a separate version of object files for each version of the compiler, then you should use code generation instead. In addition to the version limit, the object files are many times larger than the corresponding assembler object files. However,
Loop optimization
The Visual C ++ compiler supports several types of loop optimizations, but we will discuss only three: loop unrolling, automatic vectorization, and loop-invariant code motion. If you modify the code fromsource1.cso that sumOfCubesm will be passed instead of n, then the compiler will not be able to calculate the value of the parameters, you will have to compile the function so that it can work for any argument. The resulting function will be well optimized, because of which it will be large, which means the compiler will not inline it. If you copy the code with the key
/O1, then no optimizations sumOfCubeswill be applied to. Key Compilation/O2will give speed optimization. In this case, the code size will increase significantly, sumOfCubesbecause the cycle inside the function will be unwound and vectorized. It is very important to understand that vectorization will not be possible without inlining the cube function. Moreover, unwinding the cycle will also not be so effective without inlining. A simplified graphical representation of the final code is shown in the following picture (this graph is valid for both x86 and x86-64). In this diagram, a green rhombus indicates an entry point, and red rectangles indicate an exit point. Blue rhombs represent conditional statements that will be executed when a function is executed
sumOfCubes. If SSE4 is supported and x is greater than or equal to 8, then SSE4 instructions will be used to perform 4 multiplications at a time. The process of performing the same operation for several variables is called vectorization. The compiler also unwinds this loop twice. This means that the body of the loop will be repeated twice at each iteration. As a result, the performance of eight operations of multiplication will occur in 1 iteration. If xless than 8, then the code without optimizations will be used to perform the function. Please note that the compiler inserts three exit points instead of one - thus reducing the number of transitions.Unwinding of cycles is carried out by repeating the body of the cycle several times inside one iteration of a new (unwound) cycle. This increases productivity, because the operations of the cycle itself will be performed less frequently. In addition, it allows the compiler to perform additional optimizations (for example, vectorization). The disadvantage of unwinding loops is the increase in the amount of code and the load on the registers. But despite this, depending on the body of the cycle, such optimization can increase productivity by two-percent.
Unlike x86 processors, all x86-64 processors support SSE2. Moreover, you can take advantage of the AVX / AVX2 instructions on the latest x86-64 processors from Intel and AMD with a key
/arch. By indicating /arch:AVX2, you tell the compiler to also use the FMA and BMI instructions.Currently, the Visual C ++ compiler does not allow you to control loop unwinding. But you can influence it with the help of the
__forceinlinedirective loopwith the option no_vector(the latter turns off the auto-vectorization of the given cycles). If you look at the generated assembler code, you may notice that additional optimizations can be applied to it. But the compiler still did an excellent job anyway and there is no need to spend much more time analyzing to apply minor optimizations.
The function is
someOfCubesnot the only one whose loop has been unwound. If you modify the code and pass it mto the function suminstead n, the compiler will not be able to calculate its value and it will have to generate the code, the loop will be unwound twice.In conclusion, we look at such an optimization as the removal of cycle invariants. Take a look at the following code:
int sum(int x) {
int result = 0;
int count = 0;
for (int i = 1; i <= x; ++i) {
++count;
result += i;
}
printf("%d", count);
return result;
}
The only change we made is to add an additional variable, which is incremented at each iteration, and at the end it is displayed on the console. It is easy to see that this code is easily optimized by moving the incremented variable out of the loop: just assign a value to it
x. This optimization is called loop-invariant code motion. The word “invariant” shows that this technique is applicable when part of the code does not depend on expressions that include a loop variable. But here's the catch: if you apply this optimization manually, the resulting code may lose performance in certain conditions. Can you say why? Imagine a variable
xnot positive. In this case, the loop will not be executed, and in the non-optimized version the variable countwill remain untouched. The manually optimized version will perform an unnecessary assignment from x to count, which will be performed outside the loop! Moreover, if xnegative, then the variable countwill receive the wrong value. Both humans and compilers are subject to similar traps. Fortunately, the Visual C ++ compiler is smart enough to figure this out and test the loop condition before assignment, improving performance for all possible values x.In conclusion, I want to say that if you are not a compiler and not an expert on compiler optimizations, then you should avoid such transformations of your code that make it look like it works faster. Keep your hands clean and trust the compiler to optimize your code.
Optimization Control
In addition to the keysO1, /O2, /Ox, you can control the specific function using the directive optimize:#pragma optimize( "[optimization-list]", {on | off} )
In this example, the optimization list may be empty or may contain one or more values of the set:
g, s, t, y. These correspond to the keys /Og, /Os, /Ot, /Oy. An empty list with a parameter
offturns off all optimizations, regardless of the compiler keys. An empty list with a parameter onapplies the above compiler keys. The key
/Ogallows you to perform global optimizations that can only be performed inside the function being optimized, and not in the functions that call it. If LTCGenabled, it /Ogallows you to do WPO. Directive
optimizevery useful in cases where you want different functions to be optimized in different ways: some in size and others in speed. However, if you really want to have control over optimizations of this level, you should look towards profile-guided optimizations (PGOs), which are code optimization using a profile that stores behavior information recorded during the execution of the instrumental version of the code. The compiler uses the profile in order to provide better solutions during code optimization. Visual Studio introduces special tools to apply this technique to both native and managed code.Optimizations in .NET
In .NET, there is no linker that would be involved in the compilation model. Instead, there is a source compiler (C # compiler) and a JIT compiler. Only minor minor optimizations are performed on the source code. For example, at this level you will not see function inlining or loop optimizations. Instead, optimization data is performed at the JIT compilation level. The JIT compiler prior to .NET 4.5 did not support SIMD. But the JIT compiler from .NET 4.5.1 (called RyuJIT) supports SIMD.What is the difference between RyuJIT and Visual C ++ in terms of optimization capabilities? Due to RyuJIT running at runtime, it can perform optimizations that Visual C ++ is not capable of. For example, right at runtime, he can understand that an expression in a conditional statement will never take value
truein the current running version of the application, and then apply the appropriate optimization. RyuJIT can also use knowledge of the processor architecture used at runtime. For example, if the processor supports SSE4.1, then the JIT compiler uses only SSE4.1 instructions to implement the functionsubOfCubes, which will make the generated code more compact. But you need to understand that RyuJIT cannot spend a lot of time on optimization, because the time of JIT compilation affects the performance of the application. But the Visual C ++ compiler can spend a lot of time analyzing the code to find optimization opportunities to improve the final executable. With Microsoft's great new technology called .NET Native, you can compile managed code into self-contained executables using Visual C ++ optimizations. Currently, this technology only supports applications from the Windows Store. To date, the ability to control optimized managed code is limited. C # and Visual Basic compilers only allow on or off optimizations using the key
/optimize. To control JIT optimizations, you can apply the attribute System.Runtime.CompilerServices.MethodImplto the desired method with the option from MethodImplOptions. The option NoOptimizationturns off optimizations, the option NoInliningprohibits inline method, and the option AggressiveInlining(available since .NET 4.5) gives the JIT compiler a recommendation that he should inline this method.