Getting Ready or DR on Nutanix: Asynchronous Replication

The topic of building fault-tolerant data centers using Nutanix hyperconverged systems is quite extensive, therefore, in order not to skip to the top, on the one hand, and not to go into boring, on the other hand, we will divide it into two parts. In the first we consider the theory and "classical" methods of replication, in the second - our new feature, the so-called Metro Availability, the ability to build a synchronously-replicated metro cluster (metropolitan area, large city scale, and even more) at a distance of up to 400 kilometers between data centers.
Today it is already very rare to “start from the beginning” and explain why a backup data center is needed at all. Today, when, on the one hand, the volumes and value of information stored in data centers have grown, and on the other hand, many solutions for organizing distributed data storage and processing have become cheaper and widespread, you usually no longer need to explain why a company needs a backup data center. But you still have to look at how it is and how it is needed.
Nutanix, as a young company and emerging “on the edge of needs”, immediately focused on the need for a modern data center to have a backup data center and the right, multi-functional replication. That is why, even in the youngest license, which comes with every Nutanix system, and is included in the price (we call it Starter), already have full-featured replication tools. This distinguishes Nutanix from many traditional systems in which replication often comes as an option and costs extra, often quite substantial money.
Not so with us. Any Nutanix already has bidirectional asynchronous replication. Bidirectionality, by the way, which allows you to use both data centers in the active-active mode (and not the active-reserve mode, as usual), is also not found among all vendors.
In the world of replication methods, it is customary to distinguish between two basic principles of their work, the so-called “synchronous” and “asynchronous” replication.
Synchronous replication is easy. Each disk write operation is not considered complete until the same write operation is transferred and completed on the disks of the remote system. The data block has arrived, the block has written to the disks of the local storage device, but the application has not yet received a response “ready, recorded!”. In the meantime, the data block was transferred to the remote system, and the process of recording this block was started on it. And only after the block is recorded on the remote system, it reports on success, and then the system informs the application, the block of which was recorded, the local, first system about the completion of the recording.

The benefits of synchronous replication are obvious. Data is written to the local and remote systems in the safest possible way; the copy in the backup data center is always completely identical to the copy in your local data center. However, there is a minus, although it is one, it is huge.
If you have two systems connected by synchronous replication, then the speed of the active, local for your application, system will be equal to the speed of the data channel between the local and remote systems. Because until the remote system receives a data block for writing and writes it, your local system will stand and wait. And if from the application to the disks of the local system you have 16G FC, and from the local system to the remote one - 1GB Ethernet via the provider's channel through several routers, then writing to local disks will not exceed the speed of this Gigabit Ethernet channel.
If this option does not suit you, then you should look at asynchronous replication.
Asynchronous replication, on the contrary, has many drawbacks, but one plus. But big. :)
With asynchronous replication, recording occurs on the drives of the local device, regardless of the state of the remote system, and then, with the established frequency, they are transferred to this remote system, copying not the operations, but simply the state of the drives of the local data source system. This is more beneficial in terms of performance and channel utilization. Often, for example, in the case when the application constantly reads and changes the active data area, it is much easier to transfer the result once than hundreds and thousands of sequential changes. Alas, this is a big plus accompanied by the fact that an asynchronous copy, strictly speaking, never fully corresponds to the data of the active system, always lagging behind it for those few minutes that takes a replication cycle.
However, in practice, asynchronous replication is widely used. What to do with the "inaccuracy of the copy"? Well, first of all, you can think and evaluate that the system’s write performance and low latency values are more important for you than the possible loss of 15 minutes of data changes (and it often happens). Or, in addition to general asynchronous replication for all applications, use some means of data protection at the level of specific applications, and not data storage in general (for example, various tools that Microsoft products have, Availability Groups in MS Exchange, or similar tools MS SQL Server).
Basically, Nutanix did not invent anything new here. On Nutanix systems, there is both synchronous, with the help of which the so-called Metro Availability is implemented, and asynchronous replication from one Nutanix cluster, in one DC, to another, usually in another DC. Asynchronous replication is done by transferring “snapshots” of disk storage, while synchronous replication is a bit more complicated and curious.
A few words about some terminological quotation.
The word “cluster”, used today by everyone in a row, can lead to some difficulty, if not misconception. The fact is that in the IT industry today the word "cluster" is used to refer not only to very different things in nature, but also mainly applied to a structure that provides high availability. And so often the word “cluster” is used to mean exactly and only “HA-cluster”, that many have the impression that “cluster” = “fault-tolerant cluster”, that's all.
This is not always the case.
First, what is a “cluster”?
A cluster is a combination of some elements into a certain general entity of a higher order, existing and managed as an independent unit. As you can see, in this definition there is nothing about fault tolerance. It may or may not exist, and a cluster is not always an “HA cluster”.
I often have to answer the question: “Is it possible for us to scatter the nodes of the Nutanix cluster on different sites, so we will have reliability?” The
answer here is this: in theory, yes, you can (of course, do not forget that you need to stretch the sites also a pair of 10G channels for intra-cluster communication, but even this can be done today), but in practice it is not recommended, and in general “you yourself don’t want it”. Why?
Let's imagine, for the sake of analogy, that a Nutanix cluster is a group of disks in a FC array connected array. Here we have site A, and on it there is a JBOD shelf and there are a dozen drives on it in FC, and site B, with the same shelf and a dozen drives, all included in the shared FC network. And we decide to make a RAID group from all these twenty disks into a RAID-5 or 6. In principle, in theory, we can, why not. We see each JBOD as a separate FC device, merge. But then the question is what will happen to the RAID, if an excavator passes through us, something happens to the network between the sites?
Nothing good. Losses of half, or even at least a third of the participants at once, most likely will not withstand either the RAID, or, in a similar situation, the Nutanix cluster.
That is why, talking with users about clusters and about Nutanix, we have to minimize confusion, clarifying that here we say: “Nutanix cluster”, and here by “cluster” we mean “VMware HA-cluster”, and here - Real Application Cluster (RAC ) Oracle databases. And these will be all different clusters, often arranged hierarchically one above the other, and this is completely normal.
Thus, we cannot scatter the nodes of one Nutanix cluster for sites to ensure fault tolerance. But we can arrange the nodes of one “Nutanix cluster” on one site, the other (the “Nutanix cluster”) nodes on another site, and then combine them into replicated relationships in the direction we need, for example, from the main DC to the backup, from the head office to branches (and vice versa), or even completely in both directions.
Moreover, if it is a “synchronous” metro cluster, then on top of such a synchronously replicated pair of clusters, which, I recall, can be located at a distance, ideally, up to 400 kilometers (or, speaking the technical language, we need between IP sites roundtrip the package did not exceed 5ms), and then on top of this metro-pair we can create one VMware cluster, inside which the virtual machines will restart and migrate as on a common, single disk storage, according to the DRS policies that we will write. But I will tell you more about this in the next series.
For asynchronous data replication from one site to another, Nutanix uses the internal Vmcaliber snapshot mechanism. When they are used, only the difference part, a kind of diff of the contents of the disk container volume, is transmitted over the data channel between the two sites. The diff from the previous transmission is taken from the source system, then it is sent to the remote replication recipient site, and there it rolls. At present, Nutanix's asynchronous replication transmission interval is 15 minutes. That is, in the worst case, you can lose only 15 minutes of data, while, unlike synchronous replication, the process does not reduce performance and does not increase latency when working with data.
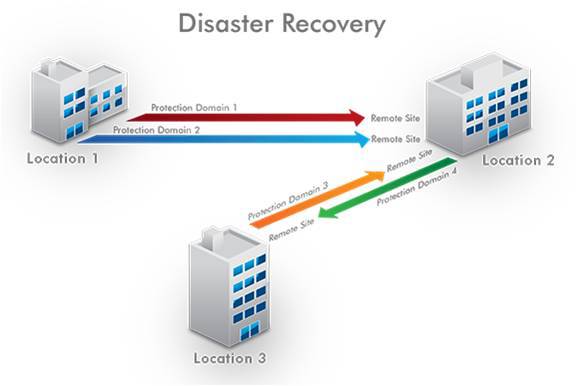
Thus, every 15 minutes on the DR-site the diff of the disks of the main system leaves, and there it automatically expands and rolls, maintaining its relevance. If you lose the system in the “main” DC, in the worst case, you will lose data changes in 15 minutes.
But what if the fifteen-minute lag is too much and synchronous replication is needed?
To do this, you can use our technology Metro Availability, which is the next post.