How our code works. Server architecture of one project
 It so happened that by the age of thirty I changed my work only once and did not have the opportunity to learn from my own experience how various projects have web projects designed for high response speed and a large number of users.
It so happened that by the age of thirty I changed my work only once and did not have the opportunity to learn from my own experience how various projects have web projects designed for high response speed and a large number of users.I apologize in advance if my tone seems to someone mentoring - I have no ambition to educate anyone, the maximum that this post claims to be is a story about the architecture of the server part of one real project. In my city, which was not the most developed from the point of view of software development, I have met more than once or twice developers who were very interested in our experience in building the server side of web applications, so guys, I write this post largely because of you, and I sincerely hope that I will succeed in satisfying your interest.
Like any other hired developer, I am not the owner of the code and cannot demonstrate the listings of the working draft, but it will also be wrong to talk about how the code base is structured without listings. Therefore, I have no choice but to “come up with” an abstract product and, through its example, go through the entire process of developing the server side: from obtaining TK by programmers to implementing storage services, using the practices adopted by our team and drawing parallels with how our real project.
Moneyflow. Formulation of the problem
A virtual customer wants to create a cloud system for accounting for the expenditure of funds from the family budget. He already came up with her name - MoneyFlow and drew UI mockups. He wants the system to have web, android and iOS versions, and the application has a high (<200 ms) response speed for any user actions. The customer is going to invest serious funds in the promotion of the service and promises an avalanche-like growth of users immediately after launch.
Software development is an iterative process, and the number of iterations during development mainly depends on how accurately the task was originally set. In this sense, our team was lucky, we have two wonderful analysts and an equally wonderful designer-layout designer (yes, such luck also happens), so by the time we start we usually have the final version of the ToR and the finished layout, which greatly simplifies life and frees us developers from the headache and the development of extrasensory skills for reading customer thoughts at a distance. The virtual customer in my person didn’t let us down either and provided UI mock-ups as a description of his vision of the service. I apologize in advance to the experts in building the UI, pixel-perfectionists and just people with a developed sense of beauty for the eerie graphics layouts and no less terrible their usability. My only (albeit weak) excuse is only that it is more a prototype than a real project, but I still hide these layouts under the cat.
The idea of the service is simple - the user enters the costs into the system, on the basis of which reports are constructed in the form of pie charts.
Layout 1. Adding Flow
Layout 2. Sample Report
Categories of expenses and types of reports are predefined by the customer and are the same for all users. The web version of the application will be a SPA written in Angular JS and a server API on ASP.NET, from which the JS application receives data in JSON format. We will build the service on the same technology stack on which our real application is built. This stack looks something like this.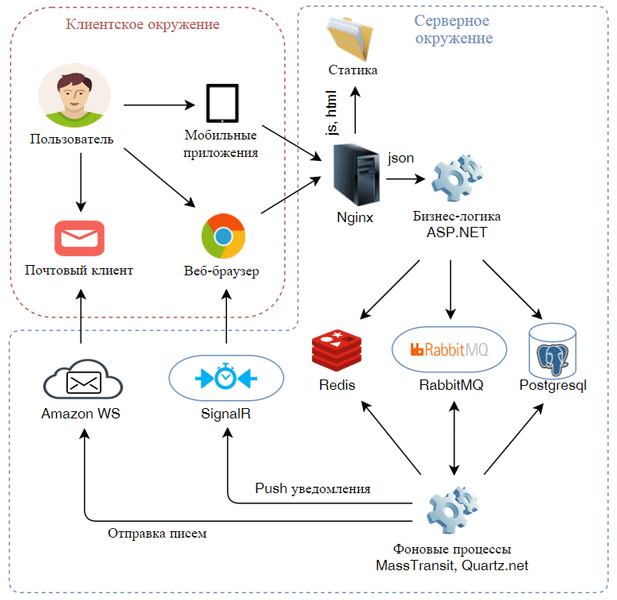
The interaction contract between the client and server parts of the application
Our team develops new functionality of the server and client parts of the service in parallel. After familiarizing ourselves with the ToR, we first determine the interface by which the frontend and backend interact. It so happened that our API is built as RPC, not REST, and when it is defined (API), we are primarily guided by the principle of the necessity and sufficiency of the transmitted data. Let's try to figure out by mock-ups what information a client application may need from the server side.
Layout 3. List of operations
We have only three columns in the list layout - the amount, description and the day the operation was completed. In addition, the client application will need the category to which the expense transaction relates to display the list, and Id, so that you can go to the editing screen with a click from the list.
An example of the result of calling the server method for a page with a list of committed expenditure operations.
[
{
"id":"fe9a2da8-96df-4171-a5c4-f4b00d0855d5",
"sum":540.0,
"details":"Покупка карточки для метро",
"date":"2015-01-25T00:00:00+05:00",
"category":”Transport”
},
{
"id":"a8a1e175-b7be-4c34-9544-5a25ed750f85",
"sum":500.0,
"details":"Поход в кино",
"date":"2015-01-25T00:00:00+05:00",
"category":”Entertainment”
}
]
Now let's look at the layout of the edit page.
Layout 4. Editing screen
To display the edit page, the client application will need a method that returns the next JSON string.
{
"id":"23ed4bf4-375d-43b2-a0a7-cc06114c2a18",
"sum":500.0,
"details":"Поход в кино",
"date":"2015-01-25T00:00:00+05:00",
"category":”Entertainment”,
"history":[
{
"text":"отредактирована в веб версии приложения",
"created":"2015-01-25T16:06:27.318389Z"
},
{
"text":"создана в веб версии приложения",
"created":"2015-01-25T16:06:27.318389Z"
}
]
}Compared with the model of the operation requested in the list, information on the history of creating / changing the record was added to the model on the edit page. As I already wrote, we are guided by the principle of necessity and sufficiency and do not create a single common data model for each entity that could be used in the API in every method associated with it. Yes, in the MoneyFlow application, the difference in the models of the list and the editing page is only in one field, but in reality such simple models can only be found in books, like “How to learn to program in C ++ at the expert level in 7 days”, with a kindly smiling fat man in a sweater on the cover. Real projects are much more complicated
The JSON objects provided by the server are, of course, serialized DTO objects, so in the server code we will have classes that define models for each method from the API. In accordance with the DRY principle, these classes, if possible, are organized in a hierarchy.
Classes defining the MoneyFlow API contract for list screens, creating and editing operations.
//модель расхода для слоя создания
public class ChargeOpForAdding
{
public double Sum { get; set; }
public string Details { get; set; }
public ECategory Category { get; set; }
}
//модель расхода для списка
public class ChargeOpForList : ChargeOpForAdding
{
public Guid Id { get; set; }
public DateTime Date { get; set; }
}
//модель расхода для слоя редактирования
public class ChargeOpForEditing : ChargeOpForList
{
public List History { get; set; }
}
After the contract is defined, front-end developers create mocks for server methods that still do not exist and go on to do Angular JS magic. Yes, we have a very thick and very wonderful client, with the respected iKbaht , Houston and several other no less wonderful anonymous Habrausers. And it would be completely ugly from the side of server developers if our beautiful, powerful JS application would work on a slow API. Therefore, at the backend, we try to develop our API as fast as possible, performing most of the work asynchronously and building the data storage model as readable as possible.
We break the system into modules
If we consider the MoneyFlow application in terms of functionality, we can distinguish two different modules in it - this is a module for working with expenses and a reporting module. If we were sure that the number of users of our application would be small, we would build a reporting module directly on top of the expense module. In this case, we would have, for example, a stored procedure that would build for the user a report for the year directly on the basis of the costs incurred. Such a scheme is very convenient in terms of data consistency, but, unfortunately, it also has a drawback. With a sufficiently large number of users, the table with the cost data will become too large for our stored procedure to work out quickly, counting on the fly, for example, how much money the user spent on transport for the year. Therefore,
Software development is an iterative process. If we consider a scheme with a single data model for expenses and reports as the first iteration, then reporting to a separate denormalized database is already iteration number two. If theorizing further, then we can fully find the direction for the following improvements. For example, how often do we have to update reports for the last month or year? Probably, in early January, users will enter information about purchases made at the end of December into the system, but most of the data coming into the system will relate to the current calendar month. The same is true for reporting, users will be more often interested in reports for the current month. Therefore, in the third iteration, if the effect of using a separate repository for reports will be offset by an increase in the number of users, You can optimize the storage system by transferring data for the current period to a faster storage located, for example, on a separate server. Or using storage like Redis, which stores its data in RAM. If we draw an analogy with our real project, then we are at iteration 2.5. Faced with a drop in performance, we optimized our storage system by transferring the data of each module to independent databases, and we also transferred some of the frequently used data to Redis.
According to legend, the MoneyFlow project is just getting ready to launch, so we will leave it at iteration number two, leaving room for future improvements.
Synchronous and Asynchronous Execution Stacks
In addition to increasing productivity by storing data in the most readable form, we try to do most of the work invisibly to the user in the asynchronous execution stack. Each time, when a request comes to us from the side of the client application, we look at how much of the work needs to be done before the response is returned to the client. Very often, we return the answer almost immediately, performing only the necessary part, such as checking the validity of the received data, shifting most of the work to asynchronous processing. It works as follows.

As an asynchronous execution stack, we call the background processes in the team that are busy processing the message queues coming from the server. The device of our background handler I will describe in detail below, but for now we’ll look at an example of interaction between the client application and the server API when clicking on the “Add” button from layout 1. For those who are too lazy to scroll - when you click on this button, a new expense will be added “Go to the cinema ”: 500 rubles per system.
What actions must be performed each time a new flow rate is introduced into the system?
- Check input validity
- Add information about the transaction to the expense accounting module
- Update the corresponding report in the reporting module
Which of these actions should we have time to complete before we report to the client about the successful processing of the operation? It is absolutely certain that we must make sure that the data transmitted by the client application is correct, and return an error if it is not so. We can also add a new record to the expense accounting module (although we can transfer this to the background process), but it will be completely unjustified to update the reports synchronously, forcing the user to wait until each report, and there may be several, will be updated.
Now the code itself. For each request received from the client part, we create an object responsible for its correct processing. The object processing the request to create a new spending transaction would look like this with us.
//Объект, обрабатывающий
//запрос создания расходной операции
public class ChargeOpsCreator
{
private readonly IChargeOpsStorage _chargeOpsStorage;
private readonly ICategoryStorage _categoryStorage;
private readonly IServiceBusPublisher _serviceBusPublisher;
public ChargeOpsCreator(IChargeOpsStorage chargeOpsStorage, ICategoryStorage categoryStorage, IServiceBusPublisher pub)
{
_chargeOpsStorage = chargeOpsStorage;
_categoryStorage = categoryStorage;
_serviceBusPublisher = pub;
}
public Guid Create(ChargeOpForAdding op, Guid userId)
{
//Проверяем входные данные
CheckingData(op);
//Работу по внесению операции в
//модуль расходов проведем синхронно
var id = Guid.NewGuid();
_chargeOpsStorage.CreateChargeOp(op);
//Передаем часть работы в фоновый процесс
_serviceBusPublisher.Publish(new ChargeOpCreated() {Date = DateTime.UtcNow, ChargeOp = op, UserId = userId});
return id;
}
//Проверяем входные данные
private void CheckingData(ChargeOpForAdding op)
{
//Сумма должна быть больше нуля
if (op.Sum <= 0)
throw new DataValidationException("Сумма должна быть больше нуля");
//Расходная операция должна относиться к реально существующей категории
if (!_categoryStorage.CategoryExists(op.Category))
throw new DataValidationException("Переданной категории не существует");
}
}
The ChargeOpsCreator object checked the correctness of the input data and added the perfect operation to the cost accounting module, after which the Id of the created record was returned to the client application. The process of updating reports is performed in the background process, for this we sent a message ChargeOpCreated to the queue server, the processor of which will update the report for the user. Messages sent to the service bus are simple DTO objects. This is what the ChargeOpCreated class looks like, which we just sent to the service bus.
public class ChargeOpCreated
{
//когда была совершена операция
public DateTime Date { get; set; }
//информация, пришедшая с клиентского приложения
public ChargeOpForAdding ChargeOp{ get; set; }
//пользователь, внесший расходную операцию
public Guid UserId { get; set; }
}
Layering an application
Both execution stacks (synchronous and asynchronous) at the assembly level are divided into three layers — the application layer (execution context), the business logic layer, and data storage services. Each layer has a strictly defined area of responsibility.
Synchronous stack. Application layer
In a synchronous stack, the execution context is an ASP.NET application. His area of responsibility, apart from the usual actions for any web server, such as receiving requests and serializing / deserializing data, is small. It:
- user authentication
- instantiation of business logic objects using an IoC container
- error handling and logging
All of the code in our controllers comes down to creating business logic objects using the IoC container that are responsible for further processing of requests. This is what the controller method will look like, called to add a new expense in the MoneyFlow application.
public Guid Add([FromBody]ChargeOpForAdding op)
{
return Container.Resolve().Create(op, CurrentUserId);
}
The application layer in our system is very simple and lightweight, in a day we can change the execution context of our system from ASP.NET MVC (as we historically have it) to ASP.NET WebAPI or Katana.
Synchronous stack. Business logic layer
The business logic layer in the synchronous stack here consists of many small objects that process incoming user requests. The ChargeOpsCreator class, which I listed above, is just an example of such an object. The creation of such classes fits well with the principle of sole responsibility and each such class can be fully tested with unit tests due to the fact that all its dependencies are injected into the constructor.
The tasks of the business logic layer in our application include:
- validation of incoming data
- user authorization (checking the user’s rights to perform an action)
- interaction with the data storage layer
- generating DTO messages for sending to the client application
- sending messages to the queue server for subsequent asynchronous processing
It is important that we check the input data for correctness only in the business logic layer of the synchronous stack. We consider all other modules (queue resolvers, storage services) to be a “demilitarized” zone from the point of view of checks, with very few exceptions.
In a real project, the objects of the business logic layer are separated from the controllers, where they are instantiated, by interfaces. But this separation did not bring us any special practical benefit, but only complicated the IoC section of the container in the configuration file.
Asynchronous stack
In an asynchronous stack, an application is a service that parses message queues arriving at a server. The service itself does not know which queues it should connect to, what types of messages and how it should process, and how many threads it can allocate to process messages of this or that queue. All this information is contained in the configuration file loaded by the service at startup.
An example of a service config (pseudocode).
<Очередь Имя = “ReportBuilder” Потоков = “10”>
<Обработчики_сообщений>
<Тип=“ChargeOpCreatedHandler” Макс_Число_Попыток=”2” Таймаут_между_попытками=”200” Уровень_логирования=”CriticalError” … />
/* еще одна очередь на 5 потоков*/
<Очередь Имя = “MailSender” Потоков = “5”>
...
The service at startup reads the configuration file, checks that there is a queue on the message server with the name ReportBuilder (if not, it creates it), checks for the existence of a routing that sends messages of the ChargeOpCreated type to this queue (if not, it sets up routing itself), and starts processing Messages that fall into the ReportBuilder queue by running the appropriate handlers for them. In our case, this is the only handler of the ChargeOpCreatedHandler type (about handlers objects a little lower). Also, the service will understand from the configuration file that it can allocate up to 10 threads for parsing messages of the “ReportBuilder” queue, that in case of an error in the operation of the ChargeOpCreatedHandler object, the message should return to the queue with a timeout of 200ms, and when the handler falls again, the message should go to the log marked “CriticalError” and some other similar parameters. This gives us a wonderful opportunity, on the fly, without making changes to the code, to scale the queue resolvers by running additional services on the backup servers in case of messages accumulating in any queue, indicating in the config file which queue it should parse, which is very , very comfortably.
The queue parsing service is a wrapper over the MassTransit library ( the project itself , an article on the hub ) that implements the DataBus pattern over the RabbitMQ queue server. But a programmer writing in a layer of business logic should not know anything about this, all the infrastructure that he is concerned with (queue server, storage key / value, DBMS, etc.) is hidden from him by an abstraction layer. Probably, many saw the post “How two programmers baked bread”about Boris and Marcus, using diametrically opposed approaches to writing code. Both of us would be suitable: Marcus would develop business logic and a layer working with data, and Boris would work with us on infrastructure, the development of which we try to conduct at a high level of abstraction (sometimes it seems to me that even Boris would approve our code) . When developing business logic, we are not trying to build objects in a long hierarchy, creating a large number of interfaces, we are rather trying to comply with the KISS principle, leaving our code as simple as possible. Here, for example, in MoneyFlow, the ChargeOpCreated message handler will look like we have already carefully registered it in the configuration of the ReportBuilder service parsing the queue.
public class ChargeOpCreatedHandler:MessageHandler
{
private readonly IReportsStorage _reportsStorage;
public ChargeOpCreatedHandler(IReportsStorage reportsStorage)
{
_reportsStorage = reportsStorage;
}
public override void HandleMessage(ChargeOpCreated message)
{
//Обновляем отчет
_reportsStorage.UpdateMonthReport(userId, message.ChargeOp.Category, message.Date.Year, message.Date.Month, message.ChargeOp.Sum);
}
}
All handler objects are descendants of the abstract MessageHandler class, where T is the type of the parsed message, with the only abstract HandleMessage method overloaded in the descendants.
public abstract class MessageHandler : where T : class
{
public abstract void HandleMessage(T message);
}
After receiving the message from the queue server, the service creates the desired handler object using the IoC container and calls the HandleMessage method, passing the received message as a parameter. To leave the opportunity to test the behavior of the handler in isolation from its dependencies, all external dependencies, while ChargeOpCreatedHandler is only a service for storing reports, are injected into the constructor.
As I already wrote, we are not engaged in checking the correctness of the input data when processing messages - this should be done by the business logic of the synchronous stack and not processing errors - this is the responsibility of the service in which the processor was launched.
Error handling in the asynchronous execution stack
Our reporting module is more suitable for determining eventual consistency than for determining strong consistency), but it still guarantees the ultimate data consistency in the report module for any possible system failures. Imagine a server with a database storing reports has crashed. It is clear that in the case of binary clustering, when each database instance is duplicated on a separate server, this situation is practically excluded, but still imagine that this happened. Clients continue to make their expenses, messages about them appear in the queue server, but the parser responsible for updating reports cannot access the database server and crashes with an error. According to the service config above, after a crash on a ChargeOpCreated message, the same message will be sent back to the queue server after 200ms, after the second attempt (also unsuccessful), the message will be serialized and stored in a special storage of dropped messages, which in our project is combined with logs. After the database server rises, we can take all messages that fell during processing from the logs and send them back to the queue server (we do this manually), thereby bringing the data of the report module to a consistent state. But all this imposes an obligation on programmers to write code in queue message handler objects according to the atomic principle. The handler should either work completely or fall immediately. Alternatively, it can also be “idempotent,” that is, having completed part of the work and having fallen, it should understand, when reprocessing the message, what work it has already completed, and not try to do it again. we can take all messages that fell during the processing of messages from the logs and send them back to the queue server (we do this manually), thereby bringing the data of the report module to a consistent state. But all this imposes an obligation on programmers to write code in queue message handler objects according to the atomic principle. The handler should either work completely or fall immediately. Alternatively, it can also be “idempotent,” that is, having completed part of the work and having fallen, it should understand, when reprocessing the message, what work it has already completed, and not try to do it again. we can take all messages that fell during the processing of messages from the logs and send them back to the queue server (we do this manually), thereby bringing the data of the report module to a consistent state. But all this imposes an obligation on programmers to write code in queue message handler objects according to the atomic principle. The handler should either work completely or fall immediately. Alternatively, it can also be “idempotent,” that is, having completed part of the work and having fallen, it should understand, when reprocessing the message, what work it has already completed, and not try to do it again. The handler should either work completely or fall immediately. Alternatively, it can also be “idempotent,” that is, having completed part of the work and having fallen, it should understand, when reprocessing the message, what work it has already completed, and not try to do it again. The handler should either work completely or fall immediately. Alternatively, it can also be “idempotent,” that is, having completed part of the work and having fallen, it should understand, when reprocessing the message, what work it has already completed, and not try to do it again.
Data storage layer
We have a common data storage layer for asynchronous and synchronous execution stacks. For a business logic developer, a storage service is simply an interface with methods for retrieving and modifying data. Under the interface is a service that completely encapsulates access to the data of a particular module. When designing service interfaces, we try, if possible, to follow the CQRS concept - each method we have is either a team that performs an action or a request that returns data in the form of DTO objects, but not simultaneously. We do this not to split the storage system into two independent structures for reading and writing, but rather for the sake of order.
No matter how we reduce the response time, performing most of the work asynchronously, a poorly designed storage system can cross out all the work done. I did not accidentally leave a description of how the storage layer is arranged in our project at the very end. We made it a rule to develop storage services only after the implementation of objects of the business logic layer was completed, so that when designing database tables we understand exactly how the data from these tables will be used. If during the development of business logic we need to get some information from the storage layer, we add to the interface that hides the implementation of the service a new method that returns data in a form convenient for business logic. In our company, it is business logic that defines the storage interface, but not the other way around.
Here is an example of a report storage service interface that was defined when developing the business logic of the MoneyFlow application.
public interface IReportsStorage
{
//метод для получения отчета. вернет json в готовом для передачи на клиент виде
string GetMonthReport (Guid userId, int month, int year);
//метод обновляет отчет за конкретный месяц
void UpdateMonthReport(Guid userId, ECategory category, int year, int month, double sum);
}
For data storage we use the Postgresql relational database. But this of course does not mean that we store data in a relational form. We make it possible to scale with sharding and design tables and queries to them according to canons specific to sharding: we do not use join-s, we build queries on primary keys, etc. When building the MoneyFlow report repository, we will also leave the opportunity to transfer some of the reports to another server, if it is needed later, without rebuilding the table structure. How we will do sharding - using the built-in mechanism for physical separation of tables ( partitioning) or by adding a shard manager to the report storage service - we will decide when the need arises for sharding. In the meantime, we should concentrate on designing the structure of the table, which would subsequently not interfere with sharding.
Postgresql has some great NoSQL data types like json and the lesser known but no less wonderful hstore. The report that the client application needs should be a json string. Therefore, it would be logical for us to use the built-in json type for storing reports and give it to the client as is, without spending resources on the DB Tables-> DTO-> json serialization chain. But, to once again promote hstore, I will do the same with the only difference being that inside the database the report will lie in the form of an associative array, for the storage of which the hstore type is intended.
To store reports, one table with four fields will be enough for us:
| Field | What does it mean |
| id | user ID |
| year | reporting year |
| month | the reporting month |
| report | hash table with report data |
The primary key of the table will be composite by fields id year month. We will use the categories of expenses as the keys of the associative report array, and the values spent on the corresponding category as the values.
An example of a report in a database.

On this line it is clear that the user with the id "d717b8e4-1f0f-4094-bceb-d8a8bbd6a673" spent 500 rubles in January 2015 on transport and 2500 rubles on entertainment.
If the implementation of the GetMonthReport () method does not raise questions, it is not difficult to generate a json report string from an associative array using the built-in postgresql tools, then for correct implementation of the UpdateMonthReport () method updating the monthly report, you will have to tinker a bit more. First, we need to make sure that the report for this month already exists in the database and create it if it is not. Secondly, we need to exclude the race condition — attempts to create / update the same report in a parallel stream. The example turned out to be quite large, but this is not due to the complexity of the hstore type, but to the need to perform the UpSert operation, which consists of two requests and the subsequent need to exclude the race state. 99% of the methods in the storage services are much simpler here, I myself did not expect that I would have to write so much code. But there is a silver lining, this example perfectly demonstrates why it is the business logic layer that defines the storage service interface, and not vice versa. If we started work on the project by creating a report repository, we would surely have made a classic repository with the AddReport (), GetReport (), UpdateReport () methods and unwittingly shifted the need to provide thread-safe access to the clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. This example perfectly demonstrates why it is the business logic layer that defines the storage service interface, and not vice versa. If we started work on the project by creating a report repository, we would surely have made a classic repository with the AddReport (), GetReport (), UpdateReport () methods and unwittingly shifted the need to provide thread-safe access to the clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. This example perfectly demonstrates why it is the business logic layer that defines the storage service interface, and not vice versa. If we started work on the project by creating a report repository, we would surely have made a classic repository with the AddReport (), GetReport (), UpdateReport () methods and unwittingly shifted the need to provide thread-safe access to the clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. why exactly the layer of business logic in us determines the storage service interface, and not vice versa. If we started work on the project by creating a report repository, we would surely have made a classic repository with the AddReport (), GetReport (), UpdateReport () methods and unwittingly shifted the need to provide thread-safe access to the clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. why exactly the layer of business logic in us determines the storage service interface, and not vice versa. If we started work on the project by creating a report repository, we would surely have made a classic repository with the AddReport (), GetReport (), UpdateReport () methods and unwittingly shifted the need to provide thread-safe access to the clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. If we started work on the project by creating a report repository, we would surely have made a classic repository with the AddReport (), GetReport (), UpdateReport () methods and unwittingly shifted the need to provide thread-safe access to the clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. If we started work on the project by creating a report repository, we would surely have made a classic repository with the AddReport (), GetReport (), UpdateReport () methods and unwittingly shifted the need to provide thread-safe access to the clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. UpdateReport () would inadvertently shift the need for thread-safe access to clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate. UpdateReport () would inadvertently shift the need for thread-safe access to clients of this repository. That is, on the business logic layer. That is why, we build the relationships of business logic layer objects with storage services, guided by the principles of a big boss, which state the following: no major manager will try to do work that his subordinate is able to handle on his own, and even more so he will not adjust under your subordinate.
Report storage service code.
//Сервис хранения отчетов
public class ReportStorage : IReportsStorage
{
private readonly IDbMapper _dbMapper;
private readonly IDistributedLockFactory _lockFactory;
public ReportStorage(IDbMapper dbMapper, IDistributedLockFactory lockFactory)
{
_dbMapper = dbMapper;
_lockFactory = lockFactory;
}
//получить отчет за месяц в формате json
public string GetMonthReport(Guid userId, int month, int year)
{
var report = _dbMapper.ExecuteScalarOrDefault("select hstore_to_json(report) from reps where id = :userId and year = :year and month = :month",
new QueryParameter("userId", userId),
new QueryParameter("year", year),
new QueryParameter("month", month));
//если отчета в базе нет - вернем пустой json объект
if (string.IsNullOrEmpty(report))
return "{}";
return report;
}
//обновить отчет за месяц
public void UpdateMonthReport(Guid userId, ECategory category, int year, int month, double sum)
{
//оставляем доступ к операции обновления отчетов только для одного потока
using (_lockFactory.AcquireLock(BuildLockKey(userId, year, month) , TimeSpan.FromSeconds(10)))
{
//обновляем отчет
RaceUnsafeMonthReportUpsert(userId, category.ToString().ToLower(), year, month, sum);
}
}
//потоконебезопасный upsert в два запроса
private void RaceUnsafeMonthReportUpsert(Guid userId, string category, int year, int month, double sum)
{
//результат запроса: null - отчета не существует, число - сумма, потраченная на соответствующую категорию за месяц
double? sumForCategory = _dbMapper.ExecuteScalarOrDefault("select Coalesce((report->:category)::real, 0) from reps where id = :userId and year = :year and month = :month",
new QueryParameter("category", category),
new QueryParameter("userId", userId),
new QueryParameter("year", year),
new QueryParameter("month", month));
//если отчета нет - его надо создать, сразу записав известные данные
if (!sumForCategory.HasValue)
{
_dbMapper.ExecuteNonQuery("insert into reps values(:userId, :year, :month, :categorySum::hstore)",
new QueryParameter("userId", userId),
new QueryParameter("year", year),
new QueryParameter("month", month),
new QueryParameter("categorySum", BuildHstore(category, sum)));
return;
}
//отредактируем существующий отчет, увеличив сумму расходов по категории
_dbMapper.ExecuteNonQuery("update reps set report = (report || :categorySum::hstore) where id = :userId and year = :year and month = :month",
new QueryParameter("userId", userId),
new QueryParameter("year", year),
new QueryParameter("month", month),
new QueryParameter("categorySum", BuildHstore(category, sumForCategory.Value + sum)));
}
//построение элемента хеш-таблицы (пары ключ:значение) в формате hstore
private string BuildHstore(string category, double sum)
{
var sb = new StringBuilder();
sb.Append(category);
sb.Append("=>\"");
sb.Append(sum.ToString("0.00", CultureInfo.InvariantCulture));
sb.Append("\"");
return sb.ToString();
}
//построение ключа блокировки обновления отчета
private string BuildLockKey(Guid userId, int year, int month)
{
var sb = new StringBuilder();
sb.Append(userId);
sb.Append("_");
sb.Append(year);
sb.Append("_");
sb.Append(month);
return sb.ToString();
}
}
In the ReportStorage service constructor, we have two dependencies - IDbMapper and IDistributedLockFactory. IDbMapper is the façade over the lightweight ORM BLToolkit framework.
public interface IDbMapper
{
List ExecuteList(string query, params QueryParameter[] list) where T : class;
List ExecuteScalarList(string query, params QueryParameter[] list);
T ExecuteObject(string query, params QueryParameter[] list) where T : class;
T ExecuteObjectOrNull(string query, params QueryParameter[] list) where T : class;
T ExecuteScalar(string query, params QueryParameter[] list) ;
T ExecuteScalarOrDefault(string query, params QueryParameter[] list);
int ExecuteNonQuery(string query, params QueryParameter[] list);
Dictionary ExecuteScalarDictionary(string query, params QueryParameter[] list);
}
It would be quite acceptable to use NHibernate or some other ORM to generate queries, but we decided to write queries by hand and only map the results of the execution of the DTO objects to the framework, which BLToolkit copes with just fine.
IDistributedLockFactory, in turn, is a facade over the distributed lock mechanism, similar to the RedisLocks mechanism built into the ServiceStack .
I already wrote that we are using the approach: abstract infrastructure is a “purely concrete” business logic, which is why we try to wrap third-party libraries with wrappers and facades in order to always be able to replace infrastructure elements without rewriting the business logic of the project.
The “Mixed” Modularization Concept
There is a certain share of cunning in words that we have allocated the MoneyFlow application reporting system as a separate, independent module. Yes, we store report data separately from accounting system data, but in our application, business logic and parts of the infrastructure, such as a service bus or a web server, are shared resources for all application modules. For our small company, in which the milling fingers of one hand of a milling machine operator are quite enough to recount programmers, such an approach is more than justified. In large companies, where different teams can work on different modules, it is customary to take care of minimizing the use of shared resources and the absence of common points of failure. So, if the MoneyFlow application were developed in a large company, its architecture would be a classic SOA.

The rejection of the idea to create a system on the basis of completely independent modules communicating with each other on the basis of one simple protocol was not easy for us. Initially, during the design, we planned to make a real SOA solution, but at the last moment, having weighed the pros and cons within our compact (not in the sense of closed and limited, but just very small) teams decided to use the “mixed” concept of module splitting: common infrastructure and business logic are independent storage services. Now I understand that this decision was correct. We were able to devote time and effort not spent on a complete duplication of the module infrastructure to improve other aspects of the application.
Instead of a conclusion
The active phase of work on the project lasted a year and a half. Now I like some parts of the system more, some less, something I would have done differently, but overall I like how our server API is arranged. I do not believe in the existence of ideal things, just as our code is not perfect. But our API turned out to be fast, it scales easily and we managed to achieve a reasonable balance between the simplicity of the code and its flexibility in aspects important for our application.