Do not rush to throw old servers, from them it is possible to collect fast Ethernet-SHD in an hour

Once we installed new disk shelves for the EMC array at one of our large customers. When I left the site, I drew attention to people in the form of a transport company who pulled out of racks and prepared for loading a large number of servers. Communication with sysadmins of customers is tight, so it quickly became clear that these are old machines, which have little memory and processor power, although there are plenty of disks. Updating them is not profitable and the glands will be sent to the warehouse. And they will be written off somewhere in a year, when they are covered with dust.
Iron, in general, is not bad, just of the past generation. To throw out, of course, was a pity. Then I suggested testing EMC ScaleIO. In short, it works like this:

ScaleIO is software that is installed on servers on top of the operating system. ScaleIO consists of a server part, a client part and management nodes. Disk resources are combined into one virtual single-level system.
How it works
The system requires three control nodes. They contain all the information about the state of the array, its components and ongoing processes. These are a kind of array orchestrators. For ScaleIO to function fully, at least one control node must be alive.
The server side is small clients that combine free space on servers into a single pool. On this pool, you can create moons (one moon will be distributed across all servers included in the pool) and give them to clients. ScaleIO can use server RAM as a read cache. The cache size is set for each server separately. The larger the total volume, the faster the array will work.
The client part is the driver of the block I / O device, which is distributed across different servers of the moons in the form of a local disk. This is how, for example, ScaleIO moons look like on Windows:
The requirements for installing ScaleIO are minimal:
CPU | Intel or AMD x86 |
Memory | 500 MB RAM for a management node 500 MB RAM on each data node 50 MB RAM for each client |
Supported Operating Systems | Linux: CentOS Windows: 2008 R2, 2012, or 2012 R2 Hypervisors: VMware ESXi OS: 5.0, 5.1, or 5.5, managed by vCenter 5.1 or 5.5 only Hyper-V XenServer 6.1 RedHat KVM |
Of course, all data is transmitted over an Ethernet network. All I / O and bandwidth are available to any application in the cluster. Each host writes to many nodes at the same time, which means that the throughput and the number of input / output operations can reach very large values. An additional advantage of this approach is that ScaleIO does not require a thick interconnect between nodes. If the server has Ethernet 1Gb, the solution is suitable for streaming recording, archive or file trash. Here you can run a test environment or developers. When using Ethernet 10Gb and SSD drives, we get a good database solution. On SAS disks, you can raise datastores on VMware. At the same time, virtual machines can run on the same servers from which space is allocated to the common moon, because under ESX there is both a client and a server part.
With a large number of disks, probability theory increases the risk of failure of any of the components. The solution is interesting: in addition to RAID groups at the controller level, data mirroring is used on different servers. All servers are divided into fault-sets - a set of machines with a high probability of simultaneous failure. Data is mirrored between fault sets in such a way that the loss of one of them does not lead to data inaccessibility. A single fault-set may include servers located in the same rack, or servers with different operating systems. The latter option is pleasant in that you can roll out patches to all Linux or Windows machines at the same time, without fear of a cluster crash due to operating system errors.

Tests
ScaleIO is installed using the installation manager. You need to download software packages for different operating systems and a csv file with the desired result. I took 8 servers, half with Windows, half with SLES. Installation on all 8 took 5 minutes and a few clicks on the "Next" button.
Here is the result:

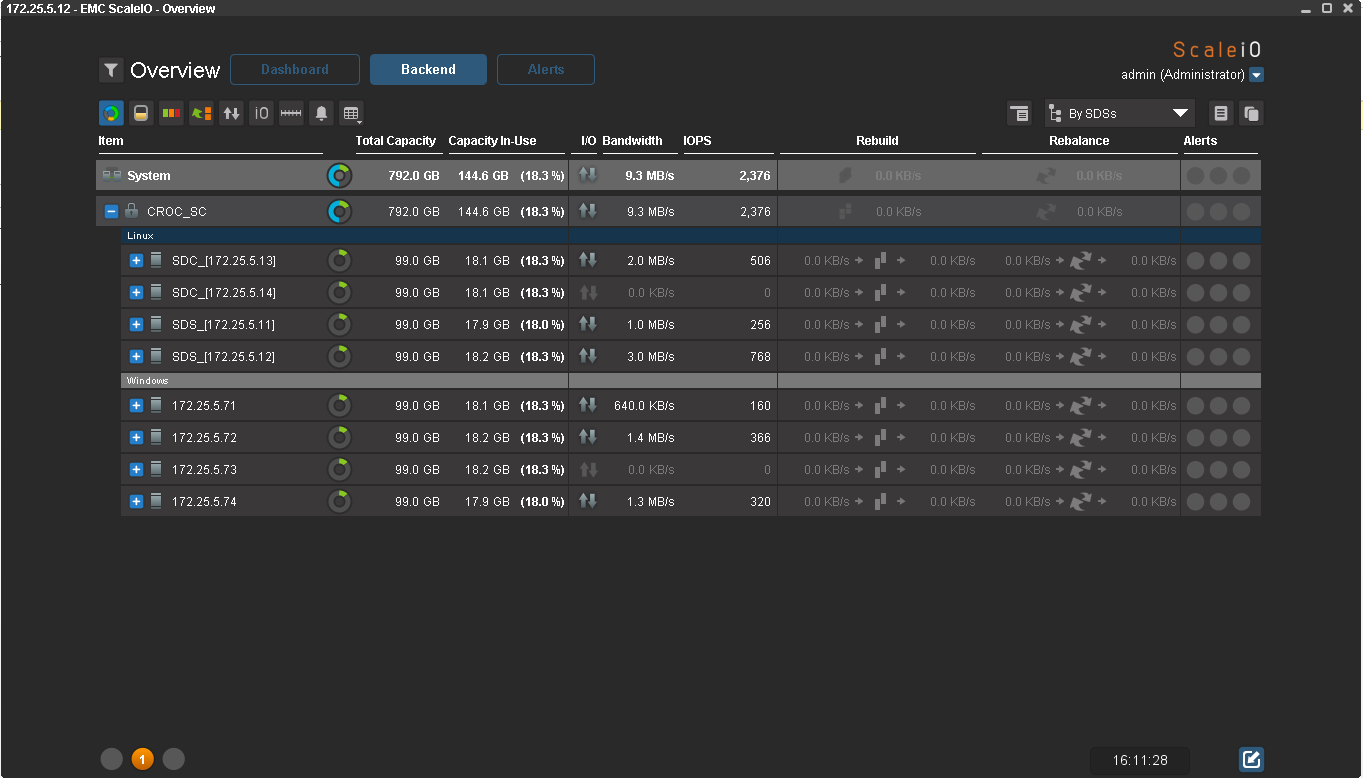
This, by the way, is the GUI through which you can control the array. For fans of the console, there is a detailed manual on cli-commands. The console, as always, is more functional.
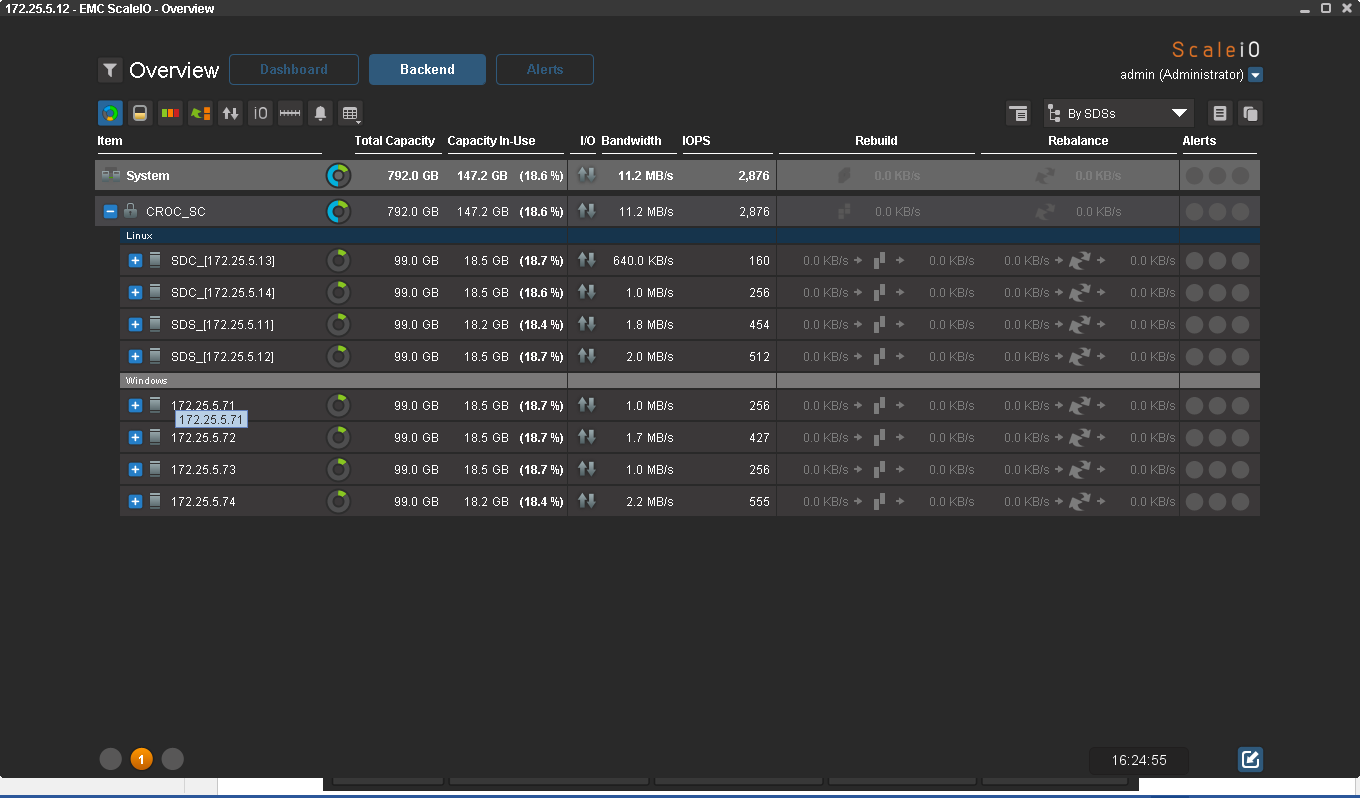
For tests, I divided all nodes with data into 2 Failover sets: with Windows and with SLES. Map our first disk to the host:

The disk capacity is small, only 56 GB. Fail-safe tests are further in the plan, but I do not want to wait for the end of the rebuild for more than 10 minutes.
The easiest way to emulate a load is to use an IOmeter. If the disk falls off even for a second, I will definitely find out about it. Unfortunately, we won’t be able to test performance in this test: the servers are virtual and the datastore is EMC CX3. Normal equipment is in production. Here the first bytes ran:

As I wrote earlier, one fail-set can be turned off. The fun begins. It's nice to know that with a productive client in emergency situations everything will be fine, so at CROC we create such situations in our lab. The best way to convince customers of the reliability of a high availability solution is to turn off one of the two equipment racks. Here I do the same:
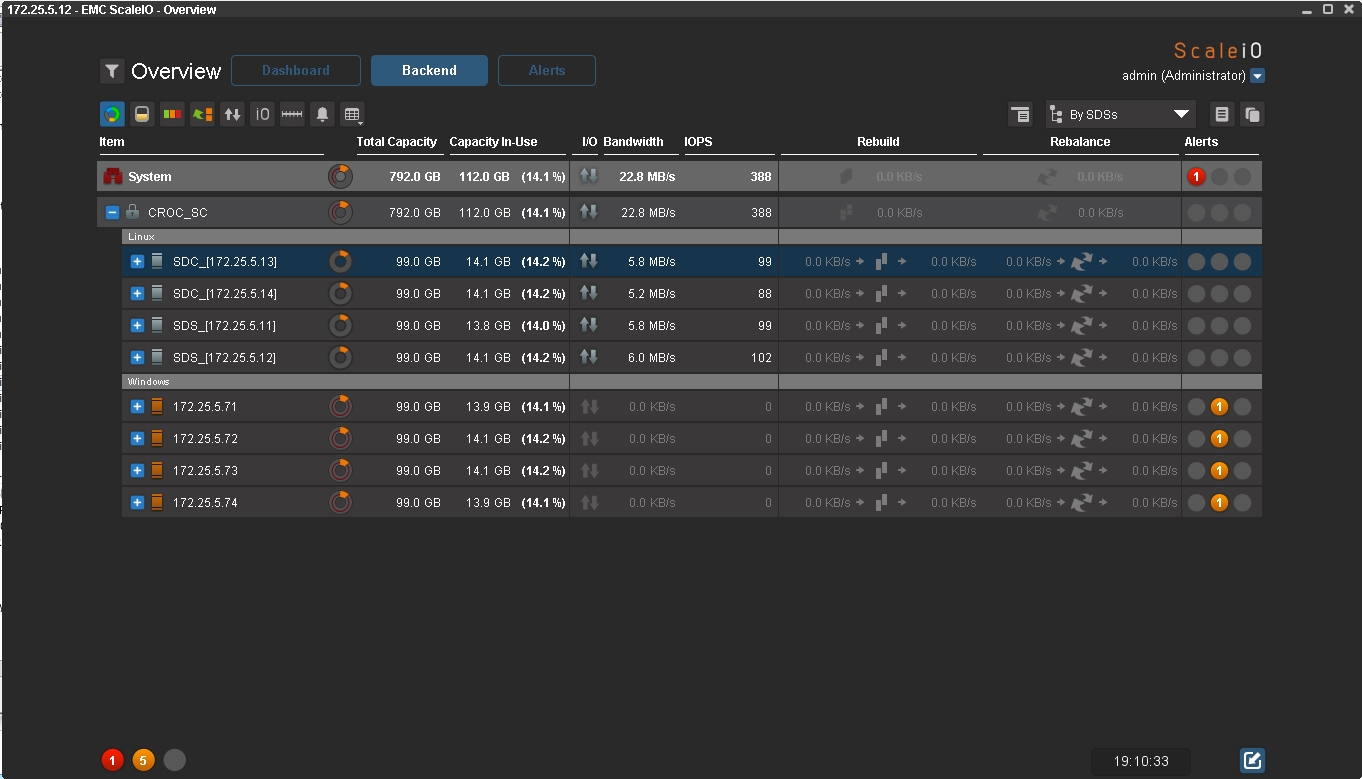
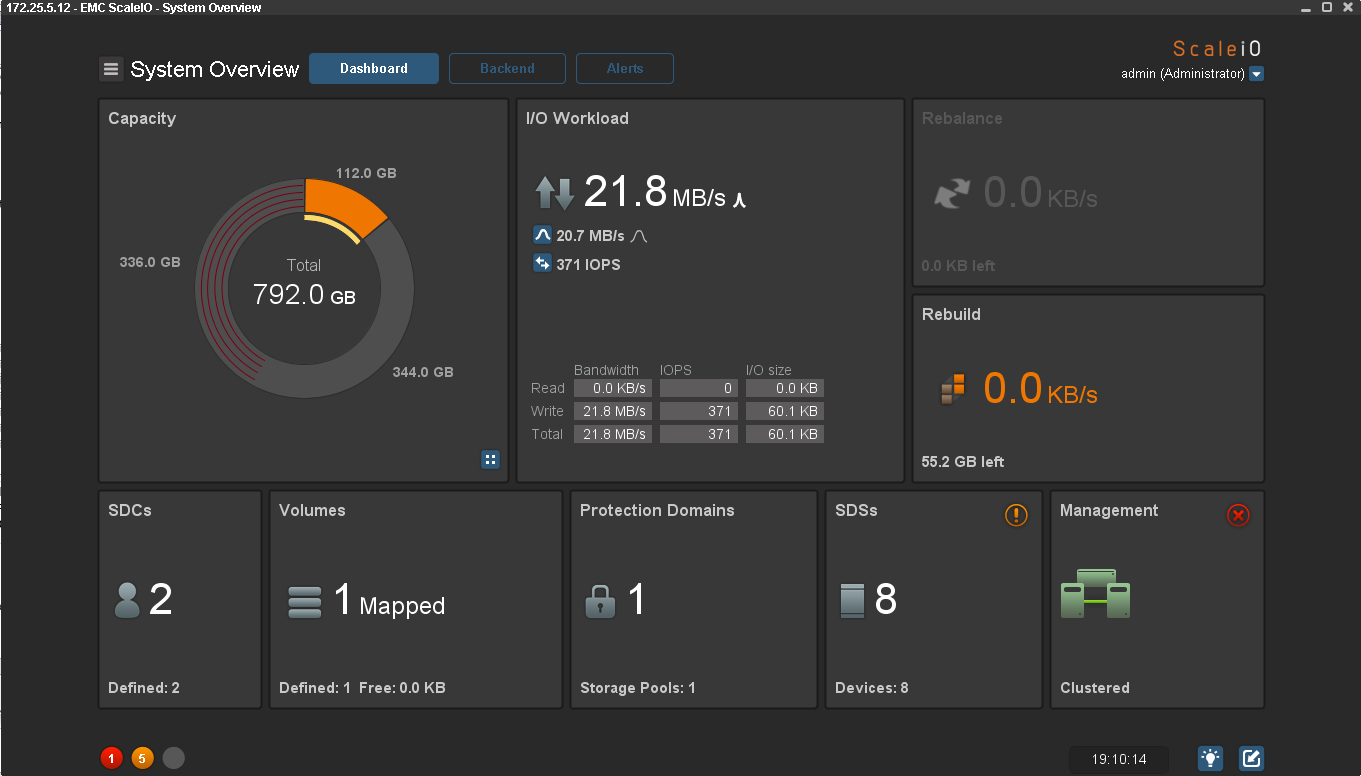
The GUI shows that all nodes with the Windows operating system are not available, which means that the data is no longer protected by redundancy. The pool went into Degraded status (red color instead of green), and IOmeter continues to write. For the host, the simultaneous failure of half the nodes went unnoticed.
Let's try to include 3 of the four nodes:
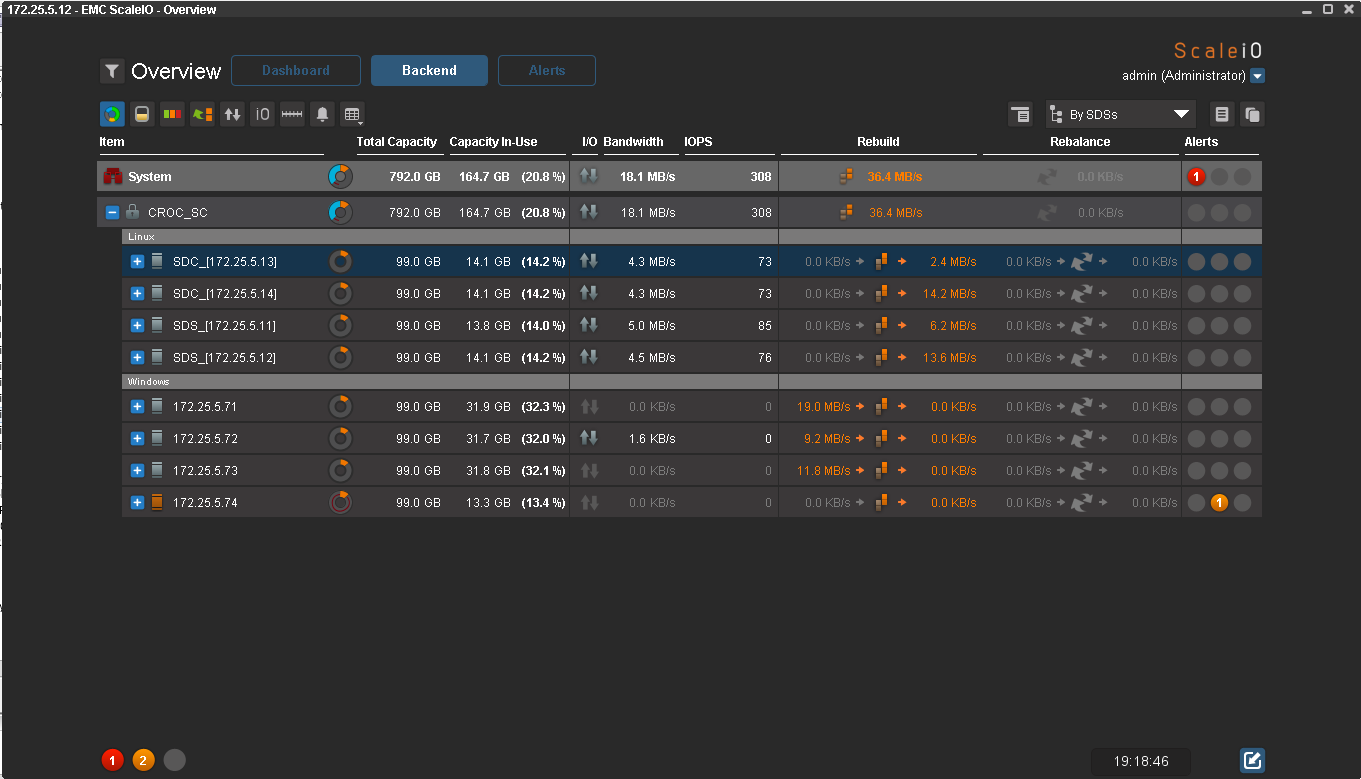
Rebuild started automatically, the flight is normal. Interestingly, data redundancy will be restored automatically. But since now there is one less node with Windows, they will take up more space. As redundancy is restored, the data will turn green.
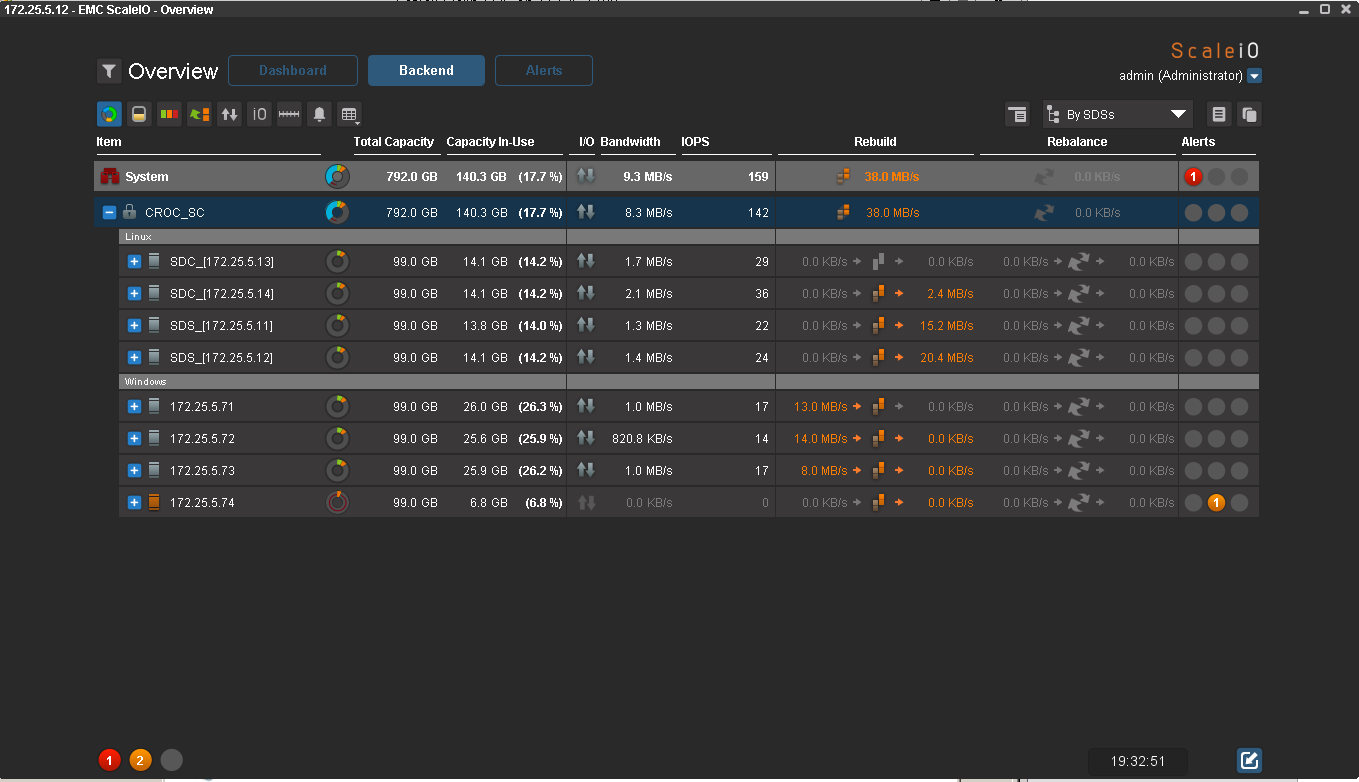
Half ready:
But now everything:
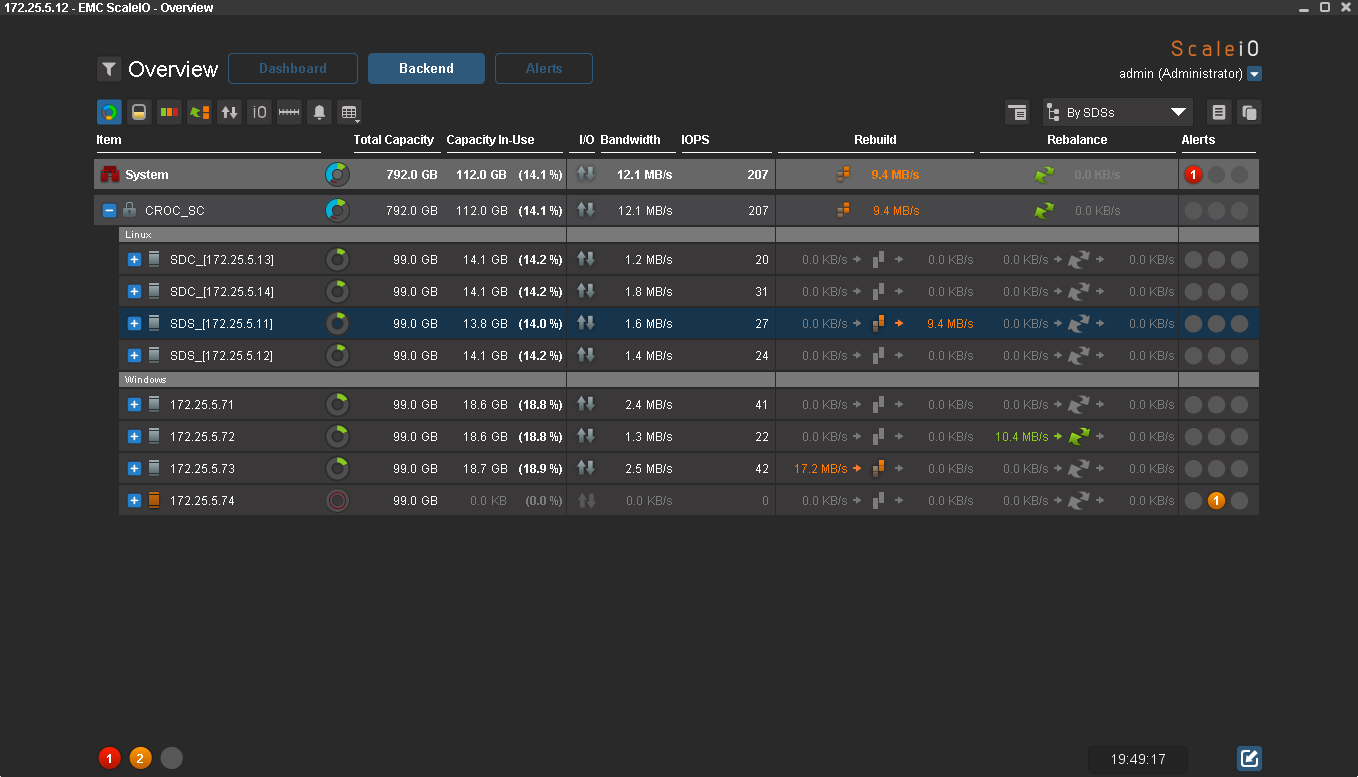
Data completely restored redundancy. There is nothing on the 4th node now. When I turn it on, balancing will begin inside one Failover set. The same thing happens when adding new nodes.
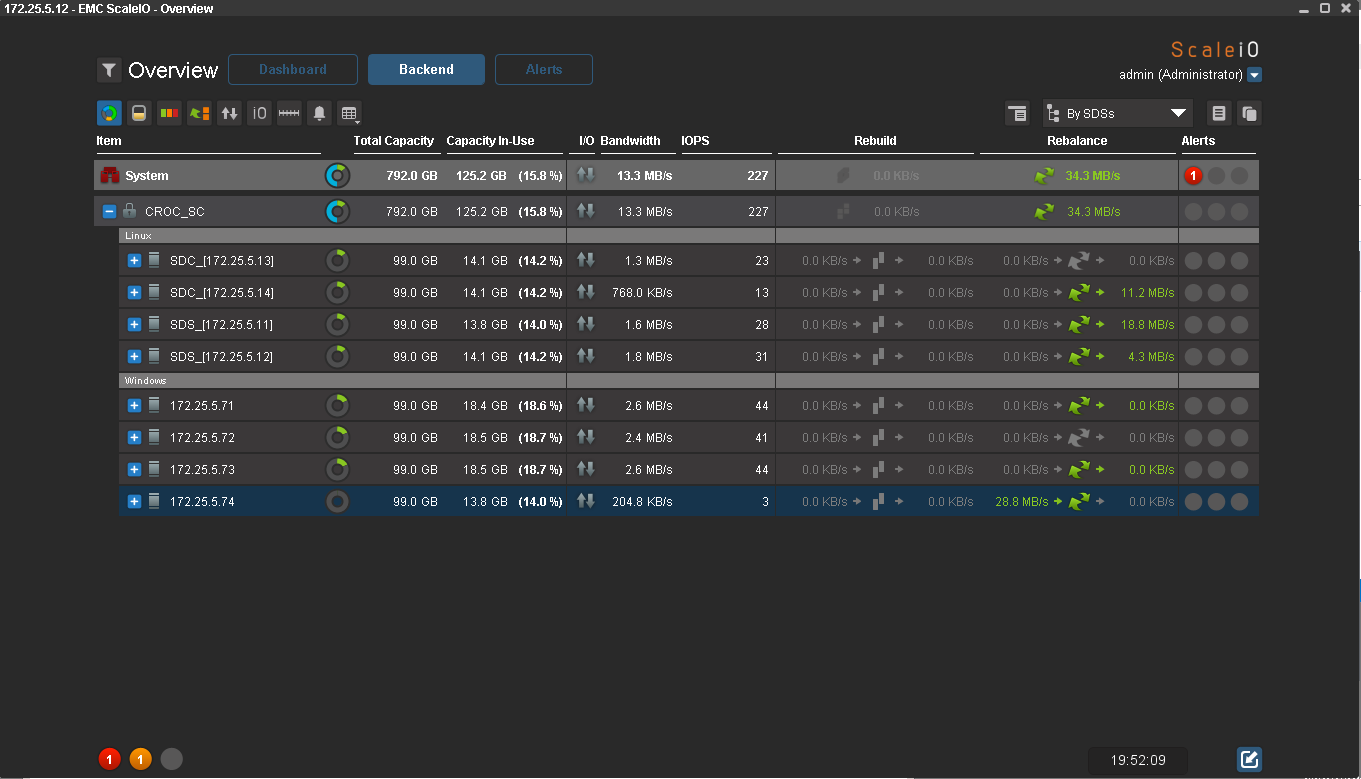
Data rebalance has started. Interestingly, the data is copied from all nodes, and not just from the nodes of the same file seter. After the end of the rebalance, 14% of the place is taken on all nodes. IOmeter is still writing data.
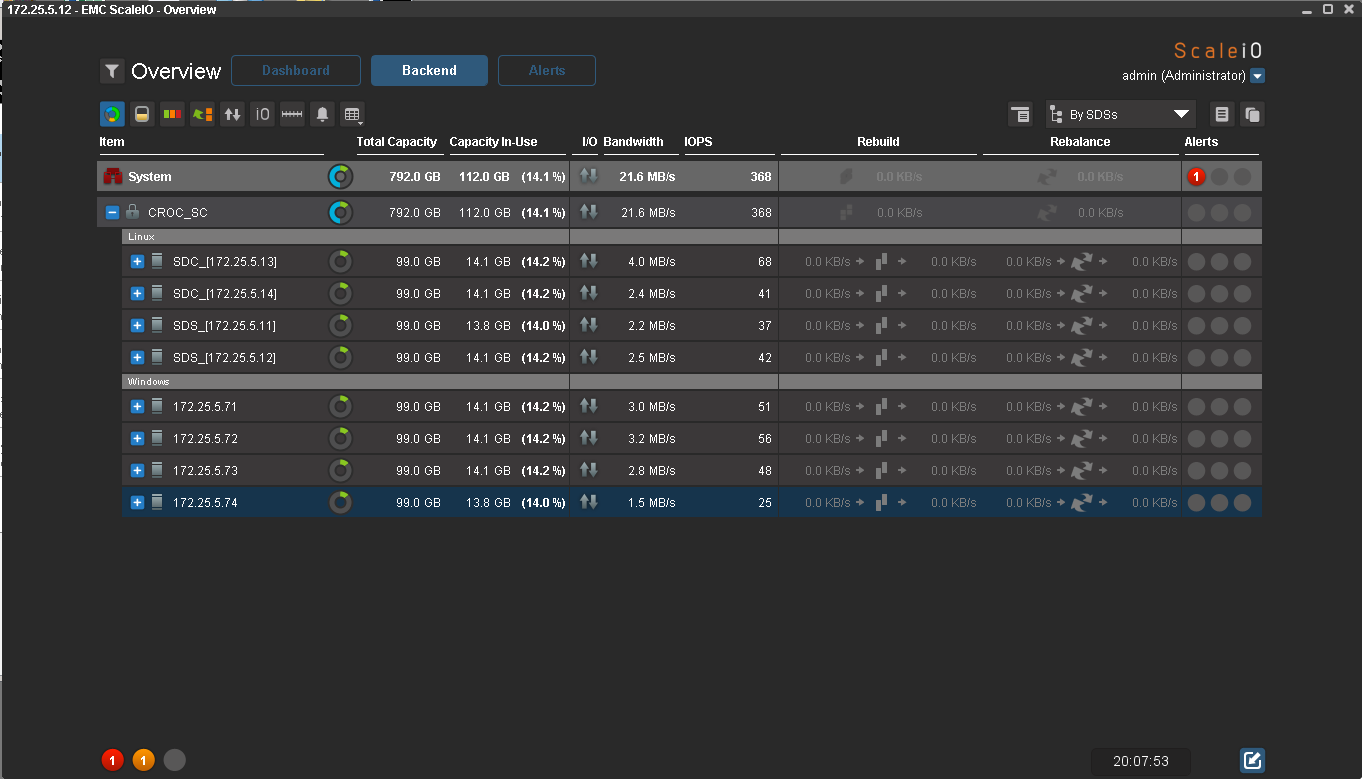
The first iteration of the tests is over, the second will be on a different hardware. Need to test performance.
Price
ScaleIO licensing policy - pay only for raw capacity. The licenses themselves are not tied to the hardware at all. This means that you can put ScaleIO on the oldest hardware, and after a couple of years, replace it with modern servers without buying licenses. A bit unusual after the standard array licensing policy, when upgraded drives are more expensive than the same drives at initial purchase.
The ScaleIO price list is approximately $ 1,572 per terabyte of raw space. Discounts are negotiated separately (I think if you read up to this place, there is no need to explain what the "price" price is). ScaleIO has analogues among open source solutions, and from other manufacturers. But ScaleIO has an important plus - round-the-clock EMC support and vast experience in implementation.
EMC colleagues say you can save up to 60% in five-year costs compared to midrange storage. This is achieved both by reducing the cost of licenses and by reducing the requirements for hardware, as well as power, cooling, and, accordingly, a place in the data center. As a result, the decision turned out to be quite “anti-crisis”. I think this year it will come in handy to many.
What else can be done
- ScaleIO can be divided into isolated domains (this is for cloud providers).
- Software can create snapshots and limit the speed of clients,
- Data on ScaleIO can be encrypted and laid out in pools with different performance.
- Linear scaling. With each new host, bandwidth, performance, and volume increase.
- Failover sets allow you to lose servers as long as there is free space to restore data redundancy.
- Variability. You can collect cheap file trash on SATA disks, or you can fast storage system with SSD disks.
- It completely replaces midrange storage on some projects.
- You can use unused space on existing servers or give a second life to old hardware.
Of the minuses - it requires a large number of ports in network switches and a large number of ip-addresses.
Typical Applications
- The most obvious is to build a public or private company cloud. The solution is easy to expand, nodes are easy to add and change.
- For infrastructure virtualization. There are clients for ESX, so there is nothing stopping us from making the ScaleIO pool (you can even on local drives of the same servers on which ESX is installed) and put virtual machines on it. In this way, good performance and additional fault tolerance can be achieved at relatively low cost.
- In a configuration with SSD and Ethernet 10G, ScaleIO is perfect for medium and small databases.
- In a configuration with capacious SATA disks, you can make cheap storage or archive, which, however, cannot be placed on tape.
- ScaleIO on SAS disks will be an excellent solution for developers and testers.
- It is suitable for some video editing tasks, when you need a combination of reliability speed and low price (you need to test in the butt for specifics, of course). The system can be used to store large files like streaming from HD cameras.
Total
Failover tests were successful. Everything goes to the point that the old servers will go back to performance testing, and then to combat use. If the customer from history at the beginning does as intended, some will receive a bonus for the saved, non-acid budget.
If you are interested in a solution, there is a desire to test it for specific tasks or just discuss it - write to rpokruchin@croc.ru. Everything can be done on the test hardware, as in that joke about the new Finnish chainsaw and Siberian men.