Parsim Wikipedia for NLP tasks in 4 teams
- Tutorial
The essence
It turns out for this purpose it is enough to run just such a set of commands:
git clone https://github.com/attardi/wikiextractor.git
cd wikiextractor
wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2
python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2and then a little polish script for post-processing
python3 process_wikipedia.pyThe result is a finished .csvfile with your body.
It is clear that:
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2can be changed to the language you need, more details here [4] ;- All the information about the parameters
wikiextractorcan be found in the manual (it seems even the official dock was not updated, unlike the mana);
A post-processing script converts wiki files to the following table:
| idx | article_uuid | sentence | cleaned sentence | cleaned sentence length |
|---|---|---|---|---|
| 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon (Comte de Pentevre) Jean I de ... | Jean i de Chatillon comte de pentevre Jean i de sha ... | 38 |
| one | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Was guarded by Robert de Vera, Count Oh ... | was guarded by Robert de Vera, Count of Oxfor ... | 18 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | However, this was opposed by Henry de Gromon, c ... | however, this was opposed by henry de grom ... | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | The king offered him another important person for his wife ... | the king offered his wife another important branch ... | 48 |
| four | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean was released and returned to France at 138 ... | Jean liberated returned france year wedding m ... | 52 |
article_uuid is a pseudo-unique key, the order of proposals on the idea should be preserved after such pre-processing.
What for
Perhaps, at the moment, the development of ML-tools has reached such a level [8] that literally a couple of days are enough to build a working NLP model / pipeline. Problems arise only in the absence of reliable datasets / ready embeds / ready language models. The purpose of this article is to alleviate your pain a little, by showing that to handle the whole of Wikipedia (the idea of the most popular corpus for training embedding of words in NLP) will be enough for a couple of hours. After all, if a couple of days are enough to build the simplest model, why spend a lot more time getting data for this model?
The principle of the script
wikiExtractorsaves wiki articles as text, divided by <doc>blocks. Actually, the script is based on the following logic:
- Take a list of all the files on the output;
- We divide files into articles;
- Remove all remaining HTML tags and special characters;
- With the help of
nltk.sent_tokenizeshare on sentences; - So that the code does not grow to enormous size and remains readable, we assign a uuid to each article;
As a preprocessing of the text is simple (you can easily cut it to yourself):
- Remove non-alphabetic characters;
- Delete stop words;
Dataset is, what now?
Main application
Most often in practice in NLP one has to face the task of constructing embeddings.
To solve it, one of the following tools is usually used:
- Ready vectors / word embeddings [6];
- Internal states of CNN, trained on such tasks as how to determine false sentences / language modeling / classification [7];
- The combination of the above methods;
In addition, it has been shown many times [9] that as a good baseline for embeddingd sentences, one can also take just averaged (with a couple of minor details that we now omit) word vectors.
Other uses
- We use random wiki suggestions as negative examples for triplet loss;
- We teach encoders for sentences using the definition of fake phrases [10];
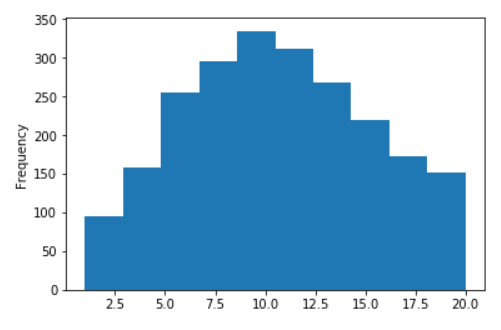
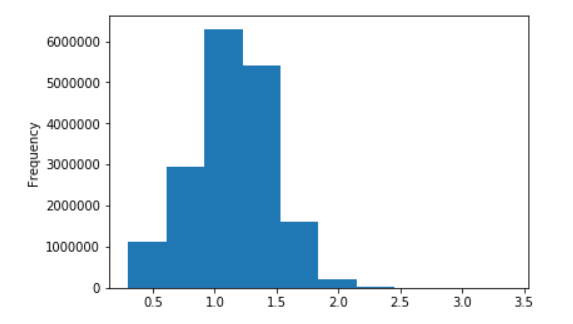
Some charts for Russian wiki
The distribution of the length of sentences for the Russian Wikipedia
No logarithms (X values are limited to 20)
Decimal logarithms
Links
- Fast-text word vectors trained on the wiki;
- Fast-text and Word2Vec models for the Russian language;
- Awesome python library wiki extractor ;
- Official page with links for wiki;
- Our script for post-processing;
- The main articles about word embeddings: Word2Vec , Fast-Text , tuning ;
- Several current SOTA approaches:
- InferSent ;
- Generative pre-training CNN;
- ULMFiT ;
- Contextual approaches for representing words (Elmo);
- Imagenet moment in NLP ?
- Baselines for embeddings offers 1 , 2 , 3 , 4 ;
- Definition of false phrases for the sentence encoder;