PROSPECTOR from the inside
- Tutorial
If possible, it is better not to develop expert systems (c)
A lot of expert systems have been developed in the world, in this post I would like to consider the structure and logic of one of the ancient ES under the name "PROSPECTOR".
1. General concepts
Expert system - a computer system that can partially replace a specialist - expert in resolving a problem situation.
PROSPECTOR is an exploration expert system designed for geological exploration of mineral deposits.
2. Brief description of the system
The PROSPECTOR system works with fuzzy data and fuzzy knowledge. The system is based on fuzzy logic and is well applied to various fields. However, despite the capabilities of the model used, the logic of the ES is different from human logic, and therefore the meaning of system issues may not be clear to the user. In this regard, a system constructed on the basis of the logic of the PROSPECTOR system should be able to explain the course of its “thoughts”.
3. The algorithm of work
System operation is a dialogue between the system and the user. During the dialogue, the system receives information from the user about the observations based on which it draws certain conclusions. The sequence of steps looks like this:
- The system selects an observation that to a greater extent changes the chances of the target hypothesis (in the PROSPECTOR system, this is the presence of certain minerals)
- The system "asks" the user about the presence of the selected observation
- The user “answers” the system about the presence of observation, and the answer is a number in the range from –5 to +5, where –5 is “definitely not”, +5 is “definitely yes”, and 0 means “I don’t know”.
- After receiving the user's response, a wave of changes passes through the semantic network: the chances of the hypotheses affected by the observation are recounted.
- If the chances of the target hypothesis suit the user, then the system ends the dialogue, otherwise step 1.
4. The structure of the knowledge base
The knowledge base is a semantic network based on the knowledge of experts in the subject area.
4.1. Semantic network
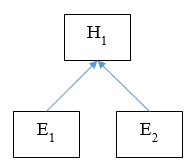
Elements of the semantic network are hypotheses, observations, and the relationships between them. For example, a semantic network may look like this:

Relative to each other, hypotheses are also observations. For example, H2 is an observation for hypothesis H1.
The following relationships are allowed in a semantic network:
- Hypothesis may depend on several observations
- Observation may affect several hypotheses.
Each hypothesis has a chance (O) and weight (C).
Weight is the value received from the user regarding system questions (for observations), in other words, we can say that weight is the degree of possibility of a given observation.
Chance is the degree to which this hypothesis is true (essentially the same probability). The dependency formula looks like this:

For hypotheses, the odds are calculated by the formula:

Before using ES, all hypotheses have, a priori set by the expert, a priori chances. The weights of the connections (C) of hypotheses and observations are 0.
4.2. Semantic network links
4.2.1. General concepts
Each connection of nodes (hypotheses and observations) in the semantic network has the coefficients LS and LN.
LS is a sufficiency coefficient:
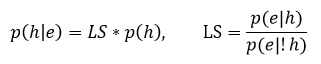
LN is a necessity coefficient:
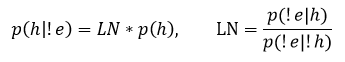
LS and LN coefficients are set by the expert on the basis of his experience and statistics.
For different values, the coefficients can have different meanings:
- LS = LN - observation E does not affect hypothesis N.
- LS = 1 - the presence of observation E does not affect hypothesis N.
- LN = 1 - lack of observation E does not affect hypothesis N.
- LS> 1 - observation E strongly affects hypothesis H (the larger the value, the more it affects).
- LN <1 - the hypothesis H is in great need of observing E (the smaller the value, the more it needs).
Based on 4 and 5 points, we can conclude that only a couple of coefficients in the ES makes sense:
LS > 1, LN <1 - needs and affects
There are 3 possible types of connections in the system:
- brain teaser
- Contextual (conceptual)
- Production
4.2.2. Logical connections
 Logical connections are operations of mathematical logic “AND”, “OR”, “NOT”. Relations impose restrictions on hypotheses, which can be interpreted as follows:
Logical connections are operations of mathematical logic “AND”, “OR”, “NOT”. Relations impose restrictions on hypotheses, which can be interpreted as follows:- For the hypothesis H1 to exist, both observations E1 and E2 (the “I” relationship) must be defined. All observations for this connection are set simultaneously.
- For the hypothesis H1 to exist, at least one observation E1 or E2 (“OR” relationship) must be defined.
Coefficients LS and LN are set for all communication, and not for each observation.
The weight is also set for communication and is calculated by the formula:
- For "And": C = min (C1, C2, ..., CN)
- For "OR": C = max (C1, C2, ..., CN)
- For "NOT": C = –C
4.2.3. Contextual links
 These communications indicate which questions should be asked first.
These communications indicate which questions should be asked first. For example, in the figure on the left before the system asks a question regarding hypothesis H3, it is necessary that the weight (C) of hypothesis H2 be in the range from 0 to 5 inclusive, that is, a positive answer is given regarding hypothesis H2.
Communication data does not have sufficiency ratios (LS) and necessity (LN).
4.2.4. Production Relations
 Relations of the form "If ... then ...". For bonds of this type, weights are calculated by solving a system of equations:
Relations of the form "If ... then ...". For bonds of this type, weights are calculated by solving a system of equations: 
For H1, the maximum and minimum coefficients are:

Assume:
- for observation E1: C = 2, LS = 50, LN = 0.4
- for observing E2: C = -3, LS = 20, LN = 0.8
Thus, we obtain the coefficients:
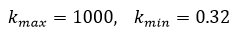
Having obtained the coefficients, we can calculate the dependence of the coefficient k (formula 2) on the weight of the observations. The graph of the function k is presented below:
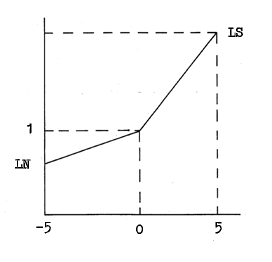
The function k is not direct, so logarithm is used for smoothing (the inverse operation of raising to a power):
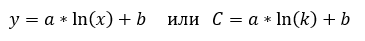
Having solved the system of equations, we obtain the function F:

After finding the function F, it is not difficult to calculate the value of C for hypothesis H1:
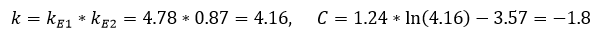
The graphs below of the obtained function F (blue) and function k (formula 2) (red): The

natural logarithm is shown as an example; in the PROSPECTOR system, calculations can be performed differently. For more accurate results, various polynomials can be used as an approximation.
4.3. Semantic Network Passages
Pass - change the weights of the semantic network. They are divided into two types: direct and reverse.
4.3.1. Direct passage
A direct pass is performed when the user introduces new information about the observations and it is necessary to recalculate the chances of hypotheses in accordance with the new data. The direct pass algorithm includes the steps:
- We set for observation the value of weights C received from the user
- We go up the hierarchy to the parent hypothesis (if there is no parent, then exit)
- We calculate the weight value (C) and the odds (O) for the hypothesis according to formulas 1 and 3, respectively, the transition to step 2.
4.3.2. Return pass
Used to find a system issue (observation). The algorithm consists of the steps:
- We find all observations that affect the target hypothesis
- For each observation, set the weight value +5 and -5.
- We carry out a direct passage for the next observation
- Calculate the deviation of the chance value of the target hypothesis after a direct pass
- We return the values of weights and odds to their original state
- After completing the passes for all observations, we single out the observation that affects (changes) to the target hypothesis to a greater extent - this is the next question of the system.
5. Example
Suppose there is a semantic network: The

target is hypothesis H1
Step 1 : perform a return pass
Due to the contextual relationship between H2 and H3, you must first obtain the value C for H2, so the return pass will be performed only for observations E1, E2 and E4
Due to the logical connection E1 and E2, the value C will be assigned to the connection itself.
A total of 4 direct passes will be performed:
- E1E2 (C = + 5) -> H1
- E1E2 (C = -5) -> H1
- E4 (C = + 5) -> H1
- E4 (C = -5) -> H1
We calculate the value of C and O for hypothesis H2 for option 1 (E1E2: C = + 5):
1) Calculate the weight (C) and odds (O) for H2:
The coupling coefficient for hypothesis H2 is:
k = k (E1 & E2) * k (E4)
Therefore:
kmax = LS (E1 & E2) * LS (E4) = 400 * 10 = 4000
kmin = LN (E1 & E2) * LN (E4) = 0.34 * 0.1 = 0.034
We solve the system of equations from clause 4.2.4, formula 3:
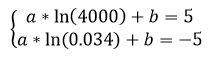
we get

Substitute the value k = 400 (for C (E1E2) = +5), we get C (H2) = 3.02, O (H2) = 2800
2) We calculate the weight (C) and the odds (O) for H1:
Coupling coefficient for the hypothesis Н1 is equal to:
k = k (H2) * k (H3)
Therefore:
kmax = LS (H2) * LS (H3) = 50 * 500 = 25000
kmin = LN (H2) * LN (H3) = 0.3 * 0.9 = 0.27
We solve the system of equations from clause 4.2.4, formula 3:
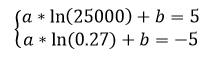
we obtain

Calculate the value of k (for C (H2) = 3.02):
k = 50 ^ (3.02 / 5) = 10.62
We obtain C (H1) = -1.75, O (H1) = 31.86
e = abs (Oa - Op) = 31.86 - 3 = 28.86
e is the deviation of the odds of the hypothesis (the difference in the odds before and after the return pass)
In a similar way we find the deviations for the other options and we get:
- E1E2 at C = +5, e = 28.86
- E1E2 at C = -5, e = 2.04
- E4 at C = +5, e = 0.12
- E4 at C = -5, e = 1.89
According to the data obtained, the following questions of the system will be E1 and E2 (due to the logical connection “AND”, the user must enter data for two observations at once).
Step 2 : receive data from the user
Assume that the user has entered data for E1: C = 3, for E2: C = -4
Step 3 : perform a direct pass
1) Calculate the coefficients (k), weights (C) and odds (O) for H2:
For the E1E2 - H2 bond (C = min (3, -4) is selected due to the logical “I”):
k = 0.34 ^ (4/5) = 0.42
C (H2) = -1.77
O (H2) = 2.94
For the Н2 - Н1 connection:
k = 0.3 ^ (1.77 / 5) = 0.65
C (Н1) = -3.24
O (Н1) = 1.95
After performing a direct pass, we get a semantic network:

If the alternatives are satisfactory, then we are done. Otherwise, posterior odds (Op) become a priori (Oa) and go to step 1.
6. Literature
- www.computing.surrey.ac.uk/ai/PROFILE/prospector.html
- aitopics.org/sites/default/files/classic/Machine_Intelligence_10/MI10-Ch15-Gaschnig.pdf
UPD: Fixed:
- logical connections, weight calculation (C)
- example (corrected incorrect calculations)