PHP 7 will get twice as effective hashtable

The process of rewriting the PHP core has begun with leaps and bounds. This article is a free retelling of the post of one of the authors of the PHP core code about the significant progress achieved in optimizing a data structure such as hashtable. More technical details under the cut.
A simple script that creates an array of 100,000 integers shows the following results:
| 32 bit | 64 bit | |
|---|---|---|
| PHP 5.6 | 7.37 MiB | 13.97 MiB |
| PHP 7.0 | 3.00 MiB | 4.00 MiB |
Test code
$startMemory = memory_get_usage();
$array = range(1, 100000);
echo memory_get_usage() - $startMemory, " bytes\n";
PHP 7, as you can see, consumes 2.5 less memory in the 32-bit version and 3.5 times in the 64-bit version, which is impressive.
Lyrical digression
In essence, in PHP, all arrays are ordered dictionaries (that is, they are an ordered list of key-value pairs), where key-value association is based on hashtable. This is done so that not only integer types can act as array keys, but also complex types like strings. The process itself is as follows - a hash is taken from the array key, which is an integer. This integer is used as the index in the array.
The problem arises when a hash function returns the same hashes for different keys, i.e. there is a collision (that it really happens is easy to see - the number of possible keys is infinitely large, while the number of hashes is limited by the size of the integer type).
There are two ways to deal with collisions. The first is open addressing, when an element is saved with a different index if the current one is already taken, the second is to store elements with the same index in a linked list. PHP uses the second method.
Usually hashtable elements are not ordered in any way. But in PHP, iterating over an array, we get the elements exactly in the order in which we wrote them there. This means that hashtable must support a mechanism for storing element order.
Old hashtable mechanism
This diagram clearly demonstrates how hashtable works in PHP 5:
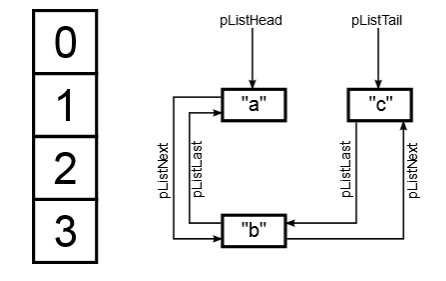
Collision resolution elements in the diagram are designated as buckets. For each such "basket" memory is allocated. The picture does not show the values that are stored in the "baskets", as they are placed in separate zval structures of 16 or 24 bytes in size. Also, a linked list is omitted in the picture, which stores the order of the elements of the array. For an array that contains the keys "a", "b", "c" it will look like this:
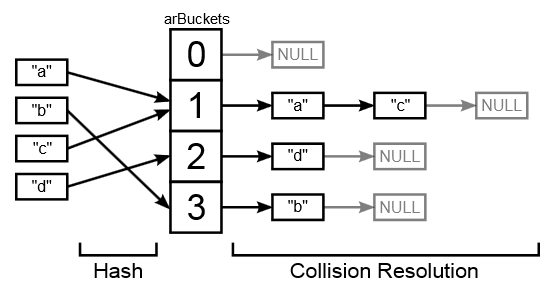
So, why is the old structure inefficient in terms of performance and memory consumption?
- "Baskets" require allocation of space. This process is rather slow and additionally requires 8 or 16 bytes of overhead in the address header. This does not allow the efficient use of memory and cache.
- The zval structure for data also requires space allocation. The problems with the memory and the overhead of the header are still the same as with the "basket", plus the use of zval obliges us to store a pointer to it in each "basket"
- Two linked lists require a total of 4 pointers to the cart (because the lists are bidirectional). This takes us another 16 to 32 bytes. In addition, navigating a linked list is an operation that caches poorly.
A new hashtable implementation addresses these shortcomings. The zval structure was rewritten in such a way that it could be directly included in complex objects (for example, in the aforementioned “basket”), and the “basket” itself began to look like this:
typedef struct _Bucket {
zend_ulong h;
zend_string *key;
zval val;
} Bucket;That is, the "basket" began to include a hash h, a key key and a value val. Integer keys are stored in the variable h (in this case, the hash and key are identical).
Let's take a look at the whole structure:
typedef struct _HashTable {
uint32_t nTableSize;
uint32_t nTableMask;
uint32_t nNumUsed;
uint32_t nNumOfElements;
zend_long nNextFreeElement;
Bucket *arData;
uint32_t *arHash;
dtor_func_t pDestructor;
uint32_t nInternalPointer;
union {
struct {
ZEND_ENDIAN_LOHI_3(
zend_uchar flags,
zend_uchar nApplyCount,
uint16_t reserve)
} v;
uint32_t flags;
} u;
} HashTable;The "baskets" are stored in the arData array. This array is a multiple of the power of two and its current size is stored in the variable nTableSize (minimum size 8). The actual size of the array is stored in nNumOfElements. Notice that the array now includes all the baskets, instead of storing pointers to them.
Element order
The arData array now stores items in the order they were inserted. When deleted from the array, the element is marked with the IS_UNDEF label and is not taken into account in the future. That is, when deleted, the element physically remains in the array until the busy cell counter reaches the size nTableSize. When this limit is reached, PHP will try to rebuild the array.
This approach saves 8/16 bytes on pointers, compared to PHP 5. A nice bonus will also be that now iterating over an array would mean a linear scan of the memory, which is much more efficient for caching than traversing a linked list.
The only drawback is the non-decreasing arData size, which can potentially lead to significant memory consumption on arrays of millions of elements.
Hashtable Bypass
The hash is managed by the DJBX33A function, which returns a 32-bit or 64-bit unsigned integer, which is too much to use as an index. To do this, we perform the “AND” operation with a hash and the size of the table reduced by one and write the result into the variable ht-> nTableMask. The index is obtained as a result of the operation
idx = ht->arHash[hash & ht->nTableMask]The resulting index will correspond to the first element in the collision array. That is, ht-> arData [idx] is the first element that we need to check. If the key stored there matches the required one, then we finish the search. Otherwise, we go to the next element until we find the required one or get INVALID_IDX, which means that this key does not exist.
The beauty of this approach is that, unlike PHP 5, we no longer need a doubly linked list.
Compressed and empty hashtable
PHP uses hashtable for all arrays. But in certain cases, for example, when the array keys are integer, this is not entirely rational. In PHP 7, hashtable compression is used for this. The arHash array in this case is NULL and the search is made using the arData indices. Unfortunately, such optimization is applicable only if the keys are ascending, i.e. for the array [1 => 2, 0 => 1] compression will not be applied.
An empty hashtable is a special case in PHP 5 and PHP 7. Practice shows that an empty array has a good chance of remaining. In this case, arData / arHash arrays will be initialized only when the first element is inserted into the hashtable. In order to avoid crutches and checks, the following technique is used: while less than or equal to its default value, nTableMask is set to zero. This means that the expression hash & ht-> nTableMask will always be zero. In this case, the arHash array contains only one element with a zero index, which contains the value INVALID_IDX. When iterating over an array, we always look up to the first encountered value INVALID_IDX, which in our case will mean an array of zero size, which is what is required of an empty hashtable.
Total
All of the above optimizations allowed us to reduce the size occupied by an element from 144 bytes in PHP 5 to 36 (32 in case of compression) bytes in PHP 7. A slight drawback of the new implementation is a slightly excessive allocation of memory and the absence of acceleration if all values of the array are the same. Let me remind you that in PHP 5 in this case only one zval is used, so the decrease in memory consumption is significant:
Test code
$startMemory = memory_get_usage();
$array = array_fill(0, 100000, 42);
echo memory_get_usage() - $startMemory, " bytes\n";
| 32 bit | 64 bit | |
|---|---|---|
| PHP 5.6 | 4.70 MiB | 9.39 MiB |
| PHP 7.0 | 3.00 MiB | 4.00 MiB |
Despite this, PHP 7 still shows the best performance.