Sphinx word processing pipeline
- Transfer
Text processing in the search engine looks quite simple from the outside, but in fact it is a complex process. When indexing, the text of documents should be processed by the HTML stripper, tokenizer, stop-word filter, word-form filter and morphological processor. And also you need to remember about exceptions, blended characters, N-grams and sentence boundaries. When searching, everything becomes even more complicated, since in addition to all of the above, you must also process the query syntax, which adds all kinds of specials. characters (operators and masks). Now we will tell how all this works in Sphinx.
A simplified text processing pipeline (in the 2.x engine) looks something like this:

It looks quite simple, but the devil is in the details. There are several very different filters (which are applied in a special order); the tokenizer does something else besides breaking the text into words; and finally, under “etc.,” in the morphology block there are actually at least three more different options.
Therefore, the following picture will be more accurate:
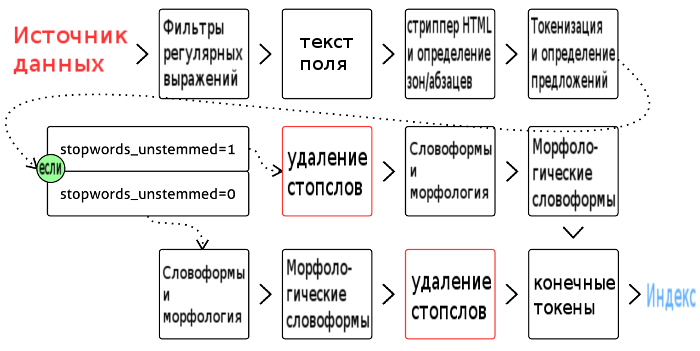
This is an optional step. In essence, this is a set of regular expressions that apply to documents and requests sent to the Sphinx, and nothing more! Thus, this is just “syntactic sugar”, but quite convenient: with the help of regexpov Sphinx processes everything in a row, and without them you would have to write a separate script to load data into the sphinx, then another one to correct the requests, and both scripts needed would keep in sync. And from within the Sphinx, we simply run all the filters over the fields and queries before any further processing. All! You will find a more detailed description in the regexp_filter section of the documentation.
This is also an optional step. This handler is connected only if the html_strip directive is specified in the source configuration . This filter works immediately after the regular expression filter. The stripper removes all HTML tags from the input text. In addition, it can extract and index individual attributes of specified tags (see html_index_attrs ), as well as delete text between tags (see html_remove_elements ). Finally, since zones in documents and paragraphs use the same SGML markup, the stripper determines the boundaries of zones and paragraphs (see index_sp and index_zones ). (Otherwise, I would have to do anotherexactly the same passage through the document in order to solve this problem. Ineffectively!)
This step is required. Whatever happens, we need to break the phrase “Mary had a little lamb” into separate keywords. This is the essence of tokenization: turn a text field into many keywords. It would seem that could be easier?
This is so, except that a simple word break using spaces and punctuation marks does not always work, and therefore we have a whole set of parameters that control tokenization.
Firstly, there are tricky characters that are both “symbols” and “not symbols”, and even moreover, can simultaneously be a “symbol”, “space” and “punctuation mark” (which at first glance can also be interpreted as a space but not really possible). To combat all this economy, the charset_table settings are used ,blend_chars , ignore_chars and ngram_chars .
By default, the Sphinx tokenizer treats all unknown characters as spaces . Therefore, no matter what crazy unicode pseudo-graphics you might “slip” into your document, it will be indexed just like a space. All characters mentioned in charset_table are treated as regular characters . Also charset_table allows you to map one character to another: This is usually used to cast characters to the same register, to remove diacritics, or for everything together. In most cases, this is enough: reduce the known characters to the contents of charset_table; replace all unknowns (including punctuation) with spaces - and that's it, tokenization is ready.
However, there are three significant exceptions.
And all this happens already with the most basic elements of the text - symbols! Are you scared ?!
In addition, tokenayzer (oddly enough) knows how to work with exceptions ( exceptions ) (such as C ++ or C # -. Where special characters are only meaningful in these key words and can be completely ignored in all other cases), and in addition it can detect proposal boundaries (if the index_sp directive is specified ). This problem cannot be solved later, because after tokenization we will no longer have any specials. characters, no punctuation. Also, this should not be done at earlier stages, since, again, 3 passes on the same text to do 4 operations on it is worse than the only one that immediately puts everything in its place.
Inside the tokenizer is designed so that exceptions are triggered earlier than anything else . In this sense, they are very similar to regular expression filters (and moreover, they can be emulated using regular expressions. We say “quite possible” here, but we never tried it ourselves: in fact, working with exceptions is much simpler and faster. Want to add one more regexp? Ok, this will lead to another pass through the text of the field, but all exceptions are immediately applied to a single pass of the tokenizer and occupy 15-20% of the tokenization time (which in general will be 2-5% of the total indexing time) .
The definition of the boundaries of sentences is defined in the tokenizer code and nothing can be configured there (and it is not necessary). Just turn it on and hope that everything works (usually it happens; although who knows, there may be some strange edge cases).
So, if you take a relatively harmless point and first enter it in one of the exception, as well as in blend_chars, and also set index_sp = 1, you risk raising a whole hornet's nest (fortunately, not going beyond the borders of the tokenizer). Again, outside of everything "just works" (although if you include all of the above options, and then another, and try to index some strange text that will trigger all at the same time conditions and thereby awaken Cthulhu - well, are to blame!)
With of this moment we have tokens! ANDall subsequent processing phases deal specifically with individual tokens. Forward!
Both steps are optional; both are disabled by default. More interestingly, word forms and morphological processors (stemmers and lemmatizers) are interchangeable in some way, and therefore we consider them together.
Each word created by the tokenizer is processed separately. Several different handlers are available: from dumb, but still in some places popular Soundex and Metaphone to Porter's classic stemmers, including the libstemmer library, as well as full-fledged lemmatizers. All processors as a whole take one word and replace it with the given normalized form. So far so good.
And now the details: morphological handlers are applied exactly in the order mentioned in the config until the word is processed. That is, as soon as the word turned out to be changed by one of the handlers - that's it, the processing chain ends, and all subsequent handlers will not even be called. For example, in the chain morphology = stem_en, stem_fr the English stemmer will have an advantage; and in the chain morphology = stem_fr, stem_en - French. And in the chain morphology = soundex, stem_en, mentioning an English stemmer is essentially useless, since soundex will convert all English words before the stemmer reaches them. An important marginal effect of this behavior is that if the word is already in normal form and one of the stemmers has detected it (but, of course, has not changed anything), then it will be processed by subsequent stemmers.
Further.Conventional word forms are the implicit morphological handler of the highest priority . If word forms are given, then the words are processed first of all by them, and they get into the morphology handlers only if no transformations have occurred. Thus, any unpleasant error of the stemmer or lemmatizer can be corrected using word forms. For example, an English stemmer converts the words “business” and “busy” to the same base “busi”. And this is easily corrected by adding one line of “business => business” to word forms. (and yes, mind you - word forms are even more than morphology, since in this case the fact of replacing a word is sufficient, and it does not matter that it itself, in fact, has not changed).
Above were mentioned "ordinary word forms." And here's why: in total there are three different types of word forms .
Consider an example:
Suppose we are indexing a “my running shoes” document with these weird settings. What will be the result in the index?
Sounds solid. However, how can a mere mortal who is not involved in the development of Sphinx and is not at all used to debug C ++ code to guess all this ? Very simple: there is a special command for this:
and at the end of this section, we illustrate how morphology and three different types of word forms interact together:
After all the processing, tokens have certain positions. Usually they are simply numbered sequentially, starting from one. However, each position in the document can belong to several tokens at the same time ! Usually this happens when one “raw” token generates several versions of the final word, either using fused characters, or by lemmatization, or in several more ways.
For example, “AT&T” in the case of the fused character “&” will be split into “at” at position 1, “t” at position 2, and also “at & t” at position 1.
This is already more interesting. For example, we have the document “White dove flew away. I dove into the pool. ”The first occurrence of the word“ dove ”is a noun. The second is the verb “dive” in the past tense. But analyzing these words as separate tokens, we can’t say anything about it (and even if we look at several tokens at once, it can be difficult to make the right decision). In this case, morphology = lemmatize_en_all will index all possible options. In this example, two different tokens will be indexed at positions 2 and 6, so that both “dove” and “dive” will be saved.
Positions influence the search using phrases (phrase) and inaccurate phrases (proximity); they also affect the ranking. And as a result of any of the four queries - “white dove”, “white dive”, “dove into”, “dive into” will result in the document being in phrase mode.
The step of removing stopwords is very simple: we just throw them out of the text. However, a couple of things still need to be borne in mind:
1. How can I completely ignore stopwords (instead of just overwriting them with spaces). Even though stop words are thrown away, the positions of the remaining words remain unchanged. This means that “microsoft office” and “microsoft in the office”, if “in” and “the” are ignored as stopwords, will produce different indexes. In the first document, the word “office” is in position 2. In the second, in position 4. If you want to completely remove the stopwords, you can use the stopword_step directive and set it to 0. This will affect the search for phrases and ranking.
2. How to add separate forms or complete lemmas to stopwords. This setting is calledstopwords_unstemmed and determines if stopwords are removed before or after morphology.
Well, we have practically covered all the typical tasks of everyday word processing. Now you should understand what is happening inside, how it all works together, and how to configure the Sphinx to achieve the result you need. Hurrah!
But there is one more thing. We briefly mention that there is also the index_exact_words option , which instructs to index the initial token (before applying morphology) in addition to morphology. There is also the bigram_index option , which will force the sphinx to index pairs of words (“a brown fox” will become “a brown”, “brown fox” tokens) and then use them for ultra-fast search in phrases. You can also use indexing and query plugins, which will allow you to implement almost any desired token processing.
And finally, in the upcoming release of Sphinx 3.0, there are plans to unify all these settings so that instead of the general directives that act on the entire document, they give the opportunity to build separate filter chains for processing individual fields. So that it would be possible, for example, first to remove some stopwords, then apply word forms, then morphology, then another filter of word forms, etc.
The whole picture
A simplified text processing pipeline (in the 2.x engine) looks something like this:
It looks quite simple, but the devil is in the details. There are several very different filters (which are applied in a special order); the tokenizer does something else besides breaking the text into words; and finally, under “etc.,” in the morphology block there are actually at least three more different options.
Therefore, the following picture will be more accurate:
Regular Expression Filters
This is an optional step. In essence, this is a set of regular expressions that apply to documents and requests sent to the Sphinx, and nothing more! Thus, this is just “syntactic sugar”, but quite convenient: with the help of regexpov Sphinx processes everything in a row, and without them you would have to write a separate script to load data into the sphinx, then another one to correct the requests, and both scripts needed would keep in sync. And from within the Sphinx, we simply run all the filters over the fields and queries before any further processing. All! You will find a more detailed description in the regexp_filter section of the documentation.
HTML stripper
This is also an optional step. This handler is connected only if the html_strip directive is specified in the source configuration . This filter works immediately after the regular expression filter. The stripper removes all HTML tags from the input text. In addition, it can extract and index individual attributes of specified tags (see html_index_attrs ), as well as delete text between tags (see html_remove_elements ). Finally, since zones in documents and paragraphs use the same SGML markup, the stripper determines the boundaries of zones and paragraphs (see index_sp and index_zones ). (Otherwise, I would have to do anotherexactly the same passage through the document in order to solve this problem. Ineffectively!)
Tokenization
This step is required. Whatever happens, we need to break the phrase “Mary had a little lamb” into separate keywords. This is the essence of tokenization: turn a text field into many keywords. It would seem that could be easier?
This is so, except that a simple word break using spaces and punctuation marks does not always work, and therefore we have a whole set of parameters that control tokenization.
Firstly, there are tricky characters that are both “symbols” and “not symbols”, and even moreover, can simultaneously be a “symbol”, “space” and “punctuation mark” (which at first glance can also be interpreted as a space but not really possible). To combat all this economy, the charset_table settings are used ,blend_chars , ignore_chars and ngram_chars .
By default, the Sphinx tokenizer treats all unknown characters as spaces . Therefore, no matter what crazy unicode pseudo-graphics you might “slip” into your document, it will be indexed just like a space. All characters mentioned in charset_table are treated as regular characters . Also charset_table allows you to map one character to another: This is usually used to cast characters to the same register, to remove diacritics, or for everything together. In most cases, this is enough: reduce the known characters to the contents of charset_table; replace all unknowns (including punctuation) with spaces - and that's it, tokenization is ready.
However, there are three significant exceptions.
- Sometimes a text editor (such as Word) inserts soft hyphen characters directly into the text! And if you do not completely ignore them (instead of just replacing them with spaces), the text will be indexed as “ma ry had a litt le lamb”. To solve this problem, use ignore_chars.
- Oriental languages with hieroglyphs. The gaps are not significant to them! Therefore, for limited support of CJK (Chinese, Japanese, Korean) texts in the kernel, you can specify the ngram_chars directive, and then each such character will be considered as a separate keyword, as if it is surrounded by spaces (even if in fact it is not).
- For tricky characters like & or. we actually DO NOT KNOW in the process of breaking into words whether we want to index them or delete them. For example, in the phrase “Jeeves & Wooster” the & sign can be completely removed. But in AT&T - no way! Also, you cannot spoil Marwel's Agents of SHIELD. For this, the Sphinx can be specified with a list of characters using the blend_chars directive. Characters from this list will be processed in two ways at once: as ordinary characters, and as spaces. Note how a simple turn from ordinary characters can lead to the generation of many tokens when the blend_chars list comes into play: say, the “Back to USSR” field will, as usual, be divided into back to ussr tokens, as usual, but also one more the ussr token will be indexed at the same position as the u in the base partition.
And all this happens already with the most basic elements of the text - symbols! Are you scared ?!
In addition, tokenayzer (oddly enough) knows how to work with exceptions ( exceptions ) (such as C ++ or C # -. Where special characters are only meaningful in these key words and can be completely ignored in all other cases), and in addition it can detect proposal boundaries (if the index_sp directive is specified ). This problem cannot be solved later, because after tokenization we will no longer have any specials. characters, no punctuation. Also, this should not be done at earlier stages, since, again, 3 passes on the same text to do 4 operations on it is worse than the only one that immediately puts everything in its place.
Inside the tokenizer is designed so that exceptions are triggered earlier than anything else . In this sense, they are very similar to regular expression filters (and moreover, they can be emulated using regular expressions. We say “quite possible” here, but we never tried it ourselves: in fact, working with exceptions is much simpler and faster. Want to add one more regexp? Ok, this will lead to another pass through the text of the field, but all exceptions are immediately applied to a single pass of the tokenizer and occupy 15-20% of the tokenization time (which in general will be 2-5% of the total indexing time) .
The definition of the boundaries of sentences is defined in the tokenizer code and nothing can be configured there (and it is not necessary). Just turn it on and hope that everything works (usually it happens; although who knows, there may be some strange edge cases).
So, if you take a relatively harmless point and first enter it in one of the exception, as well as in blend_chars, and also set index_sp = 1, you risk raising a whole hornet's nest (fortunately, not going beyond the borders of the tokenizer). Again, outside of everything "just works" (although if you include all of the above options, and then another, and try to index some strange text that will trigger all at the same time conditions and thereby awaken Cthulhu - well, are to blame!)
With of this moment we have tokens! ANDall subsequent processing phases deal specifically with individual tokens. Forward!
Word forms and morphology
Both steps are optional; both are disabled by default. More interestingly, word forms and morphological processors (stemmers and lemmatizers) are interchangeable in some way, and therefore we consider them together.
Each word created by the tokenizer is processed separately. Several different handlers are available: from dumb, but still in some places popular Soundex and Metaphone to Porter's classic stemmers, including the libstemmer library, as well as full-fledged lemmatizers. All processors as a whole take one word and replace it with the given normalized form. So far so good.
And now the details: morphological handlers are applied exactly in the order mentioned in the config until the word is processed. That is, as soon as the word turned out to be changed by one of the handlers - that's it, the processing chain ends, and all subsequent handlers will not even be called. For example, in the chain morphology = stem_en, stem_fr the English stemmer will have an advantage; and in the chain morphology = stem_fr, stem_en - French. And in the chain morphology = soundex, stem_en, mentioning an English stemmer is essentially useless, since soundex will convert all English words before the stemmer reaches them. An important marginal effect of this behavior is that if the word is already in normal form and one of the stemmers has detected it (but, of course, has not changed anything), then it will be processed by subsequent stemmers.
Further.Conventional word forms are the implicit morphological handler of the highest priority . If word forms are given, then the words are processed first of all by them, and they get into the morphology handlers only if no transformations have occurred. Thus, any unpleasant error of the stemmer or lemmatizer can be corrected using word forms. For example, an English stemmer converts the words “business” and “busy” to the same base “busi”. And this is easily corrected by adding one line of “business => business” to word forms. (and yes, mind you - word forms are even more than morphology, since in this case the fact of replacing a word is sufficient, and it does not matter that it itself, in fact, has not changed).
Above were mentioned "ordinary word forms." And here's why: in total there are three different types of word forms .
- Conventional word forms . They display 1: 1 tokens and in some way replace the morphology (we just mentioned this)
- Morphological word forms . You can replace all those running on walkers with a single line “~ run => walk” instead of many rules about “running”, “running”, “running”, “running”, etc. And if in English there may not be many such options, then in some others, like our Russian, one basis can have dozens or even hundreds of different inflections. Morphological word forms are used after morphology processors . And they still display the words 1: 1
- Multiforms . They display the words M: N. In general, they work as normal substitution and are performed at the earliest possible stage. It is easiest to imagine multiforms as some early replacements. In this sense, they are a kind of regexp or exception, but they are used at a different stage and therefore ignore punctuation. Note that after applying multiforms, the resulting tokens undergo all other morphological treatments, including the usual 1: 1 word forms !
Consider an example:
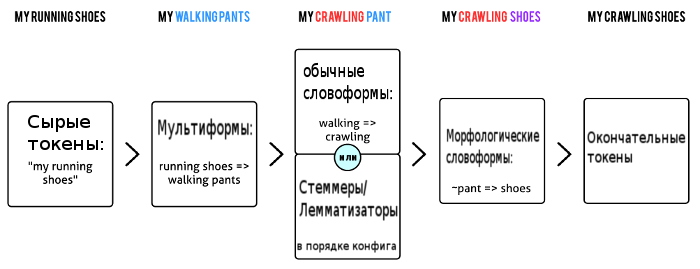
morphology = stem_en wordforms = myforms.txt myforms.txt: walking => crawling running shoes => walking pants ~ pant => shoes
Suppose we are indexing a “my running shoes” document with these weird settings. What will be the result in the index?
- First, we get three tokens - “my” “running” “shoes”.
- Then the multiform will apply and transform it into “my” “walking” “pants”.
- A regular wordform will display “walking” in “crawling” (you get “my” “crawling” “pants”)
- The morphological processor (English Stemmer) will process “my” and “pants” (since “walking” has already been processed with the usual word form) and will produce “my” “crawling” “pant”
- Finally, the morphological word form will display all forms of the word pant in shoes. The resulting tokens are "my" "crawling" "shoes" and will be stored in the index.
Sounds solid. However, how can a mere mortal who is not involved in the development of Sphinx and is not at all used to debug C ++ code to guess all this ? Very simple: there is a special command for this:
mysql> call keywords ('my running shoes', 'test1');
+ ------ + --------------- + ------------ +
| qpos | tokenized | normalized |
+ ------ + --------------- + ------------ +
| 1 | my | my |
| 2 | running shoes | crawling |
| 3 | running shoes | shoes |
+ ------ + --------------- + ------------ +
3 rows in set (0.00 sec)
and at the end of this section, we illustrate how morphology and three different types of word forms interact together:
Words and Positions
After all the processing, tokens have certain positions. Usually they are simply numbered sequentially, starting from one. However, each position in the document can belong to several tokens at the same time ! Usually this happens when one “raw” token generates several versions of the final word, either using fused characters, or by lemmatization, or in several more ways.
The magic of fused characters
For example, “AT&T” in the case of the fused character “&” will be split into “at” at position 1, “t” at position 2, and also “at & t” at position 1.
Lemmatization
This is already more interesting. For example, we have the document “White dove flew away. I dove into the pool. ”The first occurrence of the word“ dove ”is a noun. The second is the verb “dive” in the past tense. But analyzing these words as separate tokens, we can’t say anything about it (and even if we look at several tokens at once, it can be difficult to make the right decision). In this case, morphology = lemmatize_en_all will index all possible options. In this example, two different tokens will be indexed at positions 2 and 6, so that both “dove” and “dive” will be saved.
Positions influence the search using phrases (phrase) and inaccurate phrases (proximity); they also affect the ranking. And as a result of any of the four queries - “white dove”, “white dive”, “dove into”, “dive into” will result in the document being in phrase mode.
Stopwords
The step of removing stopwords is very simple: we just throw them out of the text. However, a couple of things still need to be borne in mind:
1. How can I completely ignore stopwords (instead of just overwriting them with spaces). Even though stop words are thrown away, the positions of the remaining words remain unchanged. This means that “microsoft office” and “microsoft in the office”, if “in” and “the” are ignored as stopwords, will produce different indexes. In the first document, the word “office” is in position 2. In the second, in position 4. If you want to completely remove the stopwords, you can use the stopword_step directive and set it to 0. This will affect the search for phrases and ranking.
2. How to add separate forms or complete lemmas to stopwords. This setting is calledstopwords_unstemmed and determines if stopwords are removed before or after morphology.
What else is left?
Well, we have practically covered all the typical tasks of everyday word processing. Now you should understand what is happening inside, how it all works together, and how to configure the Sphinx to achieve the result you need. Hurrah!
But there is one more thing. We briefly mention that there is also the index_exact_words option , which instructs to index the initial token (before applying morphology) in addition to morphology. There is also the bigram_index option , which will force the sphinx to index pairs of words (“a brown fox” will become “a brown”, “brown fox” tokens) and then use them for ultra-fast search in phrases. You can also use indexing and query plugins, which will allow you to implement almost any desired token processing.
And finally, in the upcoming release of Sphinx 3.0, there are plans to unify all these settings so that instead of the general directives that act on the entire document, they give the opportunity to build separate filter chains for processing individual fields. So that it would be possible, for example, first to remove some stopwords, then apply word forms, then morphology, then another filter of word forms, etc.