Fight packet loss in video conferencing
Introduction
When talking about video transmission over a network, it is mainly about video codecs and resolution. Actually, not so much is heard about video transmission. Here I would like to shed some light on the problem of combating network losses when transmitting video in video conferencing mode. Why is loss so important? Yes, because you can’t just take and skip at least one video package (unlike audio), because any decent video codec is based on the fact that consecutive frames are not very different and it is enough to encode and transmit only the difference between frames. It turns out that (almost) any frame depends on the previous ones. And the picture falls apart with losses ( although some even like it) Why videoconferencing? Because there is a very strict restriction on real time, because a delay of 500ms per circle (round-trip) is already starting to annoy users.
What are the methods to combat the loss of video packages?
Here we will consider the most common option - transfer media via RTP - over UDP.
RTP and UDP
Real-time media is typically transmitted over the RTP protocol ( RFC 3550 ). Here it is important for us to know three things about him:
- Packages are numbered in order. So any gap in the sequence number means loss (although it may also mean a delay in the packet - here the difference can be very subtle).
- In addition to RTP packets, the standard also provides service RTCP packets with which you can do anything (see below).
- Typically, RTP is implemented over UDP. This ensures the speedy delivery of each individual package. A little more about TCP is written below.
I’ll immediately notice that here we are talking about packet networks, for example IP. And in such networks, data is corrupted (lost) immediately in large portions - packets. So many methods for recovering single / few errors in a signal (popular, for example, in DVB) do not work here.
We will consider the fight against losses in a historical perspective (the benefit of the technology of video conferencing is quite young and not a single method has not yet expired completely).
Passive methods
Splitting a video stream into independent pieces
The first successful video codec for a conference on the network is H.263. The basic passive methods of dealing with losses were well developed in it. The easiest one is to break the video into pieces that will be independent of each other. Thus, the loss of a packet from one piece does not affect the decoding of the rest.
It is necessary to break into pieces at least in time, but also in space. A time-lag consists in the periodic (usually every 2 s) generation of a key frame. This is a frame that does not depend on the entire previous history, which means that it is encoded significantly (~ 5-10 times) worse than a conventional frame. Without generating key frames with any number of losses, sooner or later the picture will fall apart.
In space, the frame can also be divided. H.263 uses GOBs for this, and slices in H.264. In fact, this is one and the same thing - pieces of a frame whose encoding is independent of each other. But for proper operation, you must also ensure for each slice independence from other slices of previous frames. It turns out, as if several video sequences are encoded in parallel, from which the final picture is geometrically assembled at the output. This, of course, greatly spoils the encoding quality (or increases the bitrate, which, in essence, is the same).
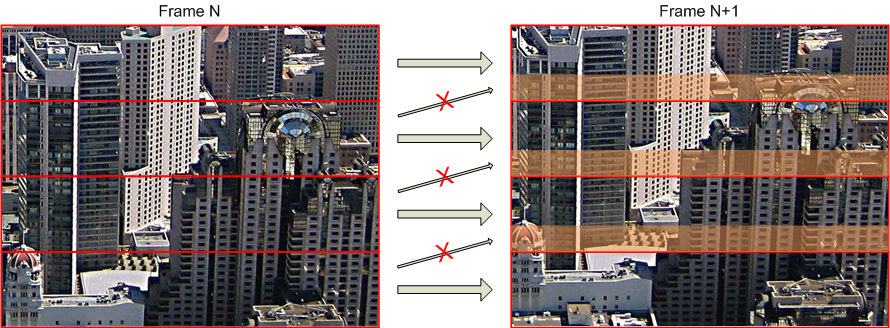
Dependencies between slices of two consecutive images. Orange indicates the areas that could be predicted from the previous image, if not for the restrictions on the slices (which means that these areas could be compressed 5-10 times more efficiently)
It is important to note here that if the generation of key frames is a standard procedure (for example, the first frame is always key), then ensuring the true independence of the slices is a very non-trivial task that may require reworking the encoder (but where does the encoder come from and how difficult is it to remodel anyone )
Error

recovery Example of recovering one lost slice (packet)
If the loss has already occurred, you can try to recover the lost data as much as possible from the available (error resilience). There is one standard method inherent in the H.263 codec: the lost GOB is restored by linear interpolation of the surrounding GOBs. But in the general case, the picture is more complex and the decoding error is propagated with each new frame (since new frames may contain links to damaged areas of the previous frame), so sophisticated mechanisms will come to apply for reasonable glossing over damaged places. In general, there is a lot of work, and after 2 seconds a key frame will come and update the whole picture, so good implementations of this method exist, it seems, only in the imagination of the developers.
Forward error correction
Another good way to deal with losses is to use redundant data, i.e. send more than necessary. But simple duplication here doesn’t look very good exactly because there are better methods in all respects. This is called FEC ( RFC 5109 ) and is arranged as follows. A group of media (information) packets of a given size (for example 5) is selected, and several (about the same or less) FEC packets are recognized on their basis. It is easy to get the FEC packet to recover any packet from the information group (parity-codes, for example RFC 6015 ). Somewhat more difficult, but it is possible to ensure that N FEC packets recover N information in group losses (for example, Reed-Solomon codes,RFC 5510 ). In general, the method is effective, often easily implemented, but very expensive in terms of communication channel.
Active methods
Re-requesting packages and key frames
With the development of video conferencing, it quickly became clear that there was little to be achieved with passive methods. We began to apply active methods, which are obvious in essence - you need to re-send lost packets. There are three different resets:
- Re-request the packet (NACK - negative acknowledgment). We lost the packet - asked for it again - received - decoded.
- Key frame request (FIR - full intra-frame request). If the decoder understands that everything went wrong and for a long time, you can immediately ask for a key frame that will erase the entire history and you can start decoding from scratch.
- Request to update a specific area of the frame. The decoder may inform the encoder that some packet is lost. Based on this information, the encoder calculates how far the error has spread over the frame and updates the damaged region in one way or another. How to realize this is understandable only theoretically, I have not seen any practical implementations.
They sort of decided on the methods - and how this is implemented in practice. But in practice, there are RTCP packets - here you can use them. There are at least three standards for sending such requests:
- RFC 2032 . This is actually the standard for packing an H.261 codec stream into RTP packets. But this standard also provides for re-requests of the first two types. This standard has been deprecated and replaced by RFC 4587 , which proposes to ignore such packages.
- RFC 4585 . Current standard. It provides for all three options and even more. In practice, it is NACK and FIR that are used.
- RFC 5104 . Also valid standard. Partially duplicates RFC 4585 (but is not compatible with it) plus a bunch of different functionality.
It is clear that active methods are much more difficult to implement than passive ones. And not because it is difficult to form a request or resend a packet (although support for three standards simultaneously complicates the issue somewhat). But because here you need to already control what is happening so that the re-requests are not too early (when the "lost" packet had not yet reached) or too late (when it was time to display the picture). Well, in case of temporary big problems in the network, passive methods restore communication within 2 seconds (the arrival of a key frame), while a naive implementation of re-requests can easily overload the network and never recover (something like this hung up on Skype a few years ago )
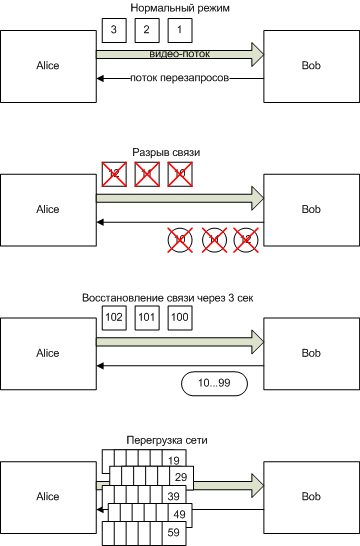
An example of a video freezing after a 3 second disconnection with the naive implementation of re-requests.
But these methods, with adequate implementation, are also much better. There is no need to reduce quality by generating key frames, slicing, or to give place to FEC packets. In general, a very small bitrate overhead can be achieved with the same result as the “expensive” passive methods.
TCP
It has become more or less clear why TCP is not used. This is the most naive method of re-requesting packages without the serious ability to control it. In addition, it provides only a re-request of the package, and re-request of the key frame in any case will have to be implemented on top.
Smart methods
We have here so far concerned only the fight against losses. But what about the width of the channel? Yes - the channel width is important, and it is ultimately manifested by the same losses (plus an increase in the packet delivery time). If the video codec is configured for a bitrate that exceeds the width of the communication channel, then trying to deal with losses in this case is a less meaningful task. In this case, you need to reduce the bitrate of the codec. This is where all the trick begins. How to determine which bitrate to set?
The main ideas are as follows:
- It is necessary to accurately and efficiently monitor the current situation in the network. For example, through RTCP XR ( RFC 3611 ), you can receive a report on delivered packets and their delays.
- If conditions worsen, reset the bitrate (what is the worsening of conditions? How to quickly reset?).
- With the normalization of conditions, you can begin to probe the upper limit of the bitrate. To prevent the picture from falling apart, for example, you can enable FEC and raise the bitrate. When problems occur, FEC will allow the picture to remain correct.
In general, it is precisely the intelligent methods for evaluating the network parameters and adjusting them for today that determine the quality of video conferencing systems. Each serious manufacturer has its own proprietary solution. And it is the development of this technology that is the main competitive advantage of video conferencing systems today.
By the way, the 3GPP TS 26.114 standard (one of the main standards for building industrial VoIP networks) states that it contains a description of a similar algorithm for audio. It is not clear how well the described algorithm is, but it is not suitable for video.
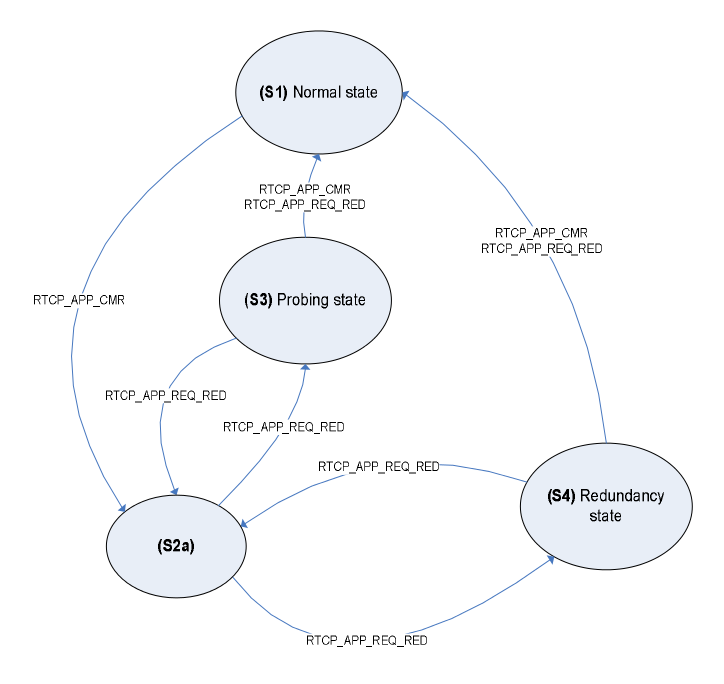
State machine of the algorithm for adapting to network conditions in the artist's view (from 3GPP TS 26.114)