Hell Visualization 1.1 - Book 2: Problems
- Transfer

- Book 1: Overview
- Book 2: Problems
- Book 3: Solutions
- Book 4: Conclusion
Welcome to the second book! Here we will explore some of the problems that may arise during the visualization process. But, for starters, a little practice:
Knowing about a problem is useful. But really feeling the problem is much better for understanding. Let's try putting ourselves in the place of the CPU / GPU.
Experiment
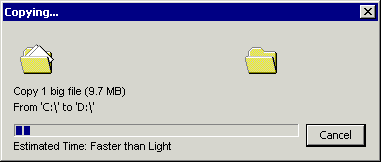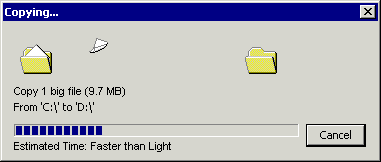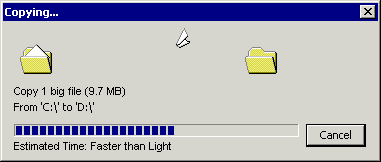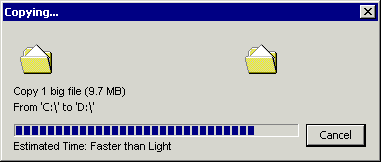
Please create 10,000 small files (for example, 1 KB each) and copy them from one hard drive to another. This operation will take a long time, although the data size is only 9.7 MB.
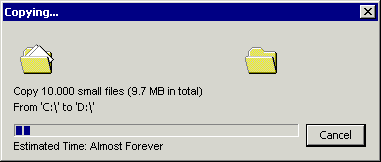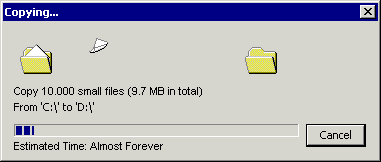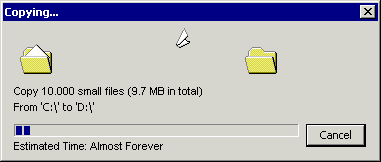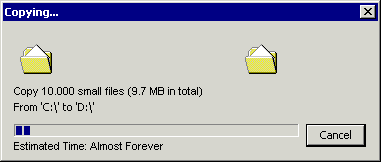
Now create one 9.7 MB file and copy it in the same way. This operation will be performed much faster!
Why? After all, the data size is the same!It’s true, but each copy operation consists of many things that need to be done, for example: prepare the file for moving, allocate memory, move the read / write heads of the drive back and forth ... All this is an overhead for each write operation. As you might have experienced in your own way, this overhead is huge if you copy a lot of small files. Visualization of many polygonal grids (that is, the execution of many commands) is much more complicated, but it feels similar.
Now let's look at the worst case that may arise during the visualization process.
Worst case
Having a lot of small polygon meshes is bad. If they use different material parameters, then everything becomes even worse. But why?
1. Many polygon meshes
The GPU can draw faster than the CPU to send commands.
The main reason for reducing the number of Draw Calls is that the graphics equipment can modify and render triangles much faster than you can transfer them. If you send a small number of triangles to each call, then you will find yourself completely connected by the CPU performance, and the GPU for the most part will be in standby mode. The CPU will not be able to “feed” the GPU fast enough. [ f05 ]
In addition, each Draw Call incurs some overhead (as mentioned above):
There is driver-level overhead whenever you make an API call, and the best way to reduce them is to call the API as little as possible. [ a02 ]
2. Many Draw Calls
One example of such additional overhead is the instruction buffer. Do you remember that the CPU fills the instruction buffer and the GPU reads it? Yes, they have to report changes and this also creates overhead (read / write pointers change, you can read more here )! For this reason, it may be better not to send commands one at a time, but to fill up the buffer first and transfer the entire block of commands to the GPU. This increases the risk that the GPU will have to wait until the CPU finishes building a block of commands, but at the same time reduces communication costs.
The GPU (fortunately) has a lot of things to do while the CPU is composing a new instruction buffer (for example, processing the previous block). Modern processors can fill several command buffers at once independently of each other, and then sequentially transfer them to the GPU.Only one example has been described above . In the real world, not only the CPU, GPU, and command buffers talk to each other. API (DirectX, OpenGL), drivers, and many other elements are included in this process, which does not make it easier.
We discussed only the case with many polygon meshes that use the same material (Render State). But what happens when we want to visualize objects with different materials?
3. Many polygon meshes and materials
Reset conveyor.
Changing the state, sometimes it is necessary to partially or completely reset the conveyor. For this reason, changing the shader or material parameters can be a very expensive operation [...] [ b01 ]You thought it wouldn't be any worse? So ... if you use different materials with different polygon meshes, you cannot group visualization commands. You set the Render State for the first grid, command to display it, then set a new Render State, send the next render command, and so on.
I painted the “Change State” team in red, because a) it is expensive and b) for readability.Setting Render State values sometimes (not always, depends on the parameters you want to change) entails resetting the entire pipeline. This means that each polygon mesh that is currently being processed (with the current Render State) must be displayed before the next one can be rendered (with the new Render State). It looks like the video above.
Instead of taking a huge number of vertices (for example, combining several grids with the same Render State. I’ll explain this optimization later), a small amount is displayed before the Render State change operation, which is obviously bad.
By the way: Since the CPU takes some minimal time to set the Draw Call parameters (regardless of the size of the polygon mesh), we can assumeno difference in the display of 2 or 200 triangles. The GPU is damn fast, and while the CPU prepares a new Draw Call, the triangles will already become newly made pixels on the screen. Of course, this “rule” will change when we talk about combining several small polygonal meshes into one big one (we will discuss this later).
I could not find the latest data on the number of polygons that can be visualized “for free” on modern graphics cards. If you know anything about this or have taken any measurements recently, please let me know!
4. Polygonal grids and multimaterials
What if a polygon mesh is assigned not one material, but two or more? Basically, the grid is torn into several pieces, and then partly "fed" to the command buffer.
Of course, this entails additional Draw Calls on each grid element.
I hope I was able to give you a quick idea of what's wrong with a large number of polygon meshes and materials. In the next book we will look at some solutions, even if all this looks awful. But there are wonderful games that prove that the problems described above were somehow overcome.
the end
[a02] GPU Programming Guide GeForce 8 and 9 Series
[b01] Real-Time Rendering : Page 711/712
[f05] Why are draw calls expensive