Ropes - Fast Lines
Hello, Habr.
Most of us work with strings one way or another. This cannot be avoided - if you write the code, you are doomed to fold the lines every day, break them into component parts and access individual characters by index. We have long been accustomed to the fact that strings are arrays of characters of a fixed length, and this entails the corresponding restrictions in working with them.
So, we cannot quickly combine the two lines - for this we need to first allocate the required amount of memory, and then copy the data from the concatenated lines there. Obviously, such an operation has complexity of the order of O (n), where n is the total length of the lines.
That is why the code
works so slowly.
Want to concatenate giant strings quickly? Do not like the fact that the string requires a contiguous region of memory for storage? Tired of using buffers to build strings?
The data structure that will save us is called the Rope string , or "rope string." The principle of its operation is very simple and can be guessed literally from intuitive considerations.
Suppose we need to add two lines:
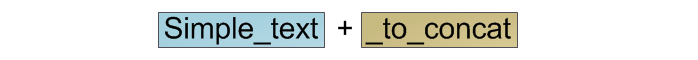
For classic lines, we simply select the memory area of the required size, copy the contents of the first line to the beginning, and the second to the end:
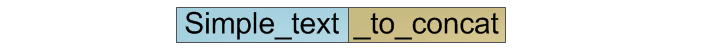
As mentioned above, the complexity of this operation is O (n).
But what if we use the information that our resulting string is a concatenation of the two source ones? Indeed, let's create an object that provides a string interface and stores information about its components - the source strings:

This way of combining strings works for O (1) - we only need to create a wrapper object for the source strings. Since this object is also a string, it can be combined with other strings to get the concatenations we need:
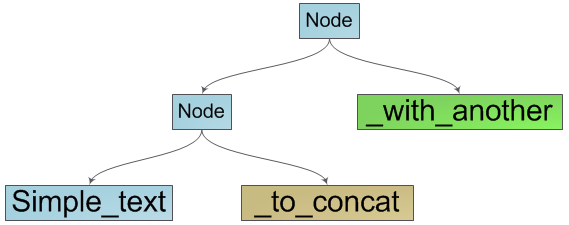
It is already obvious that our structure is a binary search tree, in the leaves of which are the elementary components of our line - a group of characters. It also becomes obvious how to enumerate the characters of a string - this is a traversal of the tree in depth with a sequential listing of characters in the leaves of the tree.
We now implement the operation of obtaining a string character by its index. To do this, we introduce an additional characteristic to the nodes of the tree - weight. If a part of symbols is stored directly in a tree node (node - leaf), then its weight is equal to the number of these symbols. Otherwise, the weight of the node is equal to the sum of the weights of its descendants. In other words, the weight of a node is the length of the string that it represents.
We need to get the ith character of the string represented by the Node node. Then two cases may arise:
Now we can concatenate strings for O (1) and index the characters in them for O (h) - the height of the tree. But for complete happiness, you need to learn how to quickly perform the operations of breaking into two lines, deleting and inserting a substring.
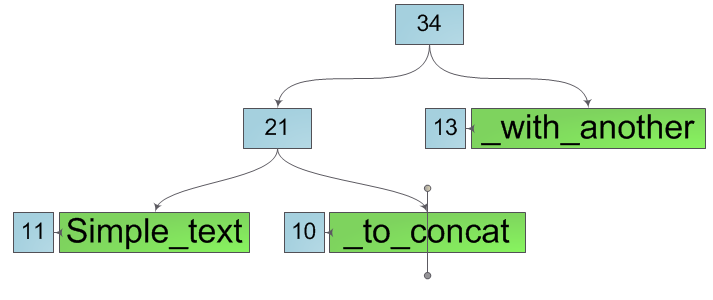
So, we have a line and it is extremely necessary for us to split it into two substrings in some of its position k (numbers in the diagram are the sizes of the corresponding trees):
The place of "line break" is always in one of the leaves of the tree. We divide this sheet into two new ones containing substrings of the original sheet. Moreover, for this operation we do not need to copy the contents of the sheet to new ones, just enter such characteristics of the sheet as offset and length and save pointers to the array of characters of the original in new sheets, changing only the offset and length:
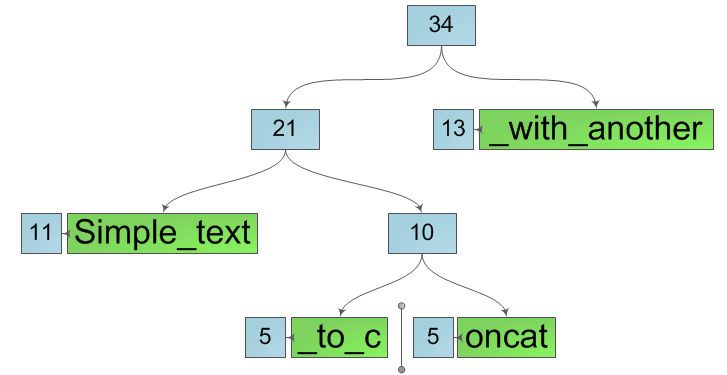
Next, we will split all the nodes along the path from the leaf to the root, creating instead of them pairs of nodes belonging, respectively, to the left and right substring being created. And we again do not change the current node, but only create two new ones instead. This means the line splitting operation spawns new substrings without affecting the original one. After splitting the original line, we get two new lines, as in the figure below.

It is easy to notice that the internal structure of such lines is not optimal - some are clearly superfluous. However, correcting this annoying omission is easy - it is enough to walk from the cut to the root in both substrings, replacing each node that has exactly one descendant with this same descendant. After that, all the extra nodes will disappear and we will get the required substrings in their final form:

The complexity of the string splitting operation is obviously O (h).
Thanks to the splitting and merging operations already implemented, the deletion and insertion are done elementarily - to delete a substring, it is enough to split the source line at the beginning and end of the deleted section and glue the last lines. To insert into strings at a specific position, we break the original string into two substrings in it and glue them with the inserted one in the desired order. Both operations have the asymptotic behavior of O (h).
An attentive reader, hearing the word “tree”, would inevitably recall the other two - “logarithm” and “balancing”. And, as always, in order to achieve the coveted logarithmic asymptotics, you still have to balance our tree. Indeed, with the current method of merging strings, the internal structure of the tree will look more like a “ladder”, for example, such as in the figure below:
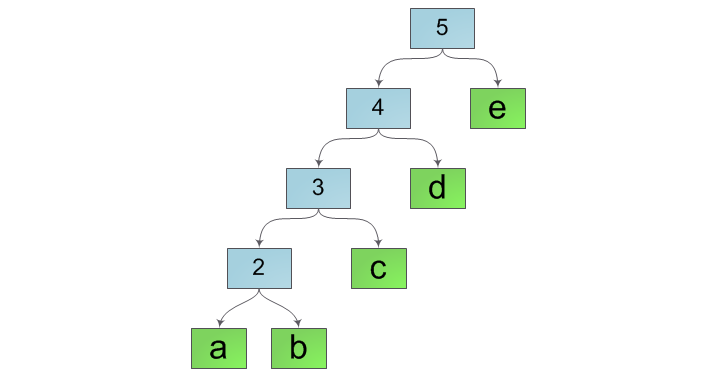
To avoid this, we will check the balance of the result at each combination of lines and, if necessary, rebuild the entire tree, balancing it. A good condition for balance is that the string length must be at least (h + 2) of the Fibonacci number. The rationale for this condition as well as a couple of additional modifications to the gluing operation were given by Boem, Atkinson and Plass in their work Ropes: an Alternative to Strings
Storing tree nodes in memory is not at all free. If we add one character to a string, then we will spend on storing information about tree nodes an order of magnitude more memory than the characters of the string themselves. In order to avoid such situations, as well as to reduce the height of the tree, it is advisable to glue lines shorter than a certain length (for example, 32) in a "classical" way. This will greatly save memory and also almost no effect on overall performance.
In the vast majority of cases, we iterate over the characters of a string sequentially. In our case, if we request symbols at the indices i and i + 1, the probability that they are physically located in the same leaf of the tree is very high. This means that when searching for these characters, we will repeat the same path from the root of the tree to the leaf. The obvious solution to this problem is caching. To do this, when searching for the next character, remember the sheet in which it is located and the range of indices that this sheet contains in itself. Then, when searching for the next character, we will first check whether our index is in the stored range and, if so, we will look for it directly in the stored sheet. You can even go further, remembering not one last position but several, for example, in a cyclic list.
Together with the previous optimization, this technique will allow us to improve the index asymptotics from O (ln (n)) to almost O (1).
What do we get as a result? We will get a persistent string implementation that does not require a continuous memory region for storage, with the logarithmic asymptotic behavior of insertion, deletion and concatenation (instead of O (n) in classical strings) and indexing almost O (1) - a result worthy of attention.
And finally, I’ll give you a couple of useful links: an article in the English wiki , a Java implementation, and a description of the C ++ implementation on the SGI website .
Use the ropes, Luke!
Most of us work with strings one way or another. This cannot be avoided - if you write the code, you are doomed to fold the lines every day, break them into component parts and access individual characters by index. We have long been accustomed to the fact that strings are arrays of characters of a fixed length, and this entails the corresponding restrictions in working with them.
So, we cannot quickly combine the two lines - for this we need to first allocate the required amount of memory, and then copy the data from the concatenated lines there. Obviously, such an operation has complexity of the order of O (n), where n is the total length of the lines.
That is why the code
string s = "";
for (int i = 0; i < 100000; i++) s += "a";works so slowly.
Want to concatenate giant strings quickly? Do not like the fact that the string requires a contiguous region of memory for storage? Tired of using buffers to build strings?
The data structure that will save us is called the Rope string , or "rope string." The principle of its operation is very simple and can be guessed literally from intuitive considerations.
Idea
Suppose we need to add two lines:
For classic lines, we simply select the memory area of the required size, copy the contents of the first line to the beginning, and the second to the end:
As mentioned above, the complexity of this operation is O (n).
But what if we use the information that our resulting string is a concatenation of the two source ones? Indeed, let's create an object that provides a string interface and stores information about its components - the source strings:
This way of combining strings works for O (1) - we only need to create a wrapper object for the source strings. Since this object is also a string, it can be combined with other strings to get the concatenations we need:
It is already obvious that our structure is a binary search tree, in the leaves of which are the elementary components of our line - a group of characters. It also becomes obvious how to enumerate the characters of a string - this is a traversal of the tree in depth with a sequential listing of characters in the leaves of the tree.
Indexing
We now implement the operation of obtaining a string character by its index. To do this, we introduce an additional characteristic to the nodes of the tree - weight. If a part of symbols is stored directly in a tree node (node - leaf), then its weight is equal to the number of these symbols. Otherwise, the weight of the node is equal to the sum of the weights of its descendants. In other words, the weight of a node is the length of the string that it represents.
We need to get the ith character of the string represented by the Node node. Then two cases may arise:
- Node - sheet. Then it contains the data directly and it is enough for us to return the i-th character of the "internal" string.
- The node is composite. Then you need to find out which descendant of the node should continue the search. If the weight of the left descendant is greater than i - the desired character is the i-th character of the left substring, otherwise it is the (iw) -th character of the right substring, where w is the weight of the left subtree.
Now we can concatenate strings for O (1) and index the characters in them for O (h) - the height of the tree. But for complete happiness, you need to learn how to quickly perform the operations of breaking into two lines, deleting and inserting a substring.
Breaking up
So, we have a line and it is extremely necessary for us to split it into two substrings in some of its position k (numbers in the diagram are the sizes of the corresponding trees):
The place of "line break" is always in one of the leaves of the tree. We divide this sheet into two new ones containing substrings of the original sheet. Moreover, for this operation we do not need to copy the contents of the sheet to new ones, just enter such characteristics of the sheet as offset and length and save pointers to the array of characters of the original in new sheets, changing only the offset and length:
Next, we will split all the nodes along the path from the leaf to the root, creating instead of them pairs of nodes belonging, respectively, to the left and right substring being created. And we again do not change the current node, but only create two new ones instead. This means the line splitting operation spawns new substrings without affecting the original one. After splitting the original line, we get two new lines, as in the figure below.
It is easy to notice that the internal structure of such lines is not optimal - some are clearly superfluous. However, correcting this annoying omission is easy - it is enough to walk from the cut to the root in both substrings, replacing each node that has exactly one descendant with this same descendant. After that, all the extra nodes will disappear and we will get the required substrings in their final form:
The complexity of the string splitting operation is obviously O (h).
Delete and Paste
Thanks to the splitting and merging operations already implemented, the deletion and insertion are done elementarily - to delete a substring, it is enough to split the source line at the beginning and end of the deleted section and glue the last lines. To insert into strings at a specific position, we break the original string into two substrings in it and glue them with the inserted one in the desired order. Both operations have the asymptotic behavior of O (h).
Optimization
Balancing
An attentive reader, hearing the word “tree”, would inevitably recall the other two - “logarithm” and “balancing”. And, as always, in order to achieve the coveted logarithmic asymptotics, you still have to balance our tree. Indeed, with the current method of merging strings, the internal structure of the tree will look more like a “ladder”, for example, such as in the figure below:
To avoid this, we will check the balance of the result at each combination of lines and, if necessary, rebuild the entire tree, balancing it. A good condition for balance is that the string length must be at least (h + 2) of the Fibonacci number. The rationale for this condition as well as a couple of additional modifications to the gluing operation were given by Boem, Atkinson and Plass in their work Ropes: an Alternative to Strings
Direct concatenation of small lines
Storing tree nodes in memory is not at all free. If we add one character to a string, then we will spend on storing information about tree nodes an order of magnitude more memory than the characters of the string themselves. In order to avoid such situations, as well as to reduce the height of the tree, it is advisable to glue lines shorter than a certain length (for example, 32) in a "classical" way. This will greatly save memory and also almost no effect on overall performance.
Last position caching
In the vast majority of cases, we iterate over the characters of a string sequentially. In our case, if we request symbols at the indices i and i + 1, the probability that they are physically located in the same leaf of the tree is very high. This means that when searching for these characters, we will repeat the same path from the root of the tree to the leaf. The obvious solution to this problem is caching. To do this, when searching for the next character, remember the sheet in which it is located and the range of indices that this sheet contains in itself. Then, when searching for the next character, we will first check whether our index is in the stored range and, if so, we will look for it directly in the stored sheet. You can even go further, remembering not one last position but several, for example, in a cyclic list.
Together with the previous optimization, this technique will allow us to improve the index asymptotics from O (ln (n)) to almost O (1).
Total
What do we get as a result? We will get a persistent string implementation that does not require a continuous memory region for storage, with the logarithmic asymptotic behavior of insertion, deletion and concatenation (instead of O (n) in classical strings) and indexing almost O (1) - a result worthy of attention.
And finally, I’ll give you a couple of useful links: an article in the English wiki , a Java implementation, and a description of the C ++ implementation on the SGI website .
Use the ropes, Luke!