An example of writing functional requirements for an Enterprise system
Recently, my friend, a programmer, said that he does not read the requirements, but instead invites the analyst to a cup of tea, they sit down together, and the analyst tells what should be realized. My friend is an intelligent person and a good programmer, and the reason why he gets knowledge of the requirements in this way is not because he is too lazy to read the documentation, but because even after reading it, he will not fully understand what is needed to do. In this article I want to tell how it is possible to write requirements for a software product so that programmers not only use requirements, but also participate in their writing; based on the actual experience, I want to show how you can describe the requirements so that these descriptions are sufficient for the implementation of the system.
The aim of our development was to create from scratch an accounting system for one of the largest Russian companies. The system was designed to replace the current one written in the late 90s. As a result, a platform and one of the business modules were implemented. In the realized part there were about 120 objects, 180 tables, about 30 printing forms.
I want to make a reservation that the approach described below is not universal for writing any software. It is suitable for enterprise-level systems, which are built on the basis of an object-oriented approach: accounting, CRM, ERP systems, workflow systems, etc.
All documentation for our software product consisted of the following sections:
The general part consisted of only two sections: a list of terms and their definitions and descriptions of user business roles. Any documentation on the system, including, for example, test scripts, relied on the definitions given here.
Business requirements described what business users needed. For example, they don’t need the User system object at all, but they need to be able to change the value of the goods in the invoice and print it. Business requirements consisted of common scenarios, use cases and descriptions of data processing algorithms. Details on the development of such requirements can be found in the book by Karl I. Wigers and Joey Beatty Software Requirements Development .
System requirementsdescribed the properties and methods of all objects in the system.
Non-functional requirements in this article we will not concern. I can only refer you to the excellent book Architecting Enterprise Solutions by Paul Dyson, Andrew Longshaw.
The integration requirements described a low-level interface for the interaction of the new system with several other systems of the company. We will not consider them here.
User interface requirements are a separate big topic, perhaps for another article.
Also here I will not touch on other sections of the documentation that relate to implementation, testing, guides, and management.
Let's take a closer look at what a list of terms is and why it is needed.
Very often, when discussing the functionality of the system, the conversation comes to a standstill. Even worse, if the parties disagree, thinking that they have agreed on everything, but as a result have a different understanding of what needs to be done. This is not the last degree due to the fact that initially the project participants could not agree on what these or other terms mean. It happens that even the simplest words cause problems: what is a user, how does a group differ from a role, who is a client. Therefore, unlike the description of business roles for terms, it is necessary to give as precise definitions as possible.
I will explain this using the term User as an example . Wikipedia gives the following definition:
User- A person or organization that uses an existing system to perform a specific function.
But it did not suit us for several reasons. First, only a person can enter the system, but not the organization. Secondly, for our system the present tense of the verb “uses” is incorrect - the system stores data about inactive or deleted users, i.e. about those who have used the system before but cannot at the moment. And finally, we have data about potential users. For example, we register an employee of a client company who may later gain (or may not) access to the system. Our definition:
User - a person who has, had, or, possibly, will have access to the system to perform operations.
Now the programmer, having read the definition, will immediately understand why the Login property in the User object is optional.
The terms are related to each other. The term “operation” is used in the User term, therefore I will give its definition:
Operation is a set of actions that comprise the content of one act of business activity. The operation must comply with the requirements of ACID (Atomicity, Consistency, Isolation, Durability). The set of operations of one module represents the client-server interface of this module.
As you can see, this definition is very important for the whole system - it not only connects the user and his business actions with what should be implemented, but also imposes requirements on HOW the system should be implemented (this HOW was determined earlier in the development of architecture ) - business actions inside an operation must be inside a transaction.
Work on the list of terms was ongoing. We maintained its completeness, i.e. they tried so that the documentation did not have a term that was not defined on this list. In addition, there were times when we changed terms. For example, after several months from the beginning of the writing of the requirements, we decided to replace the Counterparty with the Company. The reason was simple: it turned out that no one was able to use the word "counterparty" in a conversation. And if so, then it should have been replaced by something more harmonious.
Often there have been cases when you had to interrupt the discussion and go into the requirements in order to understand whether the discussed functionality is suitable for existing definitions. And in order to maintain the consistency of requirements, we ultimately had to either change the implementation or adjust the description of the terms.
As a result, we had about 200 business and system definitions in the list, which we used not only in all the documentation, including, for example, the technical design developed by programmers, but also in conversation, when verbally discussing the functionality of the system.
The second part, on which all the documentation relied, was a description of business roles.
Everyone knows what users use the system. But even in a small system, they have different rights and / or roles. Probably the easiest division is the administrator and the average user. In a large system of roles, there can be several dozen, and the analyst needs to think about it in advance and indicate roles in describing common scenarios (see below) and in the headers of use cases. The list of business roles is used to implement user groups and roles, assign functional rights to them, it is necessary for testers to test scripts under the necessary roles.
We did not have to invent the business roles of users, since the company had well-established departments, roles, functions. A description of the roles was given at a qualitative level based on an analysis of the basic functions of employees. The final assignment of roles to specific rights took place toward the end of development, when the set of functional rights became stable.
A couple of examples:

One of the important concepts that we applied in developing requirements was dividing them into levels. Alistair Coburn in the book Modern Methods for Describing the Functional Requirements for Systems identifies 5 levels. We used 4 - three levels of business requirements plus system requirements:
Business requirements
4. System requirements (there is no direct analogue, rather black).
In addition, our requirements were a tree (with cycles). Those. common scenarios were refined by usage scenarios, which, in turn, had links to checks and algorithms. Since we used wiki, the physical implementation of such a structure was not a problem. Usage scenarios, algorithms and checks used objects, their properties and methods described at the system level.
Such a methodology allowed us, on the one hand, to describe the current scenario in as much detail as needed at a given level, taking details to the lower level. On the other hand, being at any level one could rise higher to understand the context of its implementation. This was also provided by the wiki functionality: scripts and algorithms were written on separate pages, and the wiki allowed you to see which pages link to the current one. If the algorithm was used in several scenarios, then it was necessarily submitted to a separate page. Programmers usually implemented such fragments as separate methods.
The picture below shows part of our hierarchy (we will talk about the content further).

It is important to note that if the system level described all system objects without exception, then the scripts were not written for all cases of user behavior. Indeed, many objects, in fact, were directories, and the requirements for them are more or less obvious and similar. Thus, we saved the analyst’s time.
An interesting question is to whom in the project team which level is needed. Future users can read common scripts. But usage scenarios are already complex for them, so the analyst usually discusses the scenarios with users, but does not give them to them for independent study. Programmers usually need algorithms, checks, and system requirements. You can definitely respect a programmer who reads use cases. Testers (as well as analysts) need all levels of requirements, since they have to test the system at all levels.
Using wiki allowed working on requirements in parallel to all members of the project team. I note that at the same moment the different parts of the requirements were in different states: from those in work to those already implemented.
The root page of our requirements tree consisted of common scenarios, each of which described one of the 24 business processes to be implemented in this module. The scripts on the page were located in the order in which they were carried out in the company: from creating an object with goods sold, to transferring them to a client. Some specific or supporting scenarios were placed at the end in a separate section.
A common scenario is a sequence of steps by the user and the system to achieve a specific goal. Descriptions of common scenarios were significantly less formal than use cases, since they were not intended to be implemented. The main goal of the general scenario is to generalize usage scenarios, rise above the system and see what the user ultimately wants to do, and how the system helps him in this. I want to note that the common scenarios also contained the steps that the user took outside the system, since it was necessary to reflect his work in its entirety, with all the steps necessary to achieve the business goal. At this level, the role of the system in the work of an employee of the company is clearly visible, which part of this work is automated and which is not. It was here that it became clear
Some other goals of common scenarios:
Here is an example of one of the common scenarios:

As you can see, only half of the steps are automated, and even those are described as briefly as possible. It is also seen from the first step that manual translation of a print job into the 'In Work' status is, in principle, superfluous, you can simplify the user’s work and automatically transfer the job to this status when printing.
The link "Print job", indicating the description of the object in the system requirements, is superfluous, since no one needs to jump on it from the general scenario. But the link “batch printing of documents for the goods” is important - it leads to a use case that formally describes the actions of the user and the system.
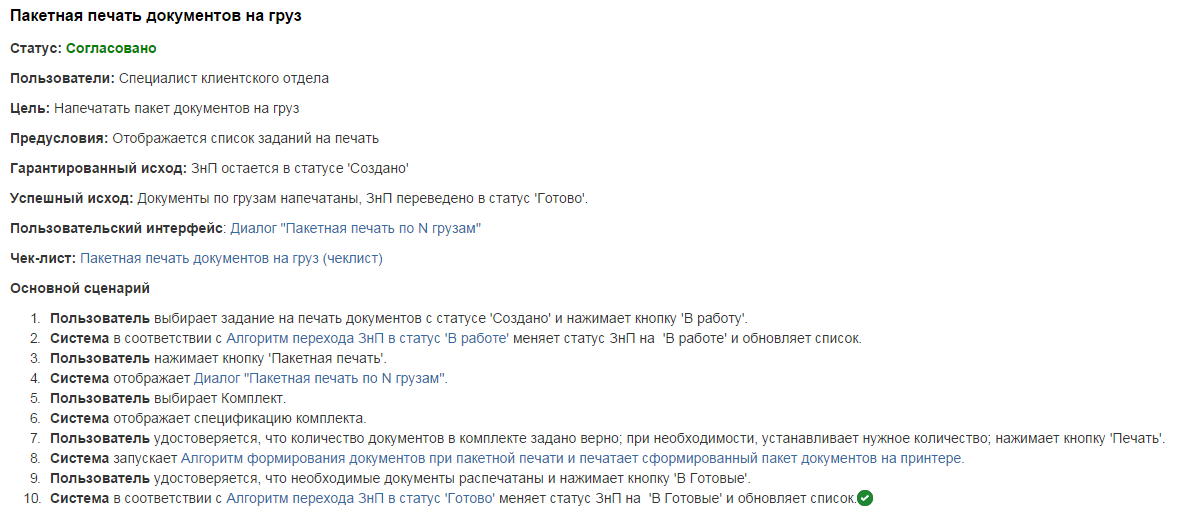
Our usage scenarios were in the following format:
The use case contained numbered steps, which in 99% of cases obviously began with the words User or System . Numbering is important because it allowed in questions and comments to refer to the desired item. Each step is usually a simple sentence in the present tense. Checks and algorithms were carried to the next level and often on separate pages in order to simplify the perception of the script, as well as for reuse.
Here is a use case referenced by the general scenario above.
Often, analysts draw a user interface and write scripts based on it, explaining this in a way that is more clear. There is some truth in this, but we held the position that the interface is the business of the interface designer. First, the analyst describes what should happen, and then the interface designer draws a thumbnail of the web page or dialog. At the same time, it happened that the script had to be changed. There is nothing to worry about, because our goal is to design all parts of the system so that it is convenient for the user. At the same time, each member of the project team, whether an analyst or an interface designer, having specific knowledge and contributing to the common cause, has an impact on the work of other members of the project team. Only together, joining forces, you can get an excellent result.
An interesting problem arose when writing algorithms. The analyst tried to describe them as fully as possible, i.e. include all possible checks and branches. However, the resulting texts turned out to be poorly readable, and, as a rule, anyway, some details were missed (probably, the lack of a compiler affected). Therefore, the analyst should describe the algorithm as fully as it is important in terms of business logic, the programmer himself must provide secondary checks in the code.
For example, consider a simple algorithm below.

Only one check is indicated in the algorithm, but it is obvious that when writing the method code, the programmer must implement checks on the input parameters; throw an exception if the current user is not defined, etc. Also, the programmer can combine this algorithm with algorithms for switching to other statuses and write a single non-public method. At the API level, the same operations will remain, but they will call a single method with parameters. Choosing the best implementation of algorithms is just the competence of the programmer.
As you know, programming is the development and implementation of data structures and algorithms. Thus, by and large, all that a programmer needs to know is the data structures necessary for implementing the system and the algorithms that manipulate them.
In developing the system, we used an object-oriented approach, and since OOP is based on the concepts of a class and an object, our data structures are class descriptions. The term "class" is specific to programming, so we used the "object". T.O. the object in the requirements is equal to the class in the object-oriented programming language (in parentheses I note that in a couple of sections of the requirements I had to go out in order to separate an object-class and an object-instance of this class in the text).
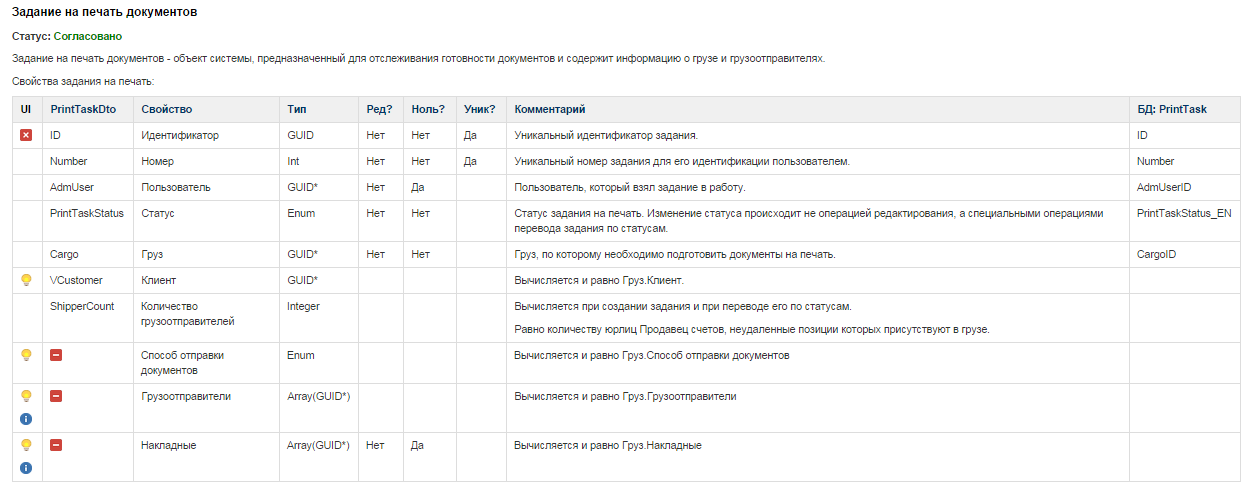
The description of each object was located on one wiki page and consisted of the following parts:
We tried to describe everything that is possible in tabular form, since the table is more visual, its structure helps to organize information, and the table is well extensible.
The first table of each object described the attributes of its properties necessary for the programmer to be able to create data structures in the database and implement the object on the application server:
Name
The name of the property operates as a user (for example, “I changed the account number”, Number - property of the Account object) and the project team. Throughout the documentation, property references were used in the form of a simple Object notation. The property is obvious to any project participant.
A type
We used Datetime, Date, Time, GUID, String, Enum, Int, Money, BLOB, Array (), Float, Timezone, TimeSpan. The type was reflected at all levels of the application: at the level of the database, application server, in the user interface in the form of code and graphical representation. Each type was given a definition so that their implementation does not raise questions among programmers. For example, such a definition was given to the Money type: it contains a real number accurate to the 4th decimal place, the number can be negative and positive; simultaneously with the value, the system stores the currency; The default currency is Russian ruble.
Sign of editable
Yes or Nodepending on whether the system allows users to change the value of this property in the editing operation. In our system, this restriction was implemented on the application server and in the user interface.
A sign of the presence of zero
Yes or No depending on whether the field does not contain values. For example, a field of type Bool must contain one of the possible values, and a field of type String can usually be empty ( NULL ). This restriction was implemented at the database level and at the application server.
Sign of uniqueness
Yes or Nodepending on whether this field is unique. Often, uniqueness is determined by a group of fields, in this case, all fields in the group had Yes + . This restriction was implemented at the database level (index) and at the application server.
Comment
Field description: what it means, what it is for, how it is used. If the property value is calculated, then this is indicated explicitly with a description of the algorithm for calculating this value.
In addition to these, there were two more columns that were filled in by the programmers of the server part when implementing the object:
Both of these fields are optional, because, for example, the property of an object may not be stored in the database, but be calculated as the invoice amount.
I want to once again draw attention to the fact that programmers took part in writing the requirements. This is important for many reasons. Firstly, in this way, programmers were better aware of the requirements, moreover, the requirements became “closer to the body,” and not just a piece of paper written by some analyst. Secondly, documentation for the API was automatically generated. Thirdly, traceability of requirements was supported, i.e. it was always clear whether this or that property was implemented, which became especially important when modifying requirements. Of course, this methodology required more discipline from programmers, which in fact was a positive factor.
In addition, thanks to these columns, programmers working on different levels of the application, it was always possible to find a common language, i.e. understand the correspondence between the property of the object in the requirements, the field in the database and the property in the API.
As I already wrote, the table view is very convenient for expansion. For example, to describe the initial migration, we had a column with the property name of the old system or the data conversion algorithm. We also used special icons to describe how an object looks in the user interface. At one time, we had a column for the index name in the database so that programmers would not forget to create them for unique fields. If necessary, you can add a column with the dimension of data types for each property.
Here is a typical description of the properties of our object.
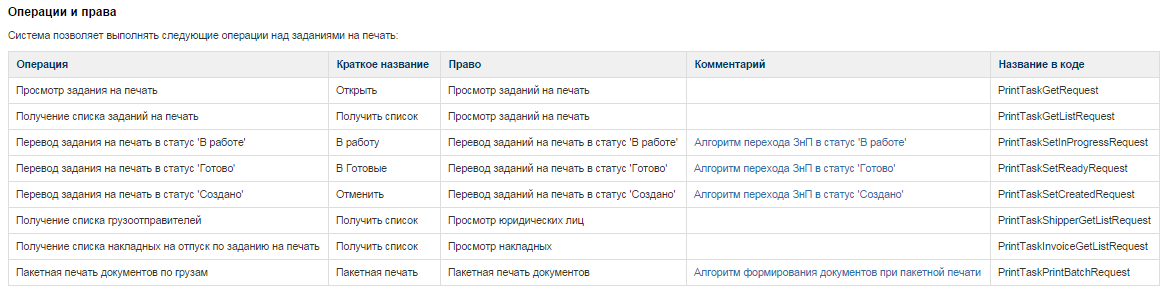
The second table of the object contained a description of its operations and their rights. Each operation in the system had a unique name ( Operation column ), but in the user interface (in the menu), operations were displayed under short names ( Short name ). To perform any operation, one had to have a certain right ( Right ). The Comment column for complex methods contained a description of the algorithm or a link to it or a more general use case. CRUD operations on all types of objects were standardized, so algorithms were usually not required for them.
Column Name in codeit was again filled in by the programmer, which, as in the description of the object, was necessary to document the API, to increase the involvement of programmers in writing requirements and traceability. Below is an example of a description of object operations:
In this section, there were also tables describing the transition by status.
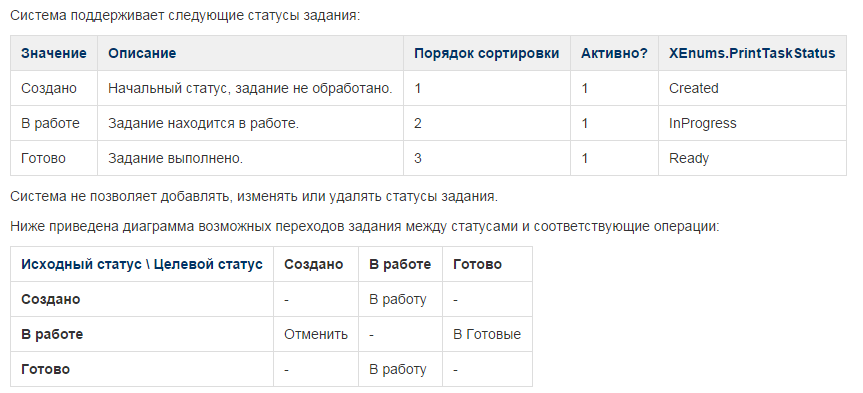
The cells contain a short name for the operation, which translates the source status into the target one. For more complex cases, you had to draw full-fledged diagrams.
After the installation of the system, certain data must be present in it. For example, a user with administrator rights or a list of countries according to the all-Russian classifier of countries of the world. These data were described in the Data section .
Everything that did not fit into the standard sections above went to the sectionAdditional information . For example, we had information on the relations of this object with the old system.
Summing up, we can say that the system requirements for the object contained all the necessary information for its implementation by the programmer: the data structure in the database, a description of the domain object, restrictions on data and methods, algorithms for implementing methods, data that should be during the installation of the system. The description structure is easy to understand and extensible.
Many will say that such detailing of requirements is time consuming and not necessary. What I would object to - but how does the programmer guess what exactly needs to be implemented? Is the phrase “You must implement the User object” enough to get working code after some time? How much tea do you need to drink with the analyst in order to extract data from him on 40 (we had so many) user properties? Who, if not an analyst or designer, should make an effort and describe all the objects?
After describing what the requirements look like, consider an interesting question: how should the tasks for programmers be formulated (we restrict ourselves to the server side of a multi-tier application)? It turns out that most tasks (not defects) come down to three options:
Typical task 1
Heading: Implement such an object.
The text of the task is a link to a page with system requirements for the object.
In such a task, the programmer needs:
Typical task 2
Title: Implement such-and-such operation of such-and-such object and rights to it.
The task text is a link to a page with system requirements for the object.
The programmer finds on the page the name of the operation and rights, and through the link in the Comment column - algorithms, checks, usage scenario.
Typical task 3
Title: Correct an object and / or operation.
This task is necessary in case of changes in requirements. The task text contains a description of the changes or a link to the requirements version comparison page.
As many may have guessed, we used Atlassian Confluence to work with the requirements. I want to briefly list the advantages of this product.
However, there were several problems:
In the end, I want to thank Vadim Loboda and Artem Karateev for valuable advice and a thorough review of this article.
Anton Stasevich
The aim of our development was to create from scratch an accounting system for one of the largest Russian companies. The system was designed to replace the current one written in the late 90s. As a result, a platform and one of the business modules were implemented. In the realized part there were about 120 objects, 180 tables, about 30 printing forms.
I want to make a reservation that the approach described below is not universal for writing any software. It is suitable for enterprise-level systems, which are built on the basis of an object-oriented approach: accounting, CRM, ERP systems, workflow systems, etc.
All documentation for our software product consisted of the following sections:
- General
• List of terms and definitions
• Description of business roles - Requirements
• Business Requirements- Common Scenarios
- Use cases
- Algorithms and checks
• Non-functional requirements
• Integration
requirements • User interface requirements - Implementation
- Testing
- Guides
- Control
The general part consisted of only two sections: a list of terms and their definitions and descriptions of user business roles. Any documentation on the system, including, for example, test scripts, relied on the definitions given here.
Business requirements described what business users needed. For example, they don’t need the User system object at all, but they need to be able to change the value of the goods in the invoice and print it. Business requirements consisted of common scenarios, use cases and descriptions of data processing algorithms. Details on the development of such requirements can be found in the book by Karl I. Wigers and Joey Beatty Software Requirements Development .
System requirementsdescribed the properties and methods of all objects in the system.
Non-functional requirements in this article we will not concern. I can only refer you to the excellent book Architecting Enterprise Solutions by Paul Dyson, Andrew Longshaw.
The integration requirements described a low-level interface for the interaction of the new system with several other systems of the company. We will not consider them here.
User interface requirements are a separate big topic, perhaps for another article.
Also here I will not touch on other sections of the documentation that relate to implementation, testing, guides, and management.
Let's take a closer look at what a list of terms is and why it is needed.
List of Terms and Definitions
Very often, when discussing the functionality of the system, the conversation comes to a standstill. Even worse, if the parties disagree, thinking that they have agreed on everything, but as a result have a different understanding of what needs to be done. This is not the last degree due to the fact that initially the project participants could not agree on what these or other terms mean. It happens that even the simplest words cause problems: what is a user, how does a group differ from a role, who is a client. Therefore, unlike the description of business roles for terms, it is necessary to give as precise definitions as possible.
I will explain this using the term User as an example . Wikipedia gives the following definition:
User- A person or organization that uses an existing system to perform a specific function.
But it did not suit us for several reasons. First, only a person can enter the system, but not the organization. Secondly, for our system the present tense of the verb “uses” is incorrect - the system stores data about inactive or deleted users, i.e. about those who have used the system before but cannot at the moment. And finally, we have data about potential users. For example, we register an employee of a client company who may later gain (or may not) access to the system. Our definition:
User - a person who has, had, or, possibly, will have access to the system to perform operations.
Now the programmer, having read the definition, will immediately understand why the Login property in the User object is optional.
The terms are related to each other. The term “operation” is used in the User term, therefore I will give its definition:
Operation is a set of actions that comprise the content of one act of business activity. The operation must comply with the requirements of ACID (Atomicity, Consistency, Isolation, Durability). The set of operations of one module represents the client-server interface of this module.
As you can see, this definition is very important for the whole system - it not only connects the user and his business actions with what should be implemented, but also imposes requirements on HOW the system should be implemented (this HOW was determined earlier in the development of architecture ) - business actions inside an operation must be inside a transaction.
Work on the list of terms was ongoing. We maintained its completeness, i.e. they tried so that the documentation did not have a term that was not defined on this list. In addition, there were times when we changed terms. For example, after several months from the beginning of the writing of the requirements, we decided to replace the Counterparty with the Company. The reason was simple: it turned out that no one was able to use the word "counterparty" in a conversation. And if so, then it should have been replaced by something more harmonious.
Often there have been cases when you had to interrupt the discussion and go into the requirements in order to understand whether the discussed functionality is suitable for existing definitions. And in order to maintain the consistency of requirements, we ultimately had to either change the implementation or adjust the description of the terms.
As a result, we had about 200 business and system definitions in the list, which we used not only in all the documentation, including, for example, the technical design developed by programmers, but also in conversation, when verbally discussing the functionality of the system.
The second part, on which all the documentation relied, was a description of business roles.
Description of Business Roles
Everyone knows what users use the system. But even in a small system, they have different rights and / or roles. Probably the easiest division is the administrator and the average user. In a large system of roles, there can be several dozen, and the analyst needs to think about it in advance and indicate roles in describing common scenarios (see below) and in the headers of use cases. The list of business roles is used to implement user groups and roles, assign functional rights to them, it is necessary for testers to test scripts under the necessary roles.
We did not have to invent the business roles of users, since the company had well-established departments, roles, functions. A description of the roles was given at a qualitative level based on an analysis of the basic functions of employees. The final assignment of roles to specific rights took place toward the end of development, when the set of functional rights became stable.
A couple of examples:
Requirement levels
One of the important concepts that we applied in developing requirements was dividing them into levels. Alistair Coburn in the book Modern Methods for Describing the Functional Requirements for Systems identifies 5 levels. We used 4 - three levels of business requirements plus system requirements:
Business requirements
- General scenarios (corresponds to the level of very white in Coburn)
- Usage Scenarios (Blue)
- Algorithms and checks (rather black)
4. System requirements (there is no direct analogue, rather black).
In addition, our requirements were a tree (with cycles). Those. common scenarios were refined by usage scenarios, which, in turn, had links to checks and algorithms. Since we used wiki, the physical implementation of such a structure was not a problem. Usage scenarios, algorithms and checks used objects, their properties and methods described at the system level.
Such a methodology allowed us, on the one hand, to describe the current scenario in as much detail as needed at a given level, taking details to the lower level. On the other hand, being at any level one could rise higher to understand the context of its implementation. This was also provided by the wiki functionality: scripts and algorithms were written on separate pages, and the wiki allowed you to see which pages link to the current one. If the algorithm was used in several scenarios, then it was necessarily submitted to a separate page. Programmers usually implemented such fragments as separate methods.
The picture below shows part of our hierarchy (we will talk about the content further).
It is important to note that if the system level described all system objects without exception, then the scripts were not written for all cases of user behavior. Indeed, many objects, in fact, were directories, and the requirements for them are more or less obvious and similar. Thus, we saved the analyst’s time.
An interesting question is to whom in the project team which level is needed. Future users can read common scripts. But usage scenarios are already complex for them, so the analyst usually discusses the scenarios with users, but does not give them to them for independent study. Programmers usually need algorithms, checks, and system requirements. You can definitely respect a programmer who reads use cases. Testers (as well as analysts) need all levels of requirements, since they have to test the system at all levels.
Using wiki allowed working on requirements in parallel to all members of the project team. I note that at the same moment the different parts of the requirements were in different states: from those in work to those already implemented.
Business requirements
Common Scenarios
The root page of our requirements tree consisted of common scenarios, each of which described one of the 24 business processes to be implemented in this module. The scripts on the page were located in the order in which they were carried out in the company: from creating an object with goods sold, to transferring them to a client. Some specific or supporting scenarios were placed at the end in a separate section.
A common scenario is a sequence of steps by the user and the system to achieve a specific goal. Descriptions of common scenarios were significantly less formal than use cases, since they were not intended to be implemented. The main goal of the general scenario is to generalize usage scenarios, rise above the system and see what the user ultimately wants to do, and how the system helps him in this. I want to note that the common scenarios also contained the steps that the user took outside the system, since it was necessary to reflect his work in its entirety, with all the steps necessary to achieve the business goal. At this level, the role of the system in the work of an employee of the company is clearly visible, which part of this work is automated and which is not. It was here that it became clear
Some other goals of common scenarios:
- streamlining knowledge about user and system work
- coordination of business processes with future users
- basis for understanding that the requirements are complete, that nothing is missing
- entry point when searching for the desired script or algorithm
Here is an example of one of the common scenarios:
As you can see, only half of the steps are automated, and even those are described as briefly as possible. It is also seen from the first step that manual translation of a print job into the 'In Work' status is, in principle, superfluous, you can simplify the user’s work and automatically transfer the job to this status when printing.
The link "Print job", indicating the description of the object in the system requirements, is superfluous, since no one needs to jump on it from the general scenario. But the link “batch printing of documents for the goods” is important - it leads to a use case that formally describes the actions of the user and the system.
Our usage scenarios were in the following format:
- A title with the following fields:
• status (In progress | Ready to review | Agreed)
• users (according to the description of business roles)
• purpose
• preconditions
• guaranteed outcome
• successful outcome
• link to the description of the user interface (developed by the interface designer)
• link to test script (filled by testers) - Main scenario
- Script extensions
Use cases
The use case contained numbered steps, which in 99% of cases obviously began with the words User or System . Numbering is important because it allowed in questions and comments to refer to the desired item. Each step is usually a simple sentence in the present tense. Checks and algorithms were carried to the next level and often on separate pages in order to simplify the perception of the script, as well as for reuse.
Here is a use case referenced by the general scenario above.
Often, analysts draw a user interface and write scripts based on it, explaining this in a way that is more clear. There is some truth in this, but we held the position that the interface is the business of the interface designer. First, the analyst describes what should happen, and then the interface designer draws a thumbnail of the web page or dialog. At the same time, it happened that the script had to be changed. There is nothing to worry about, because our goal is to design all parts of the system so that it is convenient for the user. At the same time, each member of the project team, whether an analyst or an interface designer, having specific knowledge and contributing to the common cause, has an impact on the work of other members of the project team. Only together, joining forces, you can get an excellent result.
Algorithms and checks
An interesting problem arose when writing algorithms. The analyst tried to describe them as fully as possible, i.e. include all possible checks and branches. However, the resulting texts turned out to be poorly readable, and, as a rule, anyway, some details were missed (probably, the lack of a compiler affected). Therefore, the analyst should describe the algorithm as fully as it is important in terms of business logic, the programmer himself must provide secondary checks in the code.
For example, consider a simple algorithm below.
Only one check is indicated in the algorithm, but it is obvious that when writing the method code, the programmer must implement checks on the input parameters; throw an exception if the current user is not defined, etc. Also, the programmer can combine this algorithm with algorithms for switching to other statuses and write a single non-public method. At the API level, the same operations will remain, but they will call a single method with parameters. Choosing the best implementation of algorithms is just the competence of the programmer.
System requirements
As you know, programming is the development and implementation of data structures and algorithms. Thus, by and large, all that a programmer needs to know is the data structures necessary for implementing the system and the algorithms that manipulate them.
In developing the system, we used an object-oriented approach, and since OOP is based on the concepts of a class and an object, our data structures are class descriptions. The term "class" is specific to programming, so we used the "object". T.O. the object in the requirements is equal to the class in the object-oriented programming language (in parentheses I note that in a couple of sections of the requirements I had to go out in order to separate an object-class and an object-instance of this class in the text).
The description of each object was located on one wiki page and consisted of the following parts:
- Definition of an object (copy from the list of terms)
- Description of object properties
- Description of operations and rights
- Data
- Additional Information
We tried to describe everything that is possible in tabular form, since the table is more visual, its structure helps to organize information, and the table is well extensible.
The first table of each object described the attributes of its properties necessary for the programmer to be able to create data structures in the database and implement the object on the application server:
Name
The name of the property operates as a user (for example, “I changed the account number”, Number - property of the Account object) and the project team. Throughout the documentation, property references were used in the form of a simple Object notation. The property is obvious to any project participant.
A type
We used Datetime, Date, Time, GUID, String, Enum, Int, Money, BLOB, Array (), Float, Timezone, TimeSpan. The type was reflected at all levels of the application: at the level of the database, application server, in the user interface in the form of code and graphical representation. Each type was given a definition so that their implementation does not raise questions among programmers. For example, such a definition was given to the Money type: it contains a real number accurate to the 4th decimal place, the number can be negative and positive; simultaneously with the value, the system stores the currency; The default currency is Russian ruble.
Sign of editable
Yes or Nodepending on whether the system allows users to change the value of this property in the editing operation. In our system, this restriction was implemented on the application server and in the user interface.
A sign of the presence of zero
Yes or No depending on whether the field does not contain values. For example, a field of type Bool must contain one of the possible values, and a field of type String can usually be empty ( NULL ). This restriction was implemented at the database level and at the application server.
Sign of uniqueness
Yes or Nodepending on whether this field is unique. Often, uniqueness is determined by a group of fields, in this case, all fields in the group had Yes + . This restriction was implemented at the database level (index) and at the application server.
Comment
Field description: what it means, what it is for, how it is used. If the property value is calculated, then this is indicated explicitly with a description of the algorithm for calculating this value.
In addition to these, there were two more columns that were filled in by the programmers of the server part when implementing the object:
- The name of the property of the object in the program interface.
- The name of the field in the database.
Both of these fields are optional, because, for example, the property of an object may not be stored in the database, but be calculated as the invoice amount.
I want to once again draw attention to the fact that programmers took part in writing the requirements. This is important for many reasons. Firstly, in this way, programmers were better aware of the requirements, moreover, the requirements became “closer to the body,” and not just a piece of paper written by some analyst. Secondly, documentation for the API was automatically generated. Thirdly, traceability of requirements was supported, i.e. it was always clear whether this or that property was implemented, which became especially important when modifying requirements. Of course, this methodology required more discipline from programmers, which in fact was a positive factor.
In addition, thanks to these columns, programmers working on different levels of the application, it was always possible to find a common language, i.e. understand the correspondence between the property of the object in the requirements, the field in the database and the property in the API.
As I already wrote, the table view is very convenient for expansion. For example, to describe the initial migration, we had a column with the property name of the old system or the data conversion algorithm. We also used special icons to describe how an object looks in the user interface. At one time, we had a column for the index name in the database so that programmers would not forget to create them for unique fields. If necessary, you can add a column with the dimension of data types for each property.
Here is a typical description of the properties of our object.
The second table of the object contained a description of its operations and their rights. Each operation in the system had a unique name ( Operation column ), but in the user interface (in the menu), operations were displayed under short names ( Short name ). To perform any operation, one had to have a certain right ( Right ). The Comment column for complex methods contained a description of the algorithm or a link to it or a more general use case. CRUD operations on all types of objects were standardized, so algorithms were usually not required for them.
Column Name in codeit was again filled in by the programmer, which, as in the description of the object, was necessary to document the API, to increase the involvement of programmers in writing requirements and traceability. Below is an example of a description of object operations:
In this section, there were also tables describing the transition by status.
The cells contain a short name for the operation, which translates the source status into the target one. For more complex cases, you had to draw full-fledged diagrams.
After the installation of the system, certain data must be present in it. For example, a user with administrator rights or a list of countries according to the all-Russian classifier of countries of the world. These data were described in the Data section .
Everything that did not fit into the standard sections above went to the sectionAdditional information . For example, we had information on the relations of this object with the old system.
Summing up, we can say that the system requirements for the object contained all the necessary information for its implementation by the programmer: the data structure in the database, a description of the domain object, restrictions on data and methods, algorithms for implementing methods, data that should be during the installation of the system. The description structure is easy to understand and extensible.
Many will say that such detailing of requirements is time consuming and not necessary. What I would object to - but how does the programmer guess what exactly needs to be implemented? Is the phrase “You must implement the User object” enough to get working code after some time? How much tea do you need to drink with the analyst in order to extract data from him on 40 (we had so many) user properties? Who, if not an analyst or designer, should make an effort and describe all the objects?
Setting tasks for programmers
After describing what the requirements look like, consider an interesting question: how should the tasks for programmers be formulated (we restrict ourselves to the server side of a multi-tier application)? It turns out that most tasks (not defects) come down to three options:
Typical task 1
Heading: Implement such an object.
The text of the task is a link to a page with system requirements for the object.
In such a task, the programmer needs:
- create structures in the database (table, keys, indexes, triggers, etc.);
- implement a domain object;
- implement the creation of initial data.
Typical task 2
Title: Implement such-and-such operation of such-and-such object and rights to it.
The task text is a link to a page with system requirements for the object.
The programmer finds on the page the name of the operation and rights, and through the link in the Comment column - algorithms, checks, usage scenario.
Typical task 3
Title: Correct an object and / or operation.
This task is necessary in case of changes in requirements. The task text contains a description of the changes or a link to the requirements version comparison page.
A tool for writing and managing requirements
As many may have guessed, we used Atlassian Confluence to work with the requirements. I want to briefly list the advantages of this product.
- Telework. Actually, like any wiki.
- References As you saw above, links for us are one of the main tools for linking individual parts of requirements.
- The ability to split requirements into parts (each part on its own page).
- Alerts on change. This is one of the most important collaboration tools. For example, having received such an alert in one of the scenarios, the development manager can set tasks for developers, and testers know that it is necessary to adjust test scripts.
- Comments Many of our demand pages are surrounded by leafy comment hierarchies. In Confluence, working with them is quite convenient, since the hierarchy is not flat, but in the form of a tree. In addition, it is possible to use a full-fledged editor, and not just text.
- The presence of a powerful text editor. I will not dwell here in detail, I only note that Atlassian has improved the editor throughout our work, and if at first there were a lot of glitches, then the vast majority of them were fixed.
- Storing history, comparing different versions of pages, the ability to roll back to the old version.
- View page hierarchy in tree view.
However, there were several problems:
- Since all requirements use the same names of objects and their properties, it would be very convenient to have a tool that, when changing the name, changed it in all the documentation. And when I deleted it, I found all, already invalid, links to it.
- There was no way to collect statistics. For example, each requirement had a status, but we could not automatically collect the statuses of all requirements and have a dynamic picture of the requirements development process. But it seems that at the moment something similar has already appeared in Confluence.
- Charts had to be drawn in another system, saved in PNG and the picture was already placed on the Confluence page. In this case, it was still necessary to attach the source so that in a couple of months it could be found and corrected.
- I did not find a way to export page hierarchy in MS Word. Export to XML and PDF is very often buggy (maybe it is the size of the hierarchy).
In the end, I want to thank Vadim Loboda and Artem Karateev for valuable advice and a thorough review of this article.
Anton Stasevich