Crowdsourcing Testing

Regression testing is a very important part of working on product quality. And the more products and the faster they develop, the more effort it requires.
In Yandex, we learned how to scale up the tasks of manual testing for most products using assessors - remote employees working part-time on a piece-rate basis, and now hundreds of assessors are taking part in testing Yandex products, in addition to full-time testers.
In this post it is told:
- How was it possible to make the tasks of manual testing as formalized as possible and train them to hundreds of remote employees;
- How did you manage to put the process on industrial rails, provide testing in various environments, withstand SLA in speed and quality;
- What difficulties they faced and how they were solved (and some have not yet decided);
- How did testing by assessors contribute to the development of Yandex products, how did it affect the frequency of releases and the number of bugs that were skipped?
The text is based on the transcript of the report by Olga Megorskaya from our May conference Heisenbug 2018 Piter:
From the day of the report some numbers had time to change, in such cases we indicated actual data in brackets. Further, it comes from the first person:
Today we will talk about the use of crowdsourcing techniques for scaling manual testing tasks.
I have a rather strange job title: the head of the department of expert assessments. I will try to tell by examples what I do. In Yandex, I have two main vectors of responsibility:

On the one hand, this is all that is connected with crowdsourcing. I am responsible for our crowdsourcing Yandex.Tolok platform.
On the other hand, there are teams that, if we try to give a universal definition, can be referred to as “mass non-working vacancies”. There are many different things in it, including one of our recent projects: manual testing with the help of crowd, which we call “testing by assessors”.
My main activity in Yandex is that I bring together the left and right columns from the image and try to optimize the tasks and processes in mass production using crowdsourcing. And today we will talk just about it on the example of testing tasks.
What is crowdsourcing?
Let's start with what crowdsourcing is. It can be said that this is a replacement of the expertise of one particular specialist for the so-called “wisdom of the crowd” in cases where the expertise of a specialist is either very expensive or difficult to scale.
Crowdsourcing is actively used in various areas is not the first year. For example, NASA loves crowdsourcing projects very much. There, with the help of the "crowd", they explore and discover new objects in the galaxy. It seems that this is a very difficult task, but with the help of crowdsourcing it comes down to quite simple. There is a special site, on which they spread hundreds of thousands of photographs taken by space telescopes, and ask anyone who wants to search for certain objects there. And when a lot of people found it suspiciously similar to the object they need, then higher-level specialists are connected and they begin to investigate it.
Generally speaking, crowdsourcing is such a method when we take some big high-level task and divide it into many simple and homogeneous subtasks into which many independent performers gather. Each of the performers can solve one or more of these small puzzles, and together they ultimately work on one big common cause and collect a great result for a high-level task.
Crowdsourcing in Yandex
We have already started to develop our crowdsourcing system for several years. Initially, it was used for tasks related to machine learning: to collect training data, to configure neural networks, search algorithms, and so on.
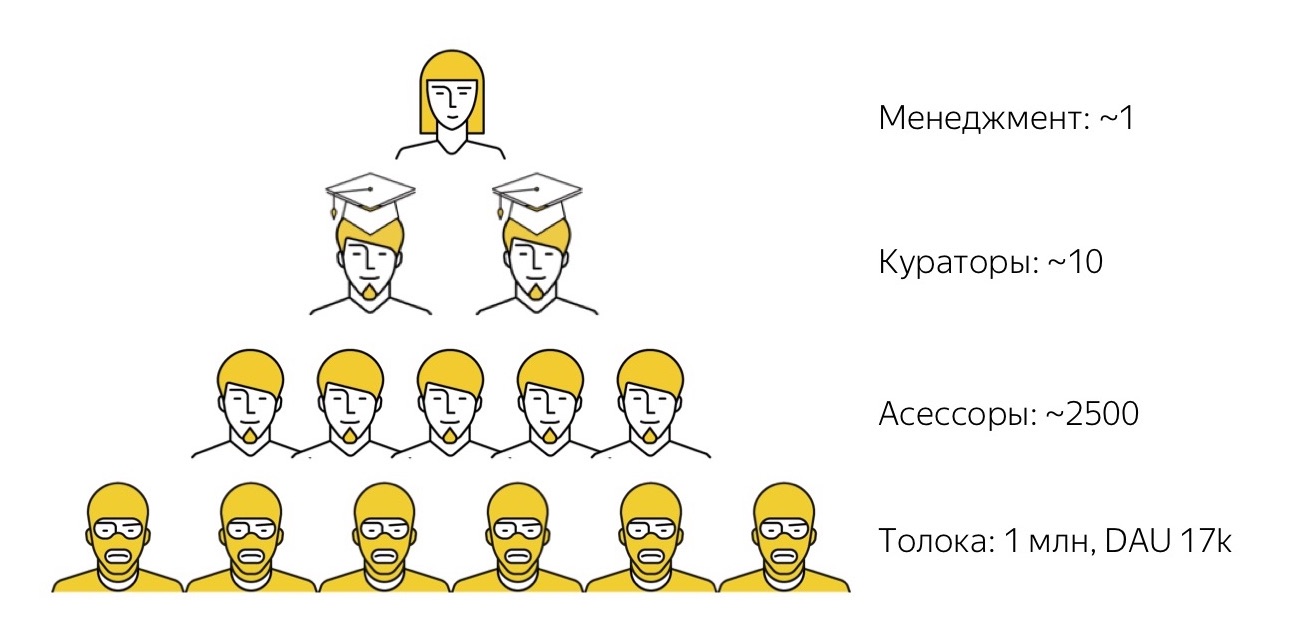
How does our crowdsourcing ecosystem work? First, we have Yandex.Toloka . This is an open crowdsourcing platform on which anyone can register either as a customer (place their tasks, set a price for them and collect data), or as a performer (find interesting tasks, perform them and receive a small reward). Toloku we launched a few years ago. We now have more than a million registered artists (we call them Tolokers), and every day in the system about 17,000 people perform tasks.
Since we initially created Toloka with an eye on tasks related to machine learning, it has traditionally been the case that most of the tasks that tolokers perform are tasks that are very simple and trivial for a person to do, but for the time being it is rather difficult for the algorithm. For example, look at a photo and say whether there is adult content on it or not, or listen to an audio recording and decipher what you heard.
Toloka is a very powerful tool in terms of performance and the amount of data it helps to collect, but rather non-trivial to use. The people in the picture wear yellow balaclavas, because all the performers in Toloka are anonymous and unknown to customers. And to manage these thousands of Anonymus, to make them do exactly what you need is not an easy task at all. Therefore, not all the tasks that we have, we are able to solve so far with the help of such an absolutely “wild” crowd. Although we are striving for this, I will say more about this later.
Therefore, for higher-level tasks, we have the next level of performers. These are the people we call assessors. The word “assessors” itself may be a little strange. It came from the word “assessment”, that is, “assessment”, because we initially used assessors to collect subjective assessments of the quality of search results. This data was then used as the target for machine learning search ranking functions. Much time has passed since then, assessors began to perform many very different other tasks, so now it is a household word: the tasks have changed, but the word has remained.
In fact, our assessors are full-time employees of Yandex, but working part-time and completely remotely. These are guys who work on their own equipment. We interact with them only remotely: we remotely select them, remotely train, remotely work with them and, if necessary, remotely dismiss them. We never intersect in person with most of them. They work on any schedule convenient for themselves, day or night: they have minimum rates equivalent to about 10-15 hours a week, and they can work out this time as they see fit. Assessors solve a variety of tasks: they are associated with search, and technical support, and with some low-level translations, and with testing, which we will continue to talk about.
As a rule, no matter what task we take, the most talented people who do it better, who are interested in this particular task, always stand out from the group of assessors who perform it. We single them out, endowing them with a loud title of supersessors, and these guys are already performing higher-level functions as curators: they check the quality of other people’s work, advise them, support them and so on.
And only at the very top of our pyramid do we have the first full-time employee who sits in the office and controls these processes. We have far fewer people who are much more advanced and have strong technical and managerial skills, literally ones. Such a system allows us to come to the fact that these units of "high-level" people build pipelines and manage production chains, in which tens, hundreds and even thousands of people are involved.
By itself, this scheme is not new, even Genghis Khan successfully applied it. She has some interesting properties that we try to use. The first property is quite understandable - such a scheme is very easily scaled. If some task needs to be suddenly started to do more, then we do not need to look for additional space in the office in order to put a person somewhere. We generally have very little to think about: just pour more money, hire more performers with this money, and of these performers more talented guys in academic caps will probably grow, and the whole system will scale further.
The second property (and it was surprising for me) - such a pyramid is very well replicated, regardless of the subject area in which to apply it. This also applies to the area we are going to talk about today, the tasks of manual testing.
Crowd testing
When we started the process of testing with the help of crowd, the biggest problem was the lack of a positive reference. There was no experience that we could refer to and say: “Well, these guys have done so, they are already testing with the help of crowds in a very similar pattern to us, and everything is good there, it means that everything will be fine with us.” Therefore, we had to rely only on our personal experience, which was separated from the testing domain and was more associated with setting up similar production processes, but in other areas.
Therefore, we had to do what we can do. What can we do? In essence, decompose one task into tasks of different levels of complexity and scatter them across the floors of our pyramid. Let's see what we did.
First, we looked at the tasks that our testers in Yandex are busy with, and asked them to conditionally scatter these tasks at different levels of complexity. This is the “hospital average”:
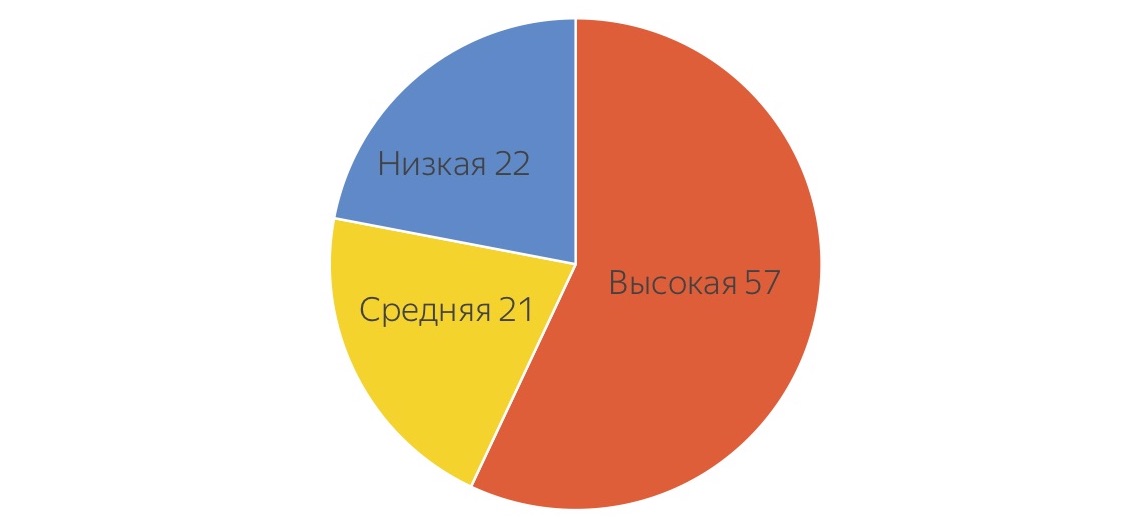
They estimated that only 57% of their time is spent on complex high-level tasks, and somewhere around 20% is spent on a very low-level routine that everyone wants to get rid of, and on tasks a little more complicated, which also It seems to be delegated. Encouraged by these figures, which show that almost half of the work can be transferred somewhere, we began to build testing with the help of crowds.
What goals did we set for ourselves?
- To make testing to cease to be a bottleneck, which it periodically appeared in production processes when the release is ready, but it waits until it passes testing.
- Unload our cool, very smart, high-level specialists - full-time testers - from the routine, taking them really interesting and higher-level tasks.
- Increase the variety of environments in which we test products.
- To learn how to handle peak loads, because our testers said that they often have uneven loads. Even if, on average, the team copes with the tasks, when a peak occurs, then it has to be raked for a very long time.
- Since we in Yandex still spent quite noticeable money on outsourcing testing in some projects, we thought that we would like to get a little more results for the money we spend, to optimize our outsourcing expenses.
I want to emphasize that among these goals there is no task to replace testers with crowds, to somehow harm them, and so on. All we wanted to do was to help the testing teams, freeing them from the low-level routine load.
Let's see what we got in the end. I’ll immediately say that the main testing tasks are now performed not by the lowest level of the “pyramid”, but by the assessors, but by the assessors, our staff members. The following discussion will go mainly about them, except for the very end.
Now assessors carry out regression testing tasks and pass all kinds of polls like “look at this application and leave your feedback”. At the full-fledged task of regression, we now have about 300 people qualified ( note: since the report was 500). But this figure is conditional, because the system that we have built works for an arbitrary number of people: as many as we need. Now our production needs are covered by approximately as many people. This does not mean that at each moment of time they are all ready and ready to perform the task: since assessors work in a flexible schedule, at every moment of time 100-150 people are ready to connect. But just a pool of artists like this. And simple tasks, like polls, when you just need to collect unformalized feedback from users, we have a lot more people going through: hundreds and thousands assessors participate in such polls.
Since these are people who work on their own equipment, each assessor has his own personal devices. This is, by default, a desktop and some kind of mobile device. Accordingly, we test our products on personal assessors devices. But it is clear that they do not have all possible devices, so if we need testing in some rare environment, we use remote access through the device farm.
Now crowd testing is already used as a standard production process of about 40 ( approx .: now 60) Yandex services and commands: this is Mail, and Disk, and Browser (mobile and desktop), and Maps, and Search, and many, many people. This is curious. When we set ourselves plans for the end of the third quarter in the fall of 2017, we had an ambitious goal: to attract at least somehow, “at least with deception, even with bribery,” at least five teams that would use our testing processes with the help of crowds. And we very strongly persuaded everyone to say: “Yes, do not be afraid, come on, try it!” But after just a few months, we had dozens of teams.
And now we are solving another problem: how to manage to connect more and more new teams that want to join these processes. So we can assume that now it is a standard practice in Yandex, which flies very well.
What have we got in terms of performance indicators? Now we are doing about 3,000 regression testing cases per day ( note: as of October 2018, already 7,000 cases ). Test runs, depending on the size, run from several hours to (peak) 2 days. Most of the passes in a few hours, within a day. The introduction of such a system has allowed us to reduce the cost by about 30% compared with the period when we used outsourcing. This allowed teams to be released much more often, on average somewhere several times, because releases began to take place with the speed that is available to the development, and not to the one that is available for testing, when it sometimes became a bottleneck.
Now I will try to tell you how we even built a production process that allowed us to come to this scheme.
Infrastructure
Let's start with the technical infrastructure. Those of you who have seen Toloka as a platform, imagine what its interface looks like: you can come into the system, choose tasks that interest you and carry them out. For internal employees, we have an internal instance of Toloki, in which we, among other things, distribute tasks of a different type to our accessors.
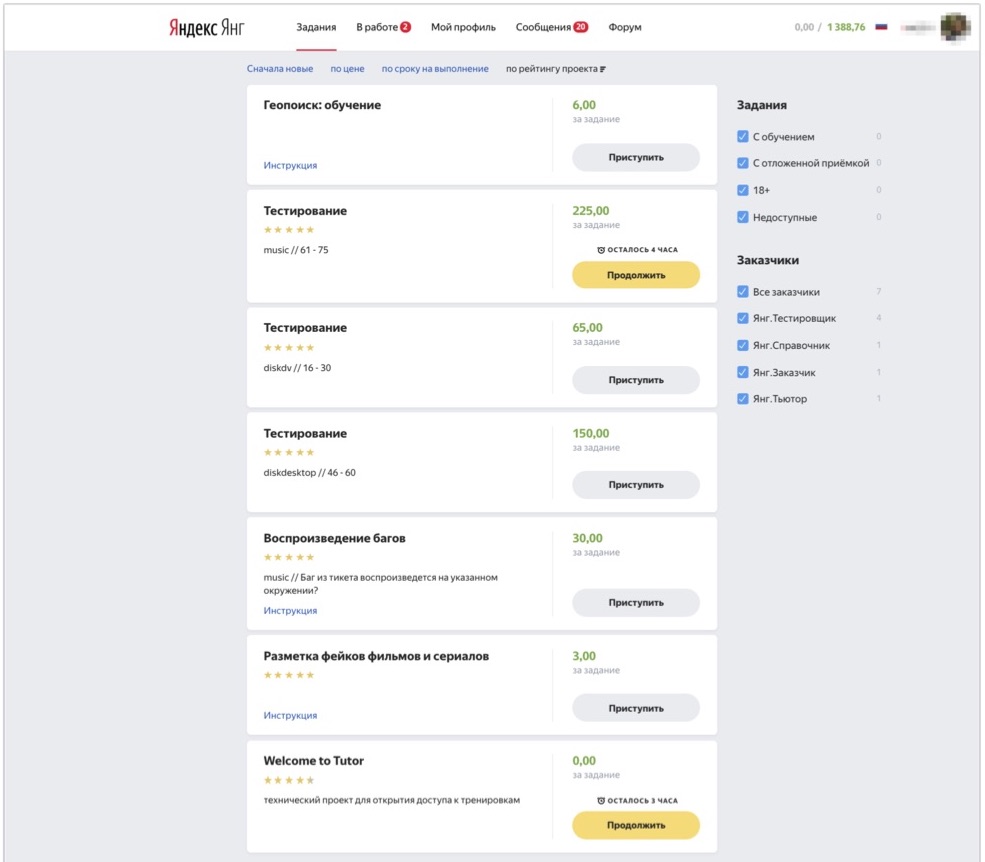
The picture shows what this interface looks like. Here you can see the tasks available to the assessor: there are several testing tasks and several tasks of a different type that the assessor from this example can also perform. And here the person comes, sees the tasks available to him at the moment, clicks "Proceed", receives test cases for analysis and begins to perform them.
An important part of our infrastructure is farms. Not all devices are on hand, so the task is essentially a couple: a test case and the environment in which it needs to be checked. When a person presses the “Proceed” button, the system checks if he has an environment in which to conduct a test. If there is, then the person simply takes the task and tests it on a personal device. If not, we send it via remote access to the farm.
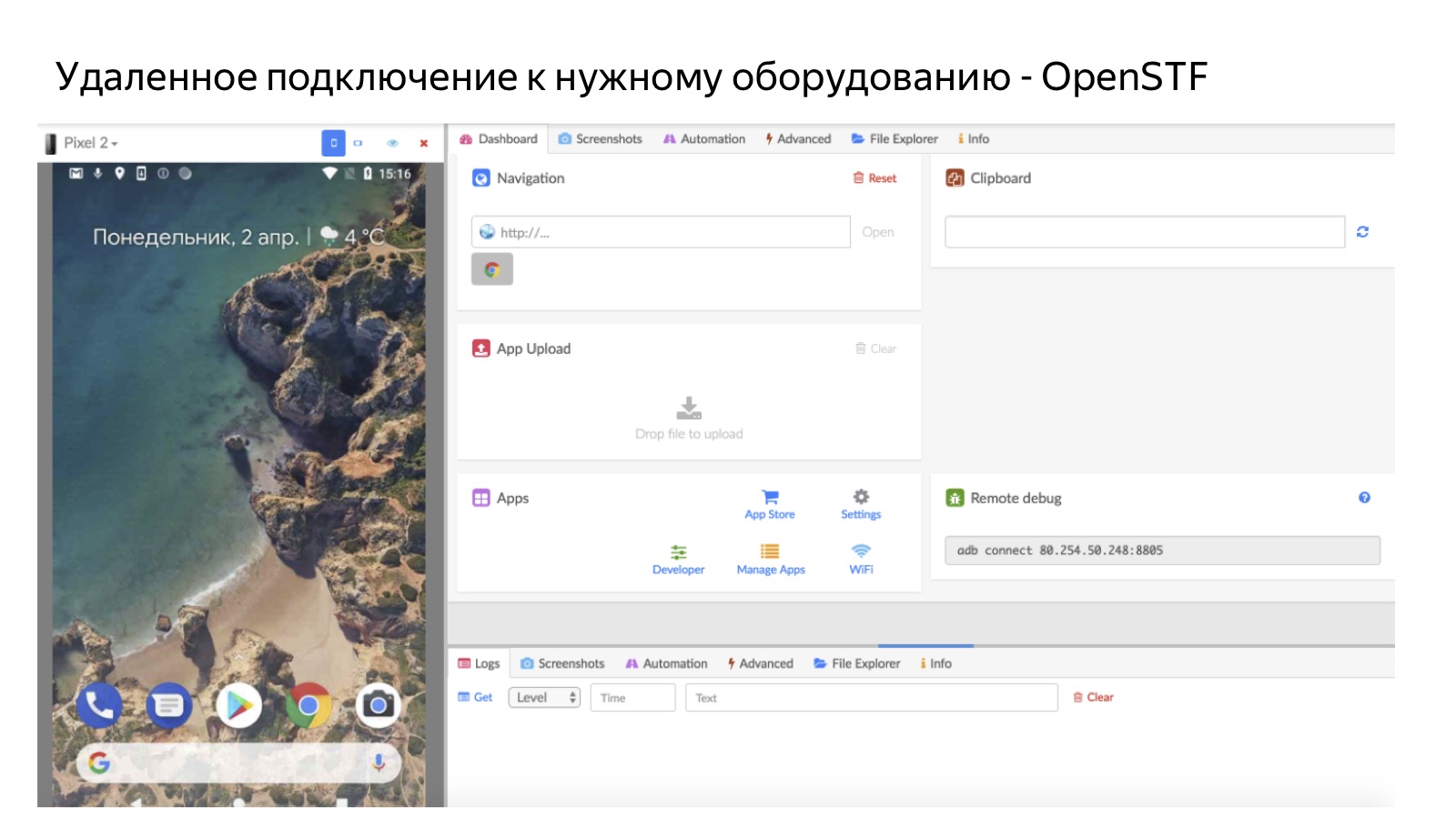
The picture shows how it looks, on the example of a mobile farm. So a person remotely connects to a mobile phone that lies in our office on the farm. For Android, we use OpenSTF open source solutions. For iOS, there are no good solutions - to such an extent that we have already made our own (but we will tell about it in detail some time next), because we could not find either the open source or anything that would make sense to buy. It is clear that the farm is useful in cases where we do not have people who have the right devices. And another important advantage of it is that the farm has a very high utilization rate: whenever and whatever person comes, we can send it to the farm at any time. This is better than handing out devices personally, because devices handed out to a person are only available for operation.
We talked a little about how this is implemented for our assessors from a technical point of view, and now the most interesting part for me: the principles of how we organized this production in general.
Crowd Production Principles
For me in this project it was interesting that the subject area seems to be very specific, but all the principles of production organization are fairly universal: the same ones used in organizing mass production in other subject areas.
1. Formalization
The first principle (not the most important, but one of the most important, one of our “whales, elephants and turtles”) is the formalization of tasks. I think you all know it by yourself. Almost any task is the easiest to do yourself. It is a little harder to explain to your colleague who is sitting next to you in the room so that he will do exactly what you need. And the task to make so that hundreds of performers whom you have never seen, who work remotely, at any arbitrary time, did exactly what you expect from them - this task is several orders of magnitude more complicated and implies a rather high threshold for entering to start doing this at all. In the context of testing tasks, the task with us, of course, is a test case that needs to be passed and processed.
And what should be the test cases in order to be able to use them in such a task as testing with crowds?
Firstly - and it turned out that this is not at all a matter of course - there should be test cases in general. There were such cases when teams came to us who wanted to be connected to testing by assessors, we said: “Great, bring your test cases, we will pass them!” At that moment the customer was sad, left, not even always returned. After several such appeals, we realized that, probably, help was needed in this place. Because if a tester from a team of a service himself regularly tests his services, he doesn’t really need complete, well-described test cases. And if we want to delegate this task to a large number of performers, then we simply cannot do without it.
But even in those cases where there were generally test cases, they were almost always understood only by those people who are very deeply immersed in service. And all other people who are out of context, it was very difficult to understand what is happening here and what needs to be done. Therefore, it was important to rework the test cases so that they are understandable to a person who is not immersed in context.
One last thing: if we reduce the task of testing to the strictly formal passage of concrete cases, it is very important to ensure that these cases are constantly updated, updated and replenished.
I will give a few examples.
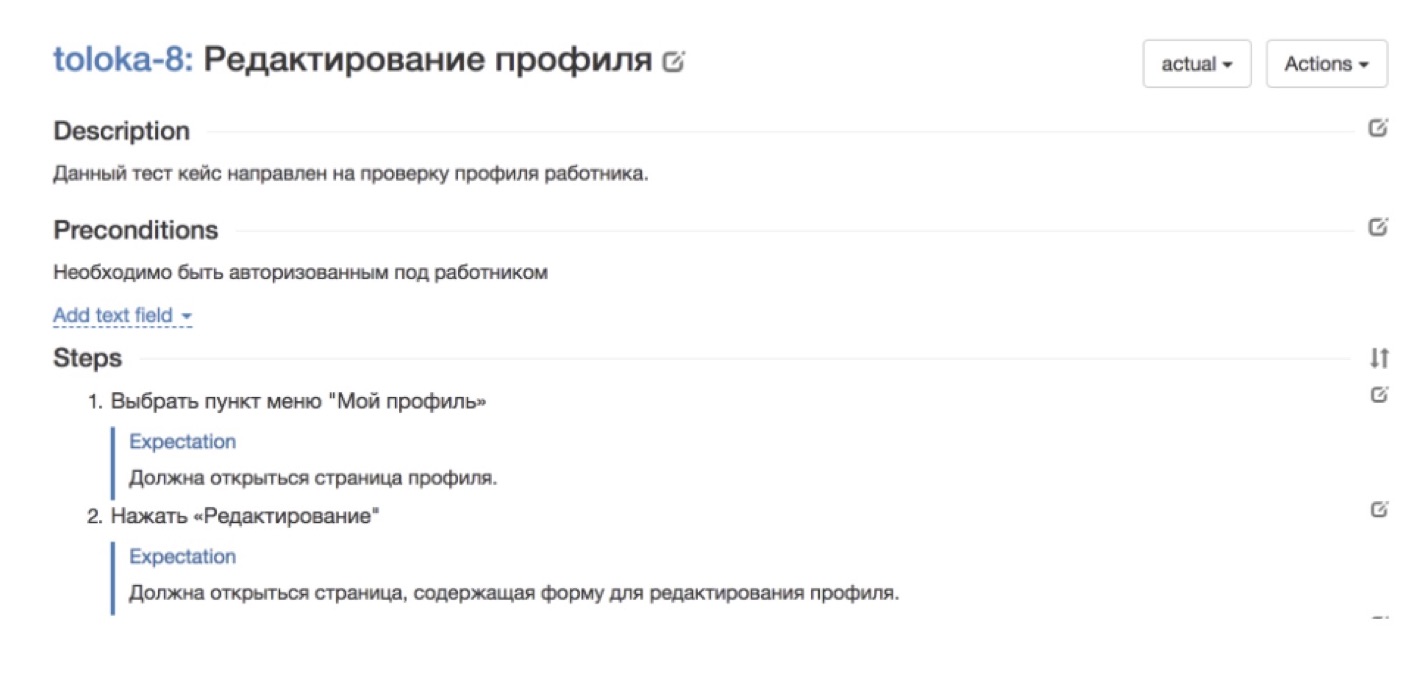
The picture above, for example, shows a good case from our native Toloka service, in which you need to check the correctness of the artist’s profile. Here everything is divided into steps. There is every step that needs to be done. There is an expectation of what should happen at every step. Such a case will be clear to anyone.
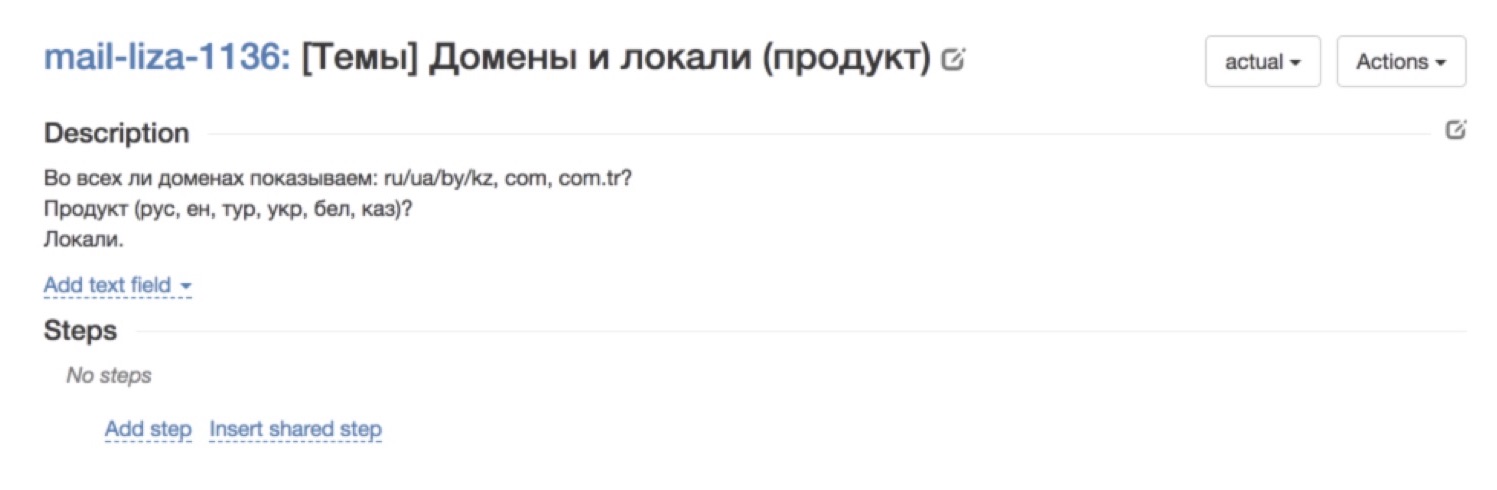
And here is an example of a not so successful case. In general, it is not clear what is happening. The description seems to be there, but in reality - what is it that you want from me? This kind of cases - it does not immediately, very bad pass.
How did we build the process of formalizing test cases so that, firstly, we generally had them, constantly appeared and replenished, and, secondly, that they were clear enough for assessors?
Through trial and error, we came to this scheme:
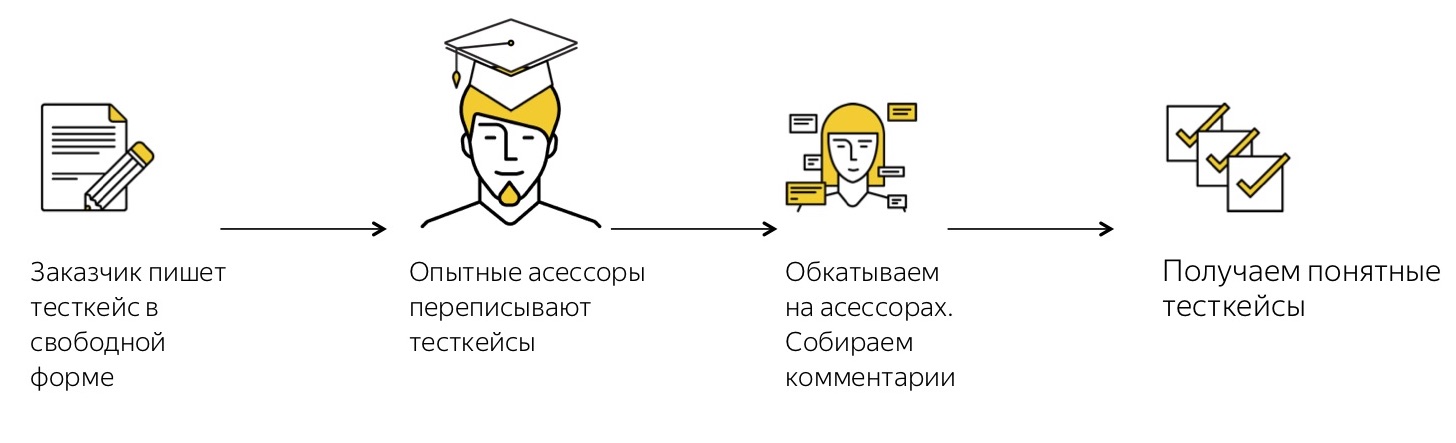
Our customer, that is, some kind of service or team, comes and in an arbitrarily arbitrary form, convenient for him, describes those test cases that he needs.
After that comes our clever assessor, who looks at this freely formulated text and translates it into well-formalized and detailed test cases. Why is it important that this assessor? Because he himself was in the shoes of those people who pass test cases from completely different areas, and he understands how detailed a test case should be in order for his colleagues to understand.
After that, we run around the case: give assignments to assignors and collect feedback. The process is organized so that if a person does not understand what is required of him in the test case, he skips it. As a rule, after the first time there is a fairly large percentage of omissions. All the same, no matter how well we at the previous stage formalize test cases, it is never possible to guess what would be incomprehensible to people. Therefore, the first run is almost always a test version, the most important of its functions is to collect the feedback. After we collected feedback, received comments from assessors, found out that they understood and what was not, we rewrite once more, append test cases. And after several iterations we get cool, very clearly formulated test cases that are clear to everyone.
This cleanup has an interesting side effect. Firstly, it turned out that for very many teams this is generally a killer feature. Everyone comes to us and says: “And what, can you really write test cases for me?” This is the most important thing, by which we attract our customers. The second effect, unexpected for me - the order in the test cases has other delayed effects. For example, we have technical writers who write user documentation, and it is much easier for them to write on the basis of such well-sorted and understandable test cases. Previously, they had to distract the service to figure out what needs to be described, and now you can use our clear and cool test cases.
I will give an example.

This is how the test case looked like before it went through our meat grinder: a very short, not full description field, it says “well, look at the screenshot in the app” and that's it.
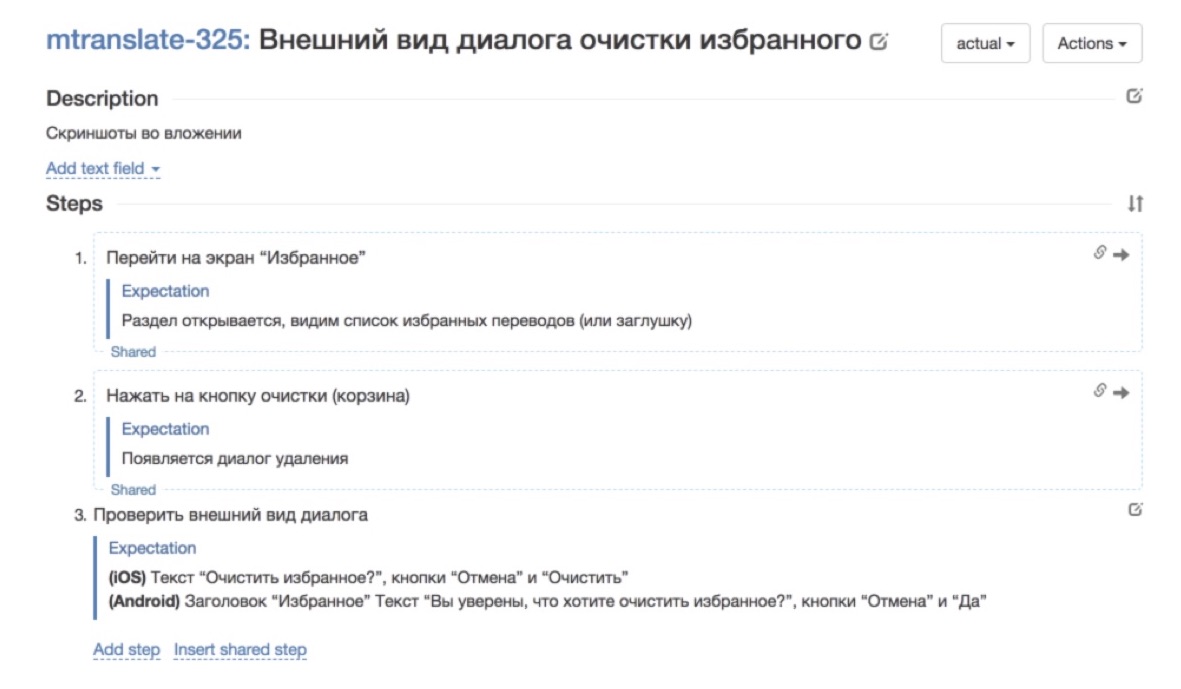
This is how it began to look after it was rewritten - steps and expectations were added at each step. So much better already. It is much more pleasant to work with such a test case.
2. Scalable learning
The next task is my favorite, the most, I think, creative in this whole thing. This is a scalable learning task. In order for us to operate with such numbers - “here we have 200 assessors, here there are 1,000, and here there are 17,000 talkers in general every day” - it is important to be able to train people quickly and scalably.
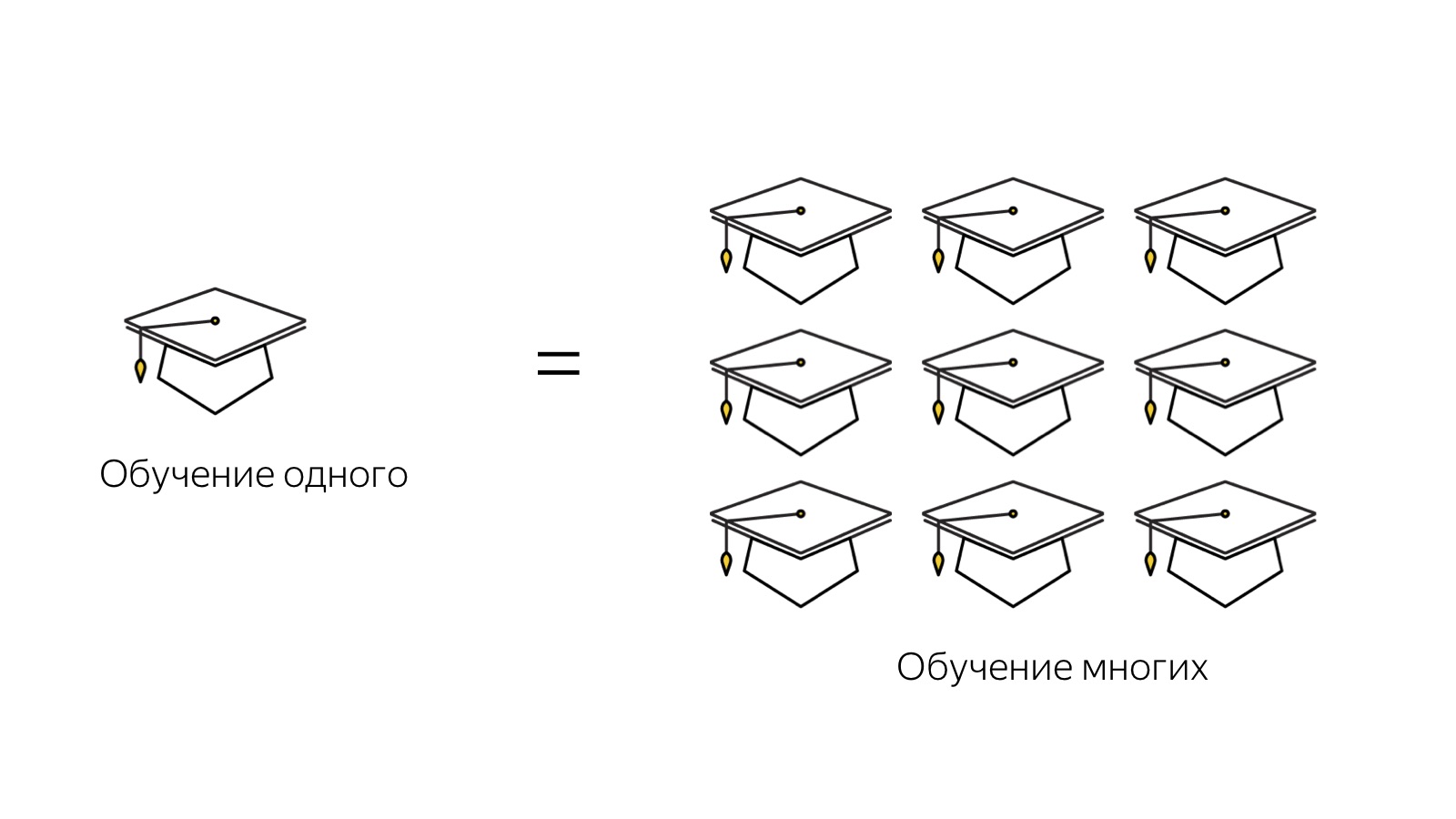
It is very important to come to such a system, when you spend no more time on training an arbitrary number of people than on training one particular specialist. This, for example, is what we encountered when working with outsourcing. The specialists are very cool, but in order to immerse them in the context of the work, the service took quite a lot of time, and at the output we still get one person who is half a year in context. And this is such a very non-scalable scheme. It turns out that each next person needs to be submerged in the context of the task for another six months. And it was necessary to expand this bottleneck.
For any mass vacancies, not only in testing, we recruit people through several channels. For testing, we do this. First, we attract people who are in principle interested in testing tasks, guys somewhere in junior-testers, for them this is a good start, immersion in the subject area. But there are still a limited number of such people on the market, and we need to have no restrictions on hiring people, so that we never rest on the number of performers.
Therefore, in addition to finding testers specifically for these tasks, we are recruiting a group of people who simply responded to the common position of the assessor. We are promoting something like this: whatever people you take, if there are a lot of them, you can arrange the process in such a way as to select the most capable of them and direct them to the solution of the task that you are pursuing. In the context of testing, we build training in such a way that it would be possible for arbitrary people who did not even know anything about testing, to train at least the minimum elements, so that they would begin to understand something. Thanks to this approach, we never rest on the lack of performers and the number of people who work on these tasks with us, it all comes down to the question of the amount of money we are willing to spend on it.
I do not know how often you come into contact with this topic, but in all sorts of popular science articles, especially about machine learning and neural networks, they often write that machine learning is very similar to human learning. We show the child 10 cards with a picture of a ball, and for the 11th time he will understand and say: “Oh! This is a ball! ”As a matter of fact, computer vision and any other machine learning technology work as well.
I want to talk about the reverse situation: the training of people can be built according to the same formal scheme as the training of machines. What do we need for this? We need a training set - a set of pre-marked examples on which a person will be trained. We need a control set on which we can check whether he has studied well or not. As in machine learning, you need a test set on which we understand how our function works at all. And we need a formal metric that will measure the quality of the work performed. It is on these principles that we have built training for the simplest regression testing tasks.
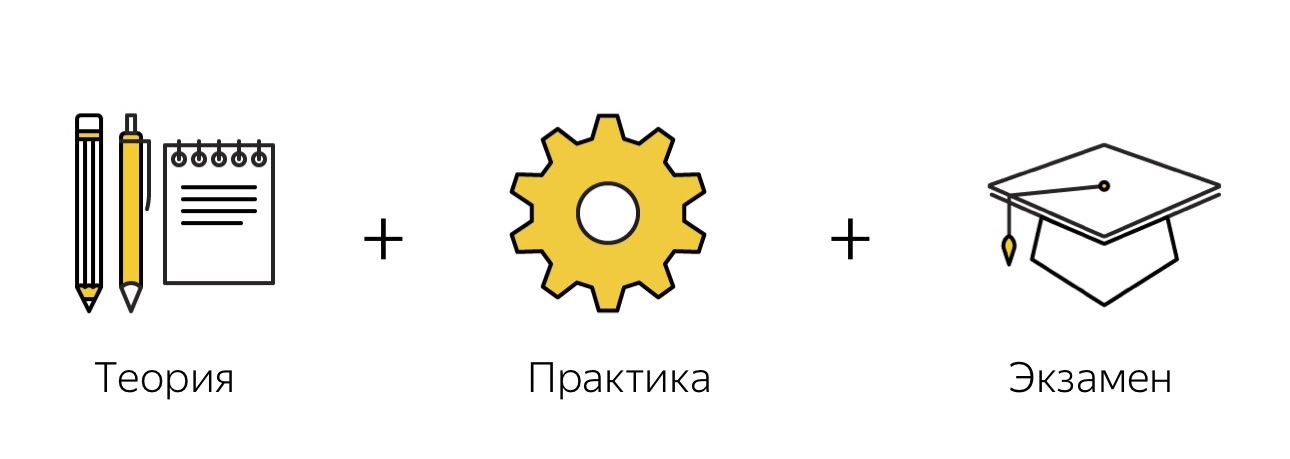
The picture shows how this training looks like in us. It consists of several parts. Firstly, there is a theory, then practice and then an exam, in which we check, the person understood the essence of the problem or did not understand.
Let's start with the theory. It is clear that for any task that the assessor performs, we have a large, spreading, full-fledged instruction with a large number of examples, where everything is analyzed in great detail. But nobody reads it.
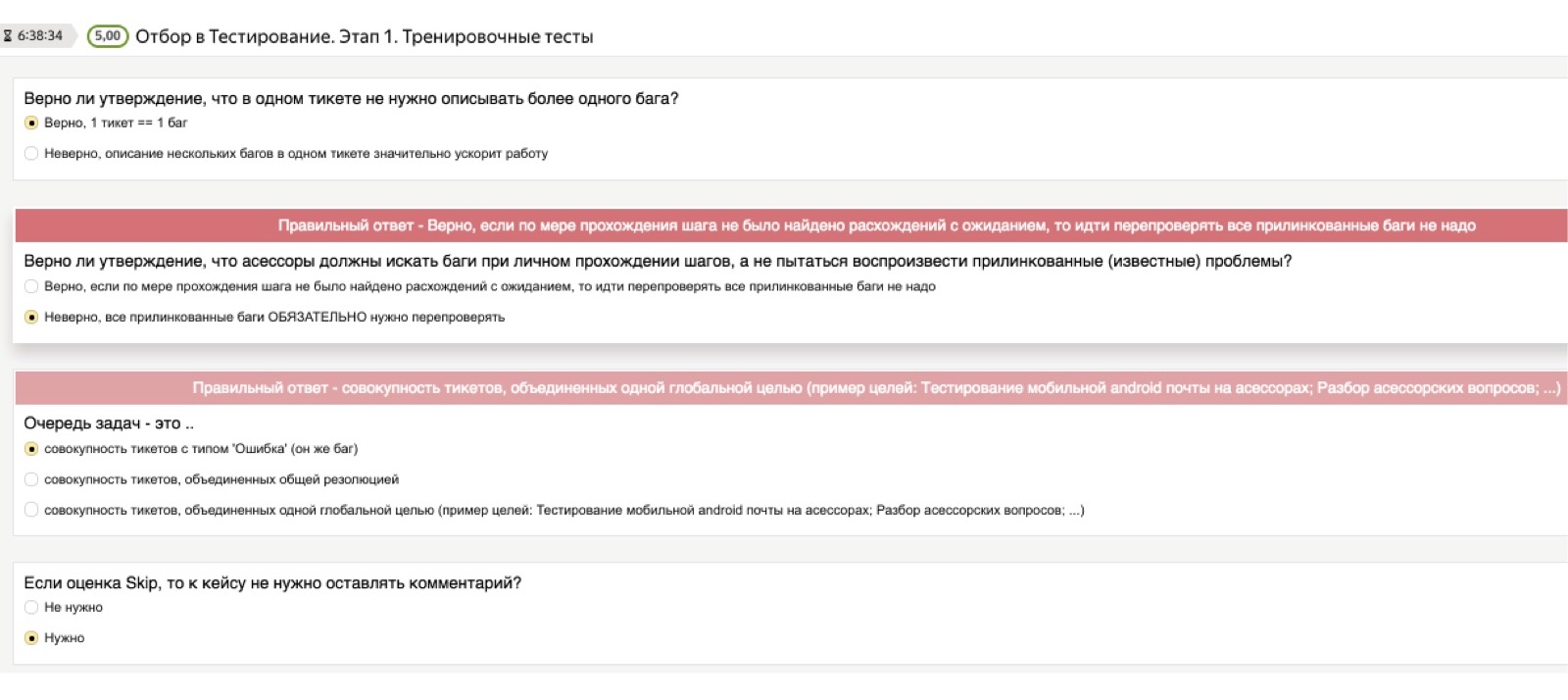
Therefore, in order to verify that theoretical knowledge really settled in a person’s head, we always give access to instructions, but after that we use what we conditionally call the “theoretical test”. This is a test in which we preload important questions and correct answers for us. Questions may be the most stupid. I think that for you it will be comical examples, but for people who have come across testing tasks for the first time in their lives, these are not at all obvious things. For example: “If I met several bugs, do I need to get several tickets — one for each bug — or dump everything in one pile?” Or: “What if I want to take a screenshot, but the screenshot doesn't work for me?”
These can be very different, arbitrarily low-level questions, and it is important for us that a person works on their own at the stage of learning the theory. Therefore, a theoretical test consists of questions of this type: “I found several bugs, do I have one ticket or several?” If a person chooses the wrong answer, he gets a red die that says: “No, wait, the right answer is different here, turn to that Attention". Even if a person has not read the instructions, he cannot pass this test.

The next moment is practice. How to make so that people who did not know anything at all about testing and did not respond specifically to the job of a tester understand what should be done next? Here we come to the very training set. I think that you will immediately find a large number of bugs that are in this picture. This is the learning task for the assessor: here is a screenshot in front of you, find all the bugs on it. What is wrong here? Calculator sticks out. What else? Layout went.

Or here is a more complex example, "with an asterisk". The mailbox of the main recipient is open, I am the one to whom this letter has been sent. Here I see such a picture in front of me. What is the bug here? The biggest problem here is that the hidden copy is shown, and I, as the recipient of the letter, see who it was in the hidden copy.
Having passed a couple of dozens of such examples, even a person who is infinitely far from testing, is already beginning to understand what it is and what is required of him further when passing test cases. The practical part is a set of examples, the bugs in which we already know; we ask the person to find them and at the end show him: “Look, the bug was here,” so that he correlates his guesses with our correct answers.
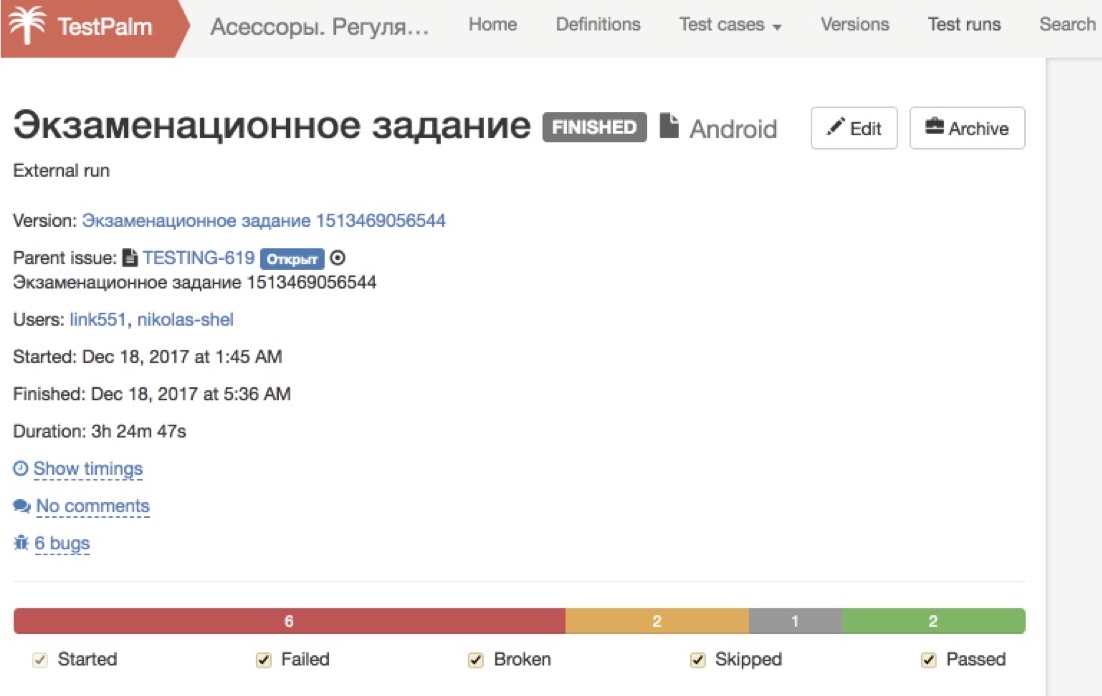
And the last part is what we call the exam. We have a special test build, the bugs of which we already know, and we ask the person to go through it. Here we no longer show him the correct and incorrect answer choices, but simply see what he could find.
The beauty of this system and its scalability lies in the fact that all these processes occur completely autonomously, without the participation of the manager. We run as many people as I like: everyone who wants to read the instructions, everyone who wants to pass the theoretical test, everyone who wants to go through the practice - all this happens automatically by pressing the button, but we don’t care at all.
The last part - the exam - is also passed by everyone who wants, and then, finally, we begin to look at them carefully. Since this is a test build and we know in advance all its bugs, we can automatically determine what percentage of the bugs were found by humans. If it is very low, then we don’t look any further, we write an automatic beating: “Thank you very much for your efforts!” - and do not give this person access to combat missions. If we see that almost all the bugs are found, then at that moment a person is connected who is looking at how correctly issued tickets, how well everything is done according to the procedure, in terms of our instructions.
If we see that a person independently mastered both theory and practice and passed the exam well, then we let such people into our production processes. This scheme is good because it does not depend on how many people we pass through it. If we need more people, we just fill in more people at the entrance and get more at the exit.
This is a cool system, but, naturally, it would be naive to believe that after that you can already have a ready tester. Even the guys who have successfully completed our training, there are many questions that they need to quickly help. And here we are faced with a lot of unexpected problems for us.
People ask a lot of questions. Moreover, these questions can be so strange that you would never have thought that the answers to these questions should be added to the instruction, described in a test or something like that. If you think this is a normal situation. Each of us is with you, when he finds himself in an unknown area, with a small probability, but will ask some question that seems to the expert silly.
Here, the situation is aggravated by the fact that we have several hundred of these people, and even if everyone has a specific chance of asking a stupid question is low, the total is: “A-aa! Oh god What's happening? It floods us! ”
Sometimes questions seem strange. For example, a person writes: “I do not understand what it means to“ tap into Undo ”.” They say to him: “Friend! This is the same as pressing the "Cancel" button. He: “Oh! Thank! Now I understand everything.
Or another person says: "It seems everything is fine, but something is broken, I can not understand whether this is a mistake or not." But after a minute he himself understands where he got - in the task of testing; probably a broken photo is not very normal. Here he understood, and ok.
Or here is an interesting example, which really plunged us into the abyss of research for a long time. A man comes and says:

Everyone does not understand what is happening, where he got this from - we tried so hard, described test cases - until we find out that he has some special browser extension that translates from Russian to English, and then from English to Russian , and in the end it turns out some kind of heresy.
In fact, there are many such questions, the study of each of them takes some non-zero time. And at some point, our customers — the services of the Yandex team who used testing by the assessors — began to tear their hair out and say: “Listen, we would spend much less time if we would test it all ourselves than sit in these chats and answer to these strange questions. ”
Therefore, we have come to a two-level chat system. There is a conditional fludilka, where our assessors communicate with their curators, with these “guys in hats” - here 90% of issues are solved. And only the most important and complex issues are escalated into a dedicated chat room in which the service team sits. This made life easier for all teams, everyone breathed calmly.
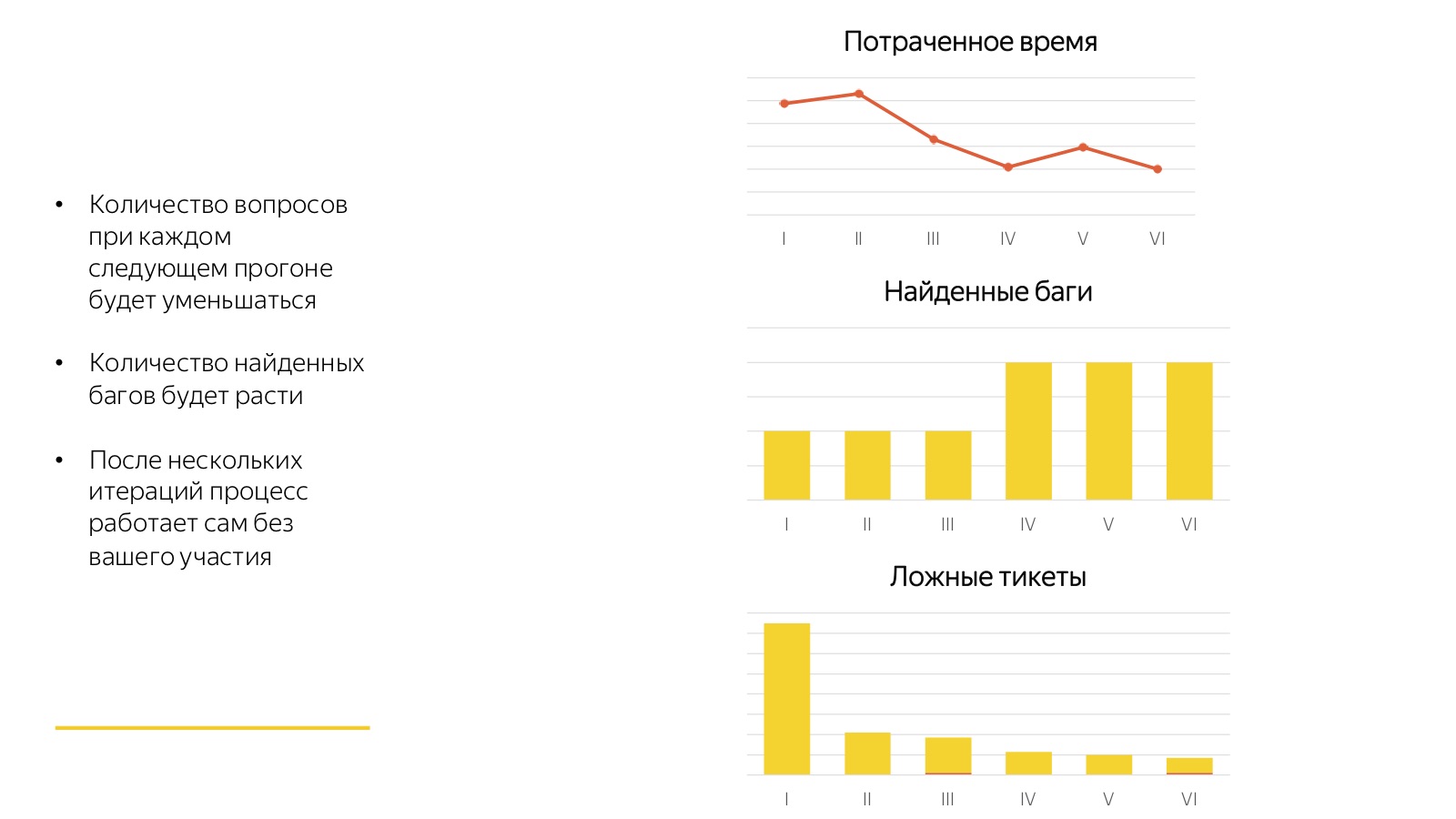
These horrors I am talking about are not so terrible. The good news is that all these processes converge very quickly. Any first launch is always very bad. The picture above shows 6 consecutive launches of the same regression.
Look at how much time the staff spent on answering questions for the first time, when the assessors did not understand what they were talking about and what they wanted from them. They found few bugs, they got a lot of tickets about anything. Therefore, the first time is horror-horror-horror, the second time is horror-horror, and by the third time, 80 percent of all processes converge. And then there is a cool process: the assessors get used to the new task, and after each launch we collect feedback, we supplement the test cases, we sort something. And it turns out a cool factory that works by pressing a button and does not require any participation of a full-time specialist.
3. Quality control
A very important point, without which all this will not work, is quality control.
Assessors work for us by piecework: all their tasks are very clearly regulated and quantified, each unit of work has its own standard tariff, and they receive payment for the number of units completed. Toloka works in the same way, and generally any crowd. This system has many advantages, it is very flexible, but it also has its drawbacks. In the system with piecework wages, any performer will try to optimize his work - to spend as little time and effort on the task in order to get much more money per unit of time. Therefore, any such system built on crowdsourcing is guaranteed to work with the minimum quality that you allow it. If you do not control the quality in any way, it will fall as low as it can fall.
The good news is that you can fight it, you can control it. If we are able to quantify the quality of work, then the task comes down to a fairly simple one. This is in theory. In practice, it is not so simple at all, especially in testing tasks. Because testing, unlike many other mass problems that we solved with the help of assessors, deals with rare events, and all sorts of statistics work quite poorly there. It is very difficult to understand how often a person really finds bugs, if in principle there are very few bugs. Therefore, we have to pervert and use several quality control methods at once, which together will give us a certain picture of the quality with which the performer works.
The first is a check in the overlap. “Overlap” means that we assign each task to several people. We do this in a natural way, because each test case needs to be tested in several environments. Thus, it turns out that the same test case was tested in environments A, B and C. We have three results from three people - passing the same test case. Further we look, whether results have dispersed.
Sometimes it happens that in one environment a bug was found, in the other two it was not found. Maybe it really is, or maybe someone’s mistake: either one person found an extra bug, or those two faked and didn’t find something. In any case, this is a suspicious case. If we encounter such a thing, then we send it to an additional recheck in order to make sure and verify who was right and who was to blame. Such a scheme allows us to catch people who, for example, started extra tickets where they were not needed, or missed where they were needed. At the same time, we look at how correctly the ticket was entered, whether everything is according to the procedure: whether screenshots are added, if necessary, a clear description is added, and so on.
In addition to this - and especially with regard to the correctness of registration of tickets - it is pleasant and convenient to automatically control some things that, on the one hand, seem to be trifles, but, on the other hand, have a rather strong influence on the working process. Therefore, we automatically check if there is an application to the ticket, whether screenshots have been added, whether there are comments on the ticket, or if it was just closed without looking at how much time was spent on it in order to detect suspicious cases. Here you can invent many different heuristics and apply them. The process is almost endless.
An overlap check is a good thing, but it gives a slightly biased assessment, because we only check controversial cases. Sometimes you want to make an honest random inspection. To do this, we use the control runs. At the training stage, we had specially assembled test assemblies, in which we know in advance where there are bugs and where not. We use similar launches for quality control and check how many bugs a person found and missed how many. This is a cool way, it gives the most complete picture of the world. But it is quite expensive to use: while we are still assembling a new test assembly ... We use this approach quite rarely, every few months.
The last important point: even if we have already done everything, it is necessary to analyze why the bugs were missed. We check if it was possible to find this bug by the steps of the test case. If it was possible, and the person missed, then it means that the person is a burdock, and you need to have an impact on him. And if this case was not, then you need to somehow complement, update the test cases.
All the quality metrics we end up with in a single rating assessors, which affects their career and destiny in our system. The higher the rating of a person, the more he receives more complex tasks and claims for bonuses. The lower the rating of the assessor, the greater the likelihood of being dismissed. When a person works stably with a low rating, we end up with him.
4. Delegation
The very last of the pillars of our pyramidal scalable scheme that we want to talk about is the task of delegation.
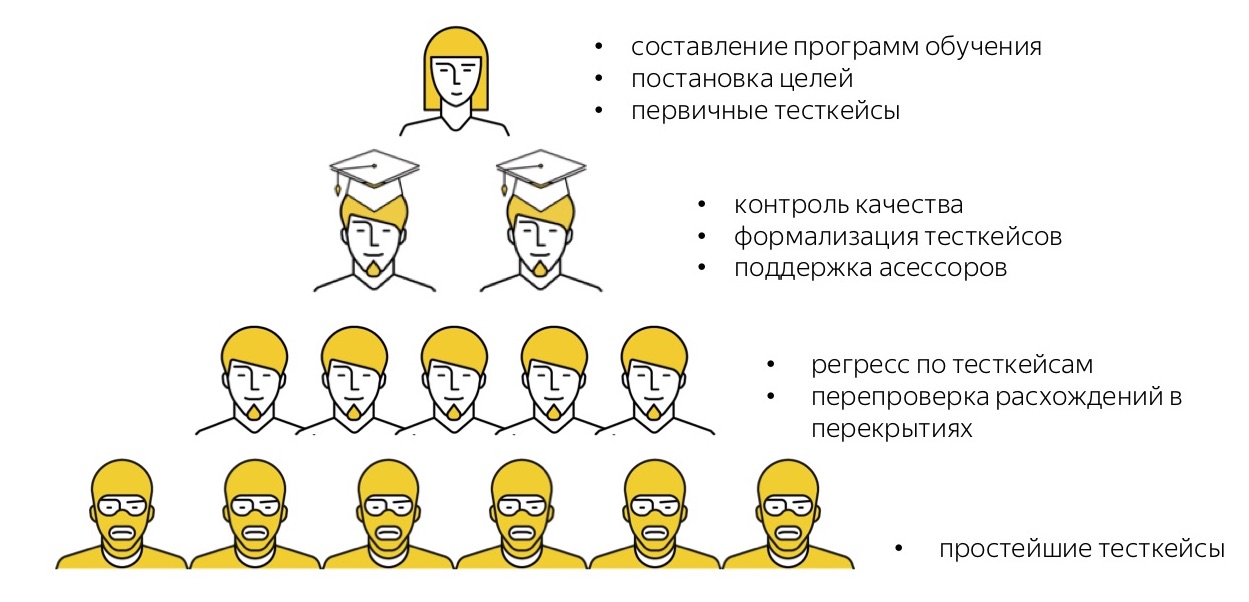
I will remind once again how the pyramid for manual testing tasks looks like. We have “high-level” people - they are full-time testers, representatives of the service team, who compose training programs for the service they need for testing, form a strategy for what needs to be tested, write primary test cases in free form.
Then we have the most talented assessors who translate test cases from free-form to formalized ones, help other assessors, support them in chatikah and carry out recheck and selective quality control.
Further there is a cloud of our numerous performers who regress in steps.
Then we have Toloka, about which we have not forgotten. Now we are at the stage of experiments: we understand that the simplest cases can be put into testing in impersonal crowd in Toloka. It will be much cheaper and faster, because there are even more performers. But while we are in the process of building this system. Now we give only the simplest, but I hope that in a few months we will come to the conclusion that we will delegate more to it.

It is very important to follow the correct development of this pyramid. First of all (such questions are often asked to me, so I want to answer them proactively), crowdsourcing is not a rejection of the labor of high-level specialists in favor of crowding, but a scaling tool. We cannot abandon the top of this pyramid, our “head”, we can only add more hands to this system with the help of crowdsourcing, thus really very easily scaling it almost for free.
Secondly, it is not rocket science, but it must be constantly remembered: this whole story functions well and correctly, if the most complex tasks for this level are solved at each of its levels. Roughly speaking, if the same can be done at several levels of the pyramid, it must be done at its lowest level. This is not a static story, but a dynamic one. We begin by saying that only “high-level” people can do some tasks, gradually work out the process and lower these tasks below, scaling and cheapening the whole process.
And I quite often hear such a remark: “Why bother to make this garden in general, it’s better to just automate everything and spend energy on it.” But crowdsourcing is not a replacement for automation, it is a parallel thing. We do this not in place of automation, but in addition to it. Such a system just allows us to free up workers who could be engaged in automation, on the one hand, and, on the other hand, to formalize the process well enough, which then will be much easier to automate.
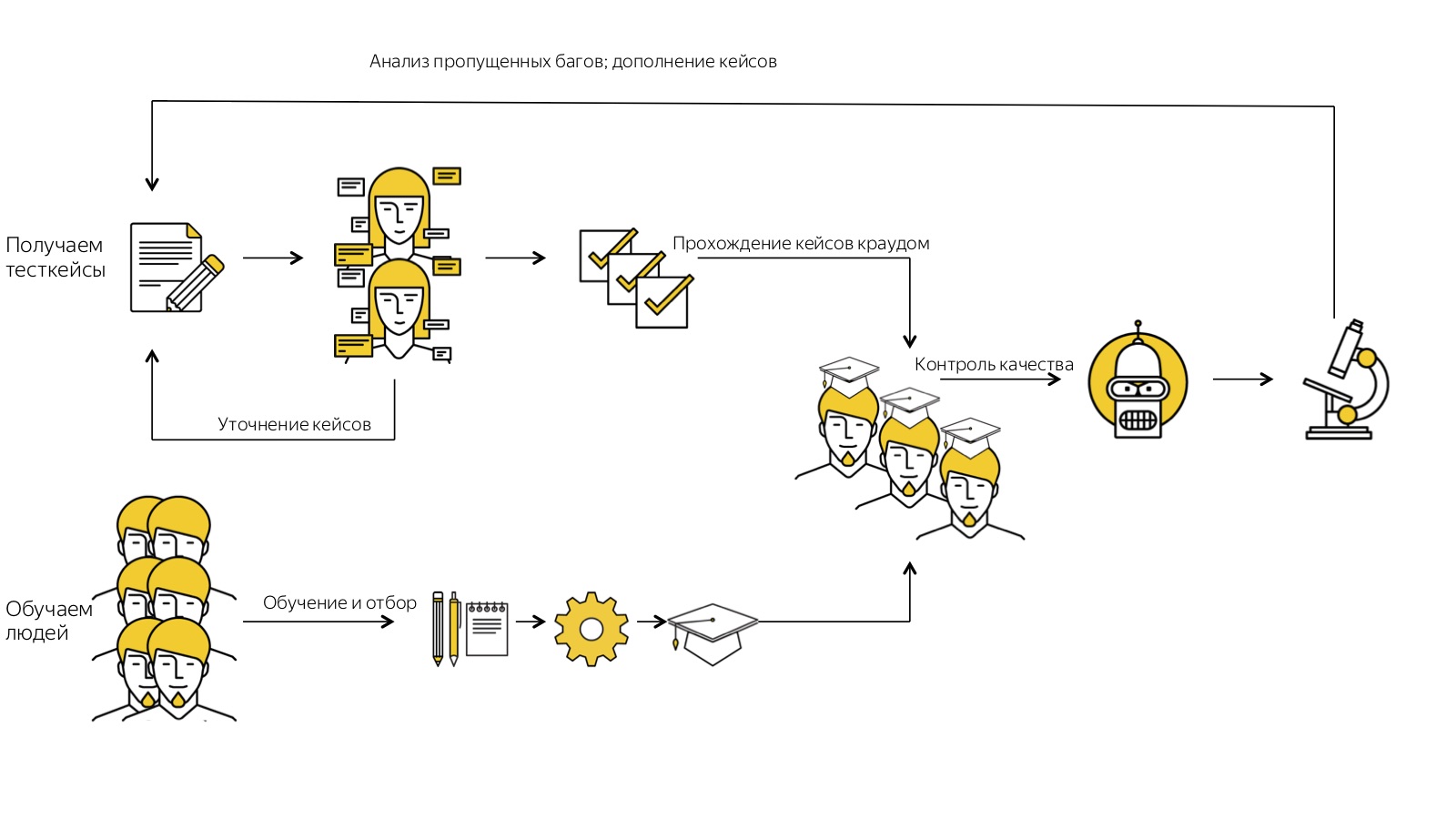
Finally, let me remind you once again how our entire history looks like. We begin by getting test cases in free form. We run them several times through assessors, collect feedback, clarify them. After that we get cool, already licked test cases. In parallel with this, we recruit many, many people, conduct them through the automatic learning system and at the output we get only those who were able to cope with all the stages on their own and understood what we wanted from him. We get trained crowd. He works with us on formalized test cases, and we control its quality: we constantly recheck, analyze cases with missing bugs in order to improve our processes.
And this system works for us, flies. I do not know if my story will be useful to someone right now from a practical point of view, but I hope that he will allow him to think a little bit more widely and to allow some tasks to be accomplished in this way. Because - and we are faced with this very often - some of you could already catch yourself thinking: “Well, maybe it works somewhere, but definitely not for me. I have such difficult tasks that it’s not about me at all. ” But our experience suggests that virtually any tasks from virtually any subject areas, if competently decomposed, formalized, and built into a clear process, can at least partially be scaled with the help of crowds.
If you like this report with Heisenbug 2018 Piter , pay attention: Moscow's Heisenbug will take place on December 6-7 , there will also be many interesting things there, and descriptions of many reports can already be seen on the conference website .