Atomic and non-atomic operations
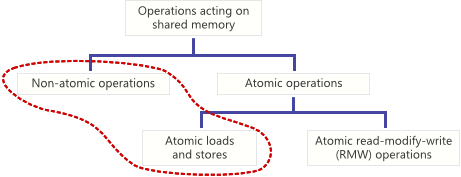
Atomic vs. Jeff Preshing Non-Atomic Operations. Original article: http://preshing.com/20130618/atomic-vs-non-atomic-operations/
A lot has already been written about the atomic operations on the Web, but mostly authors consider read-modify-write operations. However, there are other atomic operations, for example, atomic operations of loading (load) and storage (store), which are no less important. In this article, I will compare atomic load and save with their non-atomic counterparts at the processor and C / C ++ compiler level. In the course of the article, we will also deal with the concept of “race condition” from the point of view of the C ++ 11 standard.
An operation in a shared memory area is called atomicif it completes in one step relative to other threads that have access to this memory. During such an operation on a variable, no thread can observe the change half completed. Atomic loading ensures that the variable is loaded in its entirety at one point in time. Non-atomic operations do not provide such a guarantee.
Without such guarantees, non-blocking programming would not have been possible, since it would have been impossible to allow several threads to operate on one variable at a time. We can formulate the rule:
At any time when two streams simultaneously operate on a common variable, and one of them writes, both streams are required to use atomic operations.
If you break this rule, and each thread uses non-atomic operations, you find yourself in a situation that the C ++ 11 standard calls the state of racing according to data (data race) (do not confuse it with a similar concept from Java, or a more general concept of racing status (race condition)). The C ++ 11 standard does not explain why race conditions are poor, but states that in such a state you will get undefined behavior ( §1.10.21 ). The danger reason for such race conditions, however, is very simple: in them, read and write operations are torn (torn read / write).
A memory operation can be non-atomic even on a single-core processor just because it uses several processor instructions. However, a single processor instruction on some platforms may also be non-atomic. Therefore, if you write portable code for another platform, you can not rely on the assumption of atomicity of a separate instruction. Let's look at a few examples.
Non-atomic operations from several instructions
Let's say we have a 64-bit global variable initialized to zero.
uint64_t sharedValue = 0;
At some point in time, we will assign a value to it:
void storeValue()
{
sharedValue = 0x100000002;
}
If we compile this code using the 32-bit GCC compiler, we get the following machine code:
$ gcc -O2 -S -masm=intel test.c
$ cat test.s
...
mov DWORD PTR sharedValue, 2
mov DWORD PTR sharedValue+4, 1
ret
...
It can be seen that the compiler implemented 64-bit assignment using two processor instructions. The first instruction assigns the lower 32 bits the value 0x00000002, and the second puts the value 0x00000001 in the upper bits. Obviously, such an assignment is non-atomic. If various streams try to access the sharedValue variable at the same time, you can get several error situations:
- If the stream calling storeValue is interrupted between two write instructions, it will leave the value 0x0000000000000002 in memory - this is a torn write operation . If at this moment another thread tries to read sharedValue, it will receive an incorrect value that no one was going to save.
- Moreover, if the recording stream was stopped between the recording instructions, and the other stream changes the value of sharedValue before the first stream resumes operation, we will get a permanently broken record: the upper half of the variable value will be set by one stream, and the lower half by the second.
- To get a broken record on multicore processors, threads do not even need to be interrupted: any thread running on another core can read the value of a variable at the moment when only half of the new value is written to memory.
Parallel reading from sharedVariable also has its problems:
uint64_t loadValue()
{
return sharedValue;
}
$ gcc -O2 -S -masm=intel test.c
$ cat test.s
...
mov eax, DWORD PTR sharedValue
mov edx, DWORD PTR sharedValue+4
ret
...
Here, in the same way, the compiler implements reading with two instructions: first, the lower 32 bits are read into the EAX register, and then the upper 32 bits are read into EDX. In this case, if a parallel write is made between these two instructions, we will get a torn read operation, even if the write was atomic.
These problems are by no means theoretical. Tests of the Mintomic library includes the test_load_store_64_fail test, in which one stream saves a set of 64-bit values into a variable using the usual assignment operator, and the other stream performs a normal load from the same variable, checking the result of each operation. In x86 multithreaded mode, this test is expected to fail.

Non-atomic processor instructions
A memory operation can be non-atomic even if it is performed by a single processor instruction. For example, the ARMv7 instruction set contains the strd instruction, which stores the contents of two 32-bit registers in a 64-bit variable in memory.
strd r0, r1, [r2]
On some ARMv7 processors, this instruction is not atomic. When the processor sees such an instruction, it actually performs two separate operations ( §A3.5.3 ). As in the previous example, another thread running on a different kernel may fall into a torn write situation. Interestingly, the situation of a torn record can also occur on one core: a system interrupt - say, for a planned change in the context of a stream - can occur between internal 32-bit save operations! In this case, when the thread resumes its work, it will start executing the strd instruction again.
Another example, the well-known operation of the x86 architecture, the 32-bit mov operation is atomic when the operand in memory is aligned, and not atomic otherwise. That is, atomicity is only guaranteed when a 32-bit integer is located at an address that is divisible by 4. Mintimoc contains a test example test_load_store_32_fail that checks this condition. This test always runs successfully on x86, but if you modify it so that the sharedInt variable is at an unaligned address, the test will fail. On my Core 2 Quad 6600, the test crashes when sharedInt is split between different cache lines:
// Force sharedInt to cross a cache line boundary:
#pragma pack(2)
MINT_DECL_ALIGNED(static struct, 64)
{
char padding[62];
mint_atomic32_t sharedInt;
}
g_wrapper;

I think we considered enough nuances of processor execution. Let's take a look at atomicity at the C / C ++ level.
All C / C ++ operations are considered non-atomic
In C / C ++, each operation is considered non-atomic until another is explicitly indicated by the producer of the compiler or hardware platform - even the usual 32-bit assignment.
uint32_t foo = 0;
void storeFoo()
{
foo = 0x80286;
}
Language standards do not say anything about atomicity in this case. Perhaps the integer assignment is atomic, maybe not. Since non-atomic operations give no guarantees, the usual integer assignment in C is non-atomic by definition.
In practice, we usually have some information about the platforms for which the code is generated. For example, we usually know that on all modern x86, x64, Itanium, SPARC, ARM, and PowerPC processors, the usual 32-bit assignment is atomic if the destination variable is aligned. You can verify this by reading the appropriate section of the processor and / or compiler documentation. I can say that in the gaming industry the atomicity of so many 32-bit assignments is guaranteed by this particular property.
Be that as it may, when writing truly portable C and C ++ code, we follow a long-established tradition of believing that we know nothing more than what the language standards tell us. Portable C and C ++ are designed to run on any possible computing device of the past, present, and future. For example, I like to imagine a device whose memory can be changed only by pre-filling it with random garbage:

On such a device, you certainly will not want to perform parallel reading, as well as regular assignment, because the risk is too high to get a random value as a result.
In C ++ 11, a way has finally emerged to do truly portable atomic save and load. These operations performed using the C ++ 11 atomic library will work even on the conditional device described earlier: even if this means that the library will have to block the mutex in order to make each operation atomic. My library Mintomic I released recently , does not support a number of different platforms, but it works on some older computers, hand-optimized and guaranteed non-blocking.
Relaxed atomic operations
Let's go back to the sharedValuem example that we covered at the beginning. Let's rewrite it using Mintomic so that all operations are performed atomically on each platform that Mintomic supports. First, we will declare sharedValue as one of the atomic types of Mintomic:
#include
mint_atomic64_t sharedValue = { 0 };
The mint_atomic64_t type guarantees the correct alignment in memory for atomic access on each platform. This is important because, for example, the gcc 4.2 compiler for ARM in the Xcode 3.2.5 development environment does not guarantee that the uint64_t type will be aligned by 8 bytes.
In the storeValue function, instead of performing the usual non-atomic assignment, we must execute mint_store_64_relaxed.
void storeValue()
{
mint_store_64_relaxed(&sharedValue, 0x100000002);
}
Similarly, in loadValue we call mint_load_64_relaxed.
uint64_t loadValue()
{
return mint_load_64_relaxed(&sharedValue);
}
If you use the terminology of C ++ 11, then these functions are now free from race conditions according to data (data race free). If they are called at the same time, it is absolutely impossible to find yourself in a situation of torn reading or writing, regardless of which platform the code is running on: ARMv6 / ARMv7 (Thumb or ARM modes), x86, x64, or PowerPC. If you are interested in how mint_load_64_relaxed and mint_store_64_relaxed work, then both functions use the cmpxchg8b instruction on the x86 platform. Implementation details for other platforms can be found in the Mintomic implementation .
Here is the same code using the standard C ++ 11 library:
#include
std::atomic sharedValue(0);
void storeValue()
{
sharedValue.store(0x100000002, std::memory_order_relaxed);
}
uint64_t loadValue()
{
return sharedValue.load(std::memory_order_relaxed);
}
uint64_t loadValue()
{
return mint_load_64_relaxed(&sharedValue);
}
You should have noticed that both examples use relaxed atomic operations, as evidenced by the _relaxed suffix in identifiers. This suffix recalls certain guarantees regarding memory ordering.
In particular, for such operations reordering of operations with memory is allowed in accordance with reordering by the compiler or with reordering of memory by the processor . The compiler can even optimize redundant atomic operations, as well as non-atomic ones. But in all these cases, the atomic nature of the operations is preserved.
I think that in the case of parallel memory operations, using the functions of the atomic libraries Mintomic or C ++ 11 is good practice, even if you are sure that ordinary read or write operations will be atomic on the platform you use. Using atomic libraries will serve as an extra reminder that variables can be used in a competitive environment.
I hope you now understand why the World’s simplest non-blocking hash table uses Mintomic to manipulate shared memory at the same time as other threads.
About the author. Jeff Preching is a software architect at Ubisoft, a gaming company that specializes in multi-threaded programming and non-blocking algorithms. This year, he made a report on multi-threaded game development in accordance with the C ++ 11 standard at the CppCon conference, a video of this report was also on Habré . He runs an interesting blog, Preshing on Programming , which focuses on the intricacies of non-blocking programming and the related nuances of C ++.
I would like to translate many articles from his blog for the community, but since his posts often refer to one another, it is quite difficult to choose an article for the first translation. I tried to choose an article that was minimally based on others. Although the issue under consideration is quite simple, I hope it will still be of interest to many who begin to become familiar with multithreaded programming in C ++.