InterSystems iKnow. Part two. Create a simple domain
- Tutorial
This is a continuation of my Intersystems iKnow technology Natural Natural Processing talk, beginning here . In the second part you will find a description of practical work with iKnow. We will create a domain, configure it, upload the text. Then, we will look and analyze the results. More on this under the cut ...
Let's start by creating a domain. A domain in iKnow can be compared with an area in Caché or with a mailbox in the entrance of your home. This is some container where texts are loaded. In addition to texts, the tools necessary for their analysis are stored there, for example, configurations, loaders, listers, dictionaries, etc.
There are two ways to create domains. One of them is using the % iKnow.Domain class. When using this approach, you must manually write the creation code for both the domain itself and all objects inside it. This process is quite complicated, it takes time and experience with iKnow, however, it allows you to implement complex iKnow-applications with post-processing of indexed data.
There is an alternative way based on using the % iKnow.DomainDefinition class , which is suitable for rapid prototyping. It allows you to create a domain declaratively through a description of its structure in an XML representation. And the domain object itself is created automatically when the class is compiled. This method is simpler, more compact, allows you to quickly create a new domain from scratch. In this article, I will describe the second way of working and give code examples.
Comment. I create and test code in the Caché 2015.2 Field Test version. The fundamental difference from previous versions is support for stemming and lemmatization. In this regard, there will be a difference in a number of settings, but more on that later. So let's get started.
Step zero. Statement of the problem
Before starting to write code, I will formulate the problem that I will solve. We will write the simplest news aggregator. To do this, create a domain in iKnow, which will download articles from RSS feeds, and then teach him how to divide these articles by topic. I propose to take the categories of news: “politics”, “economics”, “sports” and, for example, “a threat from outer space”.
Step one. Creating a domain
Create a domain using DomainDefinition. To do this, just compile this class:
I want to note that the domain itself is completely empty, and is created as an object immediately after compiling the HabrDomain.News class. To verify this, run the
do $ system.iKnow.ListDomains () command
in the terminal. You will see that the NewsAggregator domain is formed, with an ID equal to 1 (the ID may differ if you have already created domains), without downloaded texts (# of sources is 0).
Step Two Domain setting
By setting up a domain you can understand a very wide range of actions, but now we will focus on the configuration of the domain. The configuration is used only when uploading documents to the domain and is responsible for how iKnow will process the text. A configuration is created as an object, so it can be created once, and then reused repeatedly for different domains in a given area. Theoretically, the configuration is not mandatory, and all settings can be replaced with some “default” values, but, in this case, it’s better to forget about working with Russian texts right away.
To describe the configuration in DomainDefinition, add a line inside the Domain tags:
According to this line, we created a configuration with the name “Russian”, which will use the semantic model of the Russian language for text analysis, while the mechanisms for automatically detecting the language of text documents will be disabled. The “stemming” parameter with the value “DEFAULT” is a necessary (but not sufficient) condition for Russian lemmatization to be connected when analyzing the text.
To complete the tuning of stamming, add another line after the configuration:
Step Three Creating fields for metadata
When we upload articles to our domain, not only texts will be loaded. You can still get a lot of useful information from RSS feeds, which we can then use. To store this data, configure meta-information fields. To do this, add the following lines to the XData block of the class:
Thus, we have described 5 fields. PubDate will store the publication date of the article, Title - its title, Link - a link to the full text. In the Agency field we will load the name of the resource from which we downloaded the article, and in Country - the territorial affiliation of the source.
Step Four We describe the sources where we will load the articles.
When setting the task, we agreed that the texts will be downloaded from RSS feeds. As an example, I’ll take the feed http://static.feed.rbc.ru/rbc/internal/rss.rbc.ru/rbc.ru/mainnews.rss rbc.ru, which publishes news from all sections. To tell iKnow to work with this resource, add the code:
Now I will describe in more detail the fields of this record. serverName is the server name and the first part of the RSS feed link ending with the name of the top-level domain (in our case .ru). The second part of the link is written in the url parameter. Please note that url always starts with “/”. From each publication we will load two text fields - a title and a text (by text I mean the body of the article that is published in the feed; most often this is a short introduction, not a full-fledged material)
Next is the converter. In our case, it is the standard% iKnow.Source.Converter.Html, and its purpose is to remove all html tags from the loaded text to get clear text.
And finally, we describe the loading of metadata. A little higher we created 5 fields, three of which iKnow fills automatically, this is the publication date, title and link to the full article. The two remaining fields will be populated from here. In the field “Agency” will be written “RBC”, and in “Country” - “Russia”.
Step Five Dictionaries
One of the advantages of iKnow technology is that for basic text analysis, dictionaries are not used, but a compact and fast semantic language model is used. But there are a number of tasks in which dictionaries we still need. One of them - matching - assignment of articles to topics (for example, articles on sports, politics, economics or the threat of an alien invasion). In other words, when describing a domain, we can specify the terms when mentioned in the text the article will be assigned to one or another category. Add the following code to the class:
The matching section contains a set of dictionaries. Each dictionary describes its category, the terms in which are divided into objects (subcategories) and terms. The purpose of this article is to simply demonstrate the capabilities and mechanisms of iKnow, while for a serious task, dictionaries should also be serious and very voluminous.
Step Six Launch
Now our domain is fully described.
A few words about the DeleteDomain method, which I added to the code. The created domain exists as an object of the% iKnowDomain class, but it can only be deleted by the internal methods of the HabrDomain.News class, since it is it that manages the domain.
Finally, we can start the calculation.
do ## class (HabrDomain.News).% Build ()
As a result, articles from the sources indicated by us will be added to the NewsAggregator domain created during compilation. In addition, the data will be analyzed for markers from the Matching dictionary.
Seventh step. Viewing results
To view the results, it is most convenient to use one of the existing UIs, for example, Knowledge Portal , Indexing Results, and Matching Results.

Figure 1. Knowledge Portal.
Knowledge Portal allows you to conduct an initial analysis of the results of iKnow. Here you can select any of the created domains, in our case it is NewsAggregator. The table “Top concepts” shows the frequency of mentioning of certain concepts, while frequency is the number of references to the concept, and spread is the number of articles in which the concept is present. If we select any concept in this table (the “Russia” concept is now selected, Figure 1), the contents of the “Similar Entities”, “Related Concepts”, “Paths”, “Sources” tables will be updated.
The “Similar Concepts” table displays similar concepts. In our case, those concepts where the word “Russia” is found, but additional terms (for example, “the ambassador of Serbia in Russia”) will be similar. The table “Related Concepts”, in our case, it turned out to be empty due to the small number of loaded articles, will contain a list of concepts that are most often mentioned related to the selected one. In the example below, such concepts are in italics.
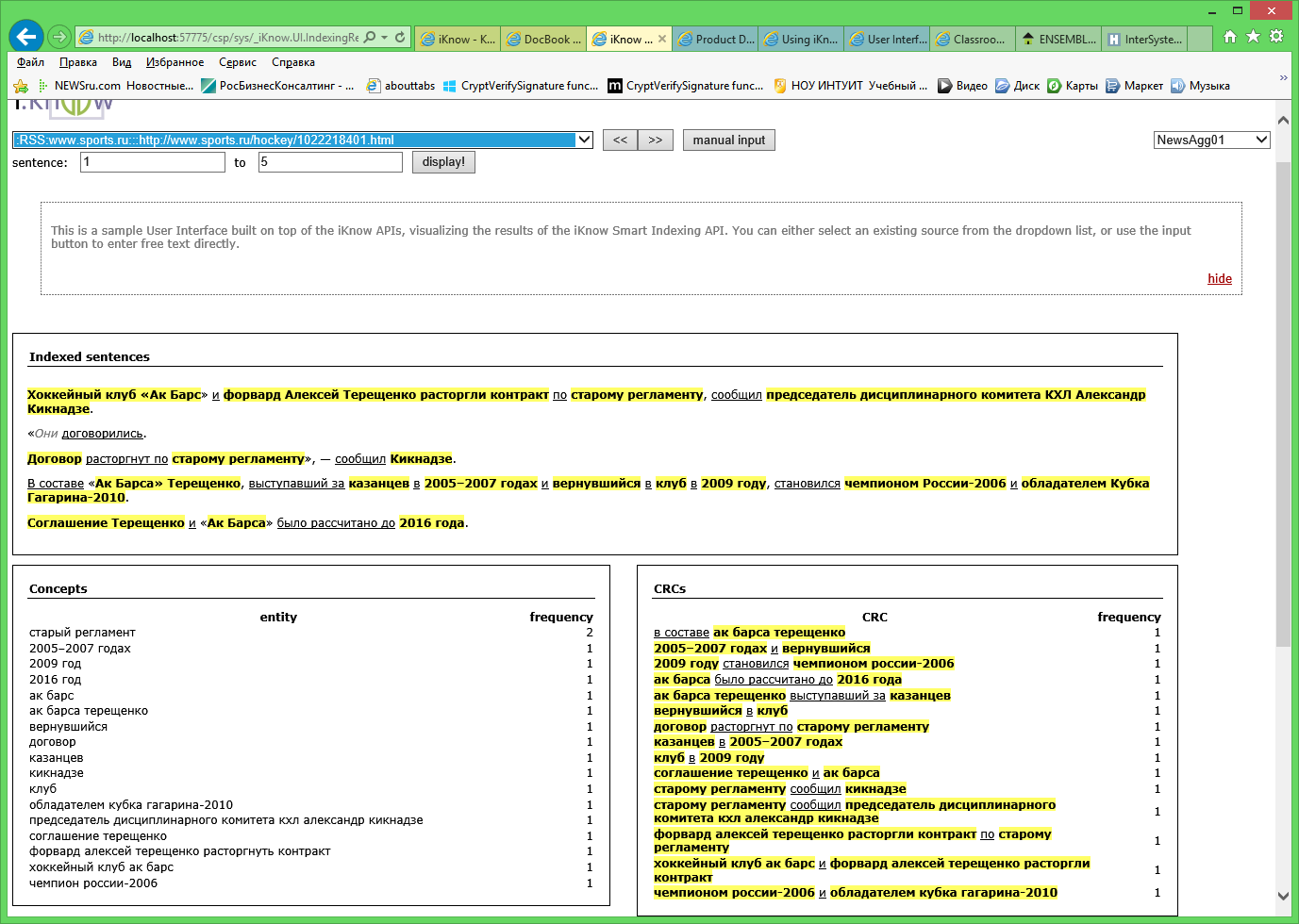
Figure 2. Indexing Results.
The Indexing Results window allows you to analyze indexing results. Here, concepts are highlighted in color, underlined in italics - links, and gray italics - insignificant words. As a rule, this window is used to check the correctness of the domain settings based on the indexing results, but it is also very convenient for reading the texts of articles (for example, when compiling dictionaries).
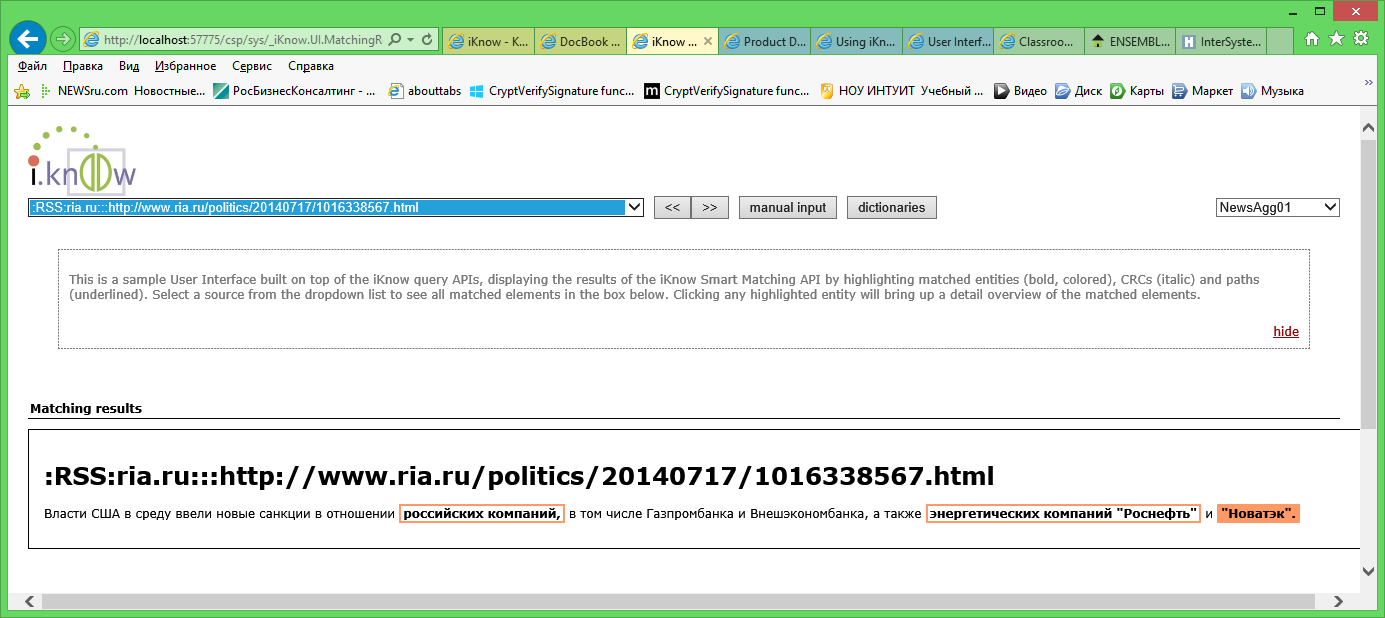
Figure 3. Matching Results.
Finally, the third available window is Matching Results. Here you can see the results of categorizing articles by dictionaries that we added to the domain description. The concept highlighted in red in the text means that it exactly matches the term from the dictionary. If a redhead only has a concept frame, it is similar to a dictionary.
It's time to take stock. We learned how to create the simplest news aggregator. For this, a domain was formed using the% iKnow.DomainDefinition class. A configuration was created in this domain that supports the Russian language and the lemmatization tool. Sources in the form of RSS feeds have been added. And finally, we created dictionaries for categorization. After that, they started building the domain and, using the standard UI, analyzed the results.
The article shows an example of creating an iKnow domain by analyzing news from an RSS feed as an example. To create a domain, the% iKnow.DomainDefinition class was used. A domain configuration was created with support for the Russian language and lemmatization, a source of RSS feeds was added, a simple dictionary for categorizing articles was created.
The DomainDefinition class is great for quickly creating domains and prototyping using iKnow. In real applications, dictionaries of terms for categorization and sentiment analysis include hundreds or even thousands of words. For such projects, the% iKnow.Domain class is used, which also allows you to perform other interesting tasks. This will be discussed in my next article.
Let's start by creating a domain. A domain in iKnow can be compared with an area in Caché or with a mailbox in the entrance of your home. This is some container where texts are loaded. In addition to texts, the tools necessary for their analysis are stored there, for example, configurations, loaders, listers, dictionaries, etc.
There are two ways to create domains. One of them is using the % iKnow.Domain class. When using this approach, you must manually write the creation code for both the domain itself and all objects inside it. This process is quite complicated, it takes time and experience with iKnow, however, it allows you to implement complex iKnow-applications with post-processing of indexed data.
There is an alternative way based on using the % iKnow.DomainDefinition class , which is suitable for rapid prototyping. It allows you to create a domain declaratively through a description of its structure in an XML representation. And the domain object itself is created automatically when the class is compiled. This method is simpler, more compact, allows you to quickly create a new domain from scratch. In this article, I will describe the second way of working and give code examples.
Comment. I create and test code in the Caché 2015.2 Field Test version. The fundamental difference from previous versions is support for stemming and lemmatization. In this regard, there will be a difference in a number of settings, but more on that later. So let's get started.
Step zero. Statement of the problem
Before starting to write code, I will formulate the problem that I will solve. We will write the simplest news aggregator. To do this, create a domain in iKnow, which will download articles from RSS feeds, and then teach him how to divide these articles by topic. I propose to take the categories of news: “politics”, “economics”, “sports” and, for example, “a threat from outer space”.
Step one. Creating a domain
Create a domain using DomainDefinition. To do this, just compile this class:
Class HabrDomain.News Extends %iKnow.DomainDefinition
{
XData Domain {XMLNamespace =TEST]
{
I want to note that the domain itself is completely empty, and is created as an object immediately after compiling the HabrDomain.News class. To verify this, run the
do $ system.iKnow.ListDomains () command
in the terminal. You will see that the NewsAggregator domain is formed, with an ID equal to 1 (the ID may differ if you have already created domains), without downloaded texts (# of sources is 0).
Step Two Domain setting
By setting up a domain you can understand a very wide range of actions, but now we will focus on the configuration of the domain. The configuration is used only when uploading documents to the domain and is responsible for how iKnow will process the text. A configuration is created as an object, so it can be created once, and then reused repeatedly for different domains in a given area. Theoretically, the configuration is not mandatory, and all settings can be replaced with some “default” values, but, in this case, it’s better to forget about working with Russian texts right away.
To describe the configuration in DomainDefinition, add a line inside the Domain tags:
According to this line, we created a configuration with the name “Russian”, which will use the semantic model of the Russian language for text analysis, while the mechanisms for automatically detecting the language of text documents will be disabled. The “stemming” parameter with the value “DEFAULT” is a necessary (but not sufficient) condition for Russian lemmatization to be connected when analyzing the text.
To complete the tuning of stamming, add another line after the configuration:
Step Three Creating fields for metadata
When we upload articles to our domain, not only texts will be loaded. You can still get a lot of useful information from RSS feeds, which we can then use. To store this data, configure meta-information fields. To do this, add the following lines to the XData block of the class:
Thus, we have described 5 fields. PubDate will store the publication date of the article, Title - its title, Link - a link to the full text. In the Agency field we will load the name of the resource from which we downloaded the article, and in Country - the territorial affiliation of the source.
Step Four We describe the sources where we will load the articles.
When setting the task, we agreed that the texts will be downloaded from RSS feeds. As an example, I’ll take the feed http://static.feed.rbc.ru/rbc/internal/rss.rbc.ru/rbc.ru/mainnews.rss rbc.ru, which publishes news from all sections. To tell iKnow to work with this resource, add the code:
Now I will describe in more detail the fields of this record. serverName is the server name and the first part of the RSS feed link ending with the name of the top-level domain (in our case .ru). The second part of the link is written in the url parameter. Please note that url always starts with “/”. From each publication we will load two text fields - a title and a text (by text I mean the body of the article that is published in the feed; most often this is a short introduction, not a full-fledged material)
Next is the converter. In our case, it is the standard% iKnow.Source.Converter.Html, and its purpose is to remove all html tags from the loaded text to get clear text.
And finally, we describe the loading of metadata. A little higher we created 5 fields, three of which iKnow fills automatically, this is the publication date, title and link to the full article. The two remaining fields will be populated from here. In the field “Agency” will be written “RBC”, and in “Country” - “Russia”.
Step Five Dictionaries
One of the advantages of iKnow technology is that for basic text analysis, dictionaries are not used, but a compact and fast semantic language model is used. But there are a number of tasks in which dictionaries we still need. One of them - matching - assignment of articles to topics (for example, articles on sports, politics, economics or the threat of an alien invasion). In other words, when describing a domain, we can specify the terms when mentioned in the text the article will be assigned to one or another category. Add the following code to the class:
The matching section contains a set of dictionaries. Each dictionary describes its category, the terms in which are divided into objects (subcategories) and terms. The purpose of this article is to simply demonstrate the capabilities and mechanisms of iKnow, while for a serious task, dictionaries should also be serious and very voluminous.
Step Six Launch
Now our domain is fully described.
full class text:
Class HabrDomain.News Extends %iKnow.DomainDefinition
{
XData Domain [ XMLNamespace = TEST ]
{
A few words about the DeleteDomain method, which I added to the code. The created domain exists as an object of the% iKnowDomain class, but it can only be deleted by the internal methods of the HabrDomain.News class, since it is it that manages the domain.
Finally, we can start the calculation.
do ## class (HabrDomain.News).% Build ()
As a result, articles from the sources indicated by us will be added to the NewsAggregator domain created during compilation. In addition, the data will be analyzed for markers from the Matching dictionary.
Seventh step. Viewing results
To view the results, it is most convenient to use one of the existing UIs, for example, Knowledge Portal , Indexing Results, and Matching Results.
Figure 1. Knowledge Portal.
Knowledge Portal allows you to conduct an initial analysis of the results of iKnow. Here you can select any of the created domains, in our case it is NewsAggregator. The table “Top concepts” shows the frequency of mentioning of certain concepts, while frequency is the number of references to the concept, and spread is the number of articles in which the concept is present. If we select any concept in this table (the “Russia” concept is now selected, Figure 1), the contents of the “Similar Entities”, “Related Concepts”, “Paths”, “Sources” tables will be updated.
The “Similar Concepts” table displays similar concepts. In our case, those concepts where the word “Russia” is found, but additional terms (for example, “the ambassador of Serbia in Russia”) will be similar. The table “Related Concepts”, in our case, it turned out to be empty due to the small number of loaded articles, will contain a list of concepts that are most often mentioned related to the selected one. In the example below, such concepts are in italics.
- [ Inflation ] in [Russia]
- [ EU trade deficit ] with [Russia]
- [Russia] reserves [the right ] to [retaliatory measures]
Figure 2. Indexing Results.
The Indexing Results window allows you to analyze indexing results. Here, concepts are highlighted in color, underlined in italics - links, and gray italics - insignificant words. As a rule, this window is used to check the correctness of the domain settings based on the indexing results, but it is also very convenient for reading the texts of articles (for example, when compiling dictionaries).
Figure 3. Matching Results.
Finally, the third available window is Matching Results. Here you can see the results of categorizing articles by dictionaries that we added to the domain description. The concept highlighted in red in the text means that it exactly matches the term from the dictionary. If a redhead only has a concept frame, it is similar to a dictionary.
It's time to take stock. We learned how to create the simplest news aggregator. For this, a domain was formed using the% iKnow.DomainDefinition class. A configuration was created in this domain that supports the Russian language and the lemmatization tool. Sources in the form of RSS feeds have been added. And finally, we created dictionaries for categorization. After that, they started building the domain and, using the standard UI, analyzed the results.
The article shows an example of creating an iKnow domain by analyzing news from an RSS feed as an example. To create a domain, the% iKnow.DomainDefinition class was used. A domain configuration was created with support for the Russian language and lemmatization, a source of RSS feeds was added, a simple dictionary for categorizing articles was created.
The DomainDefinition class is great for quickly creating domains and prototyping using iKnow. In real applications, dictionaries of terms for categorization and sentiment analysis include hundreds or even thousands of words. For such projects, the% iKnow.Domain class is used, which also allows you to perform other interesting tasks. This will be discussed in my next article.