Finding the perfect file storage

Earlier we looked at a prototype of a scalable read-only file system. It was possible to show that, using the proposed architecture, it is possible to build a file system of any capacity, with a guaranteed access time commensurate with that for accessing the file within one physical disk.
Next, we will try to figure out whether such an approach can be useful in building a general-purpose file system.
It should be noted in advance that the author is not a recognized expert in the field of distributed file systems and does not set out to make humanity happy with yet another brilliant invention. Rather, I want to demonstrate to the community a sound idea and try to undermine it in the discussion. In addition, public discussion can save the idea from patent protection.
So, let's recall the main conclusions,
which were made when building the prototype read-only system:- The contents of the file system can be divided into two parts
- Actually data, file contents
- Metadata describing file locations and related information
- Metadata should not be part of the file system structure, it is simply data about other data. There should be no special mechanisms responsible for the user-defined file system structure.
- To describe the file system, its representation by a tree is well suited, in which the key is the path, and the value is the file data (and appendage from the attributes)
- Metadata is easily compressed.
- Data and metadata can be stored on various media, including media with different physical structures. So, relatively small metadata can be placed on faster and more expensive devices, and actually file data - on something simpler.
Now the goals that I want to achieve:
- Modularity (scalability) by capacity
- Performance modularity
- Modularity on external interfaces
- Logarithmic degradation of performance with data growth
In general, we are not talking about a distributed network of devices based on a physical network of incomprehensible topology. It is assumed that outwardly everything looks like a single device that implements the functions of a general-purpose file system. And the internal structure is our purely internal affair.
A bit about the problems
.Modularity is good, but let's start from the end, with the logarithmic degradation of performance. Which implies the use of a balanced tree.
A tree is a well-known and understandable structure that has long been successfully used in DBMS and file systems. The undoubted advantage of balanced trees is the ability to grow and shrink without degradation, while maintaining acceptable disk space utilization.
In our case, the file system is a tree, where the key is the path to the file, and the value is its attributes and the body of the file. Moreover, the body is an analogue of BLOB'a and can be located in a different address space, for example, in a different storage medium.
The initial impulse was just that - but what if we make a “super-tree”, whose “super-pages” are autonomous disk subsystems that logically fall apart in half when overflowing, similar to how it happens in a B-tree. If not completed, two super-pages logically merge into one, unnecessary disk space goes back to the reserve. The transitions inside the superpage are supposed to be relatively cheap, and between them expensive.
Unfortunately, being implemented in the forehead, such a scheme is not viable. The explanation is rather boring, but it is necessary.
Trees mean paging disk space. Once pages link to each other, page identifiers must exist. A page identifier is a number that can be easily converted to an offset within a file / device. The identifier space is one-dimensional, even if the pages are on a pile of disks, we must indicate in advance (perhaps implicitly) how we are going to saw the address space on these devices.
What follows from this? On the one hand, when writing to the file system, we are dealing with a one-dimensional order of file paths, and we do not control these paths, the user is free to name the files / directories as he pleases.
On the other hand, there is a one-dimensional space of page identifiers, the order of which is somehow related to the sequence of file creation. We also do not control this order.
There is no natural connection between the order of traversal of the file tree and the order of pages that will have to be read in this case. Correlations, of course, can arise, for example, when unpacking from the archive, but it is hardly reasonable to rely on such a connection. And the situation when logically close information is physically strongly separated (the locality of links is broken) is quite normal and very likely.
This is how the phase diagram of reading pages looks when traversing a test B-tree constructed by an insert in random order:

Fig. 1
By abscissa - the number of the current page being read, by ordinate - the last time it was read.
And so - a tree containing the same data passed through the “sump”, a buffer-drive, during which the data is overflowed before sorting:

Fig 2
Ideally, when the insertion order coincides with the natural order of the key, we would just have a diagonal line.
In the case of recording file system metadata, the use of a "settler" is impossible, and when filling out the tree, the pages will be allocated in accordance with the first option.
What does this threaten? The fact that when it comes time to cut a super page, we will face a difficult choice:
- or reload the contents of half the page to the free space of the new page, which may require a lot of time. In a normal B-tree, there is no such problem. the crowded page is already in RAM and copying some of its contents is dismissively cheap compared to allocating a new page.
- or put up with the fact that isolating the super pages from each other will not succeed, and with splitting there will be a mass of horizontal links. Over time, this will lead to erosion of the locality of links and degradation of performance .. Let’s turn back to Figure 1 and imagine that we have 6 super pages (according to the number of cells) and each time the traverse line crosses the grid, we switch from one super pages to another. And, of course, we pay for it with time. You can, of course, console yourself with the fact that the logarithmic degradation of productivity during tree growth is achieved by the very fact of the tree's existence. Even if each step when descending the tree is accompanied by a transition to another super-page, it will still be a logarithm, albeit with an unpleasant coefficient. As if we disabled the disk cache in a regular file system and each call required physical operations with the device. But no, I want something more effective.
On the dimension of the identifier space.
An awkward question, why do we think the page id space is one-dimensional? Partly for historical reasons, but mainly because it suits everyone and there is no reason to change anything. It is technically not difficult, having hundreds / thousands of disks, to make two-dimensional addressing of pages - (disk ID, position on the disk) or three-dimensional (page ID, heap ID, disk ID, disk space). It is not clear, however, what to do with such an anisotropic address space, but the fact of technical feasibility has yet to be comprehended.
Funny, before the author had to rack his brains over the question of how to more efficiently ram a 2-4 dimensional spatial index into a one-dimensional space of page addresses. And now we need to construct the page space in such a way as to place two one-dimensional spaces in it - paths and file creation order. A successful design will be able to play the role of a "settler", increase the locality of the file system and reduce the number of long / expensive transitions in it.
Let's get down to it.
Let's start with a description of the basic elements:
- metadata tree - file system metadata repository. The key in the tree is the file path, the value is the file metadata and a link to the file body. The tree is fully balanced. The expected height of the tree depends on the number of elements that can be placed on the page. For example, if this is an average of 10 elements, then for a billion files you will need a tree of height 9, if 100 - then 5. Accordingly, the access speed will differ by 2 times.
- page - an element of the metadata tree. Sheet pages contain both key and metadata, intermediate pages contain only keys and links to child pages. The link to the page must be unique throughout the file system. We will understand below how to achieve this. Pages are expected to lie on fast storage devices with minimal positioning time, SSDs, for example.
Let us dwell separately on the root page of the tree. As the tree grows, the root page can wander from place to place, and a mechanism is needed with which you can at any time find out which page is currently root. This indicates the need for a registry.
It is generally assumed that the tree page contains at least 2 elements. And in each element we have a key of arbitrary length. This is a difficult moment, we will not go into it for now, we will simply assume that the solution exists, for example, based on the fact that- Page elements are ordered and most likely contain a common prefix.
- This prefix can be calculated when viewing higher pages.
- Paths are easy to compress
- Use of dictionaries is possible
- Page size we choose ourselves
- There may be reasonable restrictions on the length of names and paths.
- the body of the file is what it was all about. Everything else is just a frame for this jewel. We will assume that, unlike pages, access to bodies is more streaming and less messy. So you can place them on cheaper conventional hard drives. The body can consist of several fragments, for each fragment its own entry in the tree is made. It is important that fragments of one body are physically located nearby if possible.
- drive . There are two types - SSD (for pages) and regular hard drives (HDD) (for file bodies). We assume that it is fault tolerant, for example, being implemented as RAID. It has a unique identifier throughout the file system.
- storage module . What we called the “super page” above. Designed to work with both pages and file bodies. Therefore, it consists of two types of disks. Wherein
- The module contains those fragments of bodies, the links to which are in its pages. In this sense, it is autonomous.
- It has a unique identifier throughout the file system.
- A module can consist of a different, albeit limited, number of disks of both types
- It is assumed that there is a pool of free disks from which the module can scoop them as its fullness grows.
- This pool can be common to all modules, and then there must be a mechanism for switching disks with storage modules. Or another extreme option - the module holds a certain number of disks in the reserve and signals when the reserve runs out, after which the disks can be connected “by hand”. And maybe some intermediate option.
- At some point, the number of serviced disks of one of the types ends and the storage module becomes full
- Executive module - implements work with a tree. And also carries out the corresponding work with the bodies of files. It is able to search, add, delete and modify elements on pages and data, regardless of which storage modules it is located on. Consequently, it assumes the role of a distributed transaction manager.
Let's see how the filling of our file system occurs.
- Suppose we ask the executive module to create a file with a certain name in a certain directory.
- The executive module creates a global transaction.
- It also prepares a key - the full file name and tries to insert a new record into the tree. The record also includes, of course, the file metadata (host, rights, ...), but we will keep silent about them for simplicity.
- Information about the location of the root page is well known.
- We subtract it and find in it in accordance with our key the ID of the subpage (if any).
- Each page is located on some kind of disk, which in turn belongs to some kind of storage module. It would be logical if the identifiers of the module and the disk together with the position on the disk make up the page identifier.
- Thus, from the ID of the subpage, the executive module will know which storage module to use for which page from which disk.
- Subtract this page, etc. recursively go down to the sheet page
- In the sheet page we find a place for our new record and try to insert it. To do this, we have to capture it for recording from the corresponding storage module. Why, in turn, need a local transaction
- It may happen that there is not enough space on the sheet page for our new entry. In this case, as expected, we will create a new page and share approximately equally the contents of the old one. Wherein
- it is logical if we create a new page in the same storage module. The module selects the appropriate drive and creates a page for us on it
- We go one step up the stack of read pages and try to insert the record corresponding to the newly created page into a higher page.
- To do this, we will have to capture it for recording at its storage module
- It may happen that this page also overflows and we have to go up another step. And so on until the height of the tree and the creation of a new root page.
- As a result, after inserting a new record, we have a global transaction and a certain number of local transactions. To fix the insertion, a two-phase commit mechanism is suggested, for example, XA transactions , where the resource managers (RM) are the storage modules and the registry, and the transaction manager (TM) is the execution module
- Because we are talking about the parallel operation of several executive modules, rather, the XA + model is applicable. The question of who will take on the role of CRM (communication resource manager) remains open. Most likely the one who keeps the registry
- When you create a new page, it may turn out that the sheet page storage node is full. The choice in this situation is small - either create a new storage module, or cling to an already existing unfilled one. Creating new modules is dangerous; this is a rather expensive resource, and their number is physically limited.
- For a list of unfilled storage modules, you can contact the system registry, but the registry does not know anything about the context of the current request and can only issue a random module. This is fraught with the fact that new pages sprouting from our crowded module will begin to creep along all other modules, destroying data locality and inhibiting overall performance. A scenario that I would like to avoid.
- On the other hand, no one knows the context of the current request better than the current request itself. We already have a stack of read pages, each of which is assigned to some kind of storage module. Thus, we are able to find a new module among the higher ones.
- Nevertheless, you will have to contact the system registry to check the overflow of modules
- If it so happened that among them there are no unfilled (or all pages are in the same module), you can dig deeper. View the contents of all non-leaf pages on the stack in the hope of finding links to previously used storage modules in it. If there are several links, select the nearest one.
- You can go even further, but for this you have to change the structure of the page. We will distribute up the stack information about the used storage modules.
- We force each non-leaf page to store a list of storage modules in which the page itself and all its descendants are located
- Each time after creating a new page and after the tree structure has been established (after a possible rebalancing, for example), we distribute information about the storage module of this page up the stack of its predecessors.
- If this module is already registered, nothing happens. Otherwise, you have to capture upstream pages for writing and register a new module in them. How to make sure that you do not have to rebalance the tree again, the question is open, perhaps you should limit the number of registered modules to some reasonable number and reserve a place for them
- Now, when we have a question, to which module to bind a new page (more precisely, which storage module to request a new page from), we will go up the stack and look for a suitable module in the registered lists.
- Well, if this does not help, you will have to contact the system to create a new storage module.
- So, in secret, we got rid of the one-dimensional space of page addresses. The page identifier has as many as three dimensions (module ID, disk ID, position on the disk), although you could get by with two if you throw out the disk identifier and assign the storage module with the task of sorting out your addresses yourself. What does it give? Flexibility. For example, if suddenly a tree begins to grow vigorously in some local place, our addresses simply grow in breadth, more or less maintaining their locality. in the one-dimensional case, this would be much more difficult to achieve.
- Ok, we created a tree entry, what about the body of the file? The situation with them is simpler because bodies are independent of each other.
- The file storage module is selected along with the page from which the link points to this body.
- As with the page, the body identifier consists of the storage module ID, disk ID, and disk space.
- Undoubtedly, in the storage module there must be a distributor of disk memory, one for all or one for each mapped drive, now it does not matter.
- It’s also not important at the moment how this memory distributor is arranged
- But it is important that working with file bodies supports distributed transactions at the level of the resource manager
- It is worth noting one subtle point.
- Let's say some sheet page is full and we are going to saw it.
- It so happened that the fragments of the page fell into different storage modules.
- But there were already some records in this page and they pointed to disks from the old module.
- It would be nice to take and transfer files from one module to another. But after all, these files can be of considerable size and their transfer can take a lot of time, which we cannot afford
- Well, ok, just let the leaf pages point to file drives from another storage module. It will turn out something like NUMA, access to other people's file disks from the storage module is possible, but costs more.
- Fortunately, this is a relatively rare case, and it cannot significantly affect overall performance.
- And you can imagine a demon who will walk on a tree and in the background to correct the consequences of such excesses.
It's time to look at the big picture:
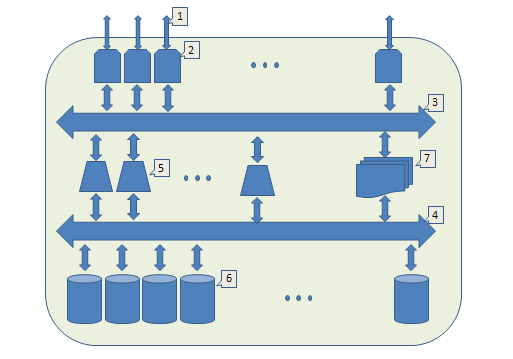
- Front end,
- Input-output module (IO). It accepts requests from outside, appoints an executor, waits for a response, and sends the result. By increasing their number, we scale the external bandwidth
- An internal bus (for example, local ethernet) through which IO modules and executive modules communicate.
- Another internal tire. Through it, storage modules communicate with executive modules.
- Executive module, implements work with a tree and manages distributed transactions. By increasing their number, we scale the possibilities of parallel execution of requests.
- Storage module. With their help, we scale the capacity of the entire system.
- System registry
It is time to turn our eyes to the real world and see how the problems described are actually solved.
GlusterFS
Let's consider the DHT mode as the one closest to the topic of this article.
- GlusterFS does not have a dedicated metadata service
- Files are distributed between servers using the file systems of these servers (with all their pros and cons)
- File structure is projected onto server file systems (brick in Gluster terms)
- It is argued that distributed storage is based on serial hashing technology , but this is some kind of degenerate case.
- The full file name is passed through a hash function that produces a 32-bit value
- the range is 32 bits in advance, when setting up the system it is divided into ranges - each of which points to a specific server
- Ranges can be adjusted manually, but in this case you need to understand exactly what you are doing
- Automatic splitting will be done in pieces at 0xffffffff / (number of servers)
- When creating a file, its server number is calculated and the file is created in the file system of this server
- When searching for a file,
- the server is calculated in a similar way, wherever it should lie
- An attempt is made to read a file from this server.
- if the attempt is unsuccessful, there is no such file
- requests are sent to search for this file to all servers of the system
- if the file was found on one of them, a link is created on the source server - a file with the desired name but zero length, with sticky-bit and xattr turned on indicating the current server
- The next time you search for this file, you can not make a broadcast request, but immediately contact the server you need
- How could it happen that the file ended up on a foreign server? For example, the regular server for this file is full. Or there has been a redistribution of hash value ranges, for example, after adding a new server.
- Adding a new server invalidates the share of 1 / (new number of servers) hash values in a sequential hash. But in the case of Gluster this share can be significantly larger due to its “naive” way of distributing hash ranges
- All this leads to the fact that over time the storage degrades and special efforts must be made to maintain it in an adequate condition.
- 'fix-layout' - go around the node and try to drag and drop files accessible through Link
- 'migration' - for each file the server is calculated where it should be and, if necessary, an attempt is made to transfer there. Very expensive procedure.
Sources:
http://www.gluster.org/
http://cloudfs.org/index.php/2012/03/glusterfs-algorithms-distribution/
http://people.redhat.com/ndevos/talks/Gluster- data-distribution_20120218.pdf
SWIFT
- Swift is not a universal file system, but an S3-compatible repository of objects. Any object is described by the triple “/ account / container / object”, where account points to the user, container is the user-defined way of grouping objects, and object is the path itself.
- To simulate the file system, containers and accounts processing servers are used that store data on their sqlite3 databases
- Object storage is similar to that in GlusterFS, but uses honest sequential hashing, in local terminology this ring
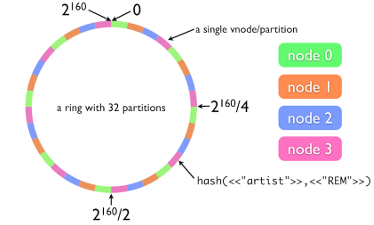
- The file name yields a 160-bit SHA-1 hash value
- For data storage (in this example) we use 4 nodes
- The hash key value range (in this example) is divided by 32, because we decided that 32 sections were enough for us
- Each section is assigned to its own node, possibly uneven distribution in accordance with the given weights
- Thus, by the hash value, we find out the number of the partition, and by it the number of the storage node
- The storage node stores files as is using the native file system (it is important that it supports xattrs)
- Now, if we decide to add a fifth node to the system, we must
- reassign the fifth part of the sections of each node to a new node
- Migrate data whose hash values are in the ranges of these reassigned partitions to a new node. 8 (i.e. 32/4) sections are not very well divided into 5, but at large values the granularity is not so noticeable.
- Be that as it may, data migration is a very costly procedure, even to just fill up a terabyte disk takes several hours. But without migration within the framework of architecture with sequential hashing, alas, nothing.
- For the purpose of data replication, the concept of a zone is introduced - a storage unit independent of unit failures from other zones. By default, each section consists of three zones. Not all zones must be operational at the time of writing the file, after the missing nodes rise, the data is automatically replicated to them.
- Container and account servers also have their own rings. Their sqlite3 databases are also stored and replicated on storage nodes.
Sources:
http://docs.openstack.org/developer/swift/
http://habrahabr.ru/company/mirantis_openstack/blog/176195/
https://julien.danjou.info/blog/2012/openstack-swift- consistency-analysis
CephFS
- Has a dedicated metadata service - Metadata Cluster, consisting of several Metadata Storage (MDS) in Ceph terms
- Data is stored on Object Storage Data (OSD)
- Including ODS and MDS store their data
- The file system structure is explicitly described in MDS. Changes to the file system are logged and replicated to ODS.
- It is believed that MDS should mostly work with the cache and read data with ODS only as a last resort. Therefore, at some point, the MDS overflows.
- Crowded MDS splits. In order to painlessly do this
- It looks something like this
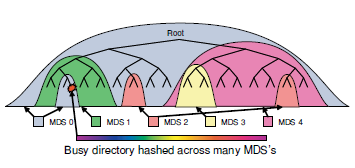
- Each MDS measures the popularity of its subdirectories using an access counter with exponential decay over time. Each operation with a directory increases this counter at the directory itself and all its higher directories in this MDS
- During MDS overflow, a suitable sub-hierarchy is resolved and transferred to another MDS
- This is done invisibly to users using transactional mechanisms.
- If a super-popular directory is found, the calls to which are much superior to everything else, there is a mechanism to smash this directory over several MDS
- It looks something like this
- To write data to ODS, the CRUSH algorithm is used
- Based on the path, description of the storage hierarchy and distribution policy, the place where the desired file is physically located (will be located) is calculated.
- The algorithm works in such a way as to eliminate data loss during any single failure.
- For example, we have several halls with racks, a separate hall may be flooded or a fire will arise in it. If we have several ethernet interfaces, any of them may fall off. The racks can be powered from different sources of energy, and the source can dry out.
- The hierarchy is configured, for example, as follows - in each room, racks are grouped by power supply and by interface.
- And, if the CRUSH replication policy is configured to be stored in triplicate, the algorithm will produce three ODS for storing the file so that each of them will be in its own room, with its own interface and they will all be powered from different sources.
- In addition to all this, efforts are being made to minimize the work that needs to be done during data migration in the event of storage growth.
- In addition to Ceph working in FS mode (CephFS), there is a lower-level S3 compatible interface: RADOS . Ceph S3 and CephFS and others are actually add-ons over it. Conceptually, RADOS is similar to SWIFT with another hash function - CRUSH works instead of rings.
Sources:
http://ceph.com/
http://ceph.com/papers/weil-ceph-osdi06.pdf
http://ceph.com/papers/weil-mds-sc04.pdf
http: // ceph. com / papers / weil-crush-sc06.pdf
http://ceph.com/papers/weil-rados-pdsw07.pdf
It is interesting to observe how people try to circumvent objective problems in existing solutions related to relying on a user-defined file system structure .
CephFS has resorted to rebalancing based on counting the cumulative popularity of descendants. Such a solution does not guarantee the balance of a tree, for example, a tree that grows only in one direction (for example, right down) will remain unbalanced.
Another visible problem with CephFS is the spread of popularity. In fact, any file access that affects popularity should extend to the root. At the same time, the corresponding directory must be captured per record, plus the costs of journaling, before the popularity is updated. A little too wasteful, the situation is saved by the fact that the entire top of the tree is in memory and these locks are relatively cheap.
And in S3-compatible systems you can see the forced balancing of the tree by administrative pressure - there are always three directories on the way. In most practical cases, this is enough or you can adapt. However, you can adapt to a wooden leg and a hook instead of a hand.
To summarize.
What distinguishes the proposed approach from existing solutions? Logical integrity and conceptual clarity. The separation of data and metadata is “in itself and not new” (C). However, we refused to bind to the user structure of the file system. And the proposed distributed transaction mechanism seems preferable to the inevitable data migration with changes in system capacity.
PS The author is grateful to Alexander Artyushin (DataEast), Alexei Knyazev (2GIS) and Alexei Medvedchikov (2GIS) for their help in preparing this work.
PPS In the heading of the article, a frame from c.f. "Indiana Jones: Searching for the Lost Ark."