How decompilation works in .Net or Java using the .Net example
- Tutorial
Today I would like to talk about decompiling applications (everything applies to the same Java, and to any language with some assumptions and limitations, but since I myself am a .Net developer, the examples will be quite a bit MSIL'ovizi :)).
For an introduction, I’ll list the current means of decompilation in the .Net world:
- JetBrains dotPeek (R # hotkey support, character server)
- Telerik JustDecompile (also not bad, many hotkeys)
- RedGate Reflector (analogue of dotPeek, but paid. Initially, it was the main one in the world .Net, but so far it was free)
- icsharpcode ILSpy (good, opensource. Useful when you yourself write code using Mono.Cecil, because This will give a better understanding of its work)
- 9rays Spices .Net Decompiler
- Dis # with inplace editor function
For software decompilation:
- Mono.Cecil (the main, coolest decompiler in the world .Net. At the output, you get an object "mirror" of the assembly contents. That is, as simple as possible, without any bells and whistles such as converting an IL array to DOM).
- ICSharpCode.Decompiler (add-on on mono.cecil that translates array [MSIL] to the DOM, where there are loops, switches and ifs. It is part of SharpDevelop / ILSpy)
- Harmony Core (similar from me, but storing information about symbols. In average condition, not ready for sale, help is welcome).
And now, I would like to describe how they work (you wonder how the machine from JetBrains works?). To at least understand how difficult it is: write your decompiler .Net assemblies back into C # code.

For a start, a full list of articles posted on Habré for this cycle Making shipped assemblies: interacting between domains without marshalling.
Making shipped assemblies: interacting between domains without marshalling.
Obtaining a .Net object pointer.
Manual cloning of a stream. When the Assembler + C # or Java = Love
Changing code system assemblies or "leakage» .Net Framework 5.0
How does decompilation in .Net or Java to .Net example,
continue to shred CLR: .Net objects outside the pool heaps SOH / LOH
Remove objects from a memory dump .Net applications
Making shipped assemblies: interacting between domains without marshalling. Obtaining a .Net object pointer. Manual cloning of a stream. When the Assembler + C # or Java = Love Changing code system assemblies or "leakage» .Net Framework 5.0 How does decompilation in .Net or Java to .Net example, continue to shred CLR: .Net objects outside the pool heaps SOH / LOH Remove objects from a memory dump .Net applicationsTo begin with, we put in our decompiler a set of requirements:
- Must accept any assembly: CLR 1. * to 4. *
- It is obliged to support not only C # output, but also MSIL, VB.NET and in general - which is enough for imagination and needs.
- The ability to choose between different versions of the language (for example, C #), while not having duplication in the implementation.
And now that the requirements are defined, let's think about how MSIL works, and how this will help us in quickly decompiling the application.
Unlike the processor language, which introduces some difficulties for us in the decompilation process (registers, optimizations, the ability to do one action in several ways), everything is as simple as possible in MSIL. If you need to write something to a local variable, then there is only one command for this. In another way, writing to a variable does not work. This property gives the final compiler (JITter) simplicity in implementation on the one hand ... On the other hand, it gives simplicity in implementation to the decompiling side.
The second property MSIL has is stack computation. There are no registers. And the only memory through which all calculations go is the stack. This absolutely does not mean that the final processor also calculates everything through the stack. Not. This means that for simplicity, this model uses the description of all calculations and calls to MSIL. What does this mean for us? This means that you can add two numbers with only one command, which, regardless of the parameters, is one. This is a command, pulling the data for addition from the stack, adds them and saves the result not somewhere but back to the stack. This is important, because for us, as for people writing a decompiler, this will not give rise to a huge branch of code.
Now we come to the most important thing: how does the decompilation process go.
So that after
Ldc_i4 5
Ldc_i4 4
Add
Stloc.1
Receive
Sum = 5 + 4;
The first difficulty that comes to mind: the position of the instructions may be different. That is, for example, for the code to be executed, it is not at all necessary that there will be no other instructions between ldind_i4 and add. For example, the following code is perfectly valid:
Ldc_i4 5
Ldc_i4 4
Ldc_i4 10
Stloc.2 // sum2
Add
Stloc.1 // sum1
What should be decompiled, for example, like this:
Sum2 = 10
Sum1 = 5 + 4;
Secondly, the names of variables in the release may be missing. Those. without impurities, the code will be like this:
= 10
= 5 + 4;
Thirdly, the most difficult thing, if-else, while, do-while, switch implementations may differ. This is especially true for lambdas, yields, async / awaits and other language gadgets, which are optional and are actually implemented on top of the usual functions of the language. How to take all this into account? In fact, both issues are resolved in only two ways.
Stack decompilation model
For decompilation, a certain MSIL code interpreter is written, which has its own stack and a command interpretation cycle. At each iteration of the loop, the next unexamined command is taken:
- If this is not a jump instruction, then we look at how many values on the stack are required by the team under study. Next, we get two computing nodes from the stack, which we put there, as the results of calculating the previous commands, and create a new node whose branches are the nodes taken from the stack. For the example above, it will look like this:
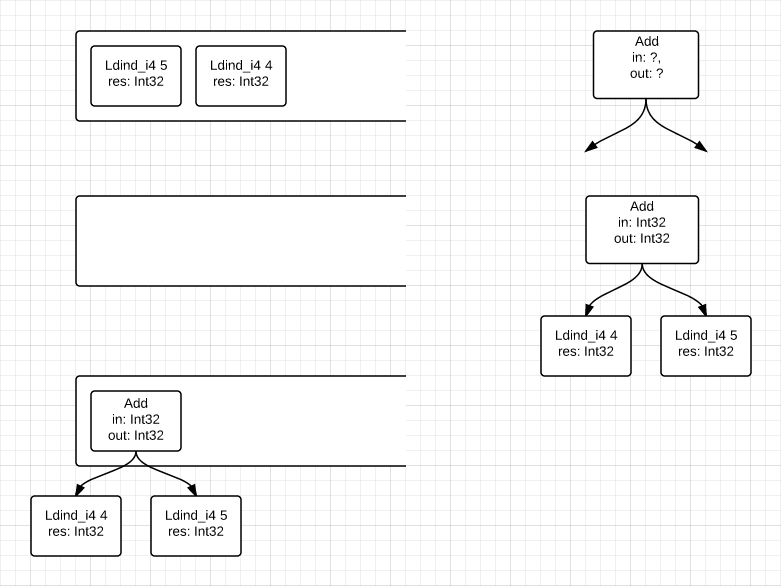
i.e. First, we have 4 teams in the input. The first two do not take anything at the entrance, but only give back - a number. Accordingly, we put them on the stack (ldind_i4 4, ldind_i4 5). After which we take the next command - Add. It takes two input values from the stack. Therefore, we read two nodes from our stack and, storing them as parameters of this command, save the command itself, onto the stack, because the team has a result. And any result is saved on the stack.
Further, the result can be passed to the method, or participate in other arithmetic operations, or returned using the ret statement.
Accordingly, if the expression were more complicated:Ldc_i4 5 Ldc_i4 4 Ldc_i4 10 Mul Add Stloc.1 // value = 5 + (4 * 10)
That process of creating the DOM would look like this:
After which the final assembly of the tree is performed: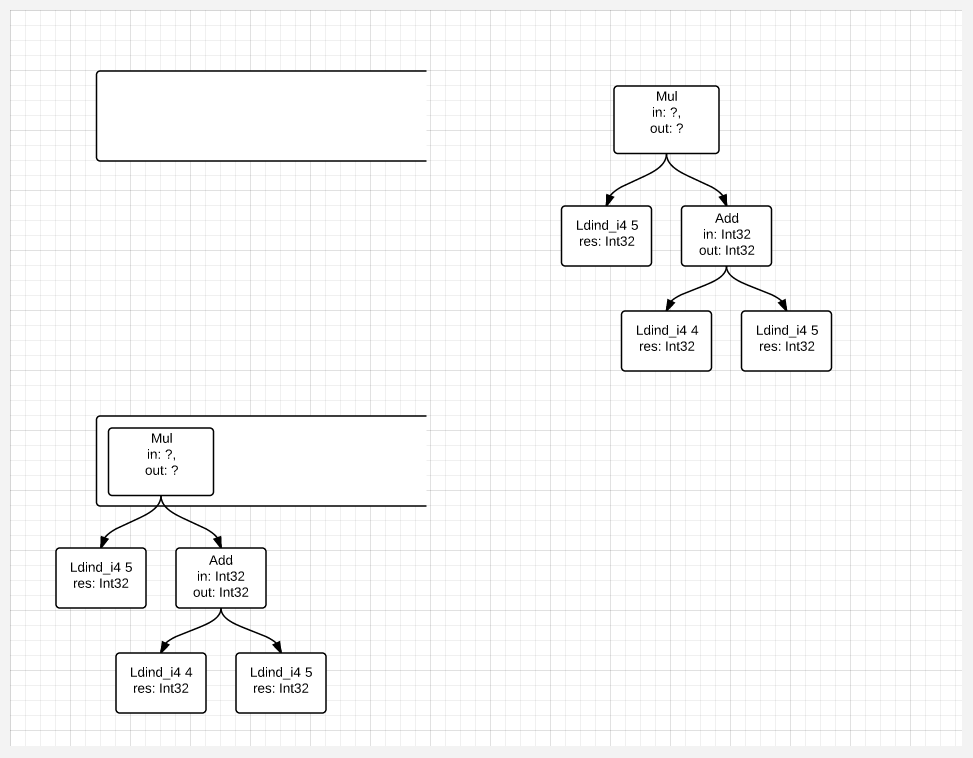
Method calls are constructed in the same way. Only in the case of methods, the number of parameters required for the call will be taken from the stack and stored in the node class of the method call. If the method returns a value, then the method call node will be stacked. If not, added to the group of ready-made expressions. - If there is a transition instruction (conditional or unconditional), a grouping node is created that contains the calculation node of the transition condition and the nodes that will be executed if this condition is met and not observed. At this stage, consider how these patterns look "bird's-eye view":
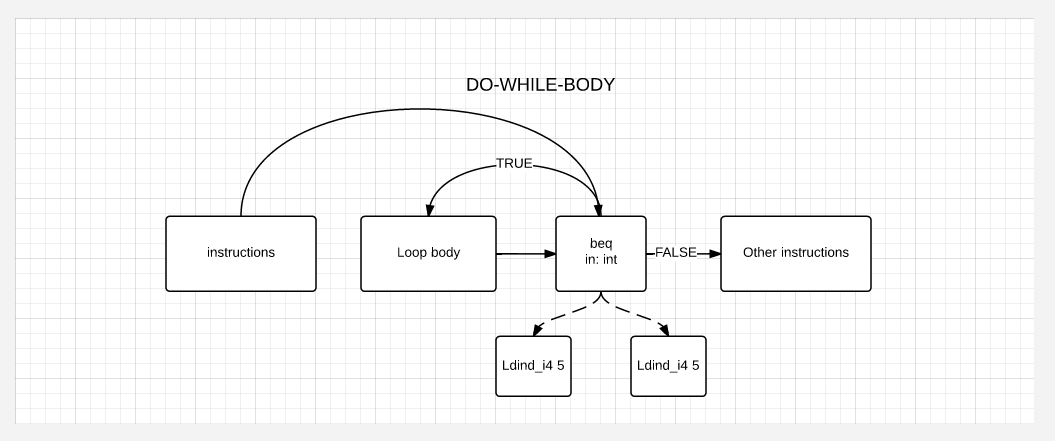
Wood assembly
These were all preparatory stages. Further, for modularity, classes are created that recognize any one structure in the tree and translate it into another. For example, if it is an if-else, then the presence of a conditional transition such that the transition is carried out forward is matched. Then the node is converted to an if-else node, the code after the transition is marked as the else (negative if) node, and the code between the condition and the else node is marked as positive if the node. If it matches as a conditional transition with the transition to previous instructions, then it matches as a while loop and the tree is also rebuilt. Accordingly, depending on the cleanliness of the performance of the matchers, at the output we get a converted tree for a specific programming language. Next, for each of the programming languages, we ask a lot of matchers that suit him. For example, cycles and conditions will suit everyone, because they will be present in almost all packages. And here, for example, async / await - it is only for C #. Therefore, only his package will be present.
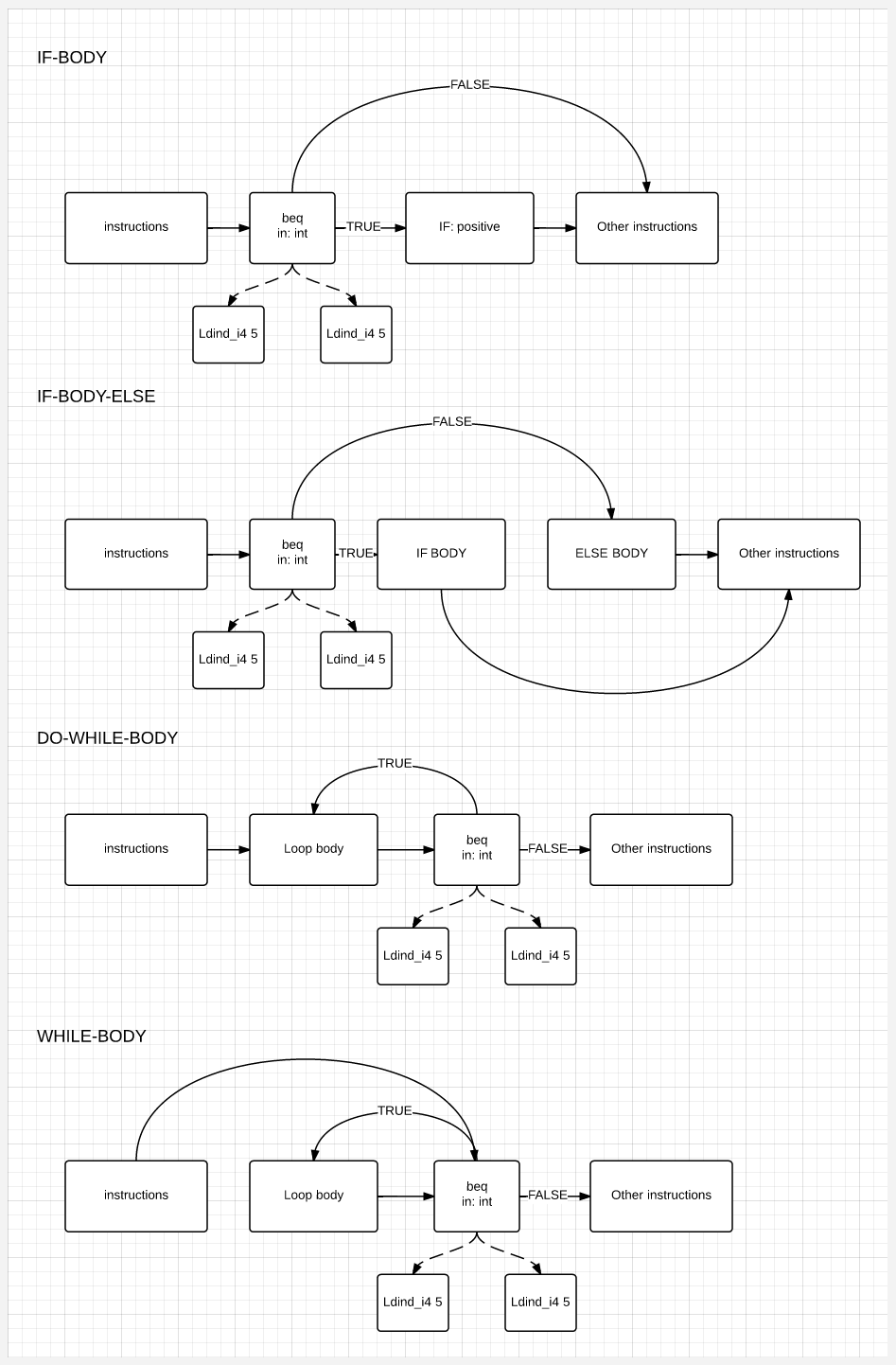
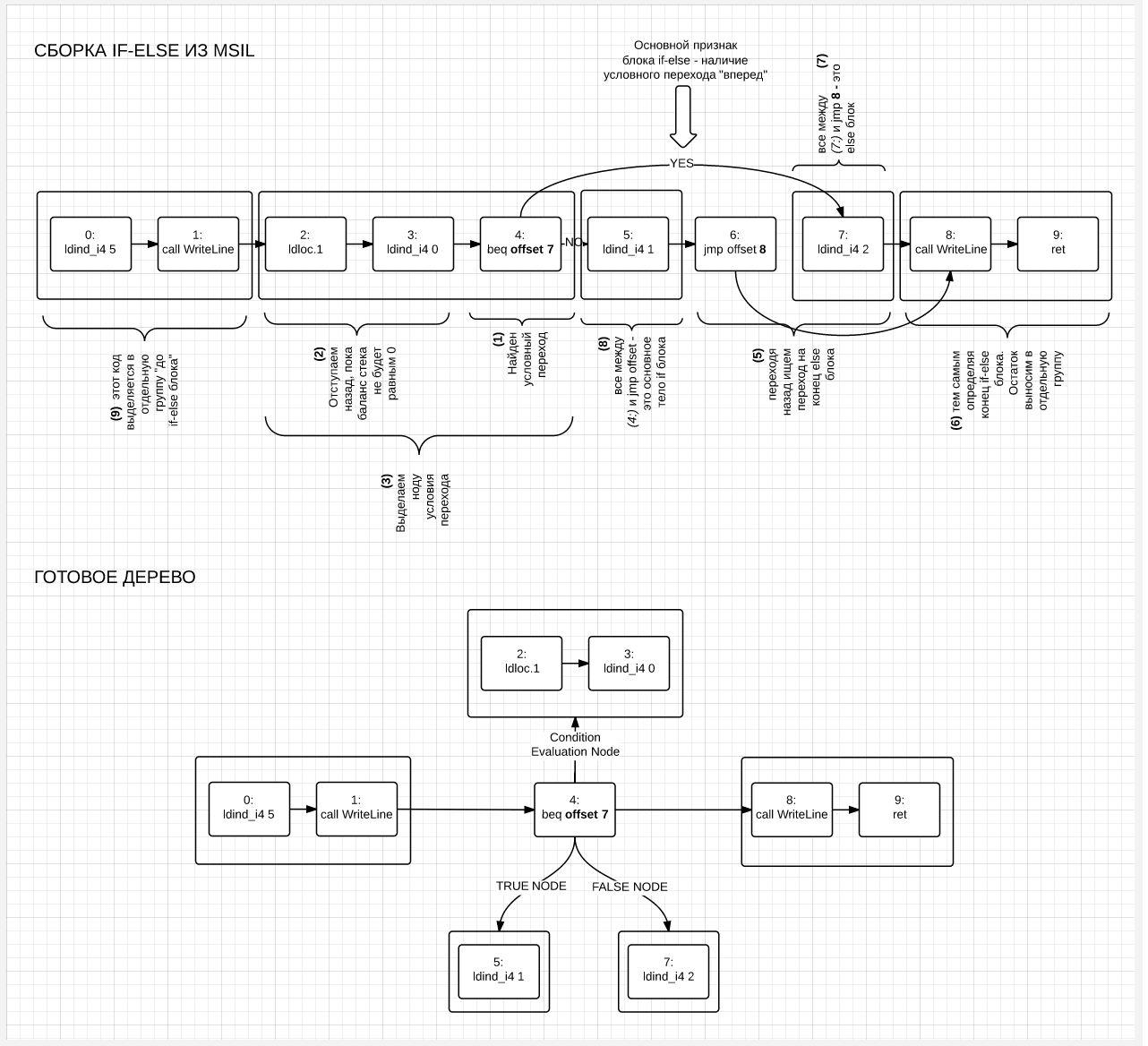
For clarity of the picture, how if-else and while / do-while are assembled, consider examples:
IF-ELSE block assembly
Build WHILE Block

Code generation
The last stage of matching is the generation of a tree code. There should not be any difficulties. Ideally, of course, it would be cool to suck in rules from R # or StyleCop. Fortunately, they are in XML. But in the simplest case, we write a generator that accepts a class description tree as an input. He must first check the entire tree: whether it contains unsupported types of nodes. If everything is in order, then the whole tree is bypassed and the corresponding method is called for each node using the Visitor design pattern, to which StringBuilder and the corresponding node are passed. Additionally, it is necessary to consider the number of spaces that must be indented from the beginning of each line. At this stage, everything is quite simple.
Variable Name Generation

Before generating the code, you need to generate the names of all the variables that were lost during the compilation process. Matching algorithms are also written for this. To generate variable names are:
- Names of methods that are not generated by the compiler, in the calculations or results of calculations of which they are used. Example: var ??? = this.Counterparty; -> ??? = counterparty.
- Data whether the variable is a loop variable. Those. Is it considered only in the body of the cycle. If it is an integer, then the candidates for the name are index, i, j.
- If the variable - in the foreach loop is an element from the iterable collection, then you can call it [collectionName] Item or just item.
To implement these and many other algorithms, matchers are used that are similar to matchmakers rearranging a tree for a specific programming language.
What's next?
Next, I will analyze specific decompilers. dotPeek dotPeek, Cecil and mine. But this is a bit later =)