Processors, cores and threads. System topology
- Tutorial
In this article, I will try to describe the terminology used to describe systems that can run several programs in parallel, that is, multi-core, multi-processor, multi-threaded. Different types of concurrency in the IA-32 CPU appeared at different times and in a somewhat inconsistent order. It’s quite easy to get confused in all this, especially considering that operating systems carefully hide details from not too sophisticated application programs.

The terminology used below is used in the documentation for Intel processors. Other architectures may have different names for similar concepts. Where I know them, I will mention them.
The purpose of the article is to show that with all the variety of possible configurations of multiprocessor, multi-core and multi-threaded systems for programs running on them, opportunities are created both for abstraction (ignoring differences) and for specificity (the ability to programmatically learn the configuration).
Of course, the oldest, most frequently used and ambiguous term is “processor”.
In the modern world, a processor is something (package) that we buy in a beautiful Retail box or a not-so-beautiful OEM bag. An indivisible entity inserted into the socket on the motherboard. Even if there is no connector and you can’t remove it, that is, if it is firmly soldered, this is one chip.

Mobile systems (phones, tablets, laptops) and most desktops have one processor. Workstations and servers can sometimes boast of two or more processors on the same motherboard.
Supporting multiple CPUs in one system requires numerous changes in its design. At a minimum, it is necessary to ensure their physical connection (provide for several sockets on the motherboard), solve processor identification issues (see later in this article, as well as my previous onenote), coordination of memory access and delivery of interrupts (the interrupt controller must be able to route interrupts to several processors) and, of course, support from the operating system. Unfortunately, I could not find a documentary mention of the creation of the first multiprocessor system on Intel processors, but Wikipedia claims that Sequent Computer Systems supplied them already in 1987 using Intel 80386 processors. Widespread support for several chips in one system becomes available starting with Intel® Pentium.
If there are several processors, then each of them has its own connector on the board. Each of them at the same time has complete independent copies of all resources, such as registers, executing devices, caches. They share a common memory - RAM. Memory can connect to them in various and rather non-trivial ways, but this is a separate story that goes beyond the scope of this article. It is important that in any situation for the executable programs the illusion of a uniform shared memory must be created, accessible from all processors included in the system.

Ready to take off! Intel® Desktop Board D5400XS
Historically, multi-core in Intel IA-32 appeared later Intel® HyperThreading, however, in the logical hierarchy, it goes next.
It would seem that if the system has more processors, then its performance is higher (on tasks that can use all resources). However, if the cost of communication between them is too high, then all the gains from concurrency are killed by long delays in transmitting common data. This is what is observed in multiprocessor systems - both physically and logically, they are very far from each other. For efficient communication in these conditions, you have to come up with specialized buses such as Intel® QuickPath Interconnect. Energy consumption, size and price of the final solution, of course, do not decrease from all this. High integration of components should come to the rescue - circuits executing parts of a parallel program should be pulled closer to each other, preferably one chip. In other words,kernels , all identical to each other, but working independently.
Intel's first IA-32 multi-core processors were introduced in 2005. Since then, the average number of cores in server, desktop, and now mobile platforms has been steadily growing.
Unlike two single-core processors in one system that share only memory, two cores can also have common caches and other resources responsible for interacting with memory. Most often, the caches of the first level remain private (each core has its own), while the second and third levels can be both general and separate. Such an organization of the system allows to reduce delays in data delivery between neighboring cores, especially if they work on a common task.
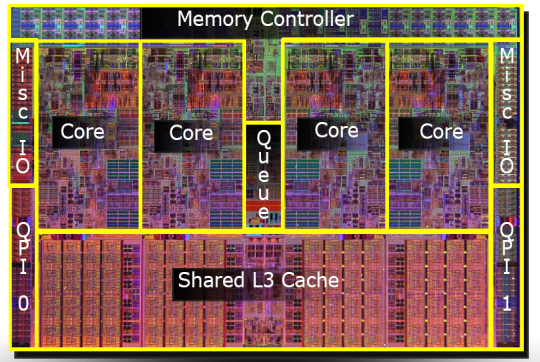
A micrograph of a four-core Intel processor codenamed Nehalem. Separate cores, a general cache of the third level, as well as QPI links to other processors and a common memory controller are allocated.
Until about 2002, the only way to get the IA-32 system, capable of simultaneously executing two or more programs, was to use multiprocessor systems. In Intel® Pentium® 4, as well as the Xeon lineup, code-named Foster (Netburst), a new technology was introduced - hyper-threads or hyper-threads - Intel® HyperThreading (hereinafter referred to as HT).
There is nothing new under the sun. HT is a special case of what is referred to in the literature as simultaneous multithreading (SMT). In contrast to the “real” kernels, which are full and independent copies, in the case of HT, only one part of the internal nodes is duplicated in one processor, primarily responsible for storing the architectural state - registers. The executive nodes responsible for organizing and processing the data remain singular, and at most one of the threads uses one of the streams. Like cores, hyperthreads share caches, but starting at what level it depends on the particular system.
I will not try to explain all the pros and cons of designs with SMT in general and with HT in particular. An interested reader can find a rather detailed discussion of technology in many sources, and, of course, on Wikipedia . However, I note the following important point explaining the current restrictions on the number of hyperthreads in real products.
In what cases is the presence of "dishonest" multicore in the form of HT justified? If one application thread is not able to load all the executing nodes inside the kernel, then they can be "borrowed" to another thread. This is typical for applications that have a bottleneck not in computing, but in accessing data, that is, often generating cache misses and having to wait for data to be delivered from memory. At this time, the kernel without HT will be forced to stand idle. The presence of HT allows you to quickly switch free executing nodes to another architectural state (because it is just duplicated) and execute its instructions. This is a special case of a technique called latency hiding, when one long operation, during which useful resources are idle, is masked by the parallel execution of other tasks. If the application already has a high degree of utilization of kernel resources,
Typical desktop and server applications designed for general-purpose machine architectures have the potential for parallelism implemented using HT. However, this potential is quickly "consumed." Perhaps for this reason, on almost all IA-32 processors, the number of hardware hyperthreads does not exceed two. In typical scenarios, the gain from using three or more hyperthreads would be small, but the loss in the size of the crystal, its energy consumption and cost is significant.
Another situation is observed in typical tasks performed on video accelerators. Therefore, these architectures are characterized by the use of SMT technology with a larger number of threads. Since Intel® Xeon Phi coprocessors (introduced in 2010) are ideologically and genealogically quite close to graphics cards, they mayfour hyperthreads on each core - a configuration unique to IA-32.
Of the three described “levels” of parallelism (processors, cores, hyperthreads), some or all of them may be absent in a particular system. This is affected by the BIOS settings (multicore and multithreading are disabled independently), microarchitecture features (for example, HT was absent in Intel® Core ™ Duo, but was returned with the Nehalem release) and system events (multiprocessor servers can turn off failed processors in case of malfunctions) and continue to "fly" on the remaining). How is this multi-level concurrency zoo visible to the operating system and, ultimately, applications?
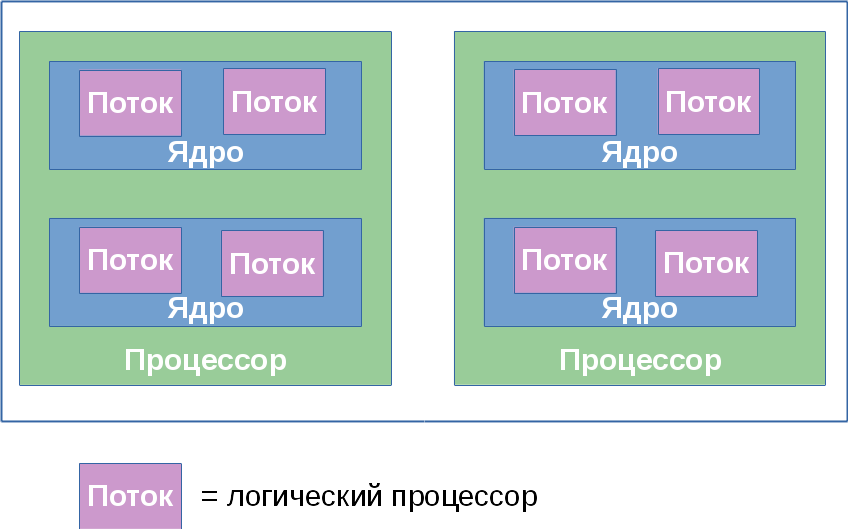
Further, for convenience, we denote the number of processors, cores, and threads in some system by the triple ( x , y , z ), wherex is the number of processors, y is the number of cores in each processor, and z is the number of hyperthreads in each core. Further, I will call this trio topology - an established term that has little to do with the section of mathematics. The product p = xyz determines the number of entities called logical processorssystem. It defines the total number of independent contexts of application processes in a shared memory system that run in parallel, which the operating system is forced to consider. I say “forced” because it cannot control the execution order of two processes located on different logical processors. This also applies to hyperthreads: although they work “sequentially” on one core, the specific order is dictated by the hardware and is not available for monitoring or controlling programs.
Most often, the operating system hides from the final applications the features of the physical topology of the system on which it is running. For example, the following three topologies: (2, 1, 1), (1, 2, 1) and (1, 1, 2) - the OS will present in the form of two logical processors, although the first of them has two processors, the second - two nuclei, and the third - only two threads.
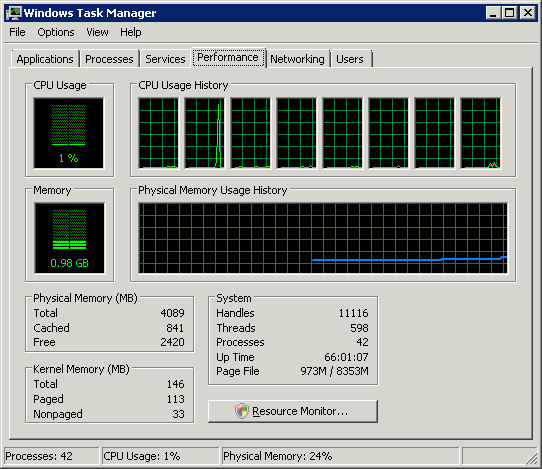
Windows Task Manager features 8 logical processors; but how much is it in processors, cores and hyperthreads?
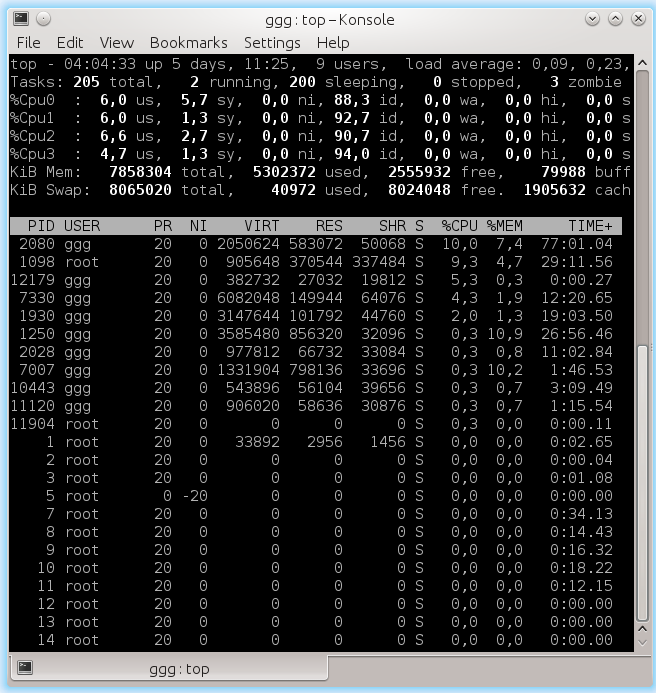
Linux
This is quite convenient for application developers - they don’t have to deal with hardware features that are often insignificant for them.
Of course, abstraction of topology into a single number of logical processors in some cases creates enough grounds for confusion and misunderstanding (in hot Internet disputes). Computing applications that want to squeeze maximum performance out of iron require detailed control over where their threads will be placed: closer to each other on adjacent hyperthreads or vice versa, further away on different processors. The speed of communication between logical processors within a single core or processor is significantly higher than the speed of data transfer between processors. The possibility of heterogeneity in the organization of random access memory also complicates the picture.
Information about the topology of the system as a whole, as well as the position of each logical processor in the IA-32, is available using the CPUID instruction. Since the advent of the first multiprocessor systems, the identification scheme of logical processors has expanded several times. To date, parts of it are contained in sheets 1, 4, and 11 of the CPUID. Which of the sheets should be looked at can be determined from the following block diagram taken from the article [2]:
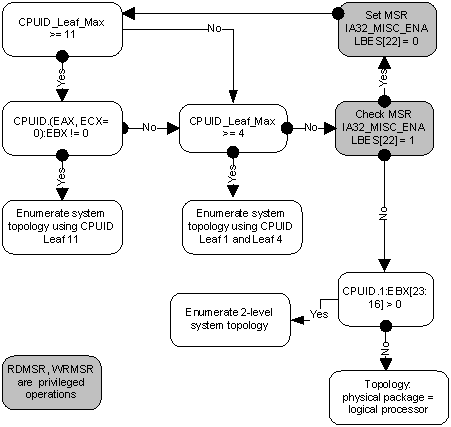
I will not bore here with all the details of the individual parts of this algorithm. If interest arises, the next part of this article can be devoted to this. I will send an interested reader to [2], in which this question is dealt with in as much detail as possible. Here, I first briefly describe what APIC is and how it relates to topology. Then we will consider working with sheet 0xB (eleven in decimal), which at the moment is the last word in “apical engineering”.
Local APIC (advanced programmable interrupt controller) is a device (now part of the processor) that is responsible for working with interrupts that come to a particular logical processor. Each logical processor has its own APIC. And each of them in the system must have a unique APIC ID value. This number is used by interrupt controllers for addressing when messages are delivered, and by all others (for example, the operating system) to identify logical processors. The specification for this interrupt controller evolved from Intel 8259 PIC through Dual PIC, APIC and xAPIC to x2APIC .
Currently, the width of the number stored in the APIC ID has reached the full 32 bits, although in the past it was limited to 16, and even earlier - only 8 bits. Today, the remnants of old days are scattered throughout the CPUID, however, all 32 bits of the APIC ID are returned in CPUID.0xB.EDX [31: 0]. On each logical processor that independently executes the CPUID instruction, its value will be returned.
The APIC ID value alone does not say anything about the topology. To find out which two logical processors are inside the same physical (that is, they are “brothers” of hypertreads), which two are inside the same processor, and which are completely different processors, you need to compare their APIC ID values. Depending on the degree of affinity, some of their bits will match. This information is contained in the CPUID.0xB sublist, which is encoded using an operand in ECX. Each of them describes the position of the bit field of one of the topology levels in EAX [5: 0] (more precisely, the number of bits that need to be shifted to the right in the APIC ID to remove the lower levels of the topology), as well as the type of this level - hyperthread, core or processor , - in ECX [15: 8].
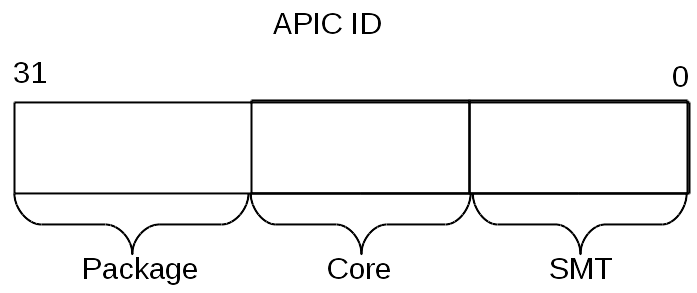
Logical processors located within the same core will have all the same bits of the APIC ID, except those belonging to the SMT field. For logical processors located in one processor, all bits except the Core and SMT fields. Since the number of sub-sheets for CPUID.0xB can increase, this scheme will allow supporting the description of topologies with a higher number of levels if necessary in the future. Moreover, it will be possible to introduce intermediate levels between existing ones.
An important consequence of the organization of this scheme is that there can be “holes” in the set of all APIC IDs of all logical processors of the system, i.e. they will not go sequentially. For example, in a multi-core processor with HT turned off, all APIC IDs may turn out to be even, since the least significant bit responsible for encoding the hyper-thread number will always be zero.
I note that CPUID.0xB is not the only source of information about logical processors available to the operating system. The list of all processors available to her, together with their APIC ID values, is encoded in the MADT ACPI table [3, 4].
Operating systems provide logical processor topology information to applications using their own interfaces.
On Linux, topology information is contained in the pseudo-file
In FreeBSD, the topology is reported through the sysctl mechanism in the kern.sched.topology_spec variable as XML:
In MS Windows 8, topology information can be seen in the Task Manager.
They are also provided by the console utility Sysinternals Coreinfo and the API call GetLogicalProcessorInformation .
I will illustrate once again the relationship between the concepts of “processor”, “core”, “hyper-thread” and “logical processor” with a few examples.


In this section I have taken out some oddities that arise due to the multi-level organization of logical processors.
As I already mentioned, caches in the processor also form a hierarchy, and it is pretty much connected with the topology of the cores, but it is not determined unambiguously. To determine which caches for which logical processors are common and which are not, the output of CPUID.4 and its sublist is used.
Some software products are delivered by the number of licenses determined by the number of processors in the system on which they will be used. Others - by the number of cores in the system. Finally, to determine the number of licenses, the number of processors can be multiplied by a fractional “core factor”, depending on the type of processor!
Virtualization systems capable of simulating multicore systems can assign arbitrary topology to virtual processors inside a machine that does not match the configuration of real hardware. So, inside the host system (1, 2, 2), some well-known virtualization systems by default take all logical processors to the upper level, i.e. create a configuration (4, 1, 1). Combined with topology-specific licensing features, this can produce fun effects.
Thanks for attention!
The terminology used below is used in the documentation for Intel processors. Other architectures may have different names for similar concepts. Where I know them, I will mention them.
The purpose of the article is to show that with all the variety of possible configurations of multiprocessor, multi-core and multi-threaded systems for programs running on them, opportunities are created both for abstraction (ignoring differences) and for specificity (the ability to programmatically learn the configuration).
Warning of signs ®, ™, © in the article
My commentary explains why company employees should use copyright marks in public communications. In this article, they had to be used quite often.
CPU
Of course, the oldest, most frequently used and ambiguous term is “processor”.
In the modern world, a processor is something (package) that we buy in a beautiful Retail box or a not-so-beautiful OEM bag. An indivisible entity inserted into the socket on the motherboard. Even if there is no connector and you can’t remove it, that is, if it is firmly soldered, this is one chip.
Mobile systems (phones, tablets, laptops) and most desktops have one processor. Workstations and servers can sometimes boast of two or more processors on the same motherboard.
Supporting multiple CPUs in one system requires numerous changes in its design. At a minimum, it is necessary to ensure their physical connection (provide for several sockets on the motherboard), solve processor identification issues (see later in this article, as well as my previous onenote), coordination of memory access and delivery of interrupts (the interrupt controller must be able to route interrupts to several processors) and, of course, support from the operating system. Unfortunately, I could not find a documentary mention of the creation of the first multiprocessor system on Intel processors, but Wikipedia claims that Sequent Computer Systems supplied them already in 1987 using Intel 80386 processors. Widespread support for several chips in one system becomes available starting with Intel® Pentium.
If there are several processors, then each of them has its own connector on the board. Each of them at the same time has complete independent copies of all resources, such as registers, executing devices, caches. They share a common memory - RAM. Memory can connect to them in various and rather non-trivial ways, but this is a separate story that goes beyond the scope of this article. It is important that in any situation for the executable programs the illusion of a uniform shared memory must be created, accessible from all processors included in the system.
Ready to take off! Intel® Desktop Board D5400XS
Core
Historically, multi-core in Intel IA-32 appeared later Intel® HyperThreading, however, in the logical hierarchy, it goes next.
It would seem that if the system has more processors, then its performance is higher (on tasks that can use all resources). However, if the cost of communication between them is too high, then all the gains from concurrency are killed by long delays in transmitting common data. This is what is observed in multiprocessor systems - both physically and logically, they are very far from each other. For efficient communication in these conditions, you have to come up with specialized buses such as Intel® QuickPath Interconnect. Energy consumption, size and price of the final solution, of course, do not decrease from all this. High integration of components should come to the rescue - circuits executing parts of a parallel program should be pulled closer to each other, preferably one chip. In other words,kernels , all identical to each other, but working independently.
Intel's first IA-32 multi-core processors were introduced in 2005. Since then, the average number of cores in server, desktop, and now mobile platforms has been steadily growing.
Unlike two single-core processors in one system that share only memory, two cores can also have common caches and other resources responsible for interacting with memory. Most often, the caches of the first level remain private (each core has its own), while the second and third levels can be both general and separate. Such an organization of the system allows to reduce delays in data delivery between neighboring cores, especially if they work on a common task.
A micrograph of a four-core Intel processor codenamed Nehalem. Separate cores, a general cache of the third level, as well as QPI links to other processors and a common memory controller are allocated.
Hyperthread
Until about 2002, the only way to get the IA-32 system, capable of simultaneously executing two or more programs, was to use multiprocessor systems. In Intel® Pentium® 4, as well as the Xeon lineup, code-named Foster (Netburst), a new technology was introduced - hyper-threads or hyper-threads - Intel® HyperThreading (hereinafter referred to as HT).
There is nothing new under the sun. HT is a special case of what is referred to in the literature as simultaneous multithreading (SMT). In contrast to the “real” kernels, which are full and independent copies, in the case of HT, only one part of the internal nodes is duplicated in one processor, primarily responsible for storing the architectural state - registers. The executive nodes responsible for organizing and processing the data remain singular, and at most one of the threads uses one of the streams. Like cores, hyperthreads share caches, but starting at what level it depends on the particular system.
I will not try to explain all the pros and cons of designs with SMT in general and with HT in particular. An interested reader can find a rather detailed discussion of technology in many sources, and, of course, on Wikipedia . However, I note the following important point explaining the current restrictions on the number of hyperthreads in real products.
Thread limits
In what cases is the presence of "dishonest" multicore in the form of HT justified? If one application thread is not able to load all the executing nodes inside the kernel, then they can be "borrowed" to another thread. This is typical for applications that have a bottleneck not in computing, but in accessing data, that is, often generating cache misses and having to wait for data to be delivered from memory. At this time, the kernel without HT will be forced to stand idle. The presence of HT allows you to quickly switch free executing nodes to another architectural state (because it is just duplicated) and execute its instructions. This is a special case of a technique called latency hiding, when one long operation, during which useful resources are idle, is masked by the parallel execution of other tasks. If the application already has a high degree of utilization of kernel resources,
Typical desktop and server applications designed for general-purpose machine architectures have the potential for parallelism implemented using HT. However, this potential is quickly "consumed." Perhaps for this reason, on almost all IA-32 processors, the number of hardware hyperthreads does not exceed two. In typical scenarios, the gain from using three or more hyperthreads would be small, but the loss in the size of the crystal, its energy consumption and cost is significant.
Another situation is observed in typical tasks performed on video accelerators. Therefore, these architectures are characterized by the use of SMT technology with a larger number of threads. Since Intel® Xeon Phi coprocessors (introduced in 2010) are ideologically and genealogically quite close to graphics cards, they mayfour hyperthreads on each core - a configuration unique to IA-32.
Logical processor
Of the three described “levels” of parallelism (processors, cores, hyperthreads), some or all of them may be absent in a particular system. This is affected by the BIOS settings (multicore and multithreading are disabled independently), microarchitecture features (for example, HT was absent in Intel® Core ™ Duo, but was returned with the Nehalem release) and system events (multiprocessor servers can turn off failed processors in case of malfunctions) and continue to "fly" on the remaining). How is this multi-level concurrency zoo visible to the operating system and, ultimately, applications?
Further, for convenience, we denote the number of processors, cores, and threads in some system by the triple ( x , y , z ), wherex is the number of processors, y is the number of cores in each processor, and z is the number of hyperthreads in each core. Further, I will call this trio topology - an established term that has little to do with the section of mathematics. The product p = xyz determines the number of entities called logical processorssystem. It defines the total number of independent contexts of application processes in a shared memory system that run in parallel, which the operating system is forced to consider. I say “forced” because it cannot control the execution order of two processes located on different logical processors. This also applies to hyperthreads: although they work “sequentially” on one core, the specific order is dictated by the hardware and is not available for monitoring or controlling programs.
Most often, the operating system hides from the final applications the features of the physical topology of the system on which it is running. For example, the following three topologies: (2, 1, 1), (1, 2, 1) and (1, 1, 2) - the OS will present in the form of two logical processors, although the first of them has two processors, the second - two nuclei, and the third - only two threads.
Windows Task Manager features 8 logical processors; but how much is it in processors, cores and hyperthreads?
Linux
topfeatures 4 logical processors. This is quite convenient for application developers - they don’t have to deal with hardware features that are often insignificant for them.
Software Topology Definition
Of course, abstraction of topology into a single number of logical processors in some cases creates enough grounds for confusion and misunderstanding (in hot Internet disputes). Computing applications that want to squeeze maximum performance out of iron require detailed control over where their threads will be placed: closer to each other on adjacent hyperthreads or vice versa, further away on different processors. The speed of communication between logical processors within a single core or processor is significantly higher than the speed of data transfer between processors. The possibility of heterogeneity in the organization of random access memory also complicates the picture.
Information about the topology of the system as a whole, as well as the position of each logical processor in the IA-32, is available using the CPUID instruction. Since the advent of the first multiprocessor systems, the identification scheme of logical processors has expanded several times. To date, parts of it are contained in sheets 1, 4, and 11 of the CPUID. Which of the sheets should be looked at can be determined from the following block diagram taken from the article [2]:
I will not bore here with all the details of the individual parts of this algorithm. If interest arises, the next part of this article can be devoted to this. I will send an interested reader to [2], in which this question is dealt with in as much detail as possible. Here, I first briefly describe what APIC is and how it relates to topology. Then we will consider working with sheet 0xB (eleven in decimal), which at the moment is the last word in “apical engineering”.
APIC ID
Local APIC (advanced programmable interrupt controller) is a device (now part of the processor) that is responsible for working with interrupts that come to a particular logical processor. Each logical processor has its own APIC. And each of them in the system must have a unique APIC ID value. This number is used by interrupt controllers for addressing when messages are delivered, and by all others (for example, the operating system) to identify logical processors. The specification for this interrupt controller evolved from Intel 8259 PIC through Dual PIC, APIC and xAPIC to x2APIC .
Currently, the width of the number stored in the APIC ID has reached the full 32 bits, although in the past it was limited to 16, and even earlier - only 8 bits. Today, the remnants of old days are scattered throughout the CPUID, however, all 32 bits of the APIC ID are returned in CPUID.0xB.EDX [31: 0]. On each logical processor that independently executes the CPUID instruction, its value will be returned.
Clarification of relationship
The APIC ID value alone does not say anything about the topology. To find out which two logical processors are inside the same physical (that is, they are “brothers” of hypertreads), which two are inside the same processor, and which are completely different processors, you need to compare their APIC ID values. Depending on the degree of affinity, some of their bits will match. This information is contained in the CPUID.0xB sublist, which is encoded using an operand in ECX. Each of them describes the position of the bit field of one of the topology levels in EAX [5: 0] (more precisely, the number of bits that need to be shifted to the right in the APIC ID to remove the lower levels of the topology), as well as the type of this level - hyperthread, core or processor , - in ECX [15: 8].
Logical processors located within the same core will have all the same bits of the APIC ID, except those belonging to the SMT field. For logical processors located in one processor, all bits except the Core and SMT fields. Since the number of sub-sheets for CPUID.0xB can increase, this scheme will allow supporting the description of topologies with a higher number of levels if necessary in the future. Moreover, it will be possible to introduce intermediate levels between existing ones.
An important consequence of the organization of this scheme is that there can be “holes” in the set of all APIC IDs of all logical processors of the system, i.e. they will not go sequentially. For example, in a multi-core processor with HT turned off, all APIC IDs may turn out to be even, since the least significant bit responsible for encoding the hyper-thread number will always be zero.
I note that CPUID.0xB is not the only source of information about logical processors available to the operating system. The list of all processors available to her, together with their APIC ID values, is encoded in the MADT ACPI table [3, 4].
Operating Systems and Topology
Operating systems provide logical processor topology information to applications using their own interfaces.
On Linux, topology information is contained in the pseudo-file
/proc/cpuinfo, as well as the output of the command dmidecode. In the example below, I filter the contents of cpuinfo on some quad-core system without HT, leaving only topological entries:Hidden text
ggg@shadowbox:~$ cat /proc/cpuinfo |grep 'processor\|physical\ id\|siblings\|core\|cores\|apicid'
processor : 0
physical id : 0
siblings : 4
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
processor : 1
physical id : 0
siblings : 4
core id : 0
cpu cores : 2
apicid : 1
initial apicid : 1
processor : 2
physical id : 0
siblings : 4
core id : 1
cpu cores : 2
apicid : 2
initial apicid : 2
processor : 3
physical id : 0
siblings : 4
core id : 1
cpu cores : 2
apicid : 3
initial apicid : 3
In FreeBSD, the topology is reported through the sysctl mechanism in the kern.sched.topology_spec variable as XML:
Hidden text
user@host:~$ sysctl kern.sched.topology_spec
kern.sched.topology_spec: 0, 1, 2, 3, 4, 5, 6, 7 0, 1, 2, 3, 4, 5, 6, 7 0, 1 THREAD group SMT group 2, 3 THREAD group SMT group 4, 5 THREAD group SMT group 6, 7 THREAD group SMT group In MS Windows 8, topology information can be seen in the Task Manager.
Hidden text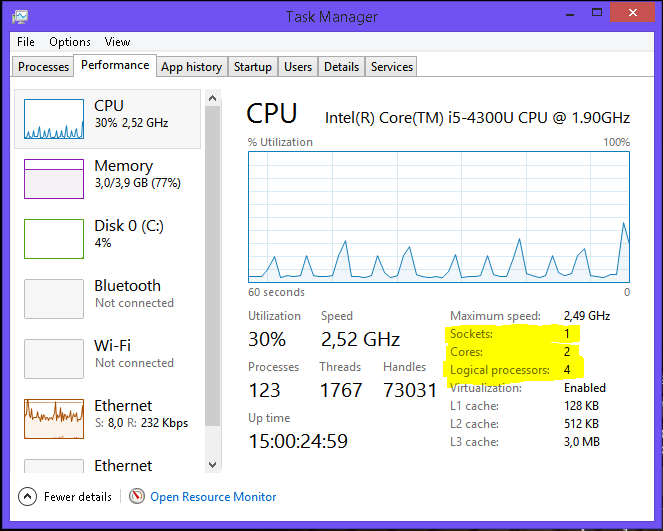
They are also provided by the console utility Sysinternals Coreinfo and the API call GetLogicalProcessorInformation .
Full picture
I will illustrate once again the relationship between the concepts of “processor”, “core”, “hyper-thread” and “logical processor” with a few examples.
System (2, 2, 2)
System (2, 4, 1)
System (4, 1, 1)
Other matters
In this section I have taken out some oddities that arise due to the multi-level organization of logical processors.
Caches
As I already mentioned, caches in the processor also form a hierarchy, and it is pretty much connected with the topology of the cores, but it is not determined unambiguously. To determine which caches for which logical processors are common and which are not, the output of CPUID.4 and its sublist is used.
Licensing
Some software products are delivered by the number of licenses determined by the number of processors in the system on which they will be used. Others - by the number of cores in the system. Finally, to determine the number of licenses, the number of processors can be multiplied by a fractional “core factor”, depending on the type of processor!
Virtualization
Virtualization systems capable of simulating multicore systems can assign arbitrary topology to virtual processors inside a machine that does not match the configuration of real hardware. So, inside the host system (1, 2, 2), some well-known virtualization systems by default take all logical processors to the upper level, i.e. create a configuration (4, 1, 1). Combined with topology-specific licensing features, this can produce fun effects.
Thanks for attention!
Literature
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer's Manual. Volumes 1-3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Shih Kuo. Intel® 64 Architecture Processor Topology Enumeration, 2012 - software.intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration
- OSDevWiki. MADT. wiki.osdev.org/MADT
- OSDevWiki. Detecting CPU Topology. wiki.osdev.org/Detecting_CPU_Topology_%2880x86%29