AI party in Silicon Valley: mayor, billionaire, presidents, geniuses, processor developers and a girl with bright hair
Last year, a wave of articles about parties in Silicon Valley was held in the Russian and Ukrainian press, with some kind of Hollywood atmosphere, but without specifying specific names, photographs, and without describing the technologies for developing hardware and writing software related to these names. This article is different! In it, too, will be billionaires, geniuses and girls, but with photos, slides, diagrams, and fragments of program code. So:
Recently, the mayor of the city of Campbell, with the Russian surname Paul Resnikoff, cut the ribbon when opening a new office for the startup Wave Computing, which, together with Broadcom, is developing a 7-nm chip to speed up the computation of neural networks. The office is located in the building of the historic fruit canning factory of the late 19th and early 20th centuries, when Silicon Valley was the largest orchard in the world. Even then, in the office, they were engaged in innovations, introducing electric motors for conveyors in the apricot-plum industry, for which about 200 employees, mostly women, worked.
On the party following the cutting of the ribbon, many well-known people in the industry appeared, in particular, Kernighan-Richie's associate and author of the most popular C compiler of the late 70s - early 80s, Stephen Johnson, one of the authors of the floating-point standard Jerome Cunen, inventor local bus concepts and chipset developer of the first PC AT Diosdado Banatao, former developers of Sun, DEC, Cyrix, Intel, AMD and Silicon Graphics processors, Qualcomm, Xilinx and Cypress chips, industrial analysts, a girl with red hair and other Californian co-workers This type of company.
At the end of the post we will talk about what books you need to read and do some exercises to join this community.
Let's start with Jerome Coonen, the innovator of floating point arithmetic and the Apple manager at the time of the first Macintosh.
Not so often there are master's theses that affect computing on billions of devices. This was the disserver Jeromei Kunen (left) "Contributions for a Floating Point Arithmetic", the results of which were included in IEEE Standard 754 floating-point numbers. After graduating from Berkeley Graduate School in 1982, Jerome went to work for Apple, where he introduced floating point libraries to the first Macintosh.
After 10 years of management at Apple, Kunen advised Hewlett-Packard and Microsoft, and in 2000 he optimized 128-bit arithmetic for AMD's only 64-bit version of x86. Recently, Jeromy turned his attention to research on floating-point standards for neural networks, in particular, disputes about Unum and Posit. Unum is the new proposed standard, promoted by the Caltech scholar John Gustafson, the author of The End of Error, the now noisy book, End of Error. Posit is a version of Unum that can be more effectively (*) than Unum implemented in hardware.
(*) More effective in terms of a combination of parameters: clock frequency, number of cycles per operation, conveyor throughput, relative area on a chip, and relative power consumption.

Images from the articles (not from Jerome) Making it and
making it easy to use it at its Own Game: Posit Arithmetic by John L. Gustafson and Isaac Yonemoto :

But for the party Stephen / Steve Johnson is the person on the compiler whose C programming language has become popular. The first C compiler was written by Denis Ritchie, but the Richie compiler was tightly tied to the PDP-11 architecture. Steve Johnson, based on the work of Alan Snyder, wrote in the mid-1970s the Portable C Compiler (PCC) compiler, which was easy to remake to generate code for different architectures. At the same time, the Johnson compiler worked quickly and was optimizing. How did he achieve this?
At the PCC input, Steve Johnson used the LALR (1) parser generated by the YACC (Yet Another Compiler Compiler) program, which was also written by Steve Johnson. After this, the compilation task was reduced to manipulating trees in recursive functions and generating code using the template table. Some of these recursive functions were machine-independent, the other part was copied by people who transferred PCC to another machine. The template table consisted of rule entries of the type “if the register is of type A and two of the register of type B, rebuild the tree into a node of type C and generate a code with the string D”. The table was machine dependent.
Due to the combination of elegance, flexibility and efficiency, the PCC compiler was transferred to more than 200 architectures - from PDP, VAX, IBM / 370, x86 to the Soviet BESM-6 and Orbit 20-700 (onboard computer in early versions of the MiG-29). According to Denis Ritchie, almost every C compiler of the early 1980s was based on PCC. From the BSD Unix world, the PCC was supplanted as the standard-only GNU GCC compiler in 1994.
In addition to PCC and Yacc, Steve Johnson is also the author of the original Lint program verification program (see eg 1978 article). The names of the programs Yacc and Lint have since become a household name. In the 2000s, Steve rewrote the MATLAB front-end and wrote MLint. Now Steve Johnson is busy with the task of parallelizing the algorithms for computing neural networks on devices like CGRA (Coarse-Grained Reconfigurable Architecture), with tens of thousands of processor elements, which are thrown between tensors through a network of tens of thousands of transistors too:

But with a glass of wine billionaire Diosdado Banatao, the founder of Chips & Technologies, S3 Graphics and an investor in Marvell. If you programmed the IBM PC in 1985-1988, when they first appeared in the USSR, then you may know that inside most of the AT-NIS with EGA and VGA graphics, there were chipsets from Chips & Technologies, which came out simultaneously with IBM-ovsky. Early C & T chipsets were designed by Banatao, who studied electronics at Stanford, and before Stanford worked as an engineer in Boeing. In 1987, Chips & Technologies bought Intel.


On the left in the picture below is John Bourgoin, President of MIPS Technologies at the time of this company's heyday in the 2000s, when chips with MIPS cores were inside most DVD players, digital cameras and TVs, with chipsets from Zoran, Sigma Design, Realtek, Broadcom and other companies. Prior to that, John was president of MIPS Silicon Graphics since 1996 when MIPS processors stood inside Silicon Graphics workstations, which were used in Hollywood to shoot the first realistic 3D Jurassic Park films. Prior to Silicon Graphics, John was one of the vice presidents of AMD, since 1976.
Art Swift, right, was the MIPS vice president of marketing in the 2000s, and before that in the 1980s he worked as an engineer at Fairchild Semiconductor (yes, that one), then as vice president of marketing at Sun, DEC, Cirrus Logic, and President of the company Transmet. Recently, Art was vice-chairman of the marketing committee of RISC-V and is familiar with Russian companies Syntacore and CloudBear in this position. And now he has become president of Wave's MIPS IP direction:

Slides from a MIPS history presentation related to the period when MIPS was managed by John Bourgoin, in the above left image:

The company Transmet, whose president was Art Swift for a while, in the photo above to the right, released the Crusoe processor in the late 1990s, which could carry out x86 instructions and reached the market in Toshiba Libretto L sub-laptops, NEC and Sharp laptops , the thin client from Compaq. Their competitive advantage over Intel and AMD was put to controlled low power consumption.
Direct implementation and verification of the full set of x86 is a very expensive event, so Transmet went the other way, which resembles the path of the Russian company MCST with the Elbrus processor (the line that began with Elbrus 2000 and is now represented as Elbrus 8C). Transmet and Elbrus were set up as a basis for a structurally simple processor with a VLIW microarchitecture, and on top of it worked the x86 emulation level using the technology that Transmeta called code morphing.
The idea of VLIW (Very Long Instruction Word - Very Long Word Instructions) is quite simple - several processor instructions are explicitly declared by one superinstruction and are executed in parallel. Unlike superscalar processors, in particular Intels, starting with PentiumPro (1996), in which the processor selects several instructions from memory, and then decides what to execute in parallel and what is sequential, based on automatic analysis of dependencies between instructions.
A superscalar processor is much more complicated than a VLIW, because a superscalar has to spend logic on maintaining the illusion of the programmer that all the selected instructions are executed one after another, although there are actually dozens of them inside the processor at different stages of execution. In the case of VLIW, the burden of maintaining such an illusion falls on the compiler from a high-level language. Ultimately, the VLIW circuit breaks down when the processor has to work with multi-level cache memory, which has unpredictable delays, which make it difficult for the compiler to schedule tick instructions. But for mathematical calculations (for example, to put Elbrus on the radar and to calculate the movement of the target) this is the most, especially in the conditions of a shortage of qualified engineering personnel (more people are needed to verify the superscalar).
Illustration of the VLIW idea, the Crusoe processor and the Toshiba Libretto L1 sub-nout:

But in the center in the photo below, Derek Meyer, Derek Meyer, the current CEO of Wave Computing. Prior to Wave, Derek was the CEO of ARC, the developer of ARC processor cores, which are used in audio chips. At one time, these cores were licensed by the Russian company NIIMA Progress , which later licensed the MIPS cores and showed the chips based on them at the exhibition in Kazan Innopolis . Derek Meyer repeatedly traveled to Russia, to St. Petersburg, where the Virage Logic development team was located. In 2009, ARC bought Virage Logic, and in 2010, ARC was swallowed up by Synopsys, the main chip design manufacturer in the world.
Right on the photo -Sergei Vakulenko , who at the dawn of his career stood at the origins of the Runet, worked in the cooperative Demos and the Kurchatov Institute, which brought the Internet to the USSR. Now Sergey is writing a cycle-accurate model of the Wave processor element for computing neural networks, and earlier he wrote instruction-accurate models of MIPS cores that were used to verify MIPS processor cores I6400 Samurai, Shaolin I7200 and others.

Here is Vadim Antonov and Sergei Vakulenko in 1990, with the first computer in the USSR connected to the Internet:

But on the right is Larry Hudepohl (Hudepol is written in Russian?). Larry began his career at Digital Equipment Corporation (DEC) as a processor designer for MicroVAX. Then Larry worked in a small company Cyrix, which in the late 1980s defied Intel and made an FPU co-processor that was compatible with Intel 80387 and was 50% faster than it. Then Larry designed the MIPS chips in Silicon Graphics. When MIPS Technologies separated from Silicon Graphics, Larry and Ryan Kinter together started the first independent MIPS product - MIPS 4K, which became the basis of the line that dominates the 2000s home electronics (DVD players, cameras, digital TVs). Then MIPS 5K flew into space - it was used by the Japanese space agency JAXA. Then Larry in the position of VP Hardware Engineering led the development of the following lines,

The Japanese spacecraft with the proud name of Hayabusa-2 (Sapsan-2), which landed on the surface of Ryugu asteroid last year , is controlled by an HR5000 processor based on the MIPS 5Kf processor core licensed by MIPS Technologies for a long time.
Here is a simple serial pipeline of the 64-bit processor core MIPS 5Kf from its datasheet :

Darren Jones, Darren Jones, on the right. He was the director of hardware engineering at MIPS in charge of the development of complex cores, with hardware multithreading, and superscalars with the extraordinary execution of instructions. Then Darren went to Xilinx, where he studied Xilinx Zynq - chips, which are based on a combination of FPGAs and ARM processors. Darren has now become vice president of engineering at Wave.
At MIPS, Darren was the leader of the group, whose members then went to work for Apple and Samsung. Designer Monica, who went to Samsung, once told me a phrase that I remembered well: “RTL design: development of equipment at the level of register transmissions: a few simple principles, everything else is muhlezh”) A canonical example of a cache is a cache (the program recorded data and read it, but it will only be remembered sometime later), but this is only a very special case of what Monica was able to do.

Hardware multithreading and an extraordinary superscalar are two different approaches to improving processor performance. Hardware multithreading allows you to increase throughput without much power consumption, but with non-trivial programming. The superscalar allows you to perform single-threaded programs roughly twice as fast, but it also spends twice as many watts. But without programming tricks.
Hardware multithreading is finally well explained in the Russian Wikipedia, here is its temporary multithreading (it is implemented in MIPS interAptiv and MIPS I7200 Shaolin), but simultaneous multithreading (it was done in the 1990s in DEC Alpha processors, then in SPARC, and then in MIPS I6400 Samurai / I6500 Daimyo).
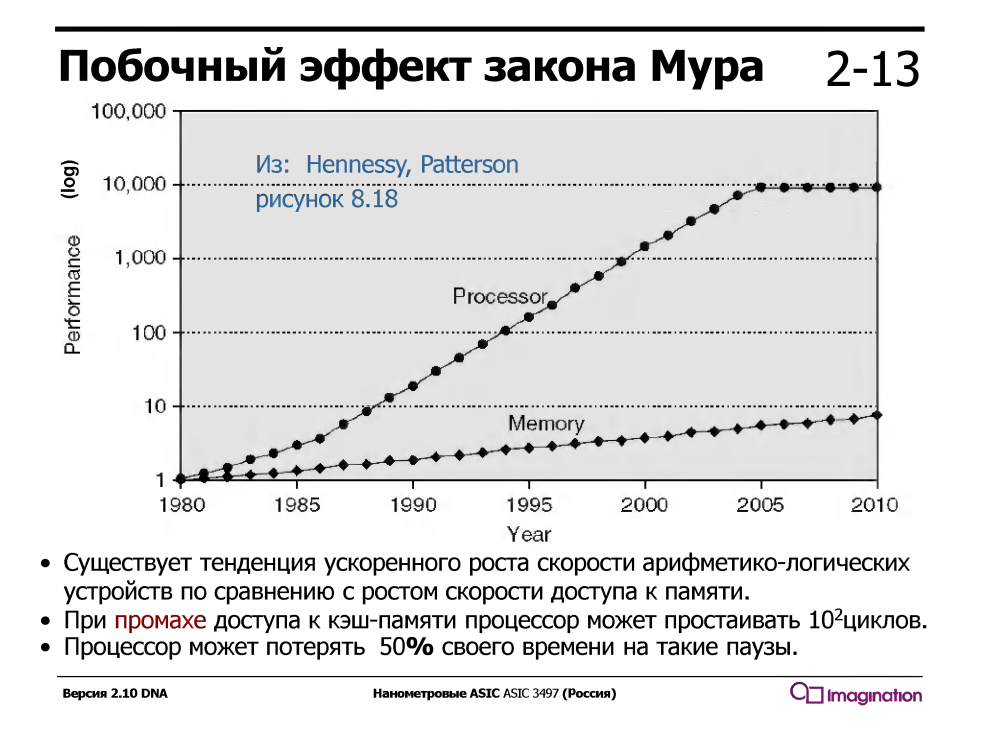
Temporary multithreading exploits the fact that a processor with a regular serial pipeline half the execution time is idle / waiting. What is he waiting for? Data that goes through caches from memory. And it waits a long time - during the waiting time for one cache miss, the processor could execute dozens or even a hundred or two simple arithmetic instructions such as addition.
This was not always the case - in the 1960s, arithmetic devices were much slower than memory. But since about 1980, the speed of processor cores has grown much faster than memory speed, and even the appearance of multi-level caches on processors solved the problem only partially.
Processors with temporal multithreading support several sets of registers, one for each thread, and when the current thread waits for data from the memory during a cache slip, the processor switches to another thread. This happens instantly, in a cycle, without interruptions, and thousands of cycles of the interrupt handler, which is enabled with software (not hardware) multithreading.
Here's the idea of multithreading on slides from the seminars of Charles Danchek , a teacher from the University of California Santa Cruz, Silicon Valley Extension. Why in Russian? Because Charles Danchek gave lectures in Moscow MISiS, then in St. Petersburg ITMO and in Kiev KPI:


Interestingly, it is possible to program in a hardware-multithreaded way just in C. Here's what it looks like:
Here is a Wave device for data centers on the side of the party. It does not work yet, although the chips are available to some customers as part of a beta program:

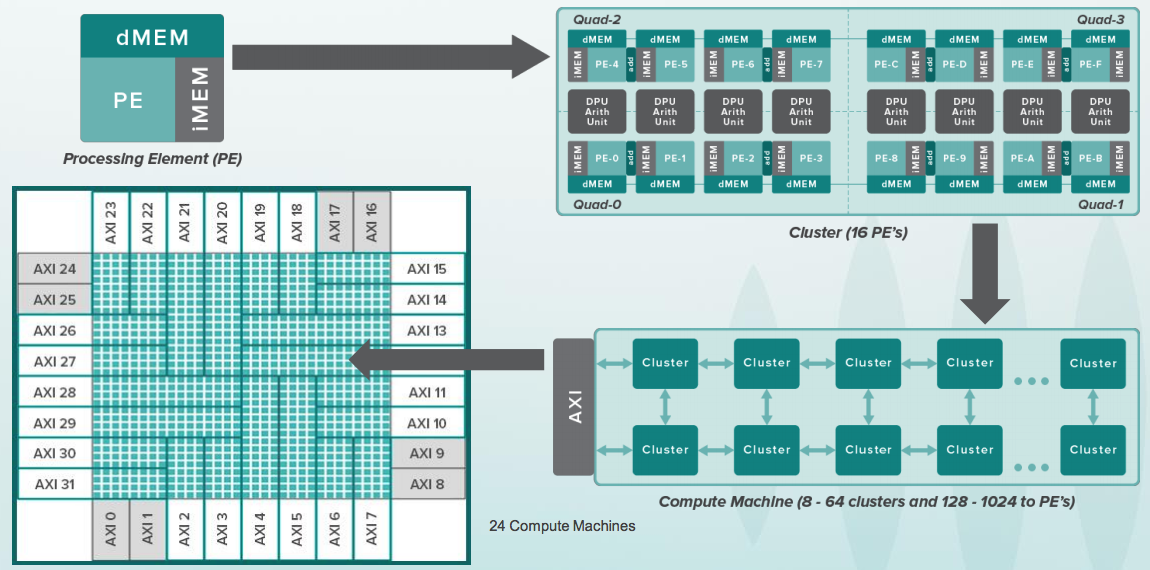
What does this device do? Can you program on Python? Here on Python, you can build the so-called Data Flow Graph (DFG) calls to the TensorFlow library. Neural networks are essentially specialized graphs like these, with matrix operations. In the Wave software group, part of which Steve Johnson manages, there is a compiler with a subset of the representation of Google’s TensorFlow in the configuration files for the chips of this device. After configuration, it can make calculations of such graphs very quickly. The device is intended for data centers, but the same principle can be applied to small chips, even inside mobile devices, for example, for face recognition:

Chijioke Anyanwu (left) - has been the custodian of the entire MIPS processor core testing system for many years. Baldwyn Chieh (center) is the designer of a new generation of processor-like elements in Wave. Baldwin used to be a senior designer at Qualcomm. Here are slides about the Wave device from the HotChips conference :


Each nanometer- wide digital innovative AI company in Silicon Valley must have its own girl with bright hair. Here is a girl in Wave. Her name is Athena, she is a sociologist by training, and works in the office as an office:

But what an office looks like from the outside, and its more than a century of history from the time when it was an innovative canning factory:


And now the question: how to understand the architecture, micro-architecture, digital circuitry, the principles of design of AI chips and participate in such parties? The easiest way is to study the textbook “Digital Circuit Design and Computer Architecture” by David Harris and Sarah Harris, and go to Wave Computing for the summer as an intern (it is planned to hire 15 trainees for the summer). I hope that this can also be done in Russian microelectronic companies that are engaged in similar developments - ELVIS, Milandr, Baikal Electronics, IVA Technologies and several others. In Kiev, this can theoretically be done in cooperation with the KPI company Melexis.
Recently, a new, finally revised version of the Harris & Harris textbook has been released, which should be here for free.www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 , but in my opinion this link does not work, and when it works, I will write about this separate post. With questions asked for interviews at Apple, Intel, AMD, and on which pages of this tutorial (and other sources) you can see the answers.
Recently, the mayor of the city of Campbell, with the Russian surname Paul Resnikoff, cut the ribbon when opening a new office for the startup Wave Computing, which, together with Broadcom, is developing a 7-nm chip to speed up the computation of neural networks. The office is located in the building of the historic fruit canning factory of the late 19th and early 20th centuries, when Silicon Valley was the largest orchard in the world. Even then, in the office, they were engaged in innovations, introducing electric motors for conveyors in the apricot-plum industry, for which about 200 employees, mostly women, worked.
On the party following the cutting of the ribbon, many well-known people in the industry appeared, in particular, Kernighan-Richie's associate and author of the most popular C compiler of the late 70s - early 80s, Stephen Johnson, one of the authors of the floating-point standard Jerome Cunen, inventor local bus concepts and chipset developer of the first PC AT Diosdado Banatao, former developers of Sun, DEC, Cyrix, Intel, AMD and Silicon Graphics processors, Qualcomm, Xilinx and Cypress chips, industrial analysts, a girl with red hair and other Californian co-workers This type of company.
At the end of the post we will talk about what books you need to read and do some exercises to join this community.
Let's start with Jerome Coonen, the innovator of floating point arithmetic and the Apple manager at the time of the first Macintosh.
Not so often there are master's theses that affect computing on billions of devices. This was the disserver Jeromei Kunen (left) "Contributions for a Floating Point Arithmetic", the results of which were included in IEEE Standard 754 floating-point numbers. After graduating from Berkeley Graduate School in 1982, Jerome went to work for Apple, where he introduced floating point libraries to the first Macintosh.
After 10 years of management at Apple, Kunen advised Hewlett-Packard and Microsoft, and in 2000 he optimized 128-bit arithmetic for AMD's only 64-bit version of x86. Recently, Jeromy turned his attention to research on floating-point standards for neural networks, in particular, disputes about Unum and Posit. Unum is the new proposed standard, promoted by the Caltech scholar John Gustafson, the author of The End of Error, the now noisy book, End of Error. Posit is a version of Unum that can be more effectively (*) than Unum implemented in hardware.
(*) More effective in terms of a combination of parameters: clock frequency, number of cycles per operation, conveyor throughput, relative area on a chip, and relative power consumption.
Images from the articles (not from Jerome) Making it and
making it easy to use it at its Own Game: Posit Arithmetic by John L. Gustafson and Isaac Yonemoto :
But for the party Stephen / Steve Johnson is the person on the compiler whose C programming language has become popular. The first C compiler was written by Denis Ritchie, but the Richie compiler was tightly tied to the PDP-11 architecture. Steve Johnson, based on the work of Alan Snyder, wrote in the mid-1970s the Portable C Compiler (PCC) compiler, which was easy to remake to generate code for different architectures. At the same time, the Johnson compiler worked quickly and was optimizing. How did he achieve this?
At the PCC input, Steve Johnson used the LALR (1) parser generated by the YACC (Yet Another Compiler Compiler) program, which was also written by Steve Johnson. After this, the compilation task was reduced to manipulating trees in recursive functions and generating code using the template table. Some of these recursive functions were machine-independent, the other part was copied by people who transferred PCC to another machine. The template table consisted of rule entries of the type “if the register is of type A and two of the register of type B, rebuild the tree into a node of type C and generate a code with the string D”. The table was machine dependent.
Due to the combination of elegance, flexibility and efficiency, the PCC compiler was transferred to more than 200 architectures - from PDP, VAX, IBM / 370, x86 to the Soviet BESM-6 and Orbit 20-700 (onboard computer in early versions of the MiG-29). According to Denis Ritchie, almost every C compiler of the early 1980s was based on PCC. From the BSD Unix world, the PCC was supplanted as the standard-only GNU GCC compiler in 1994.
In addition to PCC and Yacc, Steve Johnson is also the author of the original Lint program verification program (see eg 1978 article). The names of the programs Yacc and Lint have since become a household name. In the 2000s, Steve rewrote the MATLAB front-end and wrote MLint. Now Steve Johnson is busy with the task of parallelizing the algorithms for computing neural networks on devices like CGRA (Coarse-Grained Reconfigurable Architecture), with tens of thousands of processor elements, which are thrown between tensors through a network of tens of thousands of transistors too:
But with a glass of wine billionaire Diosdado Banatao, the founder of Chips & Technologies, S3 Graphics and an investor in Marvell. If you programmed the IBM PC in 1985-1988, when they first appeared in the USSR, then you may know that inside most of the AT-NIS with EGA and VGA graphics, there were chipsets from Chips & Technologies, which came out simultaneously with IBM-ovsky. Early C & T chipsets were designed by Banatao, who studied electronics at Stanford, and before Stanford worked as an engineer in Boeing. In 1987, Chips & Technologies bought Intel.
On the left in the picture below is John Bourgoin, President of MIPS Technologies at the time of this company's heyday in the 2000s, when chips with MIPS cores were inside most DVD players, digital cameras and TVs, with chipsets from Zoran, Sigma Design, Realtek, Broadcom and other companies. Prior to that, John was president of MIPS Silicon Graphics since 1996 when MIPS processors stood inside Silicon Graphics workstations, which were used in Hollywood to shoot the first realistic 3D Jurassic Park films. Prior to Silicon Graphics, John was one of the vice presidents of AMD, since 1976.
Art Swift, right, was the MIPS vice president of marketing in the 2000s, and before that in the 1980s he worked as an engineer at Fairchild Semiconductor (yes, that one), then as vice president of marketing at Sun, DEC, Cirrus Logic, and President of the company Transmet. Recently, Art was vice-chairman of the marketing committee of RISC-V and is familiar with Russian companies Syntacore and CloudBear in this position. And now he has become president of Wave's MIPS IP direction:
Slides from a MIPS history presentation related to the period when MIPS was managed by John Bourgoin, in the above left image:
The company Transmet, whose president was Art Swift for a while, in the photo above to the right, released the Crusoe processor in the late 1990s, which could carry out x86 instructions and reached the market in Toshiba Libretto L sub-laptops, NEC and Sharp laptops , the thin client from Compaq. Their competitive advantage over Intel and AMD was put to controlled low power consumption.
Direct implementation and verification of the full set of x86 is a very expensive event, so Transmet went the other way, which resembles the path of the Russian company MCST with the Elbrus processor (the line that began with Elbrus 2000 and is now represented as Elbrus 8C). Transmet and Elbrus were set up as a basis for a structurally simple processor with a VLIW microarchitecture, and on top of it worked the x86 emulation level using the technology that Transmeta called code morphing.
The idea of VLIW (Very Long Instruction Word - Very Long Word Instructions) is quite simple - several processor instructions are explicitly declared by one superinstruction and are executed in parallel. Unlike superscalar processors, in particular Intels, starting with PentiumPro (1996), in which the processor selects several instructions from memory, and then decides what to execute in parallel and what is sequential, based on automatic analysis of dependencies between instructions.
A superscalar processor is much more complicated than a VLIW, because a superscalar has to spend logic on maintaining the illusion of the programmer that all the selected instructions are executed one after another, although there are actually dozens of them inside the processor at different stages of execution. In the case of VLIW, the burden of maintaining such an illusion falls on the compiler from a high-level language. Ultimately, the VLIW circuit breaks down when the processor has to work with multi-level cache memory, which has unpredictable delays, which make it difficult for the compiler to schedule tick instructions. But for mathematical calculations (for example, to put Elbrus on the radar and to calculate the movement of the target) this is the most, especially in the conditions of a shortage of qualified engineering personnel (more people are needed to verify the superscalar).
Illustration of the VLIW idea, the Crusoe processor and the Toshiba Libretto L1 sub-nout:
But in the center in the photo below, Derek Meyer, Derek Meyer, the current CEO of Wave Computing. Prior to Wave, Derek was the CEO of ARC, the developer of ARC processor cores, which are used in audio chips. At one time, these cores were licensed by the Russian company NIIMA Progress , which later licensed the MIPS cores and showed the chips based on them at the exhibition in Kazan Innopolis . Derek Meyer repeatedly traveled to Russia, to St. Petersburg, where the Virage Logic development team was located. In 2009, ARC bought Virage Logic, and in 2010, ARC was swallowed up by Synopsys, the main chip design manufacturer in the world.
Right on the photo -Sergei Vakulenko , who at the dawn of his career stood at the origins of the Runet, worked in the cooperative Demos and the Kurchatov Institute, which brought the Internet to the USSR. Now Sergey is writing a cycle-accurate model of the Wave processor element for computing neural networks, and earlier he wrote instruction-accurate models of MIPS cores that were used to verify MIPS processor cores I6400 Samurai, Shaolin I7200 and others.
Here is Vadim Antonov and Sergei Vakulenko in 1990, with the first computer in the USSR connected to the Internet:
But on the right is Larry Hudepohl (Hudepol is written in Russian?). Larry began his career at Digital Equipment Corporation (DEC) as a processor designer for MicroVAX. Then Larry worked in a small company Cyrix, which in the late 1980s defied Intel and made an FPU co-processor that was compatible with Intel 80387 and was 50% faster than it. Then Larry designed the MIPS chips in Silicon Graphics. When MIPS Technologies separated from Silicon Graphics, Larry and Ryan Kinter together started the first independent MIPS product - MIPS 4K, which became the basis of the line that dominates the 2000s home electronics (DVD players, cameras, digital TVs). Then MIPS 5K flew into space - it was used by the Japanese space agency JAXA. Then Larry in the position of VP Hardware Engineering led the development of the following lines,
The Japanese spacecraft with the proud name of Hayabusa-2 (Sapsan-2), which landed on the surface of Ryugu asteroid last year , is controlled by an HR5000 processor based on the MIPS 5Kf processor core licensed by MIPS Technologies for a long time.
Here is a simple serial pipeline of the 64-bit processor core MIPS 5Kf from its datasheet :
Darren Jones, Darren Jones, on the right. He was the director of hardware engineering at MIPS in charge of the development of complex cores, with hardware multithreading, and superscalars with the extraordinary execution of instructions. Then Darren went to Xilinx, where he studied Xilinx Zynq - chips, which are based on a combination of FPGAs and ARM processors. Darren has now become vice president of engineering at Wave.
At MIPS, Darren was the leader of the group, whose members then went to work for Apple and Samsung. Designer Monica, who went to Samsung, once told me a phrase that I remembered well: “RTL design: development of equipment at the level of register transmissions: a few simple principles, everything else is muhlezh”) A canonical example of a cache is a cache (the program recorded data and read it, but it will only be remembered sometime later), but this is only a very special case of what Monica was able to do.
Hardware multithreading and an extraordinary superscalar are two different approaches to improving processor performance. Hardware multithreading allows you to increase throughput without much power consumption, but with non-trivial programming. The superscalar allows you to perform single-threaded programs roughly twice as fast, but it also spends twice as many watts. But without programming tricks.
Hardware multithreading is finally well explained in the Russian Wikipedia, here is its temporary multithreading (it is implemented in MIPS interAptiv and MIPS I7200 Shaolin), but simultaneous multithreading (it was done in the 1990s in DEC Alpha processors, then in SPARC, and then in MIPS I6400 Samurai / I6500 Daimyo).
Temporary multithreading exploits the fact that a processor with a regular serial pipeline half the execution time is idle / waiting. What is he waiting for? Data that goes through caches from memory. And it waits a long time - during the waiting time for one cache miss, the processor could execute dozens or even a hundred or two simple arithmetic instructions such as addition.
This was not always the case - in the 1960s, arithmetic devices were much slower than memory. But since about 1980, the speed of processor cores has grown much faster than memory speed, and even the appearance of multi-level caches on processors solved the problem only partially.
Processors with temporal multithreading support several sets of registers, one for each thread, and when the current thread waits for data from the memory during a cache slip, the processor switches to another thread. This happens instantly, in a cycle, without interruptions, and thousands of cycles of the interrupt handler, which is enabled with software (not hardware) multithreading.
Here's the idea of multithreading on slides from the seminars of Charles Danchek , a teacher from the University of California Santa Cruz, Silicon Valley Extension. Why in Russian? Because Charles Danchek gave lectures in Moscow MISiS, then in St. Petersburg ITMO and in Kiev KPI:
Interestingly, it is possible to program in a hardware-multithreaded way just in C. Here's what it looks like:
#include"mips/m32c0.h"#include"mips/mt.h"#include"mips/mips34k.h"// Это макро на Си использует GNUшные штучки,// которые позволяют вставлять параметры прямо в ассемблируемый код.// С помощью этого параметра поток (thread) будет знать свой ID.// Обратите внимание на инструкцию FORK. Да, это одна 32-битная инструкция!#define mips_mt_fork_and_pass_param(thread_function, param) \
__extension__ \
({ \
void * __thread_function = (thread_function); \
unsigned __param = (param); \
\
__asm__ __volatile \
( \
".set push; .set mt; fork $4,%0,%z1; .set pop" \
: : "d" (__thread_function), "dJ" (__param) \
); \
})voidthread(unsigned tc){
// Тут можно делать что-нибудь параллельное.// Потоки могут обмениваться информацией// через аппаратно-реализованные FIFO и общую память,// а также синхронизироваться аппаратными семафорами.
}
intmain(){
// Макросы чтобы поставить аппаратную многопоточностьfor (tc = 0; tc < NUM_TCS; tc++)
{
mips32_setvpecontrol (VPECONTROL_TE | tc);
u = mips32_mt_gettcstatus ();
mips32_mt_settcstatus (u | TCSTATUS_DA);
mips32_mt_settchalt (0);
}
mips_mt_emt ();
// Запускаем восемь параллельных потоков выполнения, остаемся в девятомfor (int tc = 1; tc < NUM_TCS; tc ++)
mips_mt_fork_and_pass_param (thread, tc);
thread (0);
}
Here is a Wave device for data centers on the side of the party. It does not work yet, although the chips are available to some customers as part of a beta program:
What does this device do? Can you program on Python? Here on Python, you can build the so-called Data Flow Graph (DFG) calls to the TensorFlow library. Neural networks are essentially specialized graphs like these, with matrix operations. In the Wave software group, part of which Steve Johnson manages, there is a compiler with a subset of the representation of Google’s TensorFlow in the configuration files for the chips of this device. After configuration, it can make calculations of such graphs very quickly. The device is intended for data centers, but the same principle can be applied to small chips, even inside mobile devices, for example, for face recognition:
Chijioke Anyanwu (left) - has been the custodian of the entire MIPS processor core testing system for many years. Baldwyn Chieh (center) is the designer of a new generation of processor-like elements in Wave. Baldwin used to be a senior designer at Qualcomm. Here are slides about the Wave device from the HotChips conference :
Each nanometer- wide digital innovative AI company in Silicon Valley must have its own girl with bright hair. Here is a girl in Wave. Her name is Athena, she is a sociologist by training, and works in the office as an office:
But what an office looks like from the outside, and its more than a century of history from the time when it was an innovative canning factory:
And now the question: how to understand the architecture, micro-architecture, digital circuitry, the principles of design of AI chips and participate in such parties? The easiest way is to study the textbook “Digital Circuit Design and Computer Architecture” by David Harris and Sarah Harris, and go to Wave Computing for the summer as an intern (it is planned to hire 15 trainees for the summer). I hope that this can also be done in Russian microelectronic companies that are engaged in similar developments - ELVIS, Milandr, Baikal Electronics, IVA Technologies and several others. In Kiev, this can theoretically be done in cooperation with the KPI company Melexis.
Recently, a new, finally revised version of the Harris & Harris textbook has been released, which should be here for free.www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3 , but in my opinion this link does not work, and when it works, I will write about this separate post. With questions asked for interviews at Apple, Intel, AMD, and on which pages of this tutorial (and other sources) you can see the answers.
Only registered users can participate in the survey. Sign in , please.