Assessment of the competitiveness of search queries by variations of search results
Assessing the degree of competition for a key query is one of the sacred tasks of search engine optimization. The hope of finding a query with a good conversion unnoticed by competitors is akin to finding a Filosovo stone. Let’s try and we will contribute to this alchemical get-together.
It turns out that the degree of competition can be assessed almost instantly only by comparing the search results for two interconnected queries - without analyzing puzomerki, competitor sites, click cost statistics and shoveling mountains of information.
Background
The difficulty of promotion in the TOP for a given key request is rightly associated with the number of competitors fighting for first places. There are several ways to assess the degree of this “difficulty”. Here are the most common ones.
Ranking Factor Analysis. This method consists in analyzing the search results and the sites included in it: the total number of sites, the number of contextual advertising, the average number of links, the degree of optimization of each site, etc. Then this information with the help of the weight function is reduced to one indicator KEI (Keyword Effectiveness Index), by which queries are compared. The main problems with the application of this method are the choice of indicators, their methods of (automatic) measurement and weights. Just notice that Yandex uses 800 nontrivially calculated parameters to rank pieces.
Contextual Bid Analysis. This method comes down to estimating and comparing auction rates for click cost in contextual advertising systems (Yandex Direct, Google AdWords). The connection is clear - the “more interesting” the request, the more advertisers fight for first place, the higher the rate. But the principles of pricing differ in context and in search engine optimization, which may affect the accuracy of estimates.
Comparison with competitive budgets. This information is available in numerous automatic promotion systems (SeoPult, Rookee) as statistics of its users. But the problem is that for mid-frequency and low-frequency queries such statistics may not be enough, therefore, you can often see the standard minimum amount as cost estimates. In addition, the main (if not the only) component of such a budget is the reference budget. And links now play an ever smaller role.
Idea
But there is another interesting way based on some properties of the search engine query language. In this language, concepts such as broad and precise queries usually exist. Their meaning is that in response to a wide request, you can get information in all word forms and with any order of words, and in response to the exact one - in the form in which the request is formed.
For example, in Yandex search language notation, a broad query will look like
[buy a car]And exact as
["!buy a car"]
The main requirements for search engine optimization sites are the presence of exact occurrences of the search query in the texts and markup of the site, as well as their use as anchors of external and internal links. As a result, a site that is optimized for a specific request differs from a site that is not optimized with a large number of exact occurrences of the search query.
If the request is highly competitive, then the difference in the results of the results for broad and accurate queries will not differ significantly, since there are a lot of optimized sites and there is plenty to choose from for the search algorithm. If the query is not very competitive, then the search algorithm will compensate for the lack of optimized sites with the rest - those where it can find words that are close to the search query, but possibly in a different morphology and in a different sequence.
As a result, the lower the competition, the search results are more diverse, "looser", and the easier it is for a new candidate to penetrate it. The higher the competition, the less diversity, and the greater the likelihood that it will be filled with the same people involved, squeezing between them will not be easy.
As an example, let's take a random look at a few different queries from automotive topics (in order to obviously guarantee a different degree of competition) and see what happens to them in Yandex.
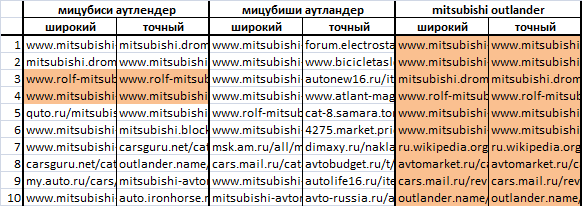
The wide and accurate forms of these queries, as well as the frequency of wide queries, are as follows:
[crossover] ["! crossover"] (239,714) [Mitsubishi Outlander] ["! Mitsubishi Outlander"] (73,760) [Mitsubishi Outlander] ["! Mitsubishi Outlander"] (68,149) [Mitsubishi Outlander] ["! Mitsubishi! Outlander"] (128) [mitsubishi outlander] ["! mitsubishi! outlander"] (41,392)
Here's what the ranking results for these queries look like. Here, the color indicates the sites that match in the issuance of a wide and accurate options. With the naked eye, you can immediately see the difference between [mitsubishi outlander] (41,392) and [mitsubishi outlander] (128) - that is, between requests with obviously different competition.
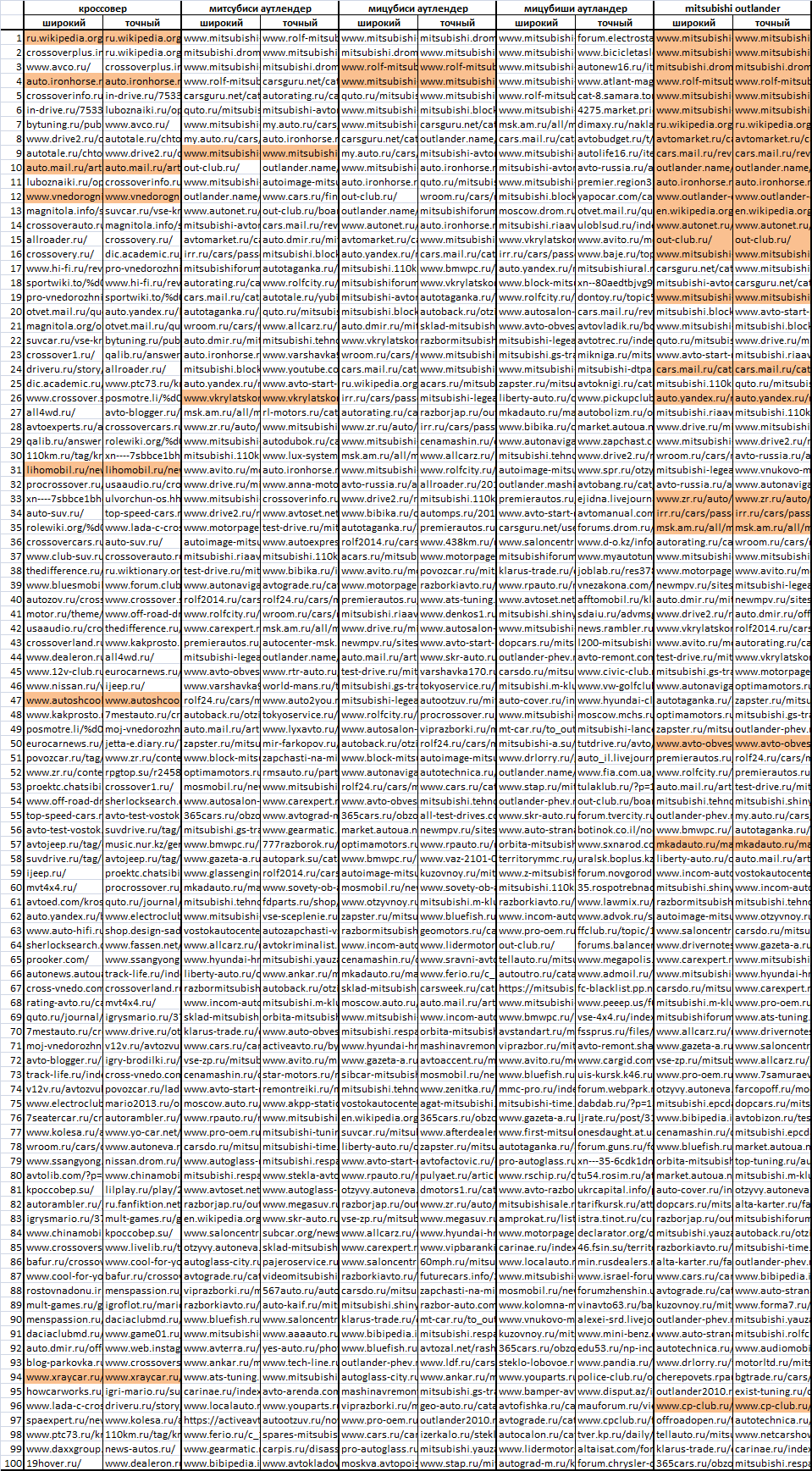
Payment
Visually, the idea is clear - the greater the difference between search results for a wide and accurate search query form - the lower the competition. The lower the variety, the higher the competition. But how to count it now? How to measure the degree of this diversity?
For this we use the expression for the distances between the ratings obtained in the paper Estimating the variability of search results .
Examples of calculations for this expression can be found here .
So, we have the following formula for calculating the weighted relative distance between two ratings R ' and R ' '
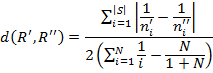
Here:
N - length of the rating (TOP5, TOP10, etc.);
| S| - the number of elements in the set S = R ' U R ' ' , that is, the total number of unique objects in two ratings;
n ' i and n ' ' i are the positions of the i- th element, respectively, in the rating R ' and R '' , and if the object is not in the rating, then its position in this rating is taken as N +1.
The higher the variety of results, the greater the distance between the ratings. Therefore, as the degree of competition, we will use the value opposite to the distance:
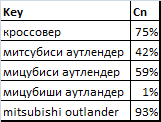
Cn = 1- d
For our requests, we obtain the following values of the degree of competition (in percent) according to the TOP100 rating.
The question now is, to what depth should I view the search results. To answer this question, the dependence of the degree of competition on the rating length presented in the following graph will help us.
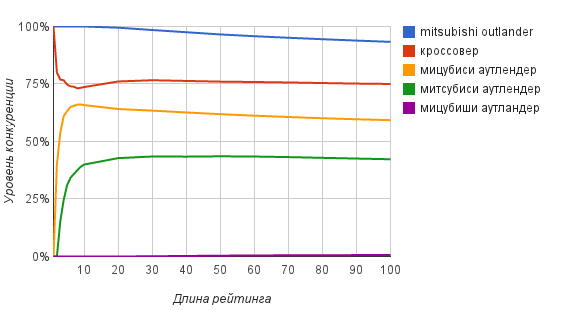
As can be seen from the graph, already at the TOP20-TOP30 level, fairly accurate estimates of the degree of competition can be obtained.
Approbation
What method of assessing the degree of competition more accurately reflects the costs of reaching the top of the search ranking? I do not know the answer to this question. I don’t know the answer to simpler questions - how to calculate the actual costs of SEO. Or at least the actual costs of optimization for a specific (separate) key request.
How then can we evaluate the accuracy of the forecast of a value that we are not able to measure?
The situation is like in dietetics: you can come up with a bunch of diets, but it’s not possible to really assess what affected the life expectancy. And just like in dietetics, one can probably get an answer only through the experience of many generations.
In the meantime, the only option for checking the accuracy of the proposed method is common sense and comparison with analogues. Well, in terms of simplicity and convenience, he has no competitors. After all, he can give estimates even for newly emerging key phrases (attention to those who earn on trends)!
As for analogues, the comparative results of assessing the degree of competition using some of the methods listed above are presented below.
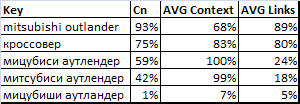
Here:
Cn - assessment of the degree of competition obtained by our method.
AVG Context - an estimate based on click cost statistics in contextual advertising systems (Yandex Direct and Google AdWords). Values are averaged and normalized (the maximum cost per click is taken as 100%).
AVG Links- An estimate obtained in automatic promotion systems (SeoPult, SeoPult PRO, Rookee) according to the recommended budget. Values are averaged and normalized (the maximum budget is taken as 100%).
Although the values differ, the main thing is that the ranking order is the same when using Cn and AVG Links ratings . It is difficult to say which of these two estimates is more accurate, but the SeoPult PRO source data for three out of five requests did not contain statistics (the minimum possible system budget was proposed). So there is every reason to believe that our algorithm can handle this task better.
Regarding the forecast for contextual bids AVG Context, then he clearly stands out from the general trend. Use this method with great caution.
Conclusion
The simplicity of the proposed method is obvious. The accuracy of the calculations seems to be quite good. Plus the ability to get grades in situations where other methods are powerless.
What else is needed to adequately meet the