Image archive storage for a site in Azure Blob storage
The article tells about the experience of organizing budget storage of an image archive for a site with millions of ads.
Images in my case are photos of apartments, houses, plots, etc. I have my own project which is a website with ads for the sale and rental of real estate. The site has something about 6 years and during this time has accumulated a fairly large number of ads. Each object card displays photos, an average of 8 photos per ad. Actually I’m going to keep these photos in the cloud so that I can show them to visitors on the object cards.
How did I keep them before? - no way. I did not store any images other than those that were manually posted. In most cases, the ads get to the site through partners through automatic feed loading. In the feed for each object there are links to photos - these are the links I store and give the visitor a photo directly from the partner. This scheme works great and saves a bunch of resources.
Photos that visitors see in the selection of ads or in the object card are actually loaded from third-party resources.
There is one nuance associated with the specifics of the site - archive objects are never deleted. Those. after an ad is removed from publication, it of course disappears from the search results, but always available via a direct link (without the seller’s contacts). For some time, links to photos still live, sometimes for years, but sooner or later they die. Archived objects are valuable because visitors continue to come from search engines. Also, a price map is built on the archive (I already wrote about it), and I also accidentally discovered an additional source of income for the project in the form of the sale of contact details of archival objects. Why do they buy them - I do not know for sure, but I assume that visitors want to get contacts because they think that the ad was removed from the publication by accident or by mistake. It also probably happens that they want to learn something from previous owners. Anyway, an ad with photos in this case is more likely to be purchased. The value of photos increases after the realization of this nuance.
Data volumes which I am going to store in a cloud make about 3-4 terabytes. Plus a daily increase of several gigabytes. Considering that this innovation of money will not directly bring, but only indirectly can affect the decision-making by the visitor, the budget in which I wanted to keep very modest - this is 1000-2000 p. per month. It would be nice to be free, but I did not find such an opportunity.
I somehow immediately looked towards Azure because I work on .net, and often I see beautiful promotional articles on this topic. Plus, you have to use this platform for the main work, but there my opportunities are limited by business requirements and management wishes.
Azure offers BLOB storage with three levels of storage: Hot, Cool and Archive. Prices at all levels are different. In general, the hotter - the cheaper the reading / writing and the more expensive the monthly storage fee, and vice versa. On Hot, it is advantageous to write / read and delete a lot, but it is expensive to store for a long time. And on Archive it is cheap to keep but expensive to read / write. Also at the archive and cold levels there is a fee for early deletion - this means that if I delete (or transfer to another level) an object earlier than a certain period, then I will still be charged as for all this period. For the archival level - it is 180 days, for the cold - 30.
The cost of storage is $ 0.0023 per GB per month at the archive level, $ 0.01 in the cold and $ 0.0196 in the hot. At the current exchange rate, this is approximately 0.15, 0.65 and 1.28 rubles, respectively.
I compared with the cost in Amazon and Google, it turns out that in Azure is cheaper.
In addition to the cost of storage, it is necessary to take into account the cost of operations - they are also different at all levels. Prices are per 10,000 transactions.
Hot
Reading: $ 0.0043, writing: $ 0.054
Cool
Reading: $ 0.01, writing: $ 0.10
Archive
Reading: $ 6, writing: $ 0.12
While the ad is active, photos in it are displayed by links from third-party resources (from partners). After removing an advertisement from publication, it becomes archived, but links to photos are still alive for a while. Sooner or later they die, and you need to take care that by this time there was an archive copy.
The processing of photographs can be described in the following steps:
When the process was written and tested, it was time for trial operation, and then it was expected that trouble would arise. At that time there were about 10 million objects in the queue; I decided to start the migration from 30,000 objects per day. I set up beautiful graphics on the dashboard and began to observe. In the statistics, I saw strange “attacks” with GetBlobProperties requests. They occur at approximately equal intervals of one hour, they always begin about one and a half hours after the start of the migration, and last some more time after its completion.
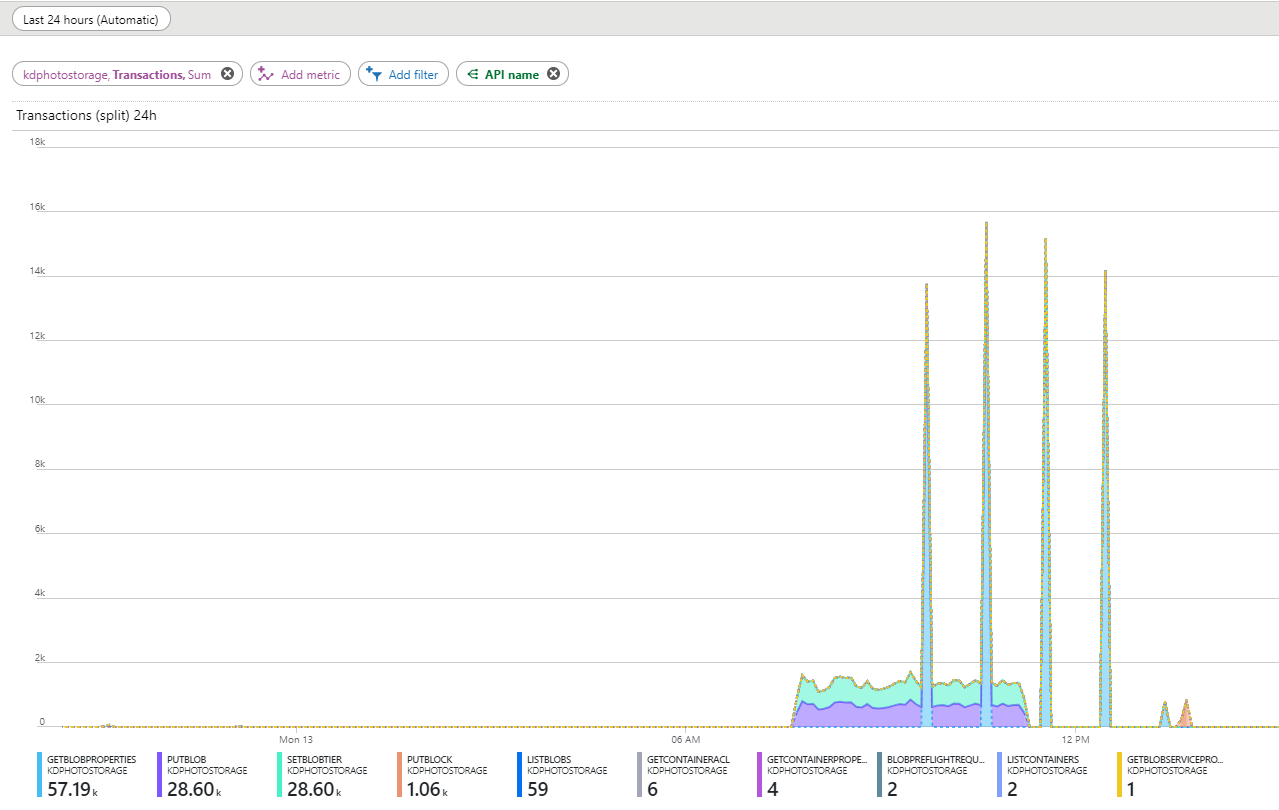
The number of such requests was too large to ignore them. I watched the logs and saw that these requests are not coming from my server, but from foreign IP addresses. I did not want to pay for them.
I searched on the stack and in the documentation, but to no avail. Postedquestion on Stackoverflow and tech support. As a result, after a long correspondence with technical support, and providing them with logs, they told me that they could reproduce the situation and this is a bug on their side.
An interesting nuance is that the answer to my question on Stackoverflow was given not explaining the reasons, but only confirming that I would pay for these requests, but the person who gave the answer insistently asked me to mark it as correct. He also casually hinted to me that they (in support) are not welcome to spread about errors in their own products. I let him know that I would not do it until he wrote the truth. I could write it myself, but I thought that the technical support staff probably measured the effectiveness including the number of confirmed answers, so I suggested that he write the true reason and in this case I would mark his answer as correct. After some hesitation, he agreed and added a comment about the bug to his comment.
The fact of the recognition of the bug satisfied me only morally, but I wanted to launch the mechanism into operation, and not to pay money for left-wing requests. Especially considering that I am so confused so as to minimize the number of requests and thus the cost.
In technical support, I was advised to wait with the launch and after a couple of weeks they wrote that the bug was fixed, but when the release with the fix will be done is unknown. They offered to enable logging and work like this, and after the release to request compensation from Microsoft. Actually, in this mode, it still works. I start the migration of a small number of objects every day and wait for the release.
The cost of the daily 30,000 objects costs while in 900 p. per month - and this is quite acceptable. Most of the costs are write operations. So when the entire queue is processed and the stage of planned work comes, it will be clear what the real cost of such storage is. But according to my calculations, this will happen in about a year.
When there will be a release in Azure Blob-storage, I will add here whether it was possible to get compensation. Regarding the monthly expenses - this is about 10% of the cost.
Images in my case are photos of apartments, houses, plots, etc. I have my own project which is a website with ads for the sale and rental of real estate. The site has something about 6 years and during this time has accumulated a fairly large number of ads. Each object card displays photos, an average of 8 photos per ad. Actually I’m going to keep these photos in the cloud so that I can show them to visitors on the object cards.
How did I keep them before? - no way. I did not store any images other than those that were manually posted. In most cases, the ads get to the site through partners through automatic feed loading. In the feed for each object there are links to photos - these are the links I store and give the visitor a photo directly from the partner. This scheme works great and saves a bunch of resources.
Photos that visitors see in the selection of ads or in the object card are actually loaded from third-party resources.
There is one nuance associated with the specifics of the site - archive objects are never deleted. Those. after an ad is removed from publication, it of course disappears from the search results, but always available via a direct link (without the seller’s contacts). For some time, links to photos still live, sometimes for years, but sooner or later they die. Archived objects are valuable because visitors continue to come from search engines. Also, a price map is built on the archive (I already wrote about it), and I also accidentally discovered an additional source of income for the project in the form of the sale of contact details of archival objects. Why do they buy them - I do not know for sure, but I assume that visitors want to get contacts because they think that the ad was removed from the publication by accident or by mistake. It also probably happens that they want to learn something from previous owners. Anyway, an ad with photos in this case is more likely to be purchased. The value of photos increases after the realization of this nuance.
Data volumes which I am going to store in a cloud make about 3-4 terabytes. Plus a daily increase of several gigabytes. Considering that this innovation of money will not directly bring, but only indirectly can affect the decision-making by the visitor, the budget in which I wanted to keep very modest - this is 1000-2000 p. per month. It would be nice to be free, but I did not find such an opportunity.
Azure
I somehow immediately looked towards Azure because I work on .net, and often I see beautiful promotional articles on this topic. Plus, you have to use this platform for the main work, but there my opportunities are limited by business requirements and management wishes.
Azure offers BLOB storage with three levels of storage: Hot, Cool and Archive. Prices at all levels are different. In general, the hotter - the cheaper the reading / writing and the more expensive the monthly storage fee, and vice versa. On Hot, it is advantageous to write / read and delete a lot, but it is expensive to store for a long time. And on Archive it is cheap to keep but expensive to read / write. Also at the archive and cold levels there is a fee for early deletion - this means that if I delete (or transfer to another level) an object earlier than a certain period, then I will still be charged as for all this period. For the archival level - it is 180 days, for the cold - 30.
Prices
The cost of storage is $ 0.0023 per GB per month at the archive level, $ 0.01 in the cold and $ 0.0196 in the hot. At the current exchange rate, this is approximately 0.15, 0.65 and 1.28 rubles, respectively.
I compared with the cost in Amazon and Google, it turns out that in Azure is cheaper.
| Azure | Amazon (S3) | ||
| Hot | $ 0.0196 | $ 0.024 | $ 0.026 |
| Cool | $ 0.01 | $ 0.01 | $ 0.01 |
| Archive | $ 0.0023 | $ 0.0045 | $ 0.007 |
In addition to the cost of storage, it is necessary to take into account the cost of operations - they are also different at all levels. Prices are per 10,000 transactions.
Hot
Reading: $ 0.0043, writing: $ 0.054
Cool
Reading: $ 0.01, writing: $ 0.10
Archive
Reading: $ 6, writing: $ 0.12
Work logic
While the ad is active, photos in it are displayed by links from third-party resources (from partners). After removing an advertisement from publication, it becomes archived, but links to photos are still alive for a while. Sooner or later they die, and you need to take care that by this time there was an archive copy.
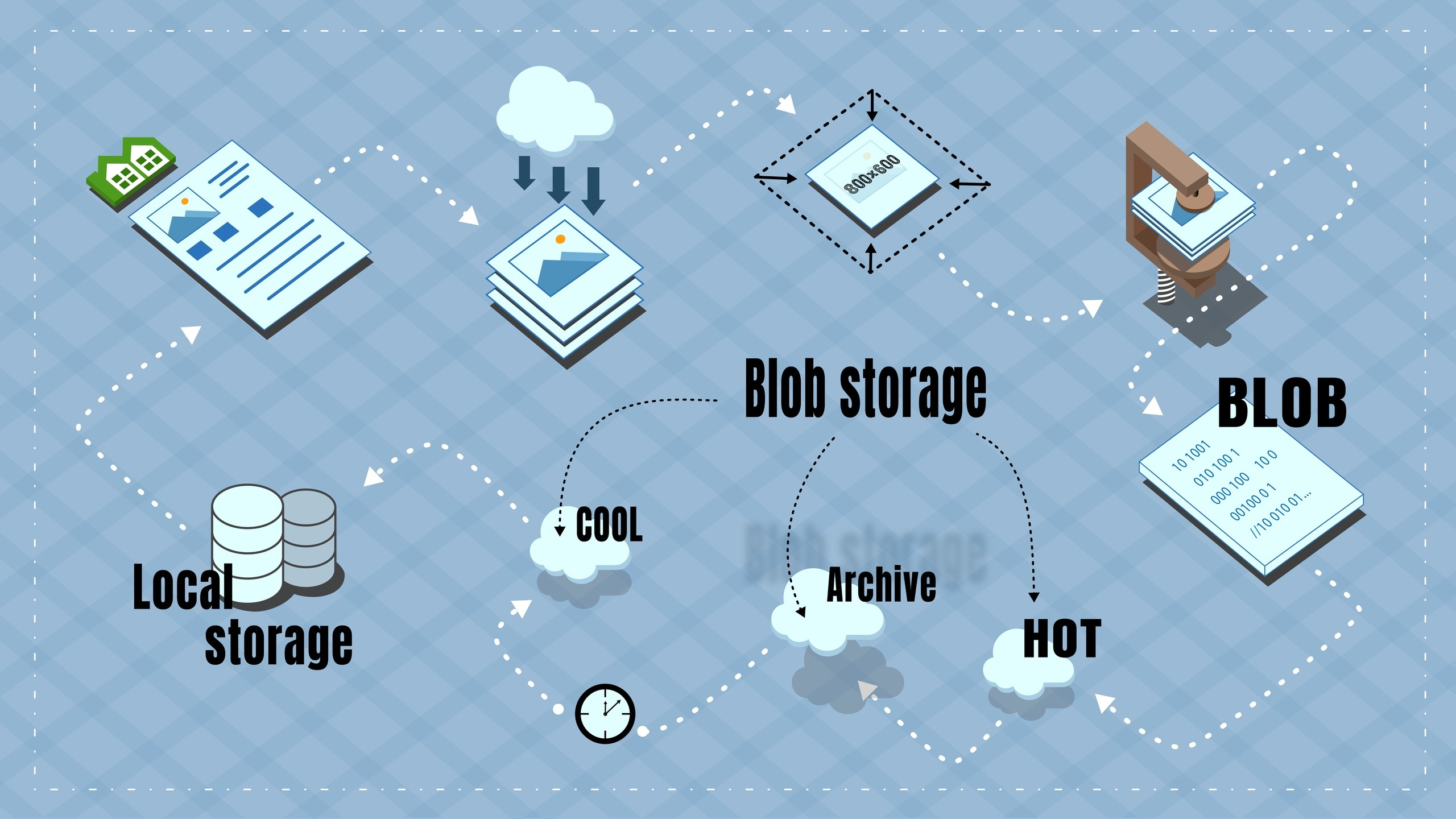
The processing of photographs can be described in the following steps:
- As soon as the ad disappears from the partner's import file, i.e. the partner has ceased to publish it, an entry is formed in the priority queue, where the priority is the number of views by visitors - the more views, the greater the likelihood that being an archive, the object will be viewed further.
- When processing a record from a queue, a blob is created containing reduced (up to 800x600) photos for the announcement. The use of composite objects instead of photos directly is also due to savings - instead of 8 recording operations (an average of 8 photos per object), one is performed, and each operation costs money.
- BLOB is loaded first in Hot, and then immediately moved to the archive. There is no opportunity to write directly to the archive, and since Cool has a fee for early removal, it is cheaper to use Hot as a transit.
- In the BLOB archive lies as long as links to the original photos are active (photos are still shown by links from partners).
- Checking for links is performed when a visitor enters the object card - if you go to it, it means that the object is popular and it makes sense to restore photos from the archive.
- If the links to the original photos are dead, check if there is an archive copy, and if there is, send a request for restoration from the archive to Cool (recovery of a blob from the archive can take up to 15 hours - this is called rehydration from Microsoft).
- As soon as the BLOB has been restored from the archive, it is copied to the local storage and divided into normal photos. Local storage is the hard drive of my server.
- Photos on the ad card are already given from the local storage.
- Photos are stored in the local storage for several days. If during this time there were views, the period of local storage is extended. If there were no views, the photos are removed from the local storage, but remain at the Cool level in Azure.
- From Cool to Archive, they are copied if there were no views for two months - the object is clearly not popular and, accordingly, there is no point in overpaying for storage in Cool.
First start
When the process was written and tested, it was time for trial operation, and then it was expected that trouble would arise. At that time there were about 10 million objects in the queue; I decided to start the migration from 30,000 objects per day. I set up beautiful graphics on the dashboard and began to observe. In the statistics, I saw strange “attacks” with GetBlobProperties requests. They occur at approximately equal intervals of one hour, they always begin about one and a half hours after the start of the migration, and last some more time after its completion.
The number of such requests was too large to ignore them. I watched the logs and saw that these requests are not coming from my server, but from foreign IP addresses. I did not want to pay for them.
I searched on the stack and in the documentation, but to no avail. Postedquestion on Stackoverflow and tech support. As a result, after a long correspondence with technical support, and providing them with logs, they told me that they could reproduce the situation and this is a bug on their side.
An interesting nuance is that the answer to my question on Stackoverflow was given not explaining the reasons, but only confirming that I would pay for these requests, but the person who gave the answer insistently asked me to mark it as correct. He also casually hinted to me that they (in support) are not welcome to spread about errors in their own products. I let him know that I would not do it until he wrote the truth. I could write it myself, but I thought that the technical support staff probably measured the effectiveness including the number of confirmed answers, so I suggested that he write the true reason and in this case I would mark his answer as correct. After some hesitation, he agreed and added a comment about the bug to his comment.
The fact of the recognition of the bug satisfied me only morally, but I wanted to launch the mechanism into operation, and not to pay money for left-wing requests. Especially considering that I am so confused so as to minimize the number of requests and thus the cost.
In technical support, I was advised to wait with the launch and after a couple of weeks they wrote that the bug was fixed, but when the release with the fix will be done is unknown. They offered to enable logging and work like this, and after the release to request compensation from Microsoft. Actually, in this mode, it still works. I start the migration of a small number of objects every day and wait for the release.
Conclusion
The cost of the daily 30,000 objects costs while in 900 p. per month - and this is quite acceptable. Most of the costs are write operations. So when the entire queue is processed and the stage of planned work comes, it will be clear what the real cost of such storage is. But according to my calculations, this will happen in about a year.
When there will be a release in Azure Blob-storage, I will add here whether it was possible to get compensation. Regarding the monthly expenses - this is about 10% of the cost.