House built by Klose or Leaf-Spine architecture: change L2 to L3
 For a long time, all the large projects related to the network, whether it be a web-project or DC of a large enterprise, were one and the same structure. It was a characteristic tree-like architecture, differing only in the size of the tree and the density of "branches", due to different requirements for reliability and performance. But the digital world does not stand still, but is growing and developing rapidly, not only in increasing volumes and speeds, but also changing its structure. All sorts of Big Data, clouds and distributed computing have made it necessary to transmit huge amounts of data between a large number of end nodes over the network, and preferably with a minimum delay.
For a long time, all the large projects related to the network, whether it be a web-project or DC of a large enterprise, were one and the same structure. It was a characteristic tree-like architecture, differing only in the size of the tree and the density of "branches", due to different requirements for reliability and performance. But the digital world does not stand still, but is growing and developing rapidly, not only in increasing volumes and speeds, but also changing its structure. All sorts of Big Data, clouds and distributed computing have made it necessary to transmit huge amounts of data between a large number of end nodes over the network, and preferably with a minimum delay.All this led to the fact that the traditional tree-like architecture, consisting of access levels, traffic aggregation and the kernel, began to skid openly and fail. There is a need to replace it. For what?
To get started, let's try to characterize the network structure in the so-called "traditional" Enterprise-projects:
- from hundreds to several thousand nodes;
- static routing;
- VLAN structure without server virtualization;
- vertically oriented (north-south) architecture
- 1G interconnects with 10G uplinks.
And here are the same characteristics for networks of modern data centers working with such Web 2.0 projects as clouds, Big Data, distributed computing and similar modern large projects:
- from thousands to millions of nodes;
- dynamic routing;
- cloud structure with virtual servers;
- predominantly horizontal (west-east) architecture;
- quick (hours, not weeks) deployment of networks and the addition of racks;
- basically 10G connections with 40G uplinks.

The needs of the new world
There is a significant difference requiring organizational change.
If we summarize the diverse requirements for modern network infrastructure, they will become as follows:
- good scalability of performance;
- fault tolerance at all levels;
- high interchangeability to reduce costs;
- predictable latency;
- high availability of equipment;
- convenience of service.
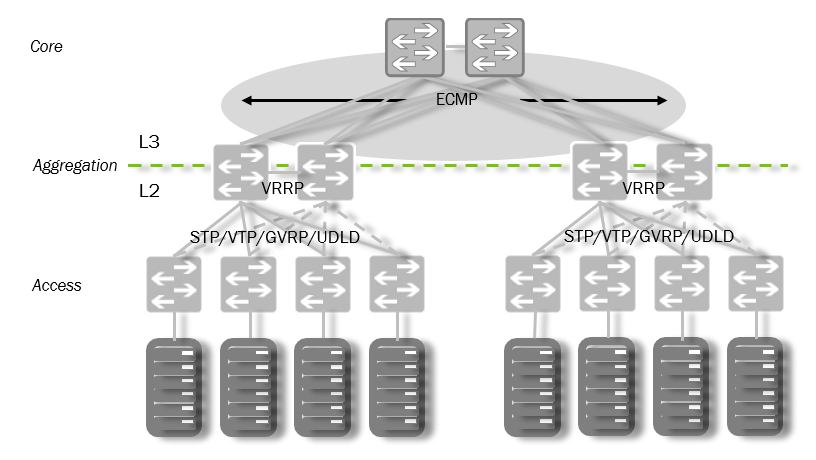
Traditional network infrastructure
What is absolutely categorical about the traditional scheme?
- A sharp decrease in productivity in case of failure at the level of aggregation;
- Lack of scalability caused by aggregation level:
- MAC / ARP
- VLANs
- congestion of horizontal traffic exchange points;
- a sharp increase in the complexity of the structure with increasing reliability;
- Many proprietary protocol options (MLAG, vPC, STP, UDLD, Bridge Assurance, LACP, FHRP, VRRP, HSRP, GLBP, VTP, MVRP ...)
Decision? As soon as we start talking about the scale, when the cost of service begins to exceed the cost of equipment (yes, so beloved by accountants and marketers, and unloved by the rest of CAPEX and OPEX), the long-known solution in the form of Clos networks comes onto the scene, also known as Leaf-Spine architecture .
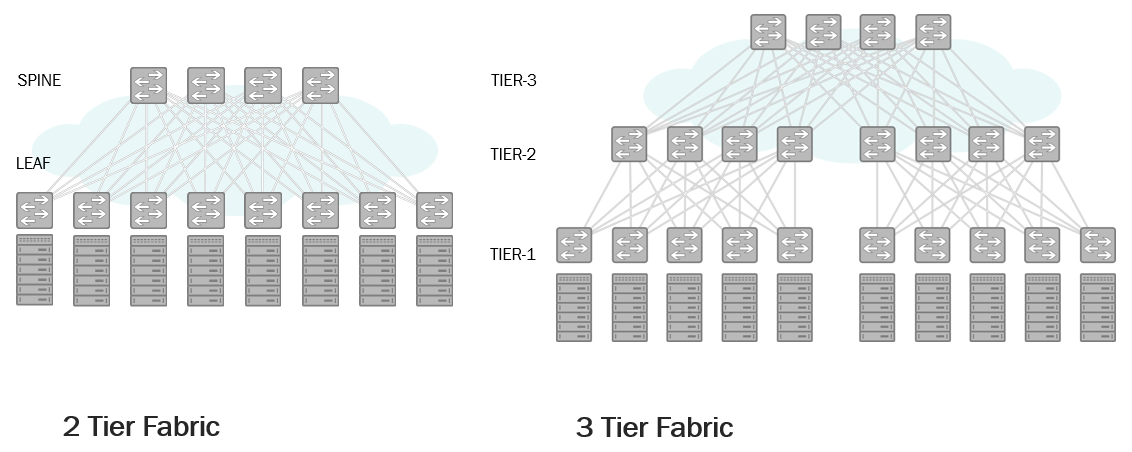
Leaf-Spine
An important note for the inattentive: the level of Spine is not at all identical to the level of aggregation. At this level, there are no horizontal connections between switches and it’s not supposed, and all the more it’s not supposed that all traffic through this level is collected and goes to the core or, say, the Internet.
This architecture itself has been known for half a century and has been successfully used in telephone networks, but now there are all the prerequisites for its active implementation in the data center network. On the one hand, the equipment has become quite productive and inexpensive at the same time, while providing extremely low latencies (hundreds of nanoseconds - this is not fiction, but quite a reality). But on the other hand, the tasks themselves became so when a centralized architecture becomes suboptimal.
What does Leaf-Spine provide when applied to the structures we are considering?
- The ability to rely on ECMP (_ which since March 2014 has been uniquely defined and recognized as the IEEE 802.1Qbp_ standard) in a continuous IP factory;
- Facilitation of equipment failure elimination due to its homogeneity;
- Predictable latency;
- Featuring scalability;
- Ease of control automation;
- Less drop in network bandwidth during equipment failure;
- TOR (Top of Rack) instead of EOR (End of Row). You can read about the specifics of TOR and EOR in this rather old, but still relevant article )
Do you want bonuses? You are welcome:
- The circuit is by default protected from loops and does not require STP;
- If the port does not respond, the routing protocol considers it dropped out and does not consider the possibility of its participation in the routes, unlike STP.
To what extent can such networks be expanded? A two-level network on common and inexpensive switches with forty-eight 10G ports and six 40G uplinks (Overprovisioning Ratio 1.6 when placing forty servers per rack) allows you to connect up to 1920 servers. Entering the third level increases this figure to 180 thousand. If this is not enough for you, levels can be increased further.
Is it possible and worth using this architecture on networks of much smaller sizes? Why not, if, of course, your project does not have any specific requirements specifically for L2 routing. Calculate the cost of a classic solution and Leaf-Spine on BMS switches. And if the latter is clearly winning for you - this is a good reason to think, right? :)
Of course, in addition to this, one more condition must be fulfilled, which was fundamental when we talked about the need to change the concept of the network: the traffic in it should be mostly horizontal, the nodes are relatively equal in terms of traffic consumption, there is no clearly distinguished direction in which the overwhelming part of the data volume. This does not mean at all that such a network should not have external connections, but traffic towards them should be commensurate with flows between nodes, and not be the main component.
We, in turn, are ready to offer you everything you need for this.

Eos 420

Eos 520
For example, cost-effective switches without a
pre-installed OS (Bare Metal Switch) on Trident II matrices, the price of a 10G port on which is less than $ 100: ETegro Eos 420 (48 10G + 6 40G) for Leaf and Eos 520 (32 40G) for Spine level.
Well and if necessary, provide their network operating system Cumulus Linux, about the capabilities of which we wrote a little earlier .
Bare Metal Switch
Why are we advocating for BMS versions of network equipment? Yes, simply because in our opinion, only it is able to provide the flexibility necessary for modern projects at the same time by choosing an OS with the necessary set of functions, and low cost of ownership due to the refusal to pay sometimes extremely expensive, but absolutely unnecessary vendor-specific features. It is unlikely that anyone will dispute the convenience of the fact that you can buy a server from one manufacturer, put the OS of another on it, and supplement it with third-party software. In our opinion, the time has come to bring this ideology of open systems to the world of network equipment.
If you want to "touch" such switches and see what open network OSs are capable of - write, we have the opportunity to organize testing.