Divide and update! We save the place, time and resources of the 1C server
The last time we told you how to change our infrastructure and how to work with databases 1C, of which we have countless already five hundred, and about how we automate work with so many data. However, there are still difficulties and crutches, and with the growing number of Buttons customers, we have to come up with new and improve old optimization methods. One of the main problems when working with a large number of 1C databases is rolling updates. Today we will talk about data sharing technology, which allows you to reduce the number of databases and simplify their maintenance.

It’s quite difficult to find documentation on the database separation mechanism: there is a short article on the foundational sitebut she brought us little benefit. There is a good old Google , but in order to understand the intricacies, you have to spend hours searching for the right piece of information for hours. We had no other choice, and now you have this article. We hope it comes in handy.
When working with 1C, you have to update a lot: configuration, KLADR, bank lists (depriving them of licenses, you know), exchange rates (oh, these economically unstable euros and dollars), user lists, processing, version of the platform. On good hardware, updating the KLADR with all regions for one base takes about half an hour. Updating the configuration takes from 10 minutes to several hours (when rolling a bundle).
When the base is one, two, ten, all this can be done in the form of daily routine work. When a few dozen - it takes a lot of time, but you can cope. When there are hundreds of bases, and theSiberian summer is the last day of reporting, it may happen that it is simply physically impossible to update all the bases - there will not be enough time and server resources.
Do not forget that Her Majesty lives in each separate database. A configuration that does not differ from base to base by one byte. Lives and eats a place, despite the fact that the configuration also needs to upload changes, insert processing and expand standard functionality.
So, if you have several bases (with the exception of organizations) of no different bases, with the same configuration, the separation mechanism can make life much easier (not without tar, but more on that later). Otherwise, very soon you will have to hire an army of admins :)
First, you need to determine the sign by which you will share the base. The separator can have any type of data, we use a string of 10 characters: ITN of the organization. The main thing is that the name of the separator (general attribute) should not coincide with the existing configuration objects, that is, it cannot be called, for example, “Organization”, since there is already such a directory. We called the separator "Group of Companies".
After that, we take your typical configuration with an empty base, go to the configurator and open the "General details" section. Add the general requisite and change the value "Data Sharing" to "Share":
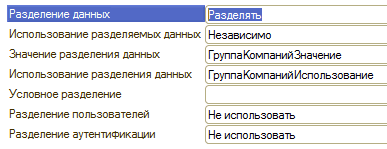
The configurator will offer to create session parameters - we silently agree and move on. After creating the “General requisite” with the separation property turned on, the database becomes like a multi-storey building. The house has elements accessible to everyone and from each floor: elevator, flight of stairs, communications, but there issomething unique, available only within the floor: apartments, corridor, windows. The metaphor is simple, and, I hope, understandable :)
To enter a specific organization (or area of the database), you must tell the separator in the connection string to the database or specify it in the v8i file (which we talked about last time ).
After / Z we indicate the general details in order. Since in our standard bookkeeping there are already two common system details, we indicate a value of -0 for them so that they are not used, and as the third (which we created) we transfer the TIN.
Now you need to determine how much of the data will be common to all areas. All this is configured through the configurator. In the properties of the general attribute that we just created, there is a “Composition” item that opens a small list of 800 parameters: We

leave the selection of parameters to your discretion, discretion and environment. Here is our version (more accurately, there are 20,000 pixels).
The separator also makes it possible to set up a separate list of users for each database - this can come in handy if you have hundreds of users - when you enter a specific database, you don’t have to scroll this list to bloody corns. We do not use this because we have set up transparent authorization.
To unload data from current databases, we use universalXML-exchange . You can’t just take and unload the database, you need to set up the exchange rules, otherwise, during the download, errors and conflicts may (and must occur), and the second database just won’t crawl through. Recall that we divide the base area for each organization and in our case such exchange rules work . If you decide to use another separator, you have to scratch your brain and checkboxes. The main thing is not to use standard unloading - this will lead to duplication of all predefined records.
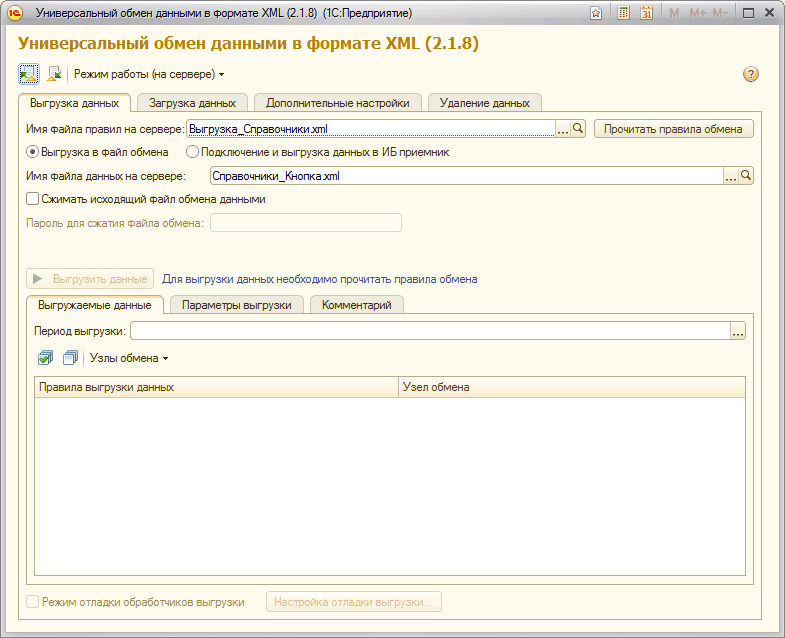
We start 1C with the / Z parameter “-0, -0, +% your separator%”, indicating the separator of the organization whose data we are going to load. We launch a universal exchange and feed it the files received during unloading: first, directories, then documents. Repeat this operation for eachbase region .
To simplify the task, we perform bulk unloading, pre-launching slightly corrected standard processing via the command line (/ Execute c: unload.epf). Then manually load the received files into a divided database.
The separation process is not a quick thing. Recall that we now have more than 500 organizations, but in a couple of weeks we managed to split only 70. However, we know for sure that in six months we will thank the past ourselves for the work done and a lot of time and effort saved. Buttons
accountants do not notice the transition of organizations from a regular database to a divided one; for them, the process is painless. The priest burns only for admins :) Side effects: saving space 1 in 20, an indirect increase in the speed of work is invaluable. In absolute terms: 50 organizations occupy 2 GB of space in SQL, while one separate database takes up from 800 MB.
The first three spoons are not so bitter - they just make us be more attentive. But what to do with the fourth, we do not yet know, but we are diligently exploring.
It’s quite difficult to find documentation on the database separation mechanism: there is a short article on the foundational sitebut she brought us little benefit. There is a good old Google , but in order to understand the intricacies, you have to spend hours searching for the right piece of information for hours. We had no other choice, and now you have this article. We hope it comes in handy.
Enough tolerating this!
When working with 1C, you have to update a lot: configuration, KLADR, bank lists (depriving them of licenses, you know), exchange rates (oh, these economically unstable euros and dollars), user lists, processing, version of the platform. On good hardware, updating the KLADR with all regions for one base takes about half an hour. Updating the configuration takes from 10 minutes to several hours (when rolling a bundle).
When the base is one, two, ten, all this can be done in the form of daily routine work. When a few dozen - it takes a lot of time, but you can cope. When there are hundreds of bases, and the
Do not forget that Her Majesty lives in each separate database. A configuration that does not differ from base to base by one byte. Lives and eats a place, despite the fact that the configuration also needs to upload changes, insert processing and expand standard functionality.
So, if you have several bases (with the exception of organizations) of no different bases, with the same configuration, the separation mechanism can make life much easier (not without tar, but more on that later). Otherwise, very soon you will have to hire an army of admins :)
Basic segregation
First, you need to determine the sign by which you will share the base. The separator can have any type of data, we use a string of 10 characters: ITN of the organization. The main thing is that the name of the separator (general attribute) should not coincide with the existing configuration objects, that is, it cannot be called, for example, “Organization”, since there is already such a directory. We called the separator "Group of Companies".
After that, we take your typical configuration with an empty base, go to the configurator and open the "General details" section. Add the general requisite and change the value "Data Sharing" to "Share":
The configurator will offer to create session parameters - we silently agree and move on. After creating the “General requisite” with the separation property turned on, the database becomes like a multi-storey building. The house has elements accessible to everyone and from each floor: elevator, flight of stairs, communications, but there is
To enter a specific organization (or area of the database), you must tell the separator in the connection string to the database or specify it in the v8i file (which we talked about last time ).
[Кнопка 7710967300 БУХ РБ]
Connect=Srvr="%servername%";Ref="%base_name%";
AdditionalParameters=/Z "-0,-0,+7710967300";
After / Z we indicate the general details in order. Since in our standard bookkeeping there are already two common system details, we indicate a value of -0 for them so that they are not used, and as the third (which we created) we transfer the TIN.
1000 and 1 checkbox
Now you need to determine how much of the data will be common to all areas. All this is configured through the configurator. In the properties of the general attribute that we just created, there is a “Composition” item that opens a small list of 800 parameters: We
leave the selection of parameters to your discretion, discretion and environment. Here is our version (more accurately, there are 20,000 pixels).
{kind=link}
The separator also makes it possible to set up a separate list of users for each database - this can come in handy if you have hundreds of users - when you enter a specific database, you don’t have to scroll this list to bloody corns. We do not use this because we have set up transparent authorization.
Unload data from current databases
To unload data from current databases, we use universal
Note to the hostess: directories and documents are better for unloading separately - this way you can avoid unnecessary errors at the time of loading.
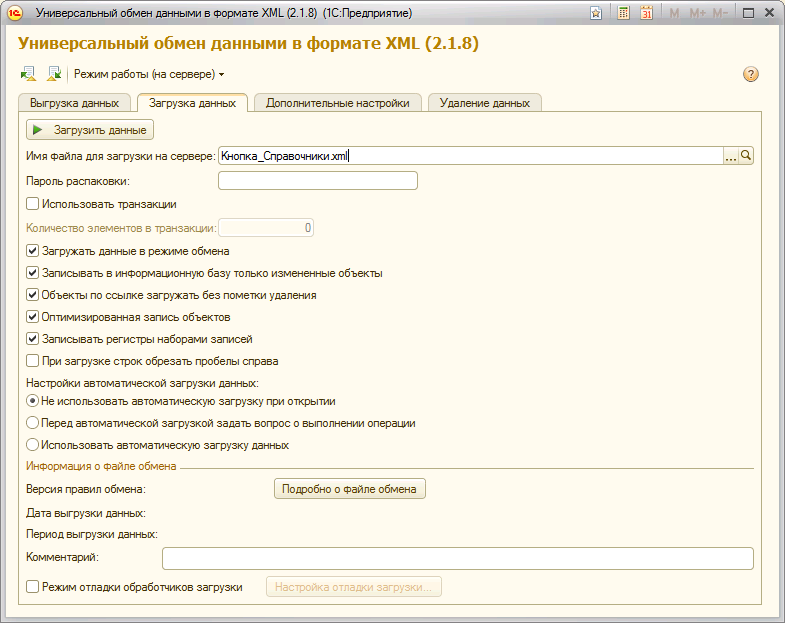
Loading data into a divided database
We start 1C with the / Z parameter “-0, -0, +% your separator%”, indicating the separator of the organization whose data we are going to load. We launch a universal exchange and feed it the files received during unloading: first, directories, then documents. Repeat this operation for each
To simplify the task, we perform bulk unloading, pre-launching slightly corrected standard processing via the command line (/ Execute c: unload.epf). Then manually load the received files into a divided database.
How to spend more time to spend less time
The separation process is not a quick thing. Recall that we now have more than 500 organizations, but in a couple of weeks we managed to split only 70. However, we know for sure that in six months we will thank the past ourselves for the work done and a lot of time and effort saved. Buttons
accountants do not notice the transition of organizations from a regular database to a divided one; for them, the process is painless. The priest burns only for admins :) Side effects: saving space 1 in 20, an indirect increase in the speed of work is invaluable. In absolute terms: 50 organizations occupy 2 GB of space in SQL, while one separate database takes up from 800 MB.
The promised fly in the ointment, even four:
- if
one of the users messed up data in one organization, you have to roll back the entire divided database - you can’t just take and roll back one data area - you have to test updates more thoroughly, especially those that add or modify directories
- if you need to transfer the database to the client (or merge the tax :), you have to do the reverse procedure: unload the organization from the divided database using universal exchange, then load it into an empty regular database and save it to.
dt file - in a divided database, you cannot manage scheduled tasks (for example, you cannot automatically update exchange rates)
The first three spoons are not so bitter - they just make us be more attentive. But what to do with the fourth, we do not yet know, but we are diligently exploring.