Advanced processor instructions in .NET or "C # Intrinsics"
In chess programs, “bitboards” (bitboards 1 , 2 ) are widely used to represent pieces on the board. As well as for other games on the same board 8 × 8, and even for card games. Various operations are often performed with bitboards, for example, finding the first set bit or counting the number of set bits. Many “tricky” algorithms were invented for these operations , and on modern processors some of these operations are available in an extended set of instructions . For example, popcnt , available in SSE4.2 ABM. There are also a couple of bsf / bsr instructions that have been available for a long time, but there is no access to them from the JIT compiler.
Of course, all serious chess programs are written in C ++, but I want to use C # for prototyping some algorithms, because I am better acquainted with it and I have less chance to shoot myself in the foot. But you also don’t want to lose performance just like that, in C / C ++ the instructions we are interested in are available with the so-called built - in functions . I tried to make a similar decision for C #.
There are ready-made libraries for SIMD instructions , but not for manipulations with bits.
What to do? It is necessary to patch the existing code somehow.
Let us dwell on the fact that we use a 64-bit processor (on a 32-bit one it is not so fun to work with bitboards), and this processor is x86_64. For incompatible architectures, you must have fallbacks (implementation in C #). Under such conditions, bsf / bsr will always be available, and popcnt is not available only on fairly ancient hardware, but more on that later.
The easiest option is to write a DLL in C ++ and export the functions we need from there. But these "functions" will consist of one instruction, and around them there will be several extra jumps that will occur during PInvoke.
The second option: use GetDelegateForFunctionPointer , it is similar to the first, but does not require a separate native DLL.
The third is to replace an already compiled method. Many interesting articles have been written about this . But here there are problems with the fact that it is a) difficult b) there are dependencies on the internals of the runtime, and therefore its version. As a result, we get a cumbersome and unstable solution, this is not our way.
The last option remains: patch the compiled JIT code.
First we need to make sure that the method is compiled: RuntimeHelpers.PrepareMethod () . And to get to the machine code, Microsoft carefully provided us with the RuntimeMethodHandle.GetFunctionPointer () method . But this link, depending on the runtime, may turn out to be both the method itself and the springboard for it. It is good that there is only one kind of springboard - JMP. We will use this:
So, we got the address, try to write something down there. It must be remembered Call-Convention, it is benefit to x86_64 one (the first four arguments in RCX, RDX, R8, R9, result in RAX):
We try ... Hooray, it works!
But now our version is no different in performance from PInvoke / GetDelegateForFunctionPointer: there are extra call / jmp from the calling method. In addition, if our fallback compiler function is inline, then the patch of this place will not help.
Inline can be pretty easily discarded using the [MethodImpl ( MethodImplOptions .NoInlining)])] attribute .
Also, as in C ++ - intrinsics, you need to completely abandon call / jmp. This is also quite easy to handle, however, you will have to get your hands dirty with assembler. We will patch the call place on the fly. To do this, we need to replace the code of our fallback not just with the necessary instructions, but by calling the "patcher" with the necessary parameters: at what address and what to replace.
Let's start by determining the address: we have the return address in the stack (in dword ptr [rax]), usually our method call happens just before it. If this is a call statement (and usually it is), then we need to check the previous 5 bytes, and if it really was a call to the desired method, then replace them entirely with the opcode of our instruction. The method patcher will look like this:
And we will call it manually from the assembler, as a result, our fallback method will be replaced with this thing:
The Patcher.PatchMethod function deals with all this, which we will call for all methods that need to be patched.
Here's what it looks like in a live example (from PerfTest):

(if the picture is not visible)
and after the first pass:

(if the picture is not visible)
Now there are little things left: JIT can inline something very strongly somewhere, or make tail-call optimization, then the return address will not really correspond to the call of our function. Unfortunately, I could not find examples of such aggressive optimizations, but just in case, this also needs to be checked. Knowing the place where the call was made from, we can verify what it actually called. Here, too, you need to jump over all the jmps and check that they will lead us to the right place. And due to the fact that we placed the replacement instructions at the very beginning of the patch unchanged, it is very easy to do this:
It’s also advisable for us not to touch anything if we suddenly find ourselves on an unsupported architecture. First, check that it is generally 64-bit: (IntPtr.Size == 8). Next, you need to make sure that this is x86_64. I did not find anything better than comparing the prologue of any function with obviously correct instructions (see Patcher.VerifyPrologue in the code).
Some instructions, such as popcnt , are not available on all processors. If speed is important to you, it is better not to use such processors at all, but it is advisable to leave a fall back for them in the library. The Intel manual says that you can check for the popcnt instruction by calling cpuid with eax = 01H and checking the ECX.POPCNT bit [Bit 23]. Here stackoverflow-driven development comes to our aid, where you can find a ready-made piece of code to callcpuid from C # .
It remains only to wrap it all up nicely: we make the attribute [ReplaceWith ("F3 48 0F B8 C1", Cpiud1ECX = 1 << 23)], which is glued to the fallback functions. It contains the code for which this intrinsic must be replaced, as well as the condition for the availability of the necessary instruction.
Benchmarks are quite primitive: we generate an array of pseudo-random numbers, then we chase each method 100 million times over it. To exclude the influence of the cycle and other tying, we first measure the time of an empty cycle. The special case of “sparse” boards was tested separately: quite often the board contains up to 8 pieces or marked cells, and on such boards the current selected folback should work out faster.
I measured and tested on two processors that were at hand: a notebook i7 and the good old Q6600. Here are the test details.
A summary table of results, the time of the "idle" cycle has already been subtracted:
As we can see, on the bsf / bsr instructions, our fallback is fast enough, so the gain from the intrinsic will be small, and even imperceptible, against the background of other parts of the algorithm. But popcnt is already much better, if you have Core i5 / i7, then it will accelerate dozens of times.
In relation to the final algorithm, I got acceleration of only 15%, because there is still a lot of code that not only counts bits. As they say, YMMV , check on your code.
The code can be taken on github .
github .
NuGet: Install-Package NetIntrinsics
Of course, all serious chess programs are written in C ++, but I want to use C # for prototyping some algorithms, because I am better acquainted with it and I have less chance to shoot myself in the foot. But you also don’t want to lose performance just like that, in C / C ++ the instructions we are interested in are available with the so-called built - in functions . I tried to make a similar decision for C #.
There are ready-made libraries for SIMD instructions , but not for manipulations with bits.
What to do? It is necessary to patch the existing code somehow.
Let us dwell on the fact that we use a 64-bit processor (on a 32-bit one it is not so fun to work with bitboards), and this processor is x86_64. For incompatible architectures, you must have fallbacks (implementation in C #). Under such conditions, bsf / bsr will always be available, and popcnt is not available only on fairly ancient hardware, but more on that later.
The easiest option is to write a DLL in C ++ and export the functions we need from there. But these "functions" will consist of one instruction, and around them there will be several extra jumps that will occur during PInvoke.
The second option: use GetDelegateForFunctionPointer , it is similar to the first, but does not require a separate native DLL.
The third is to replace an already compiled method. Many interesting articles have been written about this . But here there are problems with the fact that it is a) difficult b) there are dependencies on the internals of the runtime, and therefore its version. As a result, we get a cumbersome and unstable solution, this is not our way.
The last option remains: patch the compiled JIT code.
Implementation details
First we need to make sure that the method is compiled: RuntimeHelpers.PrepareMethod () . And to get to the machine code, Microsoft carefully provided us with the RuntimeMethodHandle.GetFunctionPointer () method . But this link, depending on the runtime, may turn out to be both the method itself and the springboard for it. It is good that there is only one kind of springboard - JMP. We will use this:
static byte* GetMethodPtr(MethodInfo method)
{
RuntimeHelpers.PrepareMethod(method.MethodHandle);
var ptr = (byte*)method.MethodHandle.GetFunctionPointer();
// skip all jumps
while (*ptr == 0xE9) {
var delta = *(int*)(ptr + 1) + 5;
ptr += delta;
}
return ptr;
}
So, we got the address, try to write something down there. It must be remembered Call-Convention, it is benefit to x86_64 one (the first four arguments in RCX, RDX, R8, R9, result in RAX):
//bsr rax, rcx; ret
*ptr++ = 0x48; *ptr++ = 0x0F; *ptr++ = 0xBD; *ptr++ = 0xC1; *ptr++ = 0xC3;
We try ... Hooray, it works!
But now our version is no different in performance from PInvoke / GetDelegateForFunctionPointer: there are extra call / jmp from the calling method. In addition, if our fallback compiler function is inline, then the patch of this place will not help.
Inline can be pretty easily discarded using the [MethodImpl ( MethodImplOptions .NoInlining)])] attribute .
Also, as in C ++ - intrinsics, you need to completely abandon call / jmp. This is also quite easy to handle, however, you will have to get your hands dirty with assembler. We will patch the call place on the fly. To do this, we need to replace the code of our fallback not just with the necessary instructions, but by calling the "patcher" with the necessary parameters: at what address and what to replace.
Let's start by determining the address: we have the return address in the stack (in dword ptr [rax]), usually our method call happens just before it. If this is a call statement (and usually it is), then we need to check the previous 5 bytes, and if it really was a call to the desired method, then replace them entirely with the opcode of our instruction. The method patcher will look like this:
static void PatchCallSite(byte* rsp, ulong code)
{
var ptr = rsp - 5;
// check call opcode
if (*ptr != 0xE8) {
// throw ERROR
}
const ulong Mask5Bytes = (1uL << 40) - 1;
*(ulong*)ptr = *(ulong*)ptr & ~Mask5Bytes | (code & Mask5Bytes);
}
And we will call it manually from the assembler, as a result, our fallback method will be replaced with this thing:
bsr rax, rcx ; заменяющая инструкция
nop ; дополним до 5 байт
push rax ; сохраним её ответ
sub rsp, 0x20 ; место под register spilling
mov rcx, QWORD PTR [rsp+0x28] ; первый аргумент — адрес возврата
; он был на стэке при входе в функию,
; а сейчас «уполз» на 0x20 + 8 байт
mov rdx, QWORD PTR [rip-0x16] ; второй аргумент — на что менять
; ссылается на начало этого куска кода
movabs rax,
call rax
add rsp, 0x20 ; поправляем стэк обратно
pop rax ; достаём из него ответ
ret
The Patcher.PatchMethod function deals with all this, which we will call for all methods that need to be patched.
Here's what it looks like in a live example (from PerfTest):
(if the picture is not visible)
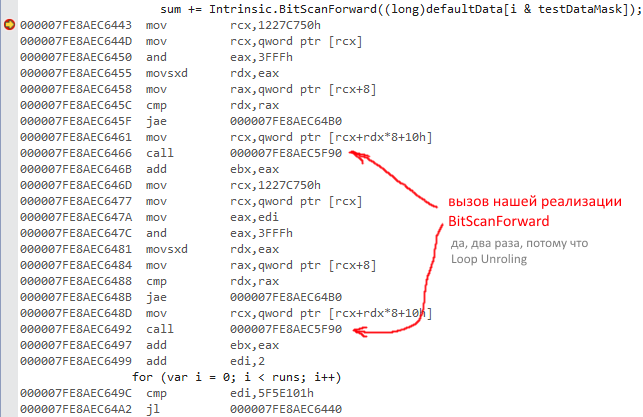{kind=link}
and after the first pass:
(if the picture is not visible)
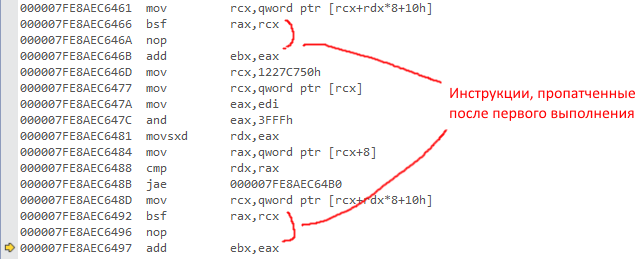{kind=link}
Now there are little things left: JIT can inline something very strongly somewhere, or make tail-call optimization, then the return address will not really correspond to the call of our function. Unfortunately, I could not find examples of such aggressive optimizations, but just in case, this also needs to be checked. Knowing the place where the call was made from, we can verify what it actually called. Here, too, you need to jump over all the jmps and check that they will lead us to the right place. And due to the fact that we placed the replacement instructions at the very beginning of the patch unchanged, it is very easy to do this:
// check call target
var calltarget = ptr + *(int*)(ptr + 1) + 5;
while (*calltarget == 0xE9) {
var delta = *(int*)(calltarget + 1) + 5;
calltarget += delta;
}
code &= Mask5Bytes;
if ((*(ulong*)calltarget & Mask5Bytes) != code) {
// throw ERROR
}
It’s also advisable for us not to touch anything if we suddenly find ourselves on an unsupported architecture. First, check that it is generally 64-bit: (IntPtr.Size == 8). Next, you need to make sure that this is x86_64. I did not find anything better than comparing the prologue of any function with obviously correct instructions (see Patcher.VerifyPrologue in the code).
Some instructions, such as popcnt , are not available on all processors. If speed is important to you, it is better not to use such processors at all, but it is advisable to leave a fall back for them in the library. The Intel manual says that you can check for the popcnt instruction by calling cpuid with eax = 01H and checking the ECX.POPCNT bit [Bit 23]. Here stackoverflow-driven development comes to our aid, where you can find a ready-made piece of code to callcpuid from C # .
It remains only to wrap it all up nicely: we make the attribute [ReplaceWith ("F3 48 0F B8 C1", Cpiud1ECX = 1 << 23)], which is glued to the fallback functions. It contains the code for which this intrinsic must be replaced, as well as the condition for the availability of the necessary instruction.
Benchmarks
Benchmarks are quite primitive: we generate an array of pseudo-random numbers, then we chase each method 100 million times over it. To exclude the influence of the cycle and other tying, we first measure the time of an empty cycle. The special case of “sparse” boards was tested separately: quite often the board contains up to 8 pieces or marked cells, and on such boards the current selected folback should work out faster.
I measured and tested on two processors that were at hand: a notebook i7 and the good old Q6600. Here are the test details.
i7-3667U
Testing Rng ... 78ms, sum = 369736839 Testing BitScanForward ... 123ms, sum = 99768073 Testing FallBack.BitScanForward ... 239ms, sum = 99768073 Testing PopCnt64 ... 106ms, sum = -1092098543 Testing FallBack.PopCnt64 ... 3143ms, sum = -1092098543 Testing PopCnt32 ... 106ms, sum = 1598980778 Testing FallBack.PopCnt32 ... 2139ms, sum = 1598980778 Testing PopCnt64 on sparse data ... 106ms, sum = 758117720 Testing FallBack.PopCnt64 on sparse data ... 952ms, sum = 758117720
Q6600
Patch status: Ok Feature PopCnt is not supported by this CPU Feature PopCnt is not supported by this CPU Testing Rng ... 92ms, sum = 369736839 Testing BitScanForward ... 154ms, sum = 99768073 Testing FallBack.BitScanForward ... 323ms, sum = 99768073 Testing PopCnt64 ... 3832ms, sum = -1092098543 Testing FallBack.PopCnt64 ... 3583ms, sum = -1092098543 Testing PopCnt32 ... 2414ms, sum = 1598980778 Testing FallBack.PopCnt32 ... 3249ms, sum = 1598980778 Testing PopCnt64 on sparse data ... 1662ms, sum = 758117720 Testing FallBack.PopCnt64 on sparse data ... 1076ms, sum = 758117720
A summary table of results, the time of the "idle" cycle has already been subtracted:
| bsf | bsf fallback | popcnt64 | popcnt64 fallback | popcnt32 | popcnt32 fallback | sparse popcnt64 | sparse popcnt64 fallback | |
|---|---|---|---|---|---|---|---|---|
| i7-3667U | 45ms | 161ms (~ 3.6x slower) | 28ms | 3065ms (~ 100x slower) | 28ms | 2061ms (~ 70x slower) | 28ms | 874ms (~ 30x slower) |
| Q6600 | 62ms | 231ms (~ 3.7x slower) | N / a | 3491ms | N / a | 3157ms | N / a | 984ms |
As we can see, on the bsf / bsr instructions, our fallback is fast enough, so the gain from the intrinsic will be small, and even imperceptible, against the background of other parts of the algorithm. But popcnt is already much better, if you have Core i5 / i7, then it will accelerate dozens of times.
In relation to the final algorithm, I got acceleration of only 15%, because there is still a lot of code that not only counts bits. As they say, YMMV , check on your code.
Where to get
The code can be taken on
NuGet: Install-Package NetIntrinsics