Backup a large number of heterogeneous web-projects
It would seem that the topic is beaten - much has been said and written about backup, so there is nothing to reinvent the wheel, just take it and do it. However, every time when the system administrator of a web project faces the task of setting up backups, for many it hangs in the air with a big question mark. How to collect backup data? Where to store backups? How to provide the necessary level of retrospective storage of copies? How to unify the backup process for the whole zoo of different software?

For ourselves, we first solved this problem in 2011. Then we sat down and wrote our backup scripts. For many years, we have used only them, and they have successfully ensured a reliable process of collecting and synchronizing backups of our clients' web projects. Backups were stored in our or some other external storage, with the possibility of tuning for a specific project.
I must say, these scripts have worked their full. But the further we grew, the more variegated projects we had with different software and external repositories that our scripts did not support. For example, we did not have support for Redis and MySQL and PostgreSQL “hot” backups, which appeared later. The process of backups was not monitored, there were only email-alerts.
Another problem was the support process. For many years, our once compact scripts have grown and turned into a huge awkward monster. And when we were going with the forces and released a new version, it was worth it to roll out an update for some of the customers who used the previous version with some kind of customization.
As a result, at the beginning of this year we made a strong-willed decision: to replace our old backup scripts with something more modern. Therefore, we first sat down and wrote out all the wishes for a new solution. It turned out about the following:
- Back up the most frequently used software:
- Files (discrete and incremental backups)
- MySQL (cold / hot backups)
- PostgreSQL (cold / hot backups)
- MongoDB
- Redis
- Store backups in popular repositories:
- Local
- FTP
- Ssh
- SMB
- Nfs
- WebDAV
- S3
- Receive alerts in case of any problems during the backup process
- Have a single configuration file that allows you to manage backups centrally
- Add support for new software through the connection of external modules
- Specify extra options for collecting dumps
- Have the ability to restore backups using standard tools.
- Ease of initial configuration
Analyzing existing solutions
We looked at open-source solutions that already exist:
- Bacula and its fork, for example, Bareos
- Amanda
- Borg
- Duplicaty
- Duplicity
- Rsnapshot
- Rdiff-backup
But each of them had its flaws. For example, Bacula is overloaded with unnecessary functions, the initial configuration is quite time-consuming because of the large amount of manual work (for example, for writing / searching database backup scripts), and for restoring copies you need to use special utilities, etc.
In the end, we came to two important conclusions:
- None of the existing solutions did not fully suit us;
- It seems that we ourselves had enough experience and madness to take up writing our decision.
So we did.
Birth nxs-backup
We chose Python as the language for implementation - it is easy to write and maintain, flexible and convenient. The configuration files were made to be described in the yaml format.
For the convenience of supporting and adding backups of new software, a modular architecture was chosen, where the process of collecting backups of each specific software (for example, MySQL) is described in a separate module.
Support for files, databases and remote repositories
Currently, support is provided for the following types of file backups, databases, and remote repositories:
DB:
- MySQL (hot / cold backups)
- PostgreSQL (hot / cold backups)
- Redis
- MongoDB
Files:
- Discrete copying
- Incremental backups
Remote repositories:
- Local
- S3
- SMB
- Nfs
- FTP
- Ssh
- WebDAV
Discrete backup
Either discrete or incremental backups are suitable for different tasks, so they implemented both types. You can specify which method to use at the level of individual files and directories.
For discrete copies (both files and databases), you can set a retrospective view in the format days / weeks / months.
Incremental backup
Incremental copies of files are made as follows: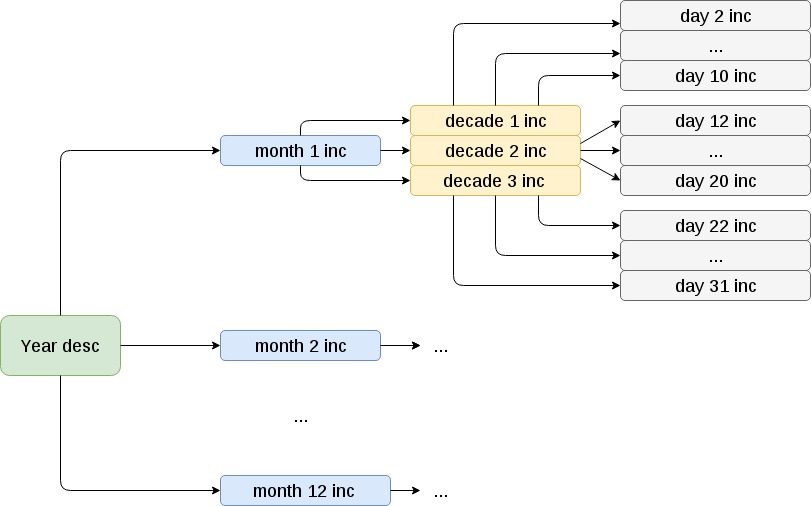
At the beginning of the year is going to full backup. Further, at the beginning of each month - an incremental monthly copy of a relatively annual. Inside the monthly - incremental decadal relative to the monthly. Inside each decade - incremental day relative to the decade.
It is worth mentioning that while there are some problems when working with directories that contain a large number of subdirectories (tens of thousands). In such cases, the collection of copies slows down significantly and can take more than a day. We are actively engaged in the elimination of this defect.
Recovering from incremental backups
There is no problem with restoring from discrete backups - just take a copy of the desired date and deploy it with the usual console tar. Incremental backups are a bit more complicated. To recover, for example, on July 24, 2018, you need to do the following:
- Expand a one-year backup, even if in our case it is counted from January 1, 2018 (in practice it can be any date, depending on when the decision was made to implement incremental backup)
- Roll on him a monthly backup for July
- Roll up the decade backup for July 21st
- Roll up a daily backup for July 24
At the same time, to execute 2-4 points, it is necessary to add the -G switch to the tar command, thereby indicating that this is an incremental backup. Of course, this is not the fastest process, but if you consider that recovering from backups is not so often economical and important, this scheme turns out to be quite effective.
Exceptions
Often you need to exclude individual files or directories from backups, for example, directories with a cache. This can be done by specifying the appropriate exception rules:
- target:
- /var/www/*/data/
excludes:
- exclude1/exclude_file
- exclude2
- /var/www/exclude_3Backups rotation
In our old scripts, the rotation was implemented so that the old copy was deleted only after the new one was assembled successfully. This led to problems on projects where, in principle, the space for backups was allocated to exactly one copy - a fresh copy could not be gathered there due to lack of space.
In the new implementation, we decided to change this approach: first remove the old one and only then collect a new copy. And the process of collecting backups put on monitoring to learn about the occurrence of any problems.
In the case of a discrete backup, the old copy is considered to be an archive that goes beyond the specified storage scheme in the format days / weeks / months. In the case of incremental backups, backups are stored by default for a year, and old copies are deleted at the beginning of each month, while archives for the same month of the previous year are considered old backups. For example, before collecting a monthly backup on August 1, 2018, the system will check if there are any backups for August 2017, and if so, delete them. This allows optimal use of disk space.
Logging
In any process, and especially in backups, it is important to keep your finger on the pulse and be able to find out if something went wrong. The system keeps a log of its work and records the result of each step: start / stop of funds, the start / end of a specific task, the result of collecting a copy in the temporary directory, the result of copying / moving a copy from the temporary directory to a permanent location, the result of backups rotation, etc. ..
Events are divided into 2 levels:
- Info : information level - the flight is normal, the next stage is completed successfully, the corresponding information record is made in the log
- Error : error level - something went wrong, the next stage ended abnormally, the corresponding error record is made in the log
E-mail notifications
At the end of the backup collection, the system can send out email notifications.
2 recipient lists are supported:
- Administrators - those who serve the server. They receive only error notifications; they are not interested in notifications of successful operations.
- Business users - in our case, these are customers who sometimes want to be notified to make sure that they are fine with backups. Or, conversely, not very. They can choose - to get the full log or only the log with errors.
Configuration File Structure
The structure of the configuration files is as follows:
/etc/nxs-backup
├── conf.d
│ ├── desc_files_local.conf
│ ├── external_clickhouse_local.conf
│ ├── inc_files_smb.conf
│ ├── mongodb_nfs.conf
│ ├── mysql_s3.conf
│ ├── mysql_xtradb_scp.conf
│ ├── postgresql_ftp.conf
│ ├── postgresql_hot_webdav.conf
│ └── redis_local_ftp.conf
└── nxs-backup.confHere /etc/nxs-backup/nxs-backup.conf is the main configuration file, which specifies the global settings:
main:
server_name: SERVER_NAME
admin_mail: project-tech@nixys.ru
client_mail:
- ''
mail_from: backup@domain.ru
level_message: error
block_io_read: ''
block_io_write: ''
blkio_weight: ''
general_path_to_all_tmp_dir: /var/nxs-backup
cpu_shares: ''
log_file_name: /var/log/nxs-backup/nxs-backup.log
jobs: !include [conf.d/*.conf]An array of jobs (jobs) contains a list of tasks (job), which are a description of what exactly to back up, where to store and in what quantity. As a rule, they are placed in separate files (one file per job), which are connected via include in the main configuration file.
They also took care of maximally optimizing the process of preparing these files and wrote a simple generator. Therefore, the administrator does not need to spend time searching for the config template for some service, for example, MySQL, but rather simply run the command:
nxs-backup generate --storage local scp --type mysql --path /etc/nxs-backup/conf.d/mysql_local_scp.confThe output is the file /etc/nxs-backup/conf.d/mysql_local_scp.conf :
- job: PROJECT-mysql
type: mysql
tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp
sources:
- connect:
db_host: ''
db_port: ''
socket: ''
db_user: ''
db_password: ''
auth_file: ''
target:
- all
excludes:
- information_schema
- performance_schema
- mysql
- sys
gzip: no
is_slave: no
extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob'
storages:
- storage: localenable: yes
backup_dir: /var/nxs-backup/databases/mysql/dump
store:
days: ''
weeks: ''month: ''
- storage: scp
enable: yes
backup_dir: /var/nxs-backup/databases/mysql/dump
user: ''
host: ''
port: ''password: ''
path_to_key: ''store:
days: ''
weeks: ''month: ''In which it remains only to substitute several necessary values.
Let us consider an example. Suppose we have on the server in the / var / www directory there are two platforms of an online store on 1C-Bitrix (bitrix-1.ru, bitrix-2.ru), each of which works from its database in different MySQL instances (port 3306 for bitrix_1_db and port 3307 for bitrix_2_db).
The file structure of a typical Bitrix project is approximately as follows:
├── ...
├── bitrix
│ ├── ..
│ ├── admin
│ ├── backup
│ ├── cache
│ ├── ..
│ ├── managed_cache
│ ├── ..
│ ├── stack_cache
│ └── ..
├── upload
└── ...As a rule, the upload directory weighs a lot, and only grows with time, so back it up incrementally. All other directories are discrete, with the exception of directories with a cache and backups collected by Bitrix native tools. Let the backup storage scheme for these two sites should be the same, while copies of files should be stored both locally and remotely in ftp storage, and the database should only be stored in remote smb storage.
The final configuration files for this setup will look like this:
- job: Bitrix-desc-files
type: desc_files
tmp_dir: /var/nxs-backup/files/desc/dump_tmp
sources:
- target:
- /var/www/*/
excludes:
- bitrix/backup
- bitrix/cache
- bitrix/managed_cache
- bitrix/stack_cache
- upload
gzip: yes
storages:
- storage: local
enable: yes
backup_dir: /var/nxs-backup/files/desc/dump
store:
days: 6
weeks: 4
month: 6
- storage: ftp
enable: yes
backup_dir: /nxs-backup/databases/mysql/dump
host: ftp_host
user: ftp_usr
password: ftp_usr_pass
store:
days: 6
weeks: 4
month: 6 - job: Bitrix-inc-files
type: inc_files
sources:
- target:
- /var/www/*/upload/
gzip: yes
storages:
- storage: ftp
enable: yes
backup_dir: /nxs-backup/files/inc
host: ftp_host
user: ftp_usr
password: ftp_usr_pass
- storage: local
enable: yes
backup_dir: /var/nxs-backup/files/inc - job: Bitrix-mysql
type: mysql
tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp
sources:
- connect:
db_host: localhost
db_port: 3306
db_user: bitrux_usr_1
db_password: password_1
target:
- bitrix_1_db
excludes:
- information_schema
- performance_schema
- mysql
- sys
gzip: no
is_slave: no
extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob'
- connect:
db_host: localhost
db_port: 3307
db_user: bitrix_usr_2
db_password: password_2
target:
- bitrix_2_db
excludes:
- information_schema
- performance_schema
- mysql
- sys
gzip: yes
is_slave: no
extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob'
storages:
- storage: smb
enable: yes
backup_dir: /nxs-backup/databases/mysql/dump
host: smb_host
port: smb_port
share: smb_share_name
user: smb_usr
password: smb_usr_pass
store:
days: 6
weeks: 4month: 6Parameters for running backup collection
In the previous example, we prepared job configuration files for collecting backups of all elements at once: files (discretely and incrementally), two databases and their storage in local and external (ftp, smb) storages.
It remains to run the whole thing. Start is made by command:
nxs-backup start $JOB_NAME -c $PATH_TO_MAIN_CONFIGThere are several reserved job names:
- files - random execution of all jobs with desc_files , inc_files types (that is, in fact, back up files only)
- databases - random execution of all jobs with the types mysql , mysql_xtradb , postgresql , postgresql_hot , mongodb , redis (that is, backing up only the database)
- external - randomly execute all jobs with external type (running only additional user scripts, more on this below)
- all - imitation of running the command in turn with job files , databases , external (default value)
Since we need to get backups of data from both files and databases as of the same time (or with a minimum difference), it is recommended to run nxs-backup with job all , which will ensure consistent execution of the described job (Bitrix-desc- files, Bitrix-inc_files, Bitrix-mysql).
That is, an important point - backups will not be collected in parallel, but sequentially, one after the other, with the minimum time difference. Moreover, the software itself at the next launch checks for the presence of an already running process in the system and, if it is detected, will automatically finish its work with a corresponding note in the log. This approach significantly reduces the load on the system. Minus - backups of individual elements are not collected at once, but with some time difference. But so far our practice shows that this is not critical.
External modules
As mentioned above, thanks to the modular architecture, the capabilities of the system can be expanded using additional user modules that interact with the system through a special interface. The goal is to be able to add support for backups of new software in the future without having to rewrite nxs-backup.
- job: TEST-externaltype: external
dump_cmd: ''
storages:
….Particular attention should be paid to the key dump_cmd , where the full command for running the external script is specified as the value. At the same time, upon completion of the execution of this command, it is expected that:
- A complete software data archive will be compiled.
- Data will be sent to stdout in json format, like:
{ "full_path": "ABS_PATH_TO_ARCHIVE", "basename": "BASENAME_ARCHIVE", "extension": "EXTERNSION_OF_ARCHIVE", "gzip": true/false }- In this case, the keys basename , extension , gzip are necessary exclusively for the formation of the final name of the backup.
- In case of successful completion of the script, the return code should be 0 and any other in case of any problems.
For example, suppose we have a script for creating snapshot etcd /etc/nxs-backup-ext/etcd.py :
#! /usr/bin/env python3# -*- coding: utf-8 -*-import json
import os
import subprocess
import sys
import tarfile
defarchive(snapshot_path):
abs_tmp_path = '%s.tar' %(snapshot_path)
with tarfile.open(abs_tmp_path, 'w:') as tar:
tar.add(snapshot_path)
os.unlink(snapshot_path)
return abs_tmp_path
defexec_cmd(cmdline):
data_dict = {}
current_process = subprocess.Popen([cmdline], stdout=subprocess.PIPE,
stderr=subprocess.PIPE, shell=True,
executable='/bin/bash')
data = current_process.communicate()
data_dict['stdout'] = data[0][0:-1].decode('utf-8')
data_dict['stderr'] = data[1][0:-1].decode('utf-8')
data_dict['code'] = current_process.returncode
return data_dict
defmain():
snapshot_path = "/var/backups/snapshot.db"
dump_cmd = "ETCDCTL_API=3 etcdctl --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/member-node1.pem"+\
" --key=/etc/ssl/etcd/ssl/member-node1-key.pem --endpoints 'https://127.0.0.1:2379' snapshot save %s" %snapshot_path
command = exec_cmd(dump_cmd)
result_code = command['code']
if result_code:
sys.stderr.write(command['stderr'])
else:
try:
new_path = archive(snapshot_path)
except tarfile.TarError as e:
sys.exit(1)
else:
result_dict = {
"full_path": new_path,
"basename": "etcd",
"extension": "tar",
"gzip": False
}
print(json.dumps(result_dict))
sys.exit(result_code)
if __name__ == '__main__':
main()The config for running this script is as follows:
- job: etcd-externaltype: external
dump_cmd: '/etc/nxs-backup-ext/etcd.py'
storages:
- storage: local
enable: yes
backup_dir: /var/nxs-backup/external/dump
store:
days: 6
weeks: 4
month: 6At the same time, the program when running job etcd-external :
- Run the /etc/nxs-backup-ext/etcd.py script with no parameters
- After completion of the script, check the completion code and the availability of the necessary data in stdout
- If all the checks were successful, the same mechanism will be further used as in the operation of already built-in modules, where the tmp_path is the value of the full_path key. If not, complete the task with the corresponding mark in the log.
Support and update
The process of developing and maintaining a new backup system has been implemented for all CI / CD canons. No more updates and script edits on the combat servers. All changes pass through our central git-repository in Gitlab, where the pipeline contains the assembly of new versions of deb / rpm-packages, which are then uploaded to our deb / rpm repositories. And after that through the package manager are delivered to the destination server clients.
How to download nxs-backup?
We did nxs-backup open-source project. Anyone can download and use it to organize the backup process in their projects, as well as modify to fit their needs, write external modules.
The source code for nxs-backup can be downloaded from the Github repository via this link . There is also a guide for installation and configuration.
We also prepared a Docker image and uploaded it to DockerHub .
If in the process of setting up or using any questions, please contact us. We will help to understand and refine the instructions.
Conclusion
In the near future we have to implement the following functionality:
- Integration with monitoring
- Backup Encryption
- Web interface for managing backup settings
- Expanding backups using nxs-backup
- And much more