How to solve user problems not in a day, but in minutes: we speed up the search by logs
We at Mail.Ru Mail are constantly faced with the need to work with user history. Considering that the monthly audience of the project is more than 40 million people, the history of all their actions is about a petabyte of data. We need to search the logs hundreds of times a day, and on average it took several hours to get the necessary information. In this case, according to our assumptions, the extraction of information from the logs could be accelerated to several seconds.
To evaluate the feasibility of developing a system for optimizing log searches, we used this table with XKCD : (actually not, but we like it anyway).
So, we seriously started optimization. The result of our work was the development of a system thanks to which we can raise the history of actions approximately 100,000 (one hundred thousand, this is not a typo) times faster. We have developed a big-data service that allows you to store petabytes of information in a structured form: each key we have corresponds to a log of some events. The storage is arranged in such a way that it is able to work on the cheapest SATA disks, and on large multi-disk storages with a minimum amount of processor time, while it is completely fault-tolerant - if any machine crashes, it’s nothing affects. If the system runs out of space, a server or several is simply added to it: the system will automatically see them and begin to record data. Reading data occurs almost instantly.
Why is this needed? Let's say something is not working for the user. To reproduce the error, we need to know the whole background: where the person went, which buttons and links he clicked on. Also, logs are necessary for making decisions in such cases as hacking a user account, when it is important to separate the actions of the user and the attacker.
Accordingly, the response speed of the technical support of the service is “tied” to the speed of searching through the logs.
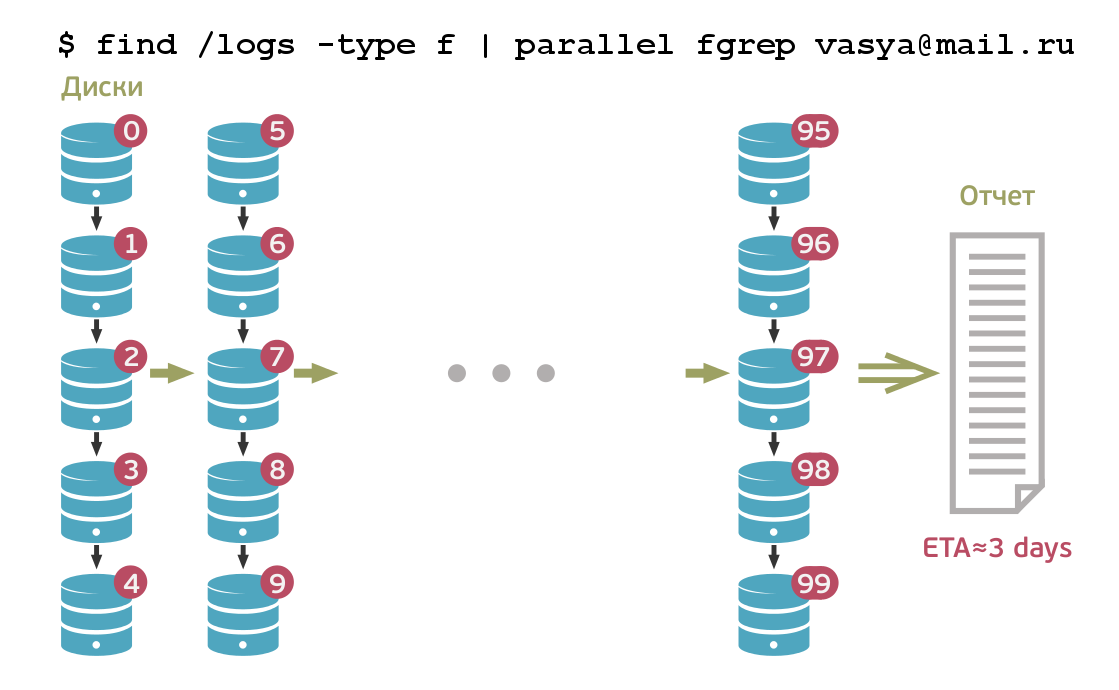
A few terabytes of logs can accumulate during the working day of a large system, especially considering that our company has many "complex" services. Suppose a user went to mail, mail turned to a database, a database went to a storage system, she also wrote logs ... To understand what the user did, all this data needs to be collected in a heap. For this, the good old grep command is used, from which the word "grab" came from. To solve the problem of one user, we eat, for example, a terabyte. This process can take several hours. We became preoccupied with this problem and began to think how to process this data much faster.
The problem is that complete separate systems for storing and processing logs that correspond to our tasks do not yet exist. For example, Hadoop (like any other MapReduce implementation) can simultaneously log logs and collect results together. But, since in Mail and Mail.Ru Cloud the amount of logs that need to be stored is estimated in petabytes, even parallel processing of such a volume will require a lot of time. In addition, with grep, you need to go over several terabytes per day, and with grep during the week this volume can grow up to a dozen terabytes. Plus, if you need to grab a large number of different logs, then to solve just one problem, you may need to grab several tens of terabytes of logs.
Hard disks can linearly record information at a speed of about 100 Mbps. However, fast recording implies unstructured, non-optimal placement of information. And for fast reading of files it is necessary that they be structured in a certain way. We needed to ensure the high speed of both processes. A large amount of information is constantly stored in the logs, while we need to quickly collect statistics for a specific user in order to quickly solve the problems that arise from him, providing high-quality technical support.
One could go the simplest way by organizing the storage of logs in a database. But this is a very, very expensive solution, because it requires the use of SSDs, database sharding, and creating replicas. We wanted to find a solution that would allow us to work with the cheapest storage on slow disks of enormous size.
Taking all these factors into account, it was decided to write a system from scratch that would speed up the process of grafting. By the way, as far as we know, she has no analogues not only in Russia, but also in the world.
The system that we created for this is organized as follows. From the point of view of the programmer, it performs, in fact, two operations: creating a record for a specific user (ID and time) and retrieving the entire history for a specific user.
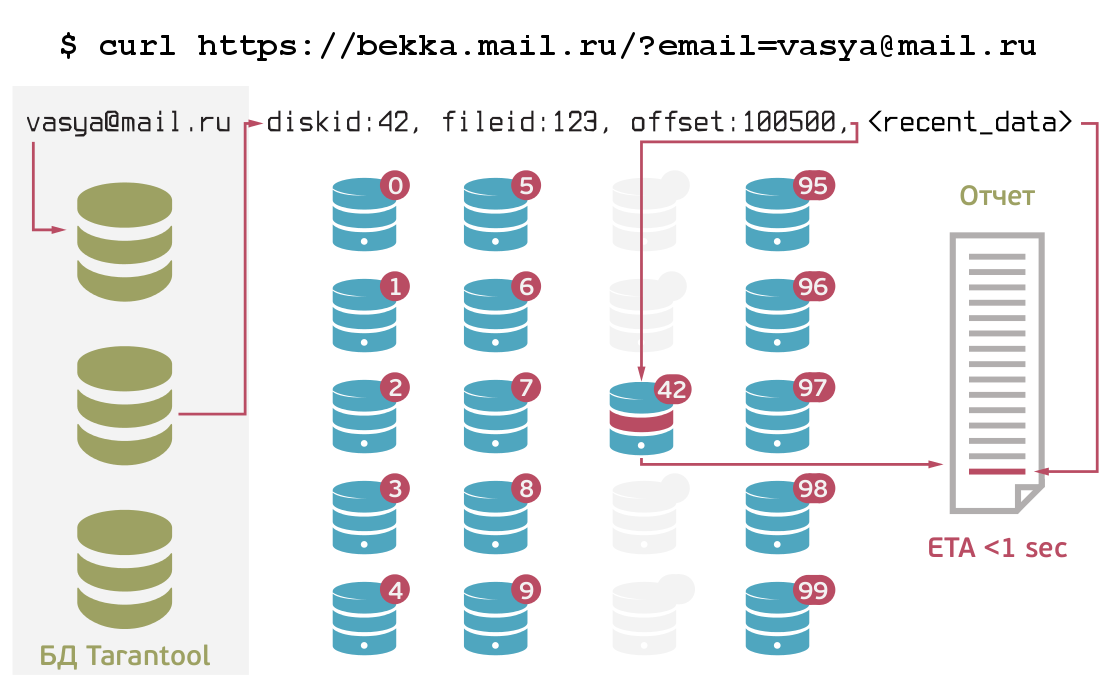
Recording is done in our Tarantool database. In it, all information is always stored in one file, and reading is carried out from memory. The base is sharded for several instances. Logs themselves are stored on multi-disk servers. Since Tarantool stores everything both in memory and on disk, it is clear that this cannot continue indefinitely. Therefore, a process is periodically started that groups user data from Tarantool and writes it to files on servers, and puts a link to this data in the database.
Thus, Tarantool stores only a recent history of users (accordingly, it can be quickly retrieved). And the "old" data is stored on disks in one large file, well-structured and suitable for quick reading. Thanks to this, the entire story for any user can be obtained in seconds. For comparison: before that, grabbing a weekly period for one user took about three days.
Each disk contains several files, in which all information for different users is written in a row. To prevent Tarantool from overflowing, the following is done: a process that reads all these files sequentially takes information about the user from the entire file, adds what is in Tarantool to it, and writes it all back to the end of the file. This whole system is also sharded and replicated, that is, there can be any number of servers, because every time we rewrite the user's history, we always write it to two disks, which are chosen randomly. After successful pair recording, the link is saved in Tarantool. Thus, even if one of the servers falls, the information does not disappear. When adding a new server, it is written into the system configuration,
Now this system is used in Mail and Mail.Ru Cloud. In the near future, we plan to introduce it in Mail.Ru for Business, and then gradually on other projects.
I will give some examples of how effective the system we created is.
Quite a frequent case: the user complains about the loss of letters from the mailbox. We take up the story and see when and from which programs he deleted them. Suppose we see that the letters were deleted from a certain IP address through POP3, from which we conclude that the user connected a POP3 client and chose the option “Download all letters and delete them from the server” - that is, in fact emails were deleted by the user, and not “disappeared themselves”. Thanks to our systematized log storage system, we can establish this fact and demonstrate it to the user in a matter of seconds. Saving the time of admins and support is gigantic.
Another example: we receive a complaint from a user who cannot open an email. Having raised all the logs for this user, we can literally within a few seconds see when and what server calls were made, what user agents, what happened on the client side. Thanks to this, we can more easily and, most importantly, much faster establish what the problem is.
Another case - the user complains that he can not enter the mailbox. We begin to look for the reason - it turns out that the account was automatically blocked for spamming. Here you need to figure out exactly who the spam is - the user himself or someone else on his behalf, and for this you will have to analyze the entire history of using the mailbox for a long period (perhaps a week, a month or even more). Glancing at the story, we see that, starting from a certain date, they went into his box from a suspicious (that is, “non-native” for the user) region. Obviously, he was just hacked. Moreover, data collection and analysis did not take a day, but a few seconds: a technical support officer simply clicked on a button and received comprehensive information. The user changed the password for the box and again got access to it.
In a word, our system saves us a lot of time every day, while allowing us to reduce the response time to the user - in my opinion, this is win. We will tell about other ways of its application in the following posts.
To evaluate the feasibility of developing a system for optimizing log searches, we used this table with XKCD : (actually not, but we like it anyway).
So, we seriously started optimization. The result of our work was the development of a system thanks to which we can raise the history of actions approximately 100,000 (one hundred thousand, this is not a typo) times faster. We have developed a big-data service that allows you to store petabytes of information in a structured form: each key we have corresponds to a log of some events. The storage is arranged in such a way that it is able to work on the cheapest SATA disks, and on large multi-disk storages with a minimum amount of processor time, while it is completely fault-tolerant - if any machine crashes, it’s nothing affects. If the system runs out of space, a server or several is simply added to it: the system will automatically see them and begin to record data. Reading data occurs almost instantly.
What's the catch?
Why is this needed? Let's say something is not working for the user. To reproduce the error, we need to know the whole background: where the person went, which buttons and links he clicked on. Also, logs are necessary for making decisions in such cases as hacking a user account, when it is important to separate the actions of the user and the attacker.
Accordingly, the response speed of the technical support of the service is “tied” to the speed of searching through the logs.
A few terabytes of logs can accumulate during the working day of a large system, especially considering that our company has many "complex" services. Suppose a user went to mail, mail turned to a database, a database went to a storage system, she also wrote logs ... To understand what the user did, all this data needs to be collected in a heap. For this, the good old grep command is used, from which the word "grab" came from. To solve the problem of one user, we eat, for example, a terabyte. This process can take several hours. We became preoccupied with this problem and began to think how to process this data much faster.
The problem is that complete separate systems for storing and processing logs that correspond to our tasks do not yet exist. For example, Hadoop (like any other MapReduce implementation) can simultaneously log logs and collect results together. But, since in Mail and Mail.Ru Cloud the amount of logs that need to be stored is estimated in petabytes, even parallel processing of such a volume will require a lot of time. In addition, with grep, you need to go over several terabytes per day, and with grep during the week this volume can grow up to a dozen terabytes. Plus, if you need to grab a large number of different logs, then to solve just one problem, you may need to grab several tens of terabytes of logs.
Hard disks can linearly record information at a speed of about 100 Mbps. However, fast recording implies unstructured, non-optimal placement of information. And for fast reading of files it is necessary that they be structured in a certain way. We needed to ensure the high speed of both processes. A large amount of information is constantly stored in the logs, while we need to quickly collect statistics for a specific user in order to quickly solve the problems that arise from him, providing high-quality technical support.
One could go the simplest way by organizing the storage of logs in a database. But this is a very, very expensive solution, because it requires the use of SSDs, database sharding, and creating replicas. We wanted to find a solution that would allow us to work with the cheapest storage on slow disks of enormous size.
Taking all these factors into account, it was decided to write a system from scratch that would speed up the process of grafting. By the way, as far as we know, she has no analogues not only in Russia, but also in the world.
How did we do this?
The system that we created for this is organized as follows. From the point of view of the programmer, it performs, in fact, two operations: creating a record for a specific user (ID and time) and retrieving the entire history for a specific user.
Recording is done in our Tarantool database. In it, all information is always stored in one file, and reading is carried out from memory. The base is sharded for several instances. Logs themselves are stored on multi-disk servers. Since Tarantool stores everything both in memory and on disk, it is clear that this cannot continue indefinitely. Therefore, a process is periodically started that groups user data from Tarantool and writes it to files on servers, and puts a link to this data in the database.
Thus, Tarantool stores only a recent history of users (accordingly, it can be quickly retrieved). And the "old" data is stored on disks in one large file, well-structured and suitable for quick reading. Thanks to this, the entire story for any user can be obtained in seconds. For comparison: before that, grabbing a weekly period for one user took about three days.
Each disk contains several files, in which all information for different users is written in a row. To prevent Tarantool from overflowing, the following is done: a process that reads all these files sequentially takes information about the user from the entire file, adds what is in Tarantool to it, and writes it all back to the end of the file. This whole system is also sharded and replicated, that is, there can be any number of servers, because every time we rewrite the user's history, we always write it to two disks, which are chosen randomly. After successful pair recording, the link is saved in Tarantool. Thus, even if one of the servers falls, the information does not disappear. When adding a new server, it is written into the system configuration,
Now this system is used in Mail and Mail.Ru Cloud. In the near future, we plan to introduce it in Mail.Ru for Business, and then gradually on other projects.
How it works?
We search the logs in two types of cases. Firstly, to solve technical problems. For example, a user complains that something is not working for him, and we need to quickly look at the whole history of his actions: what he did, where he went and so on. Secondly, if we suspect that a box has been hacked. As I said above, in this case the story is needed in order to divide the user's actions into his own and committed by the attacker.I will give some examples of how effective the system we created is.
Quite a frequent case: the user complains about the loss of letters from the mailbox. We take up the story and see when and from which programs he deleted them. Suppose we see that the letters were deleted from a certain IP address through POP3, from which we conclude that the user connected a POP3 client and chose the option “Download all letters and delete them from the server” - that is, in fact emails were deleted by the user, and not “disappeared themselves”. Thanks to our systematized log storage system, we can establish this fact and demonstrate it to the user in a matter of seconds. Saving the time of admins and support is gigantic.
Another example: we receive a complaint from a user who cannot open an email. Having raised all the logs for this user, we can literally within a few seconds see when and what server calls were made, what user agents, what happened on the client side. Thanks to this, we can more easily and, most importantly, much faster establish what the problem is.
Another case - the user complains that he can not enter the mailbox. We begin to look for the reason - it turns out that the account was automatically blocked for spamming. Here you need to figure out exactly who the spam is - the user himself or someone else on his behalf, and for this you will have to analyze the entire history of using the mailbox for a long period (perhaps a week, a month or even more). Glancing at the story, we see that, starting from a certain date, they went into his box from a suspicious (that is, “non-native” for the user) region. Obviously, he was just hacked. Moreover, data collection and analysis did not take a day, but a few seconds: a technical support officer simply clicked on a button and received comprehensive information. The user changed the password for the box and again got access to it.
In a word, our system saves us a lot of time every day, while allowing us to reduce the response time to the user - in my opinion, this is win. We will tell about other ways of its application in the following posts.