Virtualization²
In a previous article, I talked about Intel VT-x and the extensions of this technology to increase virtualization efficiency. In this article I will talk about what is offered to those who are ready to take another step: launch a VM inside a VM - nested virtualization.

Image source
So, once again about what you want to achieve and what stands in the way of happiness.
Who would think of running another virtual machine monitor running an already running monitor? In fact, in addition to purely academic curiosity, this also has practical applications, supported by already existing implementations in monitors [3, 5].
The theoretical possibility of virtualization as an imitation of the operation of one computer on another was shown by the fathers of computer technology. Sufficient conditions for effective, i.e. Rapid virtualization was also theoretically justified. Their practical implementation consisted in adding special processor modes. A virtual machine monitor (let's call it L0) can use them to minimize the overhead of managing guest systems.
However, if you look at the properties of the virtual processor visible inside the guest system, they will differ from those that the real physical one had: there will be no hardware support for virtualization in it! And the second monitor (let's call it L1), running on it, will be forced to programmatically simulate all the functionality that L0 had directly from the hardware, significantly losing performance.
The script that I described was called nested virtualization - nested virtualization. The following entities participate in it.
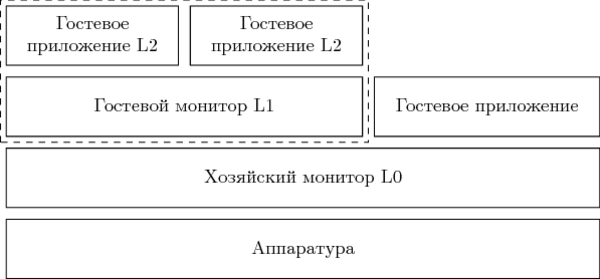
L0 and L1 are “bureaucratic” code, the execution of which is undesirable, but inevitable. L2 is the payload. The more time spent inside L2 and the less in L1 and L0, as well as in the transition state between them, the more efficiently the computing system works.
You can increase efficiency in the following ways:
So, the equipment does not directly support L2, and all the acceleration capabilities were used to ensure the operation of L1. The solution is to create a flat structure from guests L1 and L2.

In this case, the task of managing guests of both L1 and L2 is assigned to L0. For the latter, it is necessary to modify the control structures that control the transitions between root and non-root modes, so that the output occurs precisely in L0. This does not quite correspond to the ideas of L1 about what is happening in the system. On the other hand, as will be shown in the next paragraph of the article, L1 still does not have direct control over the transitions between modes, and therefore, if the flat structure is correctly implemented, none of the guests will be able to notice the substitution.
No, this is not something from the realm of crime and conspiracy theory. The adjective “shadow” for the elements of the architectural state is constantly used in all kinds of literature and documentation on virtualization. The idea is as follows. Ordinary GPR (English general purpose register) register, modified by the guest environment, cannot affect the correct operation of the monitor. Therefore, all instructions that work only with GPR can be executed directly by the guest. Whatever value it retains after leaving the guest, the monitor, if necessary, can always load a new post-factum value into the register. On the other hand, the CR0 system register determines, among other things, how virtual addresses for all memory accesses will be displayed. If the guest could write arbitrary values into it, then the monitor could not work normally. For this reason, a shadow is created - a copy of the operation-critical register stored in memory. All attempts of guest access to the original resource are intercepted by the monitor and emulated using values from the shadow copy.
The need for software modeling of work with shadow structures is one of the sources of loss of guest work productivity. Therefore, some elements of the architectural state receive hardware support for the shadow: in non-root mode, access to such a register is immediately redirected to its shadow copy.
In the case of Intel VT-x [1], at least the following processor structures get a shadow: CR0, CR4, CR8 / TPR (task priority register), GSBASE.
So, the implementation of the shadow structure for some architectural state in L0 can be purely software. However, the price for this will be the need to constantly intercept calls to it. So, in [2] it is mentioned that one exit from the “non-root” L2 to L1 does not cause about 40-50 real transitions from L1 to L0. A significant part of these transitions is caused by only two instructions - VMREAD and VMWRITE [5].
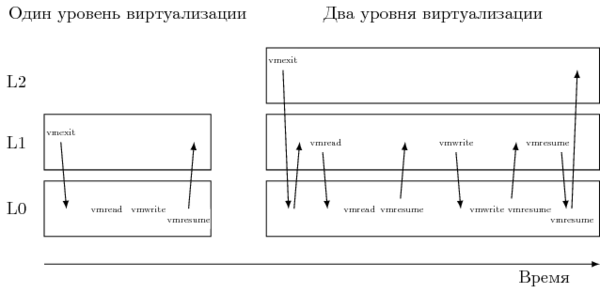
These instructions work on a VMCS (virtual machine control structure) framework that controls transitions between virtualization modes. Since the monitor L1 cannot be allowed directly to change it, the monitor L0 creates a shadow copy and then emulates working with it, intercepting these two instructions. As a result, the processing time of each output from L2 increases significantly.
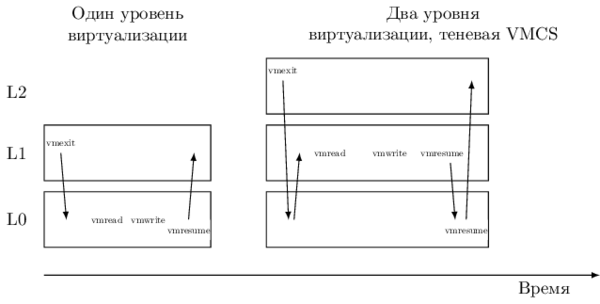
Therefore, in subsequent versions of Intel VT-x VMCS got a shadow copy - shadow VMCS. This structure is stored in memory, has the same contents as normal VMCS, and can be read / modified using VMREAD / VMWRITE instructions, including from non-root mode without generating VM-exit . As a result, a significant part of the transitions L1 → L0 is eliminated. However, shadow VMCS cannot be used to enter / exit non-root and root modes - the original VMCS managed by L0 is still used for this.
I note that the Intel EPT (English Extended Page Table) mentioned in the first part is also a hardware acceleration technique for working with another shadow structure used for address translation. Instead of monitoring the entire tree of guest translation tables (starting from the value of the CR3 privileged register) and intercepting attempts to read / modify it, it creates its own “sandbox” for it. These physical addresses are obtained after the translation of guest physical addresses, which is also done by the equipment.
In the case of embedded virtualization, as in the case of VMCS, we come to the same problem: now there are three translation levels (L2 → L1, L1 → L0 and L0 → physical address), but the hardware only supports two. This means that one of the levels of translation will have to be modeled programmatically.
If we model L2 → L1, then, as expected, this will lead to a significant slowdown. The effect will be even more significant than in the case of one level: each exception #PF (English page fault) and writing CR3 inside L2 will lead to the output in L0, and not in L1. However, if you notice [6] that guest L1 environments are created much less frequently than processes in L2, then you can make the broadcast (L1 → L0) programmatic (i.e. slow), and use the freed hardware (fast) EPT for L2 → L1 . This reminds me of an idea from the field of compiler optimizations: you should optimize the most nested code loop. In the case of virtualization, this is the most embedded guest.
Let's fantasize a bit about what might happen in the future. Further in this section are my own (and not so) ideas about how we can arrange the future virtualization. They may be completely bankrupt, impossible or inappropriate.

And in the future, the creators of VM monitors will want to dive even deeper - to bring recursive virtualization to the third, fourth and deeper levels of nesting. The techniques described above for supporting two levels of nesting become very unattractive. I'm not very sure that the same tricks can be repeated for effective virtualization, even the third level. The trouble is that the guest mode does not support re-entering yourself.
The history of computer technology recalls similar problems and suggests a solution. Early Fortran did not support recursive call of procedures because the state of local variables (activation record) was stored in statically allocated memory. Recalling an already executing procedure would erase this area, cutting off the exit from the procedure. The solution, implemented in modern programming languages, consisted of supporting a stack of records storing data of the called procedures, as well as the return address.
We see a similar situation for VMCS - an absolute address is used for this structure, the data in it belongs to the L0 monitor. The guest cannot use the same VMCS, otherwise he would risk losing the state of the host. If we had a stack or rather even a doubly linked listVMCS, in which each subsequent record would belong to the current monitor (as well as all its superiors), one would not have to resort to the tricks described above for transferring L2 under the command of L0. Exiting a guest would transfer control to his monitor while switching to the previous VMCS, and entering guest mode would activate the next one on the list.
The second feature that limits the performance of nested virtualization is the irrational processing of synchronous exceptions [7]. If an exception occurs within the embedded guest L N, control is always transferred to L0, even if his only task after this is to “lower” the processing of the situation to the monitor L closest to L N ( N-1) The descent is accompanied by an avalanche of state switching of all intermediate monitors.
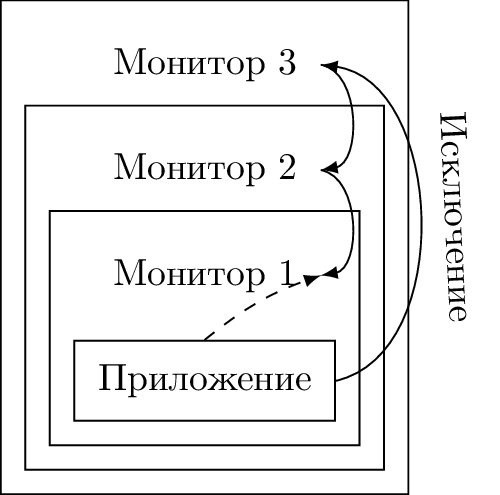
Effective recursive virtualization in architecture requires a mechanism that allows you to change the processing direction of some exceptional events: instead of a fixed order L0 → L ( N-1 ), synchronous interrupts can be directed L ( N-1 ) → L0. The intervention of external monitors is required only if more nested ones cannot handle the situation.
The topic of optimizations in virtualization (and indeed any optimizations in general) is inexhaustible - there will always be one more last frontier on the road to achieving maximum speed. In my three notes, I talked only about some Intel VT-x extensions and nested virtualization techniques and completely ignored the rest. Fortunately, researchers working on open and commercial virtualization solutions are quite willing to publish the results of their work. The materials of the annual conference of the KVM project, as well as the whitepaper of Vmware, are a good source of information on the latest achievements. For example, the issue of reducing the number of VM-exit caused by asynchronous interrupts from devices is discussed in detail in [8].
Thanks for attention!
Image source
{kind=link}
So, once again about what you want to achieve and what stands in the way of happiness.
What for
Who would think of running another virtual machine monitor running an already running monitor? In fact, in addition to purely academic curiosity, this also has practical applications, supported by already existing implementations in monitors [3, 5].
- Safe migration of hypervisors.
- Testing virtual environments before launch.
- Debugging hypervisors.
- Support for guest scripts with a built-in monitor, for example, Windows 7 with Windows XP Mode, or the development script for Windows Phone 8 mentioned on Habr .
The theoretical possibility of virtualization as an imitation of the operation of one computer on another was shown by the fathers of computer technology. Sufficient conditions for effective, i.e. Rapid virtualization was also theoretically justified. Their practical implementation consisted in adding special processor modes. A virtual machine monitor (let's call it L0) can use them to minimize the overhead of managing guest systems.
However, if you look at the properties of the virtual processor visible inside the guest system, they will differ from those that the real physical one had: there will be no hardware support for virtualization in it! And the second monitor (let's call it L1), running on it, will be forced to programmatically simulate all the functionality that L0 had directly from the hardware, significantly losing performance.
Nested virtualization
The script that I described was called nested virtualization - nested virtualization. The following entities participate in it.
- L0 is the first level monitor launched directly on the equipment.
- L1 is an embedded monitor that runs as a guest inside L0.
- L2 is a guest system running under L1.
L0 and L1 are “bureaucratic” code, the execution of which is undesirable, but inevitable. L2 is the payload. The more time spent inside L2 and the less in L1 and L0, as well as in the transition state between them, the more efficiently the computing system works.
You can increase efficiency in the following ways:
- Reduce delays in transitions between root and non-root modes. In new Intel microarchitectures, the duration of such a transition is slowly but surely decreasing.
- Reduce the number of exits from L2 by allowing more operations to be executed without generating VM-exit. Naturally, this will also speed up simple single-level virtualization scenarios.
- Decrease the number of exits from L1 to L0. As we will see later, part of the operations of a nested monitor can be performed directly, without going to L0.
- Teach L0, L1 to "negotiate" with each other. This leads us to the idea of paravirtualization, which involves modifying guest environments. I will not consider this scenario in this article (as “unsportsmanlike”), however, such solutions exist [4].
So, the equipment does not directly support L2, and all the acceleration capabilities were used to ensure the operation of L1. The solution is to create a flat structure from guests L1 and L2.
In this case, the task of managing guests of both L1 and L2 is assigned to L0. For the latter, it is necessary to modify the control structures that control the transitions between root and non-root modes, so that the output occurs precisely in L0. This does not quite correspond to the ideas of L1 about what is happening in the system. On the other hand, as will be shown in the next paragraph of the article, L1 still does not have direct control over the transitions between modes, and therefore, if the flat structure is correctly implemented, none of the guests will be able to notice the substitution.
Shadow structures
No, this is not something from the realm of crime and conspiracy theory. The adjective “shadow” for the elements of the architectural state is constantly used in all kinds of literature and documentation on virtualization. The idea is as follows. Ordinary GPR (English general purpose register) register, modified by the guest environment, cannot affect the correct operation of the monitor. Therefore, all instructions that work only with GPR can be executed directly by the guest. Whatever value it retains after leaving the guest, the monitor, if necessary, can always load a new post-factum value into the register. On the other hand, the CR0 system register determines, among other things, how virtual addresses for all memory accesses will be displayed. If the guest could write arbitrary values into it, then the monitor could not work normally. For this reason, a shadow is created - a copy of the operation-critical register stored in memory. All attempts of guest access to the original resource are intercepted by the monitor and emulated using values from the shadow copy.
The need for software modeling of work with shadow structures is one of the sources of loss of guest work productivity. Therefore, some elements of the architectural state receive hardware support for the shadow: in non-root mode, access to such a register is immediately redirected to its shadow copy.
In the case of Intel VT-x [1], at least the following processor structures get a shadow: CR0, CR4, CR8 / TPR (task priority register), GSBASE.
Shadow VMCS
So, the implementation of the shadow structure for some architectural state in L0 can be purely software. However, the price for this will be the need to constantly intercept calls to it. So, in [2] it is mentioned that one exit from the “non-root” L2 to L1 does not cause about 40-50 real transitions from L1 to L0. A significant part of these transitions is caused by only two instructions - VMREAD and VMWRITE [5].
These instructions work on a VMCS (virtual machine control structure) framework that controls transitions between virtualization modes. Since the monitor L1 cannot be allowed directly to change it, the monitor L0 creates a shadow copy and then emulates working with it, intercepting these two instructions. As a result, the processing time of each output from L2 increases significantly.
Therefore, in subsequent versions of Intel VT-x VMCS got a shadow copy - shadow VMCS. This structure is stored in memory, has the same contents as normal VMCS, and can be read / modified using VMREAD / VMWRITE instructions, including from non-root mode without generating VM-exit . As a result, a significant part of the transitions L1 → L0 is eliminated. However, shadow VMCS cannot be used to enter / exit non-root and root modes - the original VMCS managed by L0 is still used for this.
Shadow EPT
I note that the Intel EPT (English Extended Page Table) mentioned in the first part is also a hardware acceleration technique for working with another shadow structure used for address translation. Instead of monitoring the entire tree of guest translation tables (starting from the value of the CR3 privileged register) and intercepting attempts to read / modify it, it creates its own “sandbox” for it. These physical addresses are obtained after the translation of guest physical addresses, which is also done by the equipment.
In the case of embedded virtualization, as in the case of VMCS, we come to the same problem: now there are three translation levels (L2 → L1, L1 → L0 and L0 → physical address), but the hardware only supports two. This means that one of the levels of translation will have to be modeled programmatically.
If we model L2 → L1, then, as expected, this will lead to a significant slowdown. The effect will be even more significant than in the case of one level: each exception #PF (English page fault) and writing CR3 inside L2 will lead to the output in L0, and not in L1. However, if you notice [6] that guest L1 environments are created much less frequently than processes in L2, then you can make the broadcast (L1 → L0) programmatic (i.e. slow), and use the freed hardware (fast) EPT for L2 → L1 . This reminds me of an idea from the field of compiler optimizations: you should optimize the most nested code loop. In the case of virtualization, this is the most embedded guest.
Virtualization³: what's next?
Let's fantasize a bit about what might happen in the future. Further in this section are my own (and not so) ideas about how we can arrange the future virtualization. They may be completely bankrupt, impossible or inappropriate.
And in the future, the creators of VM monitors will want to dive even deeper - to bring recursive virtualization to the third, fourth and deeper levels of nesting. The techniques described above for supporting two levels of nesting become very unattractive. I'm not very sure that the same tricks can be repeated for effective virtualization, even the third level. The trouble is that the guest mode does not support re-entering yourself.
The history of computer technology recalls similar problems and suggests a solution. Early Fortran did not support recursive call of procedures because the state of local variables (activation record) was stored in statically allocated memory. Recalling an already executing procedure would erase this area, cutting off the exit from the procedure. The solution, implemented in modern programming languages, consisted of supporting a stack of records storing data of the called procedures, as well as the return address.
We see a similar situation for VMCS - an absolute address is used for this structure, the data in it belongs to the L0 monitor. The guest cannot use the same VMCS, otherwise he would risk losing the state of the host. If we had a stack or rather even a doubly linked listVMCS, in which each subsequent record would belong to the current monitor (as well as all its superiors), one would not have to resort to the tricks described above for transferring L2 under the command of L0. Exiting a guest would transfer control to his monitor while switching to the previous VMCS, and entering guest mode would activate the next one on the list.
The second feature that limits the performance of nested virtualization is the irrational processing of synchronous exceptions [7]. If an exception occurs within the embedded guest L N, control is always transferred to L0, even if his only task after this is to “lower” the processing of the situation to the monitor L closest to L N ( N-1) The descent is accompanied by an avalanche of state switching of all intermediate monitors.
Effective recursive virtualization in architecture requires a mechanism that allows you to change the processing direction of some exceptional events: instead of a fixed order L0 → L ( N-1 ), synchronous interrupts can be directed L ( N-1 ) → L0. The intervention of external monitors is required only if more nested ones cannot handle the situation.
Instead of a conclusion
The topic of optimizations in virtualization (and indeed any optimizations in general) is inexhaustible - there will always be one more last frontier on the road to achieving maximum speed. In my three notes, I talked only about some Intel VT-x extensions and nested virtualization techniques and completely ignored the rest. Fortunately, researchers working on open and commercial virtualization solutions are quite willing to publish the results of their work. The materials of the annual conference of the KVM project, as well as the whitepaper of Vmware, are a good source of information on the latest achievements. For example, the issue of reducing the number of VM-exit caused by asynchronous interrupts from devices is discussed in detail in [8].
Thanks for attention!
Literature
- Intel Corporation. Intel 64 and IA-32 Architectures Software Developer's Manual. Volumes 1-3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Orit Wasserman, Red Hat. Nested virtualization: shadow turtles. // KVM forum 2013 - www.linux-kvm.org/wiki/images/e/e9/Kvm-forum-2013-nested-virtualization-shadow-turtles.pdf
- kashyapc. Nested Virtualization with Intel (VMX) raw.githubusercontent.com/kashyapc/nvmx-haswell/master/SETUP-nVMX.rst
- Muli Ben-Yehuda et al. The Turtles Project: Design and Implementation of Nested Virtualization // 9th USENIX Symposium on Operating Systems Design and Implementation, 2010. www.usenix.org/event/osdi10/tech/full_papers/Ben-Yehuda.pdf }
- Intel Corporation. 4th Gen Intel Core vPro Processors with Intel VMCS Shadowing. www-ssl.intel.com/content/www/us/en/it-management/intel-it-best-practices/intel-vmcs-shadowing-paper.html
- Gleb Natapov. Nested EPT to Make Nested VMX Faster // KVM forum 2013 - www.linux-kvm.org/wiki/images/8/8c/Kvm-forum-2013-nested-ept.pdf
- Wing-Chi Poon, Aloysius K. Mok. Improving the Latency of VMExit Forwarding in Recursive Virtualization for the x86 Architecture // 2012 45th Hawaii International Conference on System Sciences
- Muli Ben-Yehuda. Bare-Metal Performance for x86 Virtualization. www.mulix.org/lectures/bare-metal-perf/bare-metal-intel.pdf