Pancakes with ICO on python or how to measure people and ICO projects
Good day friends.
There is a clear understanding that most ICO projects are, in essence, a completely intangible asset. ICO project is not a Mercedes-Benz car - which drives regardless of whether it is loved or not. And the main influence on the ICO is the mood of the people - both the attitude towards the founder of the \ founder ICO and the project itself.
It would be good to somehow measure the mood of the people in relation to the founder of ICO and / or to the ICO project. What was done. Report below.
The result was a tool to collect a positive / negative mood from the Internet, in particular from Twitter.
My environment is Windows 10 x64, I used Python 3 in Spyder editor in Anaconda 5.1.0, a wired connection to the network.
Data collection
I will get the mood from the Twitter posts. First, I’ll find out what the founder of ICO is doing now and how positively they speak of this using the example of a couple of famous personalities.
I will use the python tweepy library. To work with Twitter, you need to register as a developer in it, see twitter / . Get criteria for accessing Twitter.
The code is:
import tweepy
API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr"
API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr"
ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr"
ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr"
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)Now we can access the Twitter API and get something from it or vice versa. The case was done in early August. Need to get some tweets to find the current project of the founder. Searched like this:
import pandas as pd
searchstring = searchinfo+' -filter:retweets'
results = pd.DataFrame()
coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500)
for tweet in coursor.items():
my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted'])
result = pd.DataFrame(my_series).transpose()
results = results.append(result, ignore_index = True)
results.to_excel('results.xlsx')In the searchinfo substitute the desired name and forward. The result kept the results.xlsx in the exec.
Creative
Then I decided to make a creative. We need to find the projects of the founder. Project names are proper names and are capitalized. Suppose, and it seems to be true, that with a capital letter in each tweet will be written: 1) the name of the founder, 2) the name of his project, 3) the first word of the tweet and 4) extraneous words. Words 1 and 2 will be tweetted frequently, and 3 and 4 rarely, in frequency we are 3 and 4 and we will sift. Yes, it also became clear that links often come across on Twitter, 5) we’ll remove them too.
It turned out like this:
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
corpus = []
for i in range(0, len(results.index)):
review1 = []
mystr = results['text'][i]
#убрать 1)имя кого ищем и 2)его имя в тэге
mystr = re.sub(searchinfo, ' ', mystr)
searchinfo1 = searchinfo.replace(" ","_")
mystr = re.sub(searchinfo1, ' ', mystr)
#убрать 3)ссылки
splitted_text = mystr.split()
mystr=""for word in splitted_text: #первые 7 символовif len(word)>6:
if word.find('https:/')==-1and word.find('http://')==-1:
mystr = mystr+' '+word
else:
mystr = mystr+' '+word
review = re.sub('[^a-zA-Z]', ' ', mystr)
review = review.split()
for word in review:
if word[0].isupper():
review1.append(word.lower())
ps = PorterStemmer()
review1 = [ps.stem(word) for word in review1 ifnot word in set(stopwords.words('english'))]
review1 = ' '.join(review1)
corpus.append(review1)
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X = cv.fit_transform(corpus).toarray()
names = cv.get_feature_names()Analysis of creative data
In the names variable we have words, and in the variable X, the places where they are mentioned. "Fold" table X - we get the number of mentions. Delete words that are rarely mentioned. We save in Excel. And in Excel we make a beautiful bar chart with information on how often which words are mentioned in which query.
Our super ICO stars are “Le Minh Tam” and “Mike Novogratz”. Charts:
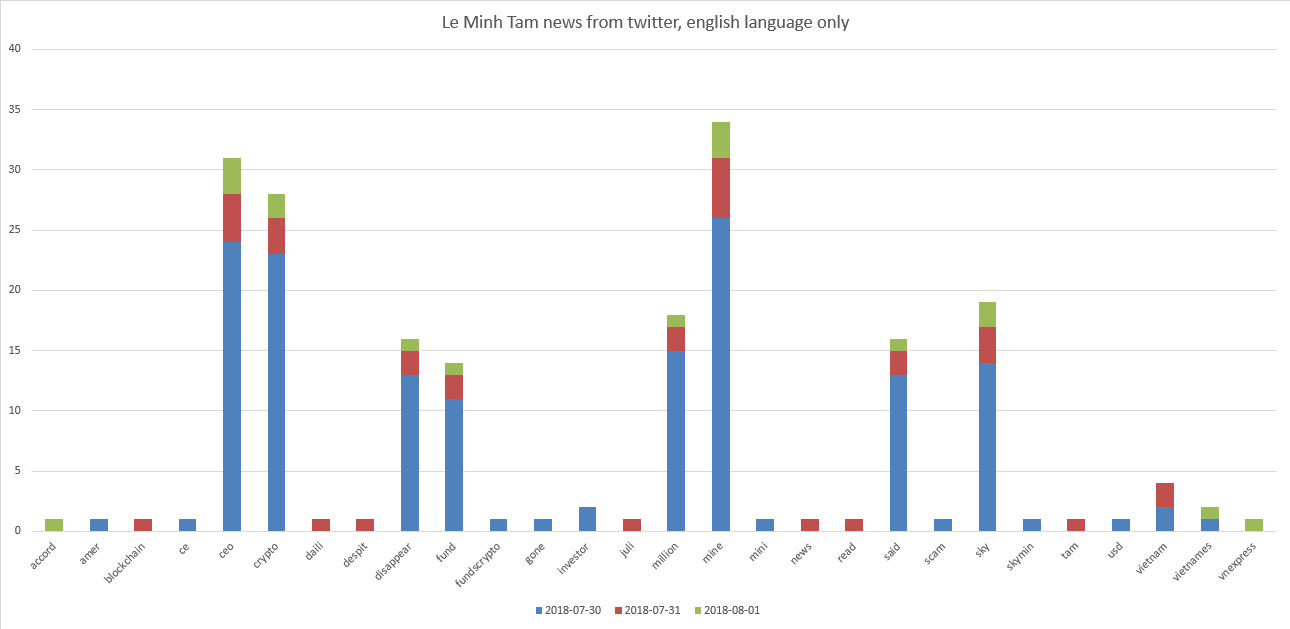
It can be seen that Le Minh Tam is related to "ceo, crypto, mine, sky". And a little bit to "disappear, fund, million".
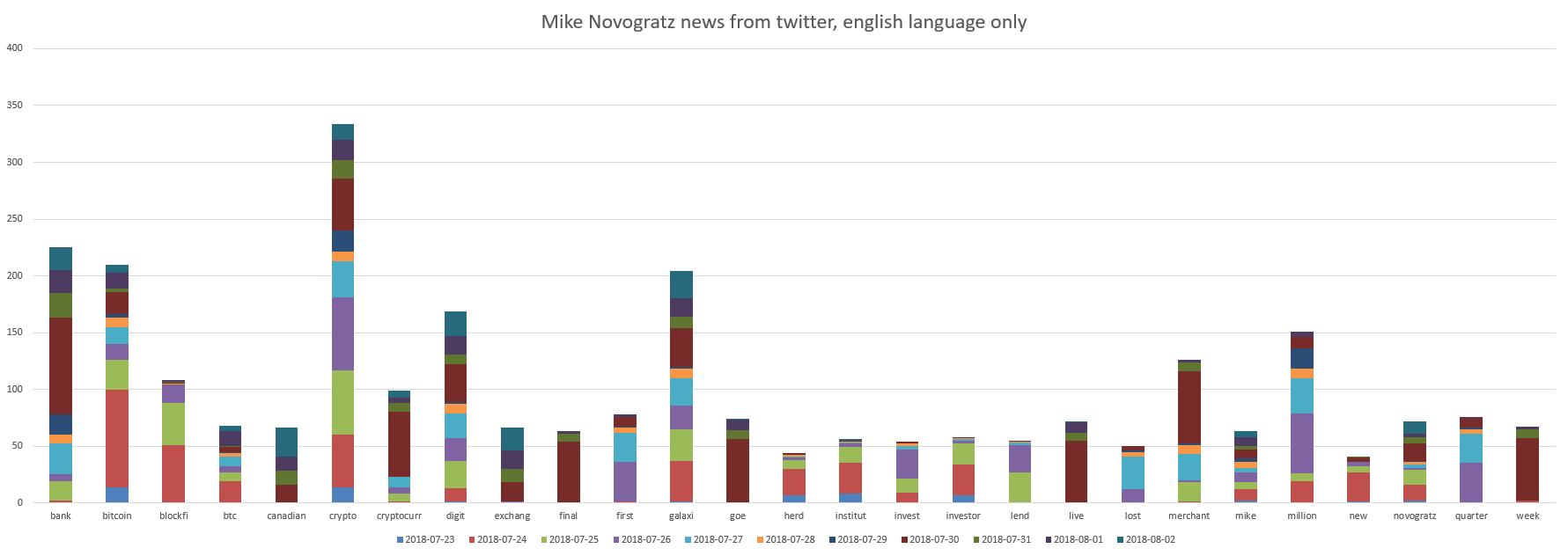
It can be seen that Mike Novogratz is related to "bank, bitcoin, crypto, digit, galaxy".
Data from X can be poured into the neural network and it can learn to define anything, or you can:
Data analysis
And then we stop to fool aroundbe creative and start using the python library TextBlob . The library is a marvel.
Smart people say she can:
- highlight phrases
- doing part of the markup
- analyze the mood (it is useful to us below),
- do classification (naive bayes, decision tree),
- translate and define language using google translate,
- do tokenization (break the text into words and sentences),
- identify frequencies of words and phrases
- parse
- detect n-grams
- do \ identify inflection \ declination \ conjugation of words (pluralization and singularization) and lemmatization,
- correct spelling.
The library allows you to add new models or languages through extensions and has WordNet integration. In short, NLP wunderwafl .
We saved the search results in the results.xlsx file above. Load it and go through it with the TextBlob library for the purpose of mood assessment:
from textblob import TextBlob
results = pd.read_excel('results.xlsx')
polarity = 0for i in range(0, len(results.index)):
polarity += TextBlob(results['text'][i]).sentiment.polarity
print(polarity/i)Cool! A couple of lines of code and a bang result.
Results Review
It turns out that at the beginning of August 2018, the tweets found on the Le Minh Tam request showed something that had a negative effect on the tweets with an average rating of all tweets minus 0.13 . If we look at the tweets ourselves, we see, for example, “Crypto Mining CEO Said to Disappear With $ 35 Million In Funds, Crypto mining firm Sky Mining's CEO Le Minh Tam has r ...”.
And fellow “Mike Novogratz” did something that had a positive effect on tweets, with an average rating of all tweets plus 0.03 . You can interpret it in such a way that everything calmly moves forward.
Attack plan
For the purposes of ICO evaluation, it is worth monitoring the information on the founders of the ICO and on the ICO itself from several sources. For example:
- social network,
- https://forklog.com/ - news with reviews,
- https://bitcointalk.org/ - forum, calendar and analytics, ratings,
- https://cointelegraph.com/ ,
- https://icorating.com/ ,
- https://www.coinschedule.com/ ,
- https://icotracker.net/ .
This should be done on an ongoing basis, for example hourly.
Plan for monitoring one ICO:
- Create a list of the names of the founders of the ICO and the ICO itself,
- Create a list of resources for monitoring,
- We make a robot that collects data for each line from 1 - for each resource from 2, the example above,
- We make a robot that gives an estimate of each 3, an example above,
- Save results 4 (and 3)
- We repeat paragraphs 3-5 hourly, in an automated way, the evaluation results can be post / send / save somewhere,
- Automatically we follow the jumps of the assessment in paragraph 6. If there are jumps in the assessment in paragraph 6, this is a reason to conduct an additional study of what is happening in an expert manner. And raise a panic, or vice versa rejoice.
Somehow like this.
PS Well, or buy this information, for example, here thomsonreuters