A / B test is easy

A / B testing is a powerful marketing tool to improve the performance of your online resource. Using A / B tests, they increase the conversion of landing pages, select the optimal headings for ads in ad networks, and improve the quality of search.
I often have to deal with the tasks of organizing A / B testing in various Internet projects. In this article I want to share the necessary basic knowledge for conducting tests and analyzing results.
Why do we need A / B tests?
So, let’s imagine the situation, our project is launched, traffic is collected on it, users actively use the resource. And one fine day, we decided to change something, for example, to place a pop-up widget for the convenience of subscribing to news.
Our solution is an intuitive assumption that it will become easier for users of the resource to subscribe to new materials, we expect an increase in the number of subscribers.
Our assumptions and hypotheses are based on personal experience and our views, which do not necessarily coincide with the views of the audience of our resource. In other words, our assumption does not mean at all that after making the changes we will get the desired effect. To test such hypotheses, we conduct A / B tests.
How do we conduct tests?
The idea of A / B testing is very simple. Resource users are randomly divided into segments. One of the segments remains unchanged - this is the control segment “A”, based on the data for this segment, we will evaluate the effect of the changes made. To users from segment “B” we show the changed version of the resource.
In order to obtain a statistically significant result, it is very important to exclude the influence of segments on each other, i.e. the user must be assigned strictly to one segment. This can be done, for example, by writing a segment label in the browser cookies.
To reduce the influence of external factors , such as advertising campaigns, day of the week, weather or seasonality, it is important to take measurements in segments in parallel, i.e. in the same time period.
In addition, it is very important to exclude internal factors , which can also significantly distort the test results. Such factors may include actions of call-center operators, a support service, editorial staff, developers or resource administrators. In Google Analytics, you can use filters to do this .
The number of users in segments is not always possible to make equal, in this regard, metrics are usually selected relative, i.e. without reference to the absolute audience values in the segment. Rationing is carried out either by the number of visitors, or by the number of page views. For example, such metrics may be the average check or CTR of the link.
One reason for dividing the audience disproportionately can be a significant change in the interface. For example, a complete update of an outdated website design, a change in the navigation system, or the addition of a pop-up form to collect contact information. Such changes can lead to both positive and negative effects in the operation of the resource.
If there is a fear that the change may have a strong negative impact, for example, lead to a sharp outflow of the audience, then, at the first stage, it makes sense to make the test segment not very large. In the absence of a negative effect, the size of the test segment can be gradually increased.
What are we improving?
If you are going to conduct A / B testing on your resource, then your project probably has already formed the main indicators that need to be improved. If there are no such indicators yet, then it's time to think about them.
Indicators are primarily determined by the objectives of the project. Below are a few popular metrics that are used in Internet projects.
Conversion
Conversion is calculated as a fraction of the total number of visitors who have completed an action. The action may be filling out a form on the landing page, making a purchase in an online store, registering, subscribing to news, clicking on a link or block.
Economic Metrics
As a rule, these metrics are applicable for online stores: the average check value , the revenue volume, referred to the number of visitors to the online store.
Behavioral factors
Behavioral factors include an assessment of visitor interest in a resource. Key metrics are: page viewing depth - the number of pages viewed, related to the number of visitors to the site, average session duration , bounce rate - percentage of users who left the site immediately after the first visit, retention rate (can be considered as 1 min% of new users).
One indicator is not always enough to assess the effect of the changes made. For example, after changes on the website of an online store, the average check may decrease, but the total revenue may increase due to an increase in the conversion of a visitor to a buyer. In this regard, it is important to control several key indicators.
Results Analysis
Well, the key indicators are defined, the test is running and we got the first data. At this point, especially if the data meets our expectations, it is tempting to draw hasty conclusions about the test results.
Do not rush, the values of our key indicators can change from day to day - this means that we are dealing with random variables. To compare random values, average values are estimated, and to estimate average values, it takes some time to accumulate a history.
The effect of the change is defined as the difference between the average values of the key indicator in the segments. This raises the following question, how confident are we in the reliability of the result? If we run the test again, then what is the likelihood that we can repeat the result?
The pictures below show examples of the distribution of indicator values in segments.
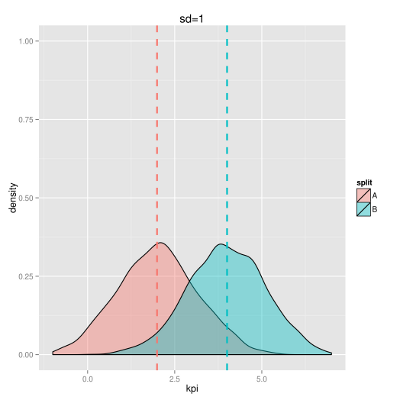

Distribution graphs characterize the frequency of occurrence of one or another value of a random variable in the sample. In this case, all values are distributed around the average.
In both pictures, the average values of the indicator in the corresponding segments are the same, the pictures differ only in the scatter of values .
This example illustrates well that the difference in average values is not enough to consider the result reliable ; it is also necessary to estimate the intersection area of distributions.
The smaller the intersection, the more confident we can say that the effect is really significant. This “confidence” in statistics is calledthe significance of the result .
As a rule, to make a positive decision on the effectiveness of changes, the significance level is chosen equal to 90%, 95% or 99%. The intersection of the distributions in this case is 10%, 5%, or 1%, respectively. With a low level of significance, there is a danger of making erroneous conclusions about the effect obtained as a result of the change.
Despite the importance of this characteristic, in reports on A / B tests, unfortunately, they often forget to indicate the level of significance at which the result was obtained.
By the way, in practice, about 8 out of 10 A / B tests are not statistically significant.
It is worth noting that the greater the volume of traffic in the segments, the smaller the variation in average daily values of the indicator. With little traffic, due to the larger scatter of random values, it will take longer to conduct the experiment, but in any case it is better than not conducting the experiment at all.
Assess the significance of the results.
To compare random variables, mathematicians came up with a whole section called testing statistical hypotheses . There are only two hypotheses: “zero” and “alternative”. The null hypothesis suggests that the difference between the average values of the indicator in the segments is insignificant. An alternative hypothesis suggests that there is a significant difference between the average values of the indicator in the segments.
To test hypotheses, there are several statistical tests. Tests depend on the nature of the measured indicator. In the general case, if we consider daily average values, we can use the Student's test . This test has worked well for small amounts of data, as takes into account sample size when evaluating significance.
As an example, I will compare the average session duration in segments on one of the resources for which I conducted the experiment: studentttest.xls .
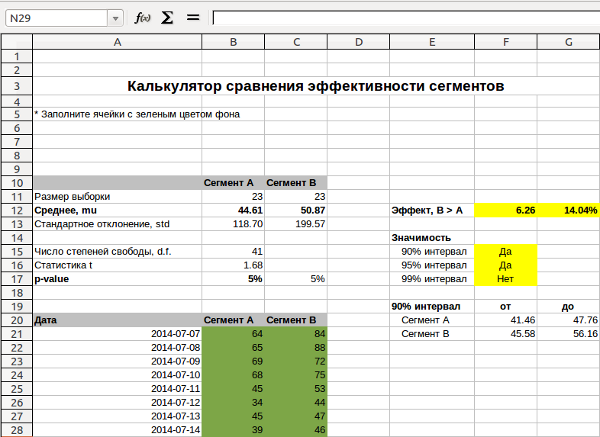
Student's test is universal, it can be used both for conversion measurements, and for such quantitative indicators as the average check, average viewing depth or the time spent by the user on the site.
If you measure only conversion, then you are dealing with a binary random value that takes only two values: the visitor “converted” and “not converted”. To assess the statistical significance in this case, you can use the on-line calculator .
Instruments
To organize the test, you need a tool that allows you to mark the audience by segments and calculate the values of key indicators separately in each segment.
If your resources allow, then such a tool can be implemented independently based on the analysis of user actions logs. If resources are limited, then you should use a third-party tool. For example, Google Analytics has the ability to define custom segments .
There are a number of services that allow you to fully automate the testing process, for example, the same Google Analytics Experiements , examples of other services can be found in the review .
What next?
The article provides the basic knowledge needed to conduct A / B tests and analyze the results. The next step is product analytics. In conclusion, I want to share a link to an excellent presentation on product analytics with examples of A / B testing from Evgeny Kuryshev.
Only registered users can participate in the survey. Please come in.
Have you ever had to organize A / B testing?
- 29.1% No, I've never heard of A / B tests before 170
- 55.1% A / B tests did not conduct, but I know what it is 322
- 8.2% Yes, I had to, compared only the values in segments 48
- 7.5% Tests carried out, compared values, considered statistical significance 44