Onion architecture. Part 1
- Transfer
Earlier, I mentioned several times about a special type of architecture, which I call onion architecture. This architecture is ideal for applications with a long life cycle and complex business logic. I believe that its use in such projects leads to excellent results, as a result of the emphasis initially laid on the architecture to separate the various aspects of the application. Onion architecture pays special attention to the description of system behavior in terms of contract programming and the transfer of infrastructure code to external modules. In the diagram below, you can see a graphical representation of a traditional “layered” architecture. This is a very popular approach, used in various variations in many projects I have seen.

Each next layer is closely connected with neighboring ones and depends on the used infrastructure modules and services. The main disadvantage of multilayer architecture is the high connectivity generated by it. As we know, the worst manifestation of high connectivity is the penetration of UI and business logic elements into the data access layer. In projects using a multi-layer architecture, the UI remains closely connected to the data access layer. Transitional dependence remains a dependency. The UI layer cannot function separately from the business logic layer, just as the business logic layer is not able to function separately from the data access layer. I deliberately ignore infrastructure issues, as infrastructure tends to change from project to project. The data access layer is constantly changing. Historically, Data approaches are updated at least every three years. Therefore, in applications with a long life cycle, you need to be prepared for the fact that in three years you will have to make changes to the data access layer. If high connectivity makes it difficult to replace obsolete modules independently of each other, the entire system can go into a state of decline and the team will have nothing left but to completely rewrite it.
I propose a new approach to building applications. To be honest, it is not entirely new, but I propose to give it a name and fix it on a par with other architectural patterns. Patterns are useful because they provide developers with a public dictionary to simplify communication. Onion architecture has many aspects, and we need to give it a name for more effective communication. The diagram below shows the onion architecture.
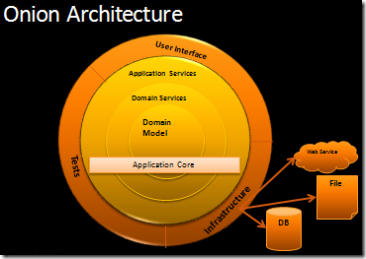
Its key feature in managing connectivity. Fundamental rule - any application module may depend on modules closer to the center of the bulb, but may not depend on more distant ones. In other words, any connectedness should be directed towards the center of the bulb.
Onion architecture gravitates toward OOP and places objects ahead of any other aspects of the application. At the very center is the domain model of the application. Around the domain model are other layers with additional business logic. The number of layers in the application can vary, but the domain model should always remain in the center and, since any connectedness is directed to the center, the domain model is connected only with itself. The first layer around the domain model is the place where the interfaces of the repositories are usually located, which ensure the storage and retrieval of objects. It should be noted that the process of saving objects is outside the core of the application, since this process usually involves interaction with the database server, and only the interfaces are in the center of the kernel. On the outer radius of the application are UI, infrastructure and tests. The outer layer is reserved for elements that change frequently. These elements must be isolated from the application core. At the very edge, there are classes that implement repository interfaces. These classes are closely related to a specific data access technology and that is why they should be moved outside the application core.
Onion architecture is based on the principle of dependency inversion. An application requires implementations of the interfaces located in the kernel, and since specific implementations are located on the external radius of the application, the application also needs a mechanism for injecting dependencies.
The database is not located in the application center.Transferring the database engine from the kernel to a separate module can be a serious step for people thinking about applications exclusively in the context of interacting with data sources. Applications, of course, can use databases to store objects, but only through a layer of infrastructure code that implements the interfaces used in the application core. The break in connectivity between the application and the database, file system, etc. reduces the cost of supporting the application throughout its life cycle.
Alistair Cockburn once wrote on the subject of hexagonal architecture on his blog(Hexagonal architecture). Hexagonal and onion architecture is based on general principles: transferring infrastructure to external modules and writing adapters to them. I plan to write more about the use of onion architecture in building enterprise-level applications. I remain in this environment and continue my discussion of onion architecture in this context.
From the translator. This post is the first of a series of Jeffrey Palermo posts on onion architecture. If the habrasociety has interest, I can do the translation of the remaining parts.
Each next layer is closely connected with neighboring ones and depends on the used infrastructure modules and services. The main disadvantage of multilayer architecture is the high connectivity generated by it. As we know, the worst manifestation of high connectivity is the penetration of UI and business logic elements into the data access layer. In projects using a multi-layer architecture, the UI remains closely connected to the data access layer. Transitional dependence remains a dependency. The UI layer cannot function separately from the business logic layer, just as the business logic layer is not able to function separately from the data access layer. I deliberately ignore infrastructure issues, as infrastructure tends to change from project to project. The data access layer is constantly changing. Historically, Data approaches are updated at least every three years. Therefore, in applications with a long life cycle, you need to be prepared for the fact that in three years you will have to make changes to the data access layer. If high connectivity makes it difficult to replace obsolete modules independently of each other, the entire system can go into a state of decline and the team will have nothing left but to completely rewrite it.
I propose a new approach to building applications. To be honest, it is not entirely new, but I propose to give it a name and fix it on a par with other architectural patterns. Patterns are useful because they provide developers with a public dictionary to simplify communication. Onion architecture has many aspects, and we need to give it a name for more effective communication. The diagram below shows the onion architecture.
Its key feature in managing connectivity. Fundamental rule - any application module may depend on modules closer to the center of the bulb, but may not depend on more distant ones. In other words, any connectedness should be directed towards the center of the bulb.
Onion architecture gravitates toward OOP and places objects ahead of any other aspects of the application. At the very center is the domain model of the application. Around the domain model are other layers with additional business logic. The number of layers in the application can vary, but the domain model should always remain in the center and, since any connectedness is directed to the center, the domain model is connected only with itself. The first layer around the domain model is the place where the interfaces of the repositories are usually located, which ensure the storage and retrieval of objects. It should be noted that the process of saving objects is outside the core of the application, since this process usually involves interaction with the database server, and only the interfaces are in the center of the kernel. On the outer radius of the application are UI, infrastructure and tests. The outer layer is reserved for elements that change frequently. These elements must be isolated from the application core. At the very edge, there are classes that implement repository interfaces. These classes are closely related to a specific data access technology and that is why they should be moved outside the application core.
Onion architecture is based on the principle of dependency inversion. An application requires implementations of the interfaces located in the kernel, and since specific implementations are located on the external radius of the application, the application also needs a mechanism for injecting dependencies.
The database is not located in the application center.Transferring the database engine from the kernel to a separate module can be a serious step for people thinking about applications exclusively in the context of interacting with data sources. Applications, of course, can use databases to store objects, but only through a layer of infrastructure code that implements the interfaces used in the application core. The break in connectivity between the application and the database, file system, etc. reduces the cost of supporting the application throughout its life cycle.
Alistair Cockburn once wrote on the subject of hexagonal architecture on his blog(Hexagonal architecture). Hexagonal and onion architecture is based on general principles: transferring infrastructure to external modules and writing adapters to them. I plan to write more about the use of onion architecture in building enterprise-level applications. I remain in this environment and continue my discussion of onion architecture in this context.
From the translator. This post is the first of a series of Jeffrey Palermo posts on onion architecture. If the habrasociety has interest, I can do the translation of the remaining parts.
Only registered users can participate in the survey. Please come in.
Continue translation
- 88.9% Yes 404
- 11% No 50