Finding the best audio system for speech recognition with closed source, but with open APIs, for integration
Instead of introducing
I decided to supplement the report a little, which I was still a student. Time has passed and, as they say, progress does not stand still. Speech recognition technologies are developing dynamically. Something appears, something disappears. I bring to your attention the most famous speech engines that a developer can use in his product on the basis of a license agreement. I will be glad to comments and additions.
Content:
1. Search and analysis of the color space optimal for constructing prominent objects on a given class of images
2. Determination of the dominant signs of classification and the development of a mathematical model of facial expressions "
3. Synthesis of an optimal recognition algorithm for facial expressions
4. Implementation and testing of the facial recognition algorithm
5. Creation of a test database lip images of users in various states to increase the accuracy of the system
6. Search for the optimal audio speech recognition system based on open source passcode
7.Search for an optimal audio recognition system for speech recognition with closed source code, but with open APIs, for integration
8. Experiment of integrating a video extension into an audio recognition system with speech test protocol
Objectives:
Determine the most optimal audio speech recognition system (speech engine) based on closed source code, that is, a license which does not fit the definition of open source software.
Tasks:
Identify speech recognition audio systems that fall under the concept of closed source. Consider the most famous options for speech systems converting voice to text, for the prospects of integrating a video module into the most optimal voice library, which has an open API for this operation. Draw conclusions on the appropriateness of using speech recognition audio systems based on closed source code for our goals and objectives.

Introduction
Implementing your own speech recognition system is a very complex, time-consuming and resource-intensive task that is difficult to accomplish within the framework of this work. Therefore, it is planned to integrate the presented video identification technology into speech recognition systems, which have special capabilities for this. Since closed-source speech recognition systems are implemented more efficiently and the speech recognition accuracy in them is higher, therefore, the integration of our video development into their work should be considered a more promising direction compared to open-source audio speech recognition systems. However, it is necessary to keep in mind the fact
Closed Source (Proprietary software)
As for the definition of closed source code, it must be said that it means that only binary (compiled) versions of the program are distributed and the license implies a lack of access to the source code of the program, which makes it difficult to create modifications of the program. Third party access to the source code is usually granted upon signing a non-disclosure agreement. [1].
Closed source software is proprietary (proprietary) software. However, it must be borne in mind that the phrase "closed source" can be interpreted in different ways. Since it may mean licenses in which the source code of the programs is not available. However, if we consider it the antonym of open source, then it refers to software that does not fit the definition of an open source license, which has a slightly different meaning. One of those controversial issues was how to interpret the concepts of an application programming interface.
Application Programming Interface (API)
Since March 24, 2004, on the basis of a decision of the European Commission for closed source programs, as a result of the lawsuit, a definition of API appeared, which stands for application programming interface or as an application programming interface (in English - application programming interface). API - a set of ready-made classes, procedures, functions, structures and constants provided by the application (library, service) for use in external software products. Used by programmers to write all kinds of applications.
The API defines the functionality that the program (module, library) provides, while the API allows you to abstract from how exactly this functionality is implemented.
If the program (module, library) is considered as a black box, then the API is a lot of “handles” that are available to the user of this box, which he can twist and pull.
Software components communicate with each other through the API. In this case, components usually form a hierarchy - high-level components use the API of low-level components, and those, in turn, use the API of even lower-level components.
According to this principle, protocols for transmitting data over the Internet are built. The standard protocol stack (OSI network model) contains 7 levels (from the physical layer of bit transfer to the level of application protocols similar to HTTP and IMAP protocols). Each level uses the functionality of the previous level of data transfer and, in turn, provides the necessary functionality to the next level.
It is important to note that the concept of protocol is close in meaning to the concept of API. Both are an abstraction of functionality, only in the first case we are talking about data transfer, and in the second - about the interaction of applications. [2].
Dragon Mobile SDK
The toolkit itself is called NDEV. In order to get the necessary code and documentation, you need to register on the site in the “cooperation program”. Website:
dragonmobile.nuancemobiledeveloper.com/public/index.php [5].
The toolkit (SDK) contains both the client and server components. The diagram illustrates their interaction at the upper level:
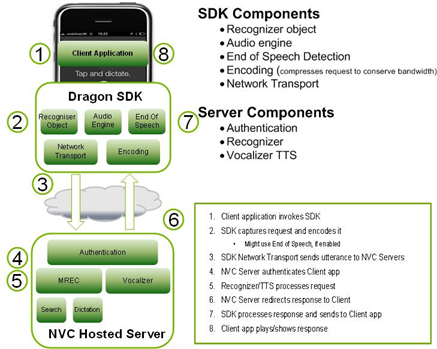
Fig. 1. The principle of operation of the Dragon Mobile SDK technology
The Dragon Mobile SDK consists of various code examples and project templates, documentation, as well as a software platform (framework) that simplifies the integration of speech services into any application.
The Speech Kit framework allows you to easily and quickly add speech recognition and synthesis (TTS, Text-to-Speech) services to applications. This platform also provides access to speech processing components located on the server through asynchronous “clean” network APIs, minimizing overhead and resource consumption.
The Speech Kit platform is a full-featured high-level “framework” that automatically manages all low-level services.
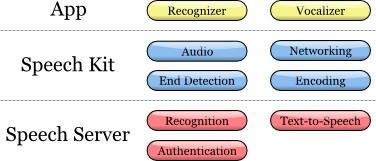
Fig. 2. Speech Kit architecture
The platform performs several coordinated processes:
1. Provides full control of the audio system for recording and playback
2. The network component manages the connections to the server and automatically reconnects with the elapsed timeout with each new request
3. The end of speech detector detects when the user has finished speaking and automatically stops recording if necessary
4. The encoding component compresses and decompresses the streaming audio recording, reducing the requirements to bandwidth and reducing the average delay time.
The server system is responsible for most of the operations involved in the speech processing cycle. The process of speech recognition or synthesis is performed entirely on the server, processing or synthesizing the audio stream. In addition, the server authenticates according to the configuration of the developer.
The Speech Kit platform is a network service and needs some basic settings before using speech recognition or speech synthesis classes.
This installation performs two basic operations:
First, it defines and authorizes your application.
Secondly, it establishes a connection with a voice server, which allows quick requests for voice processing and, therefore, improves the quality of user service.
Speech recognition
Recognition technology allows users to dictate instead of typing where text input is usually required. The speech recognizer provides a list of text results. It is not tied to any user interface (UI) object in any way, therefore the selection of the most suitable result and the selection of alternative results remains at the discretion of the user interface of each application.

Fig. 3. Speech recognition process
In the work of our application on the Android OS, we were able to integrate the solution from Dragon Mobile SDK. The pioneer of the speech recognition industry has shown excellent results, especially in English. However, the limited free functionality should be considered its biggest drawback: only 10 thousand requests per day - which soon became insufficient for our application to work. Access should be paid for .
Google Speech Recognition API

Fig. 4. Google Voice Search logo
This is a Google product that allows you to enter voice search using speech recognition technology. The technology is integrated into mobile phones and computers, where you can enter information using voice. Since June 14, 2011, Google announced the integration of the speech engine in Google Search and since then it has been operating in stable mode since that time. This technology on personal computers is only supported by the Google Chrome browser. The function is enabled by default in dev-channel assemblies, but can be enabled manually by adding a command flag. There is also a voice control feature for entering voice commands on Android phones.
Initially, Google Voice Search - supported short search queries with a length of 35-40 words. It was necessary to turn the microphone on and off to send a request, which was very unnatural for use (such a function still remains in the Google search bar, you just need to click on the microphone). However, at the end of February 2013, the ability to recognize continuous speech was added to the Chrome browser and, in fact, Google Voice Search was transformed into Speech Input (you can try the technology using the example of typing in Google Translate ). The technology can be experimentally tested, for example, also here . Read the full documentation here. We only note that if earlier many developers sinned by illegally using various tricks to wedge themselves into the Google Speech API recognition channel, now, during frequent changes to the API since May 2014, the process of accessing the API has actually become legal, since it works with the database data of the speech recognition system, it is enough to register an account with Google Developers and then you can work with the system within the framework of the legal field.
Voice Search comes with the following services by default: Google, Wikipedia, YouTube, Bing, Yahoo, DuckDuckGo and Wolfram | Alpha and others. You can also add your own search engines. The extension also adds a voice input button for all sites using HTML5 search forms. A microphone is required for the extension to work. Speech input is very experimental, so don't be surprised if it doesn't work. [3].
To do this, to use the Google Voice Search technology, you need to do the following: You
need to make a POST request for the address (now it often changes - for example, in the month of May there were three changes and therefore you need to be prepared for this) with audio data in FLAC or Speex format. Implemented a demonstration of recognition of WAVE files using C #. The number of query restrictions per day was not noticed. There was a risk with 10,000 characters, like many other speech recognition systems, but we have experimentally proved such values, we can overcome them daily.
I will not specifically dwell on how this technology works. A lot of articles are available on the network, including on the Habr. I only note that speech recognition systems have a practically similar principle of operation, which was presented in the paragraph above on the example of Nuance.
Yandex Speech Kit

Fig. 5. Yandex Speech Kit logo
I’ll immediately notice that I personally did not work with this library. I’ll only tell you about the experience of a programmer who worked with us. He said that the documentation is very difficult for him to perceive and the system has a limit on the number of requests: 10,000 per day, so in the end we did not use the database from Yandex. Although, according to the developers, this toolkit is number 1 for the Russian language and that the research group of the company, which worked alone in Switzerland, the other in Moscow, was able to make a technological breakthrough in this area. However, with such a decision, it’s quite difficult to enter the international market, according to Grigory Bakunov,
Brief description of the technology: api.yandex.ru/speechkit/
Documentation for Android: api.yandex.ru/speechkit/generated/android/html/index.html
Documentation for iOS: api.yandex.ru/speechkit/generated/ios/html /index.html
You can download the libraries on the Yandex Technologies portal: api.yandex.ru/speechkit/downloads/
Microsoft Speech API

Fig. 6. Microsoft Speech API
Microsoft has also recently begun to actively develop speech technology. Especially after the announcement of the Cortana voice assistant and the development of automatic technology for simultaneous tele-translation from English to German and vice versa for Skype
, there are currently 4 use cases :
1. For Windows and Windows Server 2008. You can add a speech engine for Windows applications using managed or native code that you can take with the API and control the speech engine that is built into Windows and Windows Server 2008.
2. Speech Platforms. Embedding the platform in applications that use Microsoft distributed distributions (language packs with speech recognition or text-to-speech tools).
3. Embedded. Built-in solutions that allow a person to interact with devices using voice commands. For example, driving Ford cars using voice commands in WIndows Automotive
4. Services. Developing an application with speech functions that can be used in real time, thereby freeing yourself from the creation, maintenance and modernization of the speech solution infrastructure.
Microsoft Speech Platform (SDK available)
After installation - you can see help on the following path
And you also need to install Runtime ( link )
as well as Runtime Languages (Version 11). Those. for each language you need to download and install a dictionary. I saw 2 versions of the dictionary for English and Russian.
System requirements (for SDK)
Support for
Windows 7, Windows Server 2008, Windows Server 2008 R2, Windows Vista
Development and support
• Windows Vista or later
• Windows 2003 Server or later
• Windows 2008 Server or later
Deployment is supported on:
• Windows 2003 Server or later
• Windows 2008 Server or later
Pros:
1) Ready technology, take and use! (there is an SDK)
2) Support from Microsoft
Cons:
1) there is no separation from potential competitors
2) as I understand it - it can only be deployed to the server Windows (Windows 2003 Server, Windows 2008 Server or later)
3) development for Windows 8 is not announced, only windows 7 so far and early versions of windows
Using Microsoft Speech API 5.1 for speech synthesis and recognition
Article how to work with API
Installation (only for Windows XP), as I understand it, Speech API 5.1 is now included in Microsoft Speech Platform (v 11), so it makes sense to familiarize yourself with the article .
Microsoft Speech API Project Examples
MSDN links about working with Microsoft.Speech.dll
1. How to start working with a speech recognition system (Microsoft.Speech)
2. Speech recognition engine. Grammar loading. Methods
Examples:
C #, Conversations with a computer or System.Speech
Short article how to use System.Speech. The author points out the need for an English version of Windows Vista or 7.
Speech recognition with C # - Dictation and custom grammar
Tutorial on how to use Microsoft system classes for audio recognition tasks (voice to text), the author also made a post on his blog for the inverse speech into the text.
The project (WinForms) on the tutorial is launched and assembled. There is a recognition of a 20 second interval. And narrow dictionary recognition for managing software - Choices ("Calculator", "Notepad", "Internet Explorer", "Paint"); If we say the phrase "start calculator", etc. then the corresponding software is launched.
C # Speech to Text
Client on WPF.
The purpose of this article is to give you a small idea of the capabilities of the system. Take a closer look at how the speech engine classes work. You can also find all MSDN documentation here .
Creating Grammar in .NET
Examples of working with the GrammarBuilder class
Microsoft .NET Speech API allows you to quickly and easily create applications that will benefit from interacting with a Microsoft research center that specializes in speech recognition. You can build grammatical processes and forms for work. This article is an example of how to implement all this. in the programming language C #.
Speech for Windows Phone 8
Here are some aspects of audio recognition programming under Windows Phone 8.
Conclusion
Thus, having considered the most common closed-source speech recognition systems, it should be noted that according to its data library, the product based on Dragon NaturallySpeaking should be considered the most accurate. It is most suitable for recognition tasks based on our visual mobile extension (as it has good documentation and a simple API code for embedding). However, it should be noted that this toolkit has a very complex licensing system, the procedure and rules for using this technology. Therefore, it becomes difficult to implement a custom product on the Dragon Mobile SDK.
Therefore, in this case, it is more appropriate for our purposes and tasks to use the Google speech tools, which are more embedded and faster due to the large computing power compared to the Dragon Mobile SDK. Also, the advantage of Google’s speech recognition was the lack of restrictions on the number of requests per day (many speech recognition systems with closed source code have a limit of 10,000 requests). Also, this company began to actively strive to develop its speech engine on the basis of a license agreement. Let me remind you again in May 2014 that the leapfrog of a frequent change of APIs from the corporation began and in order to coordinate the process it is necessary to have GoogleDevelopers status.
The great advantage of closed source recognition systems (but an open API for developers), compared to open source audio recognition systems, is high accuracy (due to the huge database libraries) and speech recognition speed, so using them to solve our tasks is a relevant area.
List of references
1) Frequently Asked Questions (and Answers) about Copyright: www.chillingeffects.org/copyright/faq.cgi#QID805
2) Stoughton, Nick (April 2005). “Update on Standards” (PDF). USENIX. Retrieved 2009-06-04.
3) Kai Fu Li, Speech Input API Specification. Editor's Draft October 18, 2010 Latest Editor's Draft: dev.w3.org ... Editors: Satish Sampath, Google Inc. Bjorn Bringert, Google Inc.
4) Google Chrome voice search: habrahabr.ru/post/111201
5) Dragon Mobile SDK official page: dragonmobile.nuancemobiledeveloper.com/public/index.php
To be continued