Hyload in the cloud on a living example
Hello, Flops.ru hosting is with you today and we will tell you about the results of moving a rather large and loaded project to our cloud environment. The project in question is the Adguard line of adblock applications , the developers of which kindly participated in the preparation of this article.
In the article we will talk about the virtual infrastructure of the project, the results of the transfer to the cloud, and at the same time we will list several interesting bottlenecks and bugs that were discovered due to migration. In addition, we give a number of graphs illustrating the work of the project. In general, we invite you to cat.
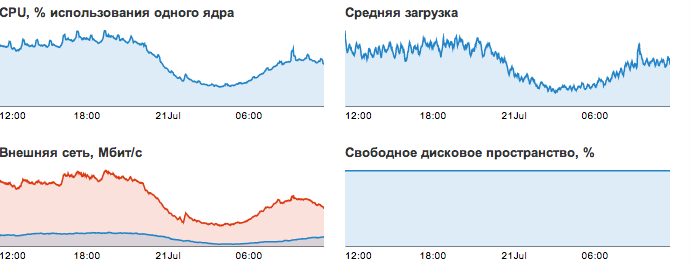
Rush hour traffic is 200-250 Mbps. the total memory capacity of all virtual project servers is 70 GB. The total peak CPU consumption is in the region of 8 Xeon 2620 processor cores. Before the move, the project lived on 8 virtual machines that were located on 2 physical servers. During the migration, it was decided to move the most loaded applications to separate servers (one server - one application), and the number of machines increased to 12:
Since we support both Linux and Windows, all machines without exception managed to migrate. We will not dwell in detail on the move itself - it passed without surprises, and instead we will talk about interesting aspects that attracted attention after the move.
Although the load created by the project is far from the very extreme highload, they are nevertheless quite high and affect all subsystems - from the network stack to the data storage system.
Let's start with the network stack. The client’s product line consists of several desktop applications that periodically go to the backend servers for updates and new databases. Each product of the line is serviced by its own backend located on a separate virtual server. Since there are many clients, they generate a decent load on the network. Here is a graph of traffic consumption by one of the backend servers:

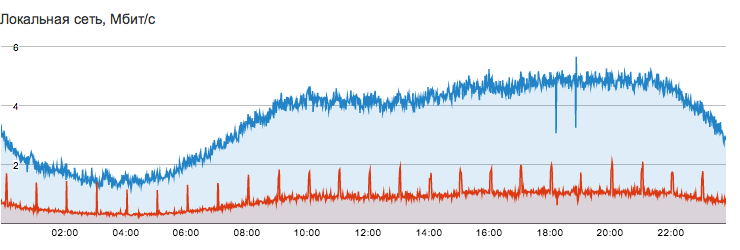
It should be noted separately the local FLOPS network, which is used for communication between client servers.
The only application that actively works with the drive is the Postgres database hosted on a separate virtual server. Access logs, service data and statistics are actively written to the database, which leads to a high intensity of writing to disk - up to 750 iops for writing and up to 1500 iops for reading in peaks.
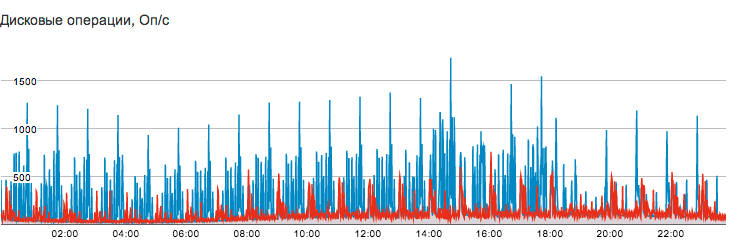
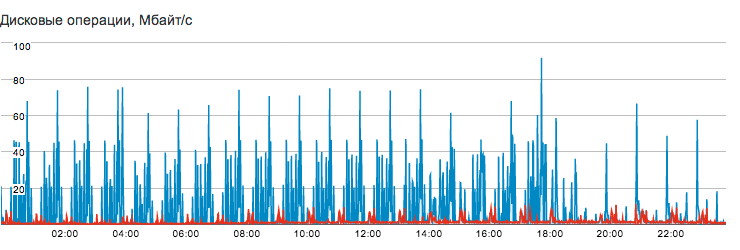
Note that even under these conditions, the average load (Load Average) remains relatively small, mainly due to the low response time of the disk subsystem due to the use of SSDs:

Unlike read operations, which are well amortized by various caches and do not always reach disks, each write to the database is accompanied by a synchronous write to the write-ahead log (WAL) and abuts during the response of the block device. Therefore, without using an SSD, peak performance was lower and LA was higher.
Although the client had his own monitoring before the move, our funds significantly expanded his tools. In addition, the client began to receive messages about events occurring inside its servers, for example, such:
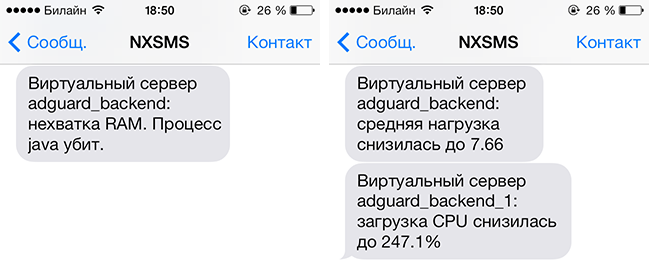
Detailed statistics and the ability to reconfigure the server on the fly made it possible to fine-tune the required resource consumption for each server.
Statistics helped to track a number of subtle bugs that were previously unknown or that could not be localized. Here is some of them:
After transferring and analyzing the graphs, it turned out that one of the backend applications showed very strange behavior - over time, CPU consumption jumped by an integer number of cores:
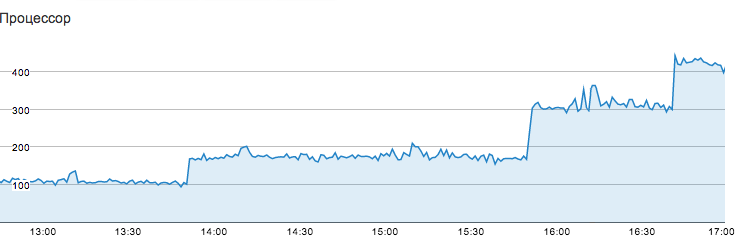
After the next jump, it turned out that everything was to blame for the very complex (and incorrect) regular expression that periodically resulted to freezing threads inside this regexp with 100% CPU consumption.
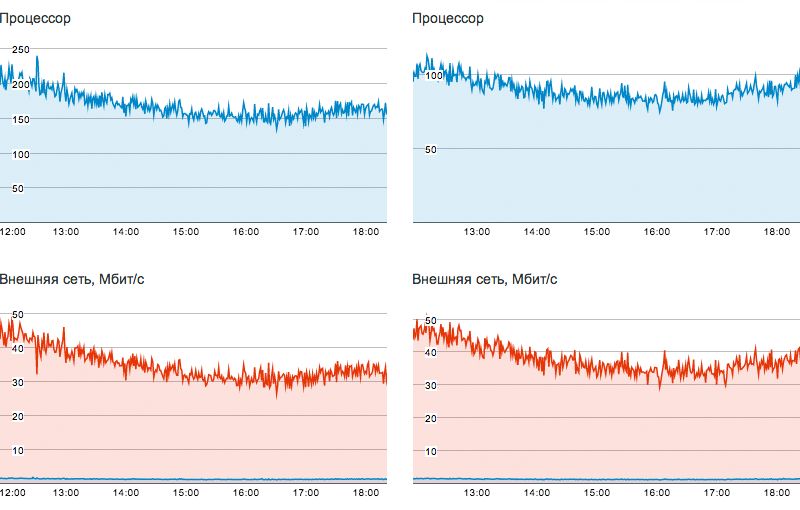
The client was very puzzled by the permanently high CPU load on the backend servers. The reason was that gzip-compression of server responses using java with such volumes of traffic requires large computational resources. The client optimized the distribution of content, and things went much better. Left and right - CPU load before and after optimization.
One of the phenomena that the client took a lot of time to comprehend was a sharp jump in traffic like this:
As it turned out, they were associated with new versions. If you develop software and periodically release updates to it, we recommend that you immediately envisage situations where your customers come to download them at the same time. The more your distribution weighs, the more you risk falling in such situations :)
Despite the fact that before the transfer, the project was serviced by two servers, each of which could service the project alone, the possible failure of one of them would guarantee an idle time of tens of minutes and spoiled nerves. Cloud migration has reduced the dependence on physical iron.
As you can see from the graphs above , the database works quite intensively with the database and in peaks it can generate up to 750 iops for writing and up to 1500 iops for reading. The disk array used by the client before the move was unable to provide such performance and was a bottleneck in the system. Migration to the cloud allowed us to get rid of this “bottleneck”.
The cloud control panel allowed developers to perform actions that were previously available only to the system administrator - creating new virtual servers, launching a clone copy to test the test feature, analyzing the load and changing the parameters of the instances. Data on all servers is now at hand, which becomes significant when there are a lot of machines.
One of the results of the move, which made a great impression on the client, is the possibility of very fast horizontal scaling. The whole sequence of actions is as follows:
We will estimate the costs of hosting before and after the move.
Before: the project was hosted on two colocation servers with a configuration of 96 Gb RAM, 6 × 1 Tb SATA (hardware RAID10), 2x Xeon E5520. A dedicated server with a similar config can be found for 18-20 thousand rubles a month. We need two of them, so the cost of servers will be 36-40 thousand per month. A dedicated band of 300 Mbps will cost somewhere in 13-15 thousand rubles a month. The switch will probably cost another 3-5 thousand. Rounding, we can say that the total cost will be in the region of 52-60 thousand rubles per month.
After:the cost of 1GB of memory on fixed tariff plans is 500 rubles per month. The total cost of servers with a total RAM of 70 GB is 35 thousand rubles. In addition, it is necessary to include traffic that does not fit into the daily limit. Its cost will be approximately 8-12 thousand rubles per month. The result is 43-47 thousand rubles a month.
It would be nice to take into account the costs of installing and configuring (monitoring, SMS notifications, backups, virtualization) dedicated servers, but even without this, renting resources in the cloud in this particular case is 15-20% cheaper than renting physical servers for the same task.
When comparing two ways to host a single complex project - in the cloud and on dedicated servers - the cloud showed its convincing superiority. It turned out to be cheaper, more convenient, more flexible, helped to eliminate a number of weak points of the project and gave the client the opportunity to ignore many routine tasks, such as setting statistics, monitoring and backups.
Although so far we can name individual scenarios where the cloud will lose to dedicated servers, we are sure that over time there will be fewer and fewer such scenarios.
Traditionally, we suggest you register and take advantage of the FLOPS trial period (see the video tutorial) to evaluate the benefits yourself. The trial period is 500 rubles or 2 weeks (depending on what will end earlier). Thanks for attention.
In the article we will talk about the virtual infrastructure of the project, the results of the transfer to the cloud, and at the same time we will list several interesting bottlenecks and bugs that were discovered due to migration. In addition, we give a number of graphs illustrating the work of the project. In general, we invite you to cat.
Brief characteristics of the project
Rush hour traffic is 200-250 Mbps. the total memory capacity of all virtual project servers is 70 GB. The total peak CPU consumption is in the region of 8 Xeon 2620 processor cores. Before the move, the project lived on 8 virtual machines that were located on 2 physical servers. During the migration, it was decided to move the most loaded applications to separate servers (one server - one application), and the number of machines increased to 12:
- 2 build servers with Windows OS
- 3 loaded servers with backends for client applications
- 1 database server
- 1 server with all kinds of frontends
- 1 Windows server with company accounting
- 1 test environment server
- 3 lightly loaded servers for various purposes (forum, tickets, bugtracker, etc.)
Since we support both Linux and Windows, all machines without exception managed to migrate. We will not dwell in detail on the move itself - it passed without surprises, and instead we will talk about interesting aspects that attracted attention after the move.
Although the load created by the project is far from the very extreme highload, they are nevertheless quite high and affect all subsystems - from the network stack to the data storage system.
Public and local area network
Let's start with the network stack. The client’s product line consists of several desktop applications that periodically go to the backend servers for updates and new databases. Each product of the line is serviced by its own backend located on a separate virtual server. Since there are many clients, they generate a decent load on the network. Here is a graph of traffic consumption by one of the backend servers:
It should be noted separately the local FLOPS network, which is used for communication between client servers.
- The local network is completely free, which allows you to use it without regard to traffic.
- Bandwidth - 1 Gbps.
- Unlike DigitalOcean and Linode, the local FLOPS network is private and can be used to create a trusted environment.
- If you want to completely isolate some virtual servers from the outside world, while maintaining their Internet access, you can do this using a local network by setting up NAT on your other server.
Disk subsystem
The only application that actively works with the drive is the Postgres database hosted on a separate virtual server. Access logs, service data and statistics are actively written to the database, which leads to a high intensity of writing to disk - up to 750 iops for writing and up to 1500 iops for reading in peaks.
Note that even under these conditions, the average load (Load Average) remains relatively small, mainly due to the low response time of the disk subsystem due to the use of SSDs:
Unlike read operations, which are well amortized by various caches and do not always reach disks, each write to the database is accompanied by a synchronous write to the write-ahead log (WAL) and abuts during the response of the block device. Therefore, without using an SSD, peak performance was lower and LA was higher.
Transfer Results
Statistics and Monitoring
Although the client had his own monitoring before the move, our funds significantly expanded his tools. In addition, the client began to receive messages about events occurring inside its servers, for example, such:
Detailed statistics and the ability to reconfigure the server on the fly made it possible to fine-tune the required resource consumption for each server.
Easier bug detection
Statistics helped to track a number of subtle bugs that were previously unknown or that could not be localized. Here is some of them:
CPU spike
After transferring and analyzing the graphs, it turned out that one of the backend applications showed very strange behavior - over time, CPU consumption jumped by an integer number of cores:
After the next jump, it turned out that everything was to blame for the very complex (and incorrect) regular expression that periodically resulted to freezing threads inside this regexp with 100% CPU consumption.
Suboptimal work with gzip content
The client was very puzzled by the permanently high CPU load on the backend servers. The reason was that gzip-compression of server responses using java with such volumes of traffic requires large computational resources. The client optimized the distribution of content, and things went much better. Left and right - CPU load before and after optimization.
Sudden spikes in external network traffic
One of the phenomena that the client took a lot of time to comprehend was a sharp jump in traffic like this:
As it turned out, they were associated with new versions. If you develop software and periodically release updates to it, we recommend that you immediately envisage situations where your customers come to download them at the same time. The more your distribution weighs, the more you risk falling in such situations :)
Minimizing equipment failure risks
Despite the fact that before the transfer, the project was serviced by two servers, each of which could service the project alone, the possible failure of one of them would guarantee an idle time of tens of minutes and spoiled nerves. Cloud migration has reduced the dependence on physical iron.
Database Acceleration
As you can see from the graphs above , the database works quite intensively with the database and in peaks it can generate up to 750 iops for writing and up to 1500 iops for reading. The disk array used by the client before the move was unable to provide such performance and was a bottleneck in the system. Migration to the cloud allowed us to get rid of this “bottleneck”.
Reducing the dependence of developers on system administrator actions
The cloud control panel allowed developers to perform actions that were previously available only to the system administrator - creating new virtual servers, launching a clone copy to test the test feature, analyzing the load and changing the parameters of the instances. Data on all servers is now at hand, which becomes significant when there are a lot of machines.
Fast horizontal scaling
One of the results of the move, which made a great impression on the client, is the possibility of very fast horizontal scaling. The whole sequence of actions is as follows:
- Cloning and starting a combat server (5-10 seconds)
- Configuring round-robin DNS or adding one more destination in the nginx proxy config (1-3 minutes)
Economical effect
We will estimate the costs of hosting before and after the move.
Before: the project was hosted on two colocation servers with a configuration of 96 Gb RAM, 6 × 1 Tb SATA (hardware RAID10), 2x Xeon E5520. A dedicated server with a similar config can be found for 18-20 thousand rubles a month. We need two of them, so the cost of servers will be 36-40 thousand per month. A dedicated band of 300 Mbps will cost somewhere in 13-15 thousand rubles a month. The switch will probably cost another 3-5 thousand. Rounding, we can say that the total cost will be in the region of 52-60 thousand rubles per month.
After:the cost of 1GB of memory on fixed tariff plans is 500 rubles per month. The total cost of servers with a total RAM of 70 GB is 35 thousand rubles. In addition, it is necessary to include traffic that does not fit into the daily limit. Its cost will be approximately 8-12 thousand rubles per month. The result is 43-47 thousand rubles a month.
It would be nice to take into account the costs of installing and configuring (monitoring, SMS notifications, backups, virtualization) dedicated servers, but even without this, renting resources in the cloud in this particular case is 15-20% cheaper than renting physical servers for the same task.
Conclusion
When comparing two ways to host a single complex project - in the cloud and on dedicated servers - the cloud showed its convincing superiority. It turned out to be cheaper, more convenient, more flexible, helped to eliminate a number of weak points of the project and gave the client the opportunity to ignore many routine tasks, such as setting statistics, monitoring and backups.
Although so far we can name individual scenarios where the cloud will lose to dedicated servers, we are sure that over time there will be fewer and fewer such scenarios.
Traditionally, we suggest you register and take advantage of the FLOPS trial period (see the video tutorial) to evaluate the benefits yourself. The trial period is 500 rubles or 2 weeks (depending on what will end earlier). Thanks for attention.