How vendors IA-32 planted a pig to the creators of virtualization systems
It is unlikely that anyone will be surprised by the fact that not only Intel, but also companies such as AMD and VIA are involved in the development of the IA-32 architecture. More information can be found, for example, in an article by A. Fog . Today I plan to talk about one, in my opinion, not completely thought out ISA change introduced by AMD.

When thinking about AMD’s impact on the IA-32 architecture, the first thing I remember is the REX prefix and support for the 64-bit processor mode. And this is certainly a “positive” effect that made the IA-32 better. However, there were other interesting changes that I personally can’t call positive.
The coding of the IA-32 command system has evolved into an arch-complex structure due to a long evolution ( prefixes alonewhat are they worth). Talking about some decoding problems and their solutions in the articles “Does your disassembler work correctly?” And “How to deal with IA-32 code or features of the Simics decoder” , I forgot to mention a few interesting facts. The maximum possible length of IA-32 instructions is 15 bytes. There may be several prefixes in the encoding, and their number is actually limited only by the condition on the length of the instruction. In this case, the same prefix may occur several times, or, for example, there may be prefixes that can in no way affect this instruction. All of them will be simply ignored.
In my opinion, a good example illustrating this situation can be given on the basis of instructions
This, of course, is a very strange feature, but there’s no getting away from it. And some compilers can generally use prefixes to align code.

For many years, there has been instruction in Intel architecture
For example, for a number,
Let's see how it can be encoded:

Nothing interesting:
Now let's add some prefix to the encoding of this instruction ... Say
After doing some research, they found that the combination of a prefix
For the same input number
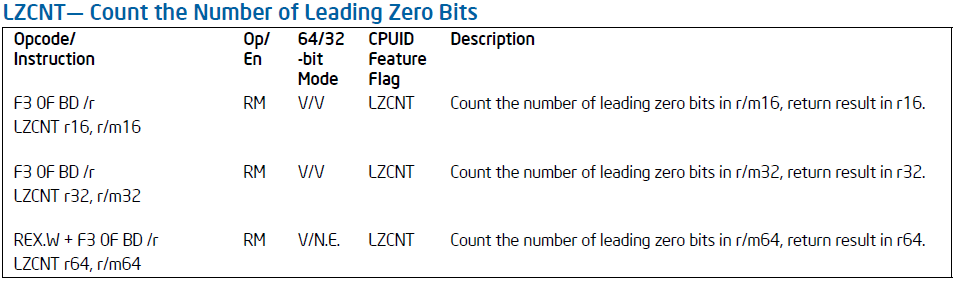
This instruction appeared as part of the ABM (Advanced Bit Manipulation) command extension , consisting of two instructions
Unfortunately, you cannot disable this instruction in any way.
The first set of commands
First, this change obviously violates backward compatibility. But this, in my opinion, is not her worst property. As mentioned above, according to AMD research, instructions
But the article is not about that, so now let's move away a bit from the typical needs of the average user and look at the needs of the developers.
As you know, most of the software stack is written and debugged on the simulator before baking the chip itself. So let's see how this change can affect the speed and accuracy of the simulation.
Of course, everyone wants to model as quickly as possible. The speed of a conventional interpreter is never enough. Everyone wants to load the BIOS in seconds, and the operating system in minutes. For this reason, the model is much more complicated, an optimizing binary translator appears , which allows to reduce the time of the simulator. But this is still not enough! They add support for direct execution of guest instructions on the host, which further complicates the model, while improving performance several times. Read more about the different modes of operation of the simulator can be found in the article "Software simulation of a microprocessor. Gearbox . ”
It is easy to guess that no problems should arise in the interpreter or in the translator. Problems may arise when using hardware virtualization . Neither
This leads to the fact that if you need to simulate a Haswell + processor, then on an older processor, such as Sandy Bridge, you can execute
They broke virtualization!

However, there is a solution to this problem - preview the page.
The existing virtualization mechanism allows you to limit the set of memory pages that guest software can access. Thus, we can allow direct execution of code located only on pages that do not contain
Such a change, of course, leads to a drop in productivity and complication of an already not so simple simulator. This, in my opinion, is precisely the negative effect of these changes.
PS Such an instruction is not the only one. Along with the BMI1 extension , Intel added a new instruction
When thinking about AMD’s impact on the IA-32 architecture, the first thing I remember is the REX prefix and support for the 64-bit processor mode. And this is certainly a “positive” effect that made the IA-32 better. However, there were other interesting changes that I personally can’t call positive.
The coding of the IA-32 command system has evolved into an arch-complex structure due to a long evolution ( prefixes alonewhat are they worth). Talking about some decoding problems and their solutions in the articles “Does your disassembler work correctly?” And “How to deal with IA-32 code or features of the Simics decoder” , I forgot to mention a few interesting facts. The maximum possible length of IA-32 instructions is 15 bytes. There may be several prefixes in the encoding, and their number is actually limited only by the condition on the length of the instruction. In this case, the same prefix may occur several times, or, for example, there may be prefixes that can in no way affect this instruction. All of them will be simply ignored.
In my opinion, a good example illustrating this situation can be given on the basis of instructions
NOP(No OPeration is an instruction that does nothing. Encoding 0x90). 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x66 0x90- this is also an instruction NOP, all 14 prefixes are 0x66simply ignored. This, of course, is a very strange feature, but there’s no getting away from it. And some compilers can generally use prefixes to align code.
On this the flowers are over, the berries begin.
For many years, there has been instruction in Intel architecture
BSR. It first appeared in the Intel 80386 processor . It finds the serial number of the most significant bit equal to 1. For example, for a number,
0x11aa00bbthis instruction will return 28. Let's see how it can be encoded:
Nothing interesting:
0x0F 0xBDand Mod R / M bytes for operands. Now let's add some prefix to the encoding of this instruction ... Say
0xF3. This will result in a valid instruction, the prefix will simply be ignored, as it relates to string operations or input / output instructions. No crime.What, in fact, did the comrades from AMD?
After doing some research, they found that the combination of a prefix
0xF3with an instruction BSRin the software is very rare, and they reprofiled this combination into a new instruction - LZCNTwhich calculates the number of leading zeros. For the same input number
0x11aa00bbin 32-bit mode, this instruction will return not 28, but 3. This instruction appeared as part of the ABM (Advanced Bit Manipulation) command extension , consisting of two instructions
LZCNTand POPCNT(in this command, I personally see nothing bad) , each of which has a separate bit in the CPUID . Unfortunately, you cannot disable this instruction in any way.
The first set of commands
ABMsupported AMD processor based on Barcelona microarchitecture . Intel has added instructions POPCNTto the Nehalem processor instruction set. And one would think that Intel would stop there, but no. The instruction LZCNTappeared in Haswell processors.Why is this bad?
First, this change obviously violates backward compatibility. But this, in my opinion, is not her worst property. As mentioned above, according to AMD research, instructions
BSRwith this prefix are extremely rare. And yet, purely theoretically, such a situation is possible. But the article is not about that, so now let's move away a bit from the typical needs of the average user and look at the needs of the developers.
As you know, most of the software stack is written and debugged on the simulator before baking the chip itself. So let's see how this change can affect the speed and accuracy of the simulation.
Of course, everyone wants to model as quickly as possible. The speed of a conventional interpreter is never enough. Everyone wants to load the BIOS in seconds, and the operating system in minutes. For this reason, the model is much more complicated, an optimizing binary translator appears , which allows to reduce the time of the simulator. But this is still not enough! They add support for direct execution of guest instructions on the host, which further complicates the model, while improving performance several times. Read more about the different modes of operation of the simulator can be found in the article "Software simulation of a microprocessor. Gearbox . ”
It is easy to guess that no problems should arise in the interpreter or in the translator. Problems may arise when using hardware virtualization . Neither
LZCNT, nor, moreover, BSRdoes not cause access to the VM monitor. This leads to the fact that if you need to simulate a Haswell + processor, then on an older processor, such as Sandy Bridge, you can execute
BSRinstead LZCNT. Conversely, if you want to simulate some simpler processor, for example, Quark on a host with Haswell, you run the risk of getting the opposite effect - LZCNTinstead BSR. They broke virtualization!
However, there is a solution to this problem - preview the page.
The existing virtualization mechanism allows you to limit the set of memory pages that guest software can access. Thus, we can allow direct execution of code located only on pages that do not contain
LZCNTinstruction encodings . And pre-scan each new page for the presence of these commands. Such a change, of course, leads to a drop in productivity and complication of an already not so simple simulator. This, in my opinion, is precisely the negative effect of these changes.
PS Such an instruction is not the only one. Along with the BMI1 extension , Intel added a new instruction
TZCNT, which is similarly associated with the team BSF.