Obtaining a morphic 3D face model based on a photo from an arbitrary perspective

A 3D morphable face model (3D Morphable Model, hereafter 3DMM) is a statistical model of the structure and texture of the face that is used by computer vision, computer graphics, in the analysis of human behavior and in plastic surgery.
The uniqueness of each facial feature makes modeling a human face a non-trivial task. 3DMM is created to obtain a face model in the space of explicit correspondences. This means pointwise correspondence between the resulting model and other models that allow morphing. In addition, low-level transformations should be reflected in 3DMM, such as the differences between a male face and a feminine, neutral facial expression from a smile.

Researchers at the University of Michigan offer the latest method for obtaining 3DMM face based on in-depth training. Using the high efficiency of deep neural networks to implement non-linear mappings, their method allows to obtain 3DMM based on a 2D image taken in an arbitrary setting.
Earlier approaches
Usually, 3DMM is obtained using a set of 3D face scans and a set of 2D images of these same faces. The generally accepted approach is to use dimension reduction when training with a teacher, which is performed by applying Principal Component Analysis (PCA) on a training dataset consisting of 3D facial scans and corresponding 2D images. When using linear models such as PCA, non-linear transformations and facial variations cannot be reflected in 3DMM. Moreover, to simulate accurate 3D face textures, a large amount of “3D information” is needed. Thus, the use of this approach is ineffective.
Proposed method
The idea of the proposed method is to use deep neural networks or, more specifically, convolutional neural networks (which are better suited for the problem under consideration and less costly in terms of computation time than multilayer perceptrons) for obtaining 3DMM. The coding neural network (encoder) accepts a face image at the input and generates the texture parameters and face albedo, with which two decoding neural networks (decoders) evaluate the texture and albedo.
As mentioned earlier, linear 3DMM has a number of problems, such as the need for 3D facial scans, the inability to use images taken from an arbitrary angle, and the limited accuracy of representation due to the use of linear PCA. In turn, the proposed method allows to obtain a non-linear 3DMM model based on 2D images of high-resolution faces taken from an arbitrary angle .
Planar view
In their approach, the researchers use a detailed 2D map of the face to represent its texture and albedo. They argue that spatial information plays an important role, since they use convolutional neural networks, and frontal face images contain little information about the lateral sides. That is why their choice fell on the planar presentation.
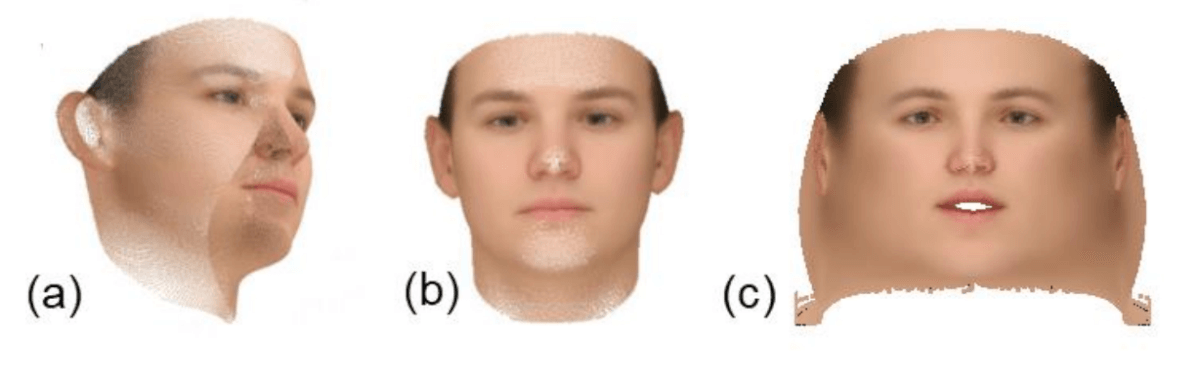
Three different representations of albedo. (a) - 3D representation, (c) - albedo as 2D frontal image of the face, (c) - planar representation.
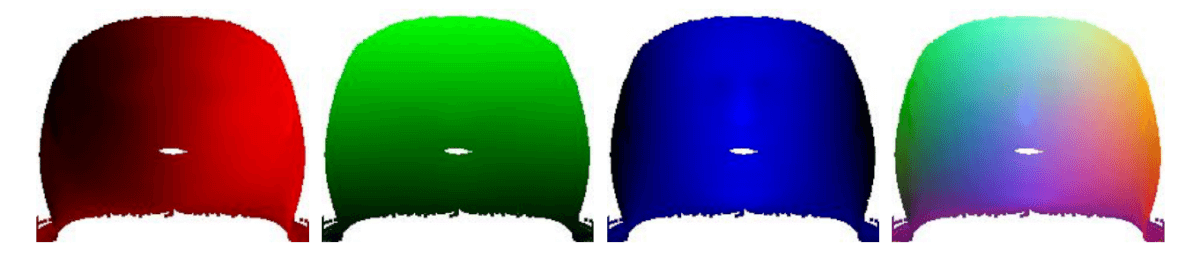
Planar view. x, y, z and the total representation of the texture.
Neural network architecture
The researchers designed a neural network, which, taking the image as input, encodes it into a vector of texture, albedo and lighting. Encoded hidden vectors for albedo and textures are decoded using two decoders, which use convolutional neural networks. At the output, the decoders give out the glare of the face, its albedo and 3D face texture. Using these parameters, a differentiated rendering layer generates a face model by combining 3D texture, albedo, lighting, and camera location parameters obtained by the encoder. The architecture is shown in the diagram below.
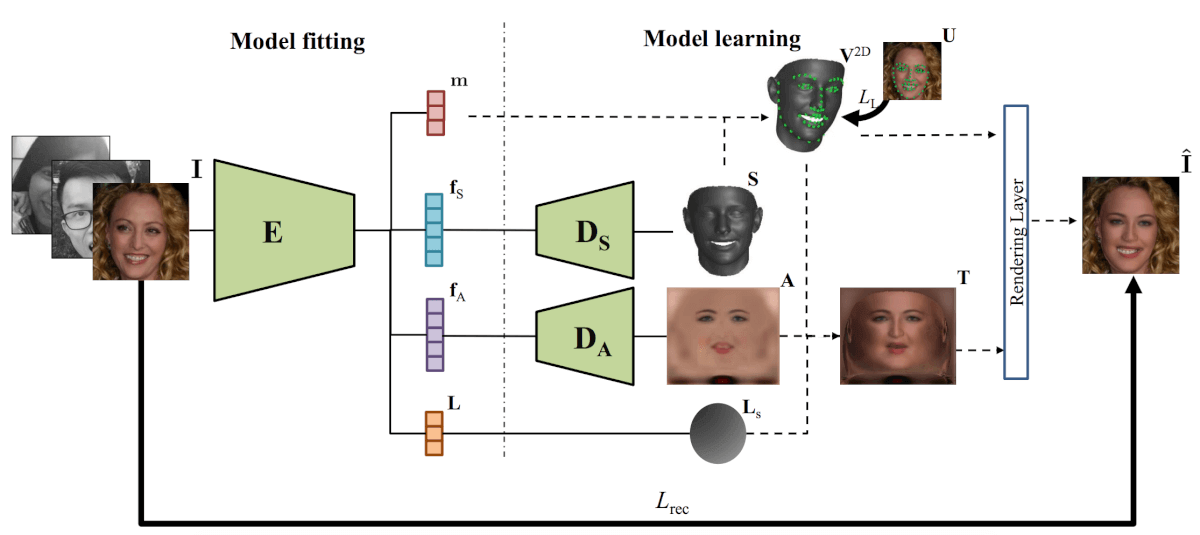
The architecture of the proposed method for obtaining nonlinear 3DMM
The resulting stable nonlinear 3DMM can be used for 2D face mapping and solving the problem of three-dimensional face reconstruction.
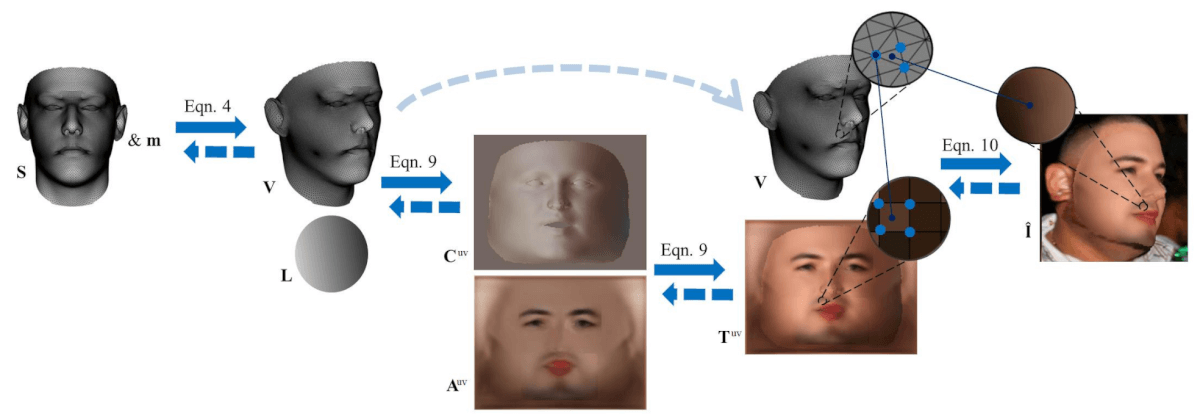
Rendering layer scheme
Comparison with other methods
The considered method was compared with other methods by the example of the following tasks: 2D overlay, 3D reconstruction and face editing . The proposed method is superior to other modern approaches to solve these problems. The results of the comparison are presented below.
2D face overlay
One of the applications of the method is the imposition of faces, which should significantly improve the analysis of faces in a number of tasks (for example, face recognition). The imposition of faces is not an easy task, but the method under consideration shows good results in solving it.

2D overlay results. Invisible marks are marked in red. The considered method reflects the unusual posture, lighting and facial expression.
3D face reconstruction
The considered method was also compared to the example of 3D facial reconstruction and showed outstanding results compared to other methods.

Quantitative comparison of 3D reconstruction results

The results of 3D reconstruction in comparison with the method of Sela and others. The proposed method saves facial hair and other facial features much better than this method.

The results of 3D reconstruction in comparison with VRN from Jackson and others on the example of the famous dataset CelebA.

The results of 3D reconstruction in comparison with the method of Tewari, etc. As can be seen, the proposed method solves the problem of compressing the face in the presence of different textures (such as facial hair).
Face editing
The discussed method splits the face image into separate elements and allows changing the face with the help of manipulations over them. The results of the work of this method when editing faces were evaluated on the example of such tasks as changing lighting and adding additional face elements.

The results of adding a beard. The first column contains the original images, the subsequent one - different degrees of change of the beard.

Comparison with Shu et al. (Second line). As you can see, the proposed method gives more realistic images, and in addition, the identity of the face is better preserved.
Conclusion
The proposed method, presumably, will be widely distributed, since it allows you to get accurate and stable 3DMM. Although 3DMM has been widely distributed since its inception, before the appearance of the method in question, there was no effective acquisition of this model using 2D images from an arbitrary angle.
The proposed method uses deep neural networks as an approximator for sustainable modeling of human faces with all their features. Such an unusual way to obtain 3DMM allows you to manipulate the image and can be used in many tasks, some of which were presented in the article.
Translation - Boris Rumyantsev.