SIEM depths: out-of-box correlations. Part 1: Pure marketing or unsolvable problem?
How often do you hear the statement that the correlation rules supplied by the SIEM manufacturer do not work and are deleted, or are turned off immediately after installing the product? At information security events, any section dedicated to SIEM, in one way or another, addresses this issue.
Let's take a chance and try to find a solution to the problem.

Most often, the main problem is that the correlation rules of the manufacturer SIEM are not initially adapted to the particular infrastructure of a particular customer.
Analyzing the problems voiced at different sites, it seems that the problem has no solution. Introducing SIEM, you still have to either very much refine what the manufacturer supplies, or throw out all the rules and write your own from scratch, and this problem is inherent in all solutions from any part of the Gartner quadrant.
Unwittingly you ask yourself: is it really that bad and is this Gordian knot impossible to cut? Is the expression “Correlation rules working out of the box” really just a marketing slogan for which there is nothing worth?
The article may interest you if:
In this series of articles we will list the main problems that hinder the implementation of the concept of “Correlation Rules Working Out of the Box”, and also try to describe a systematic approach to solve them.
At once I will make a reservation that by technical specialists this article can be characterized as: “water”, “about nothing”. All it is, but not quite. Before you deal with a difficult task, you want to first find out why it originated and what its solution gives us.
For a better understanding of the whole range of issues that will be presented, I will give the general structure of the whole cycle of articles:
Let's try to formulate our task in general terms: “I, as a customer who bought the SIEM solution, subscribe to update the rule base and pay the manufacturer (and sometimes the integrator) for support, I want the correlation rules to be promptly supplied to me would be in my SIEM and immediately benefited. " As for me, I’m quite sober a wish that is not burdened with some kind of architectural or structural technical limitations.
And now, attention, let's say that we have already solved all the problems and our task has already been completed. What does this give us?
Many technical specialists who came across the solution of the task and finished reading this place will immediately object: "Yes, of course there are pluses, but this is technically unrealizable." Personally, I think that the task is quite “lift-up” and already now, both in the western and Russian markets, there are SIEM, which contain all the elements necessary to solve it. I want to focus your attention on this - the products allow us not to solve the problem, but only contain all the necessary blocks, from which, as a designer, we can assemble the solution we are looking for.
I think this is very important, because Everything that will be described later can be implemented in almost any existing and mature SIEM.
Quite lyric, then we will talk in more detail about the problems that arise in the way of solving our problem.
In search of a solution to the above problem, let's see what problems we have to face. Allocation of the main problems will allow a better understanding of the issues, as well as develop a systematic approach to solve them.
The problems that we face are a snowball, each of which dramatically aggravates the situation. The set of all these problems leads to the fact that creating “Correlation Rules that work out of the box” is extremely difficult.
In general, problems are divided into the following four large blocks:

Let's now look at these issues in more detail.
This problem is easiest to describe using the following analogy.
The world around us is diverse and multifaceted, but our hearing and vision captures only a limited range of radiations. Having seen or heard some phenomenon, we build in our head the image of this event, operating with its already trimmed model. For example, our eye does not see in the infrared spectrum, and the ear does not detect vibrations below 16 Hz. This is the first transformation of the original phenomenon. In our model, our fantasy happens to bring what was not in the original phenomenon. We can tell the interlocutor about this phenomenon, using oral speech with all its limitations and peculiarities. This is the second transformation of the model. Finally, the interlocutor, in our words, decides to write about this phenomenon to his colleague in the messenger. This is the third and most likely the most dramatic transformation of the model in terms of information loss.
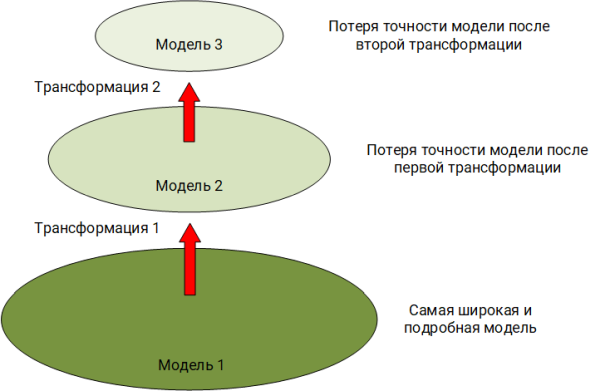
In the example described above, we observe a classical problem, to which the original “conceptual model” ( Boards B. Ya., Yakovlev S. A., System modeling ), by simplification, is transformed into another model while losing in detail.
Exactly the same thing happens in the world of events generated by software or hardware.
The explanation can serve this simplified picture already from our subject area:
Now what it looks like within our task.
We already have a simplified model (which has already lost a lot of details) of some phenomenon represented by a record in the log file — an event. SIEM reads this event, normalizes it by distributing data across the fields of its scheme. The number of fields in the scheme a priori cannot contain as many as is necessary to cover all possible semantics of all events from all sources, that is, at this step, the model is also transformed and data is lost.

It is important to understand that due to the presence of this problem, the expert, analyzing the logs in the SIEM or describing the correlation rule, sees not the initial event itself, but its at least twice distorted model, which has lost quite a lot of information. And, if the lost information is extremely important in investigating the incident and, as a result of writing the rule, it will have to be retrieved from somewhere. Finding the missing information to an expert is possible either by referring to the original source (raw event, memory dump, etc.), or by modeling the missing data in your head based on your experience, which is impossible to do directly from the correlation rules.
A good indicator of this problem is, if not strange, fields such as Customer device string, Datafield, or something else. These fields represent a kind of "dump" where, put the data that do not know where to put, or when all other suitable fields are simply filled.
The set of taxonomy fields, as a rule, reflects the model of the "world" as the SIEM developer sees the subject area. If the model is very “narrow”, then there will be a small number of fields in it and, when normalizing part of the events, they will simply be missed. This problem often has a SIEM with an initially fixed and dynamically non-expandable set of fields.
On the other hand, if there are too many fields, there are problems associated with a lack of understanding in which field it is necessary to put certain data of the original event. This situation entails the possibility of the emergence of semantic duplication, when semantically the same data of the original event fits immediately under several fields. This is often observed in solutions where the set of scheme fields can be dynamically expanded with any normalization module supported by a new source.
If there is a “combat” SIEM on hand, look at your events. How often do you use reserved additional fields (Custom device string, Datafield, etc.) during normalization? Many types of events with additional fields filled in indicate that you are observing the first problem. Now remember, or ask your colleagues, how often with the support of a new source, they had to add a new field, because the reserved ones were not enough? The answer to this question is an indicator of the second problem.
It is important to remember who and how normalizes events, because It plays an important role. Some sources are supported directly by the developer of the SIEM solution, part of the integrator who implemented the SIEM for you, and part by yourself. It is here that the following problem awaits us: Each of the participants interprets the meaning of the fields of the event map in their own way and therefore normalizes differently. Thus, semantically identical given different participants can decompose into different fields. Of course, there are a number of fields, the name of which does not allow for a dual interpretation. Suppose src_ip or dst_ip, but even with them there are difficulties. For example, in network events, is it necessary to change src_ip to dst_ip when normalizing incoming and outgoing connections within one session?
Based on the above, it is necessary to create a clear methodology for supporting sources, within which it would be explicitly stated:
As part of the solution of the task, the object of protection is our automated system (AS). Yes, it is the AU in the definition of GOST 34.003-90 , with all its processes, people and technology. This is an important note, we will return to it later in the following articles.
The word "mutation" is not chosen here by chance. Let's remember that in biology, mutation is understood as persistent changes in the genome. What is the AU genome? As part of this series of articles under the AU genome, I will understand its architecture and structure. A "lasting change" - nothing more than the result of the daily work of system administrators, network engineers, information security engineers. Under the actions of these changes, the AU every minute passes from one state to another. Some states are characterized by a greater level of security, some less. But now for us it does not matter.
It is important to understand that the AU model is not static, all parameters of which are described in the technical and working documentation, but a living, constantly mutated object. SIEM, when building a model of the object of protection within itself, must take this into account and be able to update it promptly and promptly, keeping up with the rate of mutation. And, if we want to make the correlation rules “work out of the box”, it is necessary that they take into account these mutations and always operate with the most actual picture of the “world”.
From the above “pyramid” it is clear that in developing the rules of correlation, we are forced to fight about all the problems that lie at lower levels. In the fight against these problems, the rules impart superfluous logic: additional filtering of events, checking for null values, converting data types and transforming this data (for example, extracting a domain name from the full name of a domain user), isolating information about who interacts with whom and within the event.
After all this, the rules are overgrown with such a number of sensible expressions, the search for substrings and regular expressions, that the logic of their work becomes clear only to their authors and that until the moment of their closest leave. Moreover, the constant changes of the automated system - mutations require regular updating of the rules to combat falls. Familiar picture?
As part of this series of articles, we will try to understand how to make the correlation rules work out of the box.
To solve the problem we have to face the following problems:
Many of these problems lie in the plane of constructing the correct event scheme — the set of fields and the process of normalizing events — the foundation of the correlation rules. Another part of the problem is solved by organizational and methodological methods. If we manage to find a solution to these problems, then the concept of working out-of-the-box rules will give a wide positive effect and raise the expertise that manufacturers put at SIEM to a new level.
What's next? In the next article we will try to deal with the loss of data when transforming the “world” model and think about what the required set of fields for the problem - the scheme should look like.
Cycle of articles:
SIEM depths: out-of-box correlations. Part 1: Pure marketing or unsolvable problem? ( This article )
SIEM Depths: Out-of-Box Correlations. Part 2. The data scheme as a reflection of the model of the "world"
Depth of SIEM: correlations out of the box. Part 3.1. Categorization of events
Depth SIEM: out-of-box correlations. Part 3.2. SIEM Depth event normalization methodology
: out-of-box correlations. Part 4. System model as a context of correlation rules
Let's take a chance and try to find a solution to the problem.
Most often, the main problem is that the correlation rules of the manufacturer SIEM are not initially adapted to the particular infrastructure of a particular customer.
Analyzing the problems voiced at different sites, it seems that the problem has no solution. Introducing SIEM, you still have to either very much refine what the manufacturer supplies, or throw out all the rules and write your own from scratch, and this problem is inherent in all solutions from any part of the Gartner quadrant.
Unwittingly you ask yourself: is it really that bad and is this Gordian knot impossible to cut? Is the expression “Correlation rules working out of the box” really just a marketing slogan for which there is nothing worth?
The article may interest you if:
- You are already working with some kind of SIEM solution.
- Only plan its implementation.
- Gathered to build your SIEM with blackjack and correlations based on the ELK stack, or something else.
What will the articles be about?
In this series of articles we will list the main problems that hinder the implementation of the concept of “Correlation Rules Working Out of the Box”, and also try to describe a systematic approach to solve them.
At once I will make a reservation that by technical specialists this article can be characterized as: “water”, “about nothing”. All it is, but not quite. Before you deal with a difficult task, you want to first find out why it originated and what its solution gives us.
For a better understanding of the whole range of issues that will be presented, I will give the general structure of the whole cycle of articles:
- Article 1: This article. Let's talk about the formulation of the problem and try to understand why we generally need the rules “Correlation rules that work out of the box.” The article will be ideological in nature and, if it becomes completely boring, you can skip it. But I do not advise doing this, because in the following articles I will refer to it often. Here we will discuss the main problems that stand in our way, and methods for their solution.
- Article 2: Hooray! It is here that we get to the first details of the proposed approach to solving the problem. We describe how our protected information system SIEM should “see”. Let's talk about what should be a set of fields necessary for the normalization of events.
- Article 3: We describe the role of categorizing events and how the methodology of event normalization is built on its basis. We show how IT events differ from IS events and why they should have different categorization principles. Let us give living examples of the work of this methodology.
- Article 4: We will closely look at the assets of which our automated system is composed and see how they affect the operability of the rules. Make sure that with them, too, is not so simple: they must be identified and constantly maintained up to date.
- Article 5: That for which everything was started. We describe an approach to writing correlation rules, based on all that was described in previous articles.
Task setting and why it is important
Let's try to formulate our task in general terms: “I, as a customer who bought the SIEM solution, subscribe to update the rule base and pay the manufacturer (and sometimes the integrator) for support, I want the correlation rules to be promptly supplied to me would be in my SIEM and immediately benefited. " As for me, I’m quite sober a wish that is not burdened with some kind of architectural or structural technical limitations.
And now, attention, let's say that we have already solved all the problems and our task has already been completed. What does this give us?
- First , we save labor costs of our specialists. Now they do not need to spend time studying the logic of each new rule and adapting it to the realities of a particular automated system.
- Secondly , we save the budget, because We do not ask the integrator, or someone else for a separate money to write or adapt the rules for us.
- Thirdly , all significant players in the SIEM market have research departments and departments that are purposefully engaged in analyzing information security threats. It is important to use their experience, especially if we pay for it.
- Fourth , we reduce the time of our reaction to new threats. I will not write about the eternity that passes between the appearance of a threat, the development of correlation rules for its detection and the implementation of a specific product from a specific customer, many articles have already been written on this topic.
- Fifth , it brings us all closer to the possibility of sharing among ourselves the unified rules that will work for any customer, within the framework of a specific SIEM solution, of course.
Many technical specialists who came across the solution of the task and finished reading this place will immediately object: "Yes, of course there are pluses, but this is technically unrealizable." Personally, I think that the task is quite “lift-up” and already now, both in the western and Russian markets, there are SIEM, which contain all the elements necessary to solve it. I want to focus your attention on this - the products allow us not to solve the problem, but only contain all the necessary blocks, from which, as a designer, we can assemble the solution we are looking for.
I think this is very important, because Everything that will be described later can be implemented in almost any existing and mature SIEM.
Quite lyric, then we will talk in more detail about the problems that arise in the way of solving our problem.
The challenges we face
In search of a solution to the above problem, let's see what problems we have to face. Allocation of the main problems will allow a better understanding of the issues, as well as develop a systematic approach to solve them.
The problems that we face are a snowball, each of which dramatically aggravates the situation. The set of all these problems leads to the fact that creating “Correlation Rules that work out of the box” is extremely difficult.
In general, problems are divided into the following four large blocks:
- Data loss during normalization associated with the transformation of the models of the "world".
- The lack of clear and generally accepted rules for the normalization of events.
- Permanent "mutation" of the object of protection - our automated system.
- Lack of rules for writing correlation rules.
Let's now look at these issues in more detail.
Transformation of the world model
This problem is easiest to describe using the following analogy.
The world around us is diverse and multifaceted, but our hearing and vision captures only a limited range of radiations. Having seen or heard some phenomenon, we build in our head the image of this event, operating with its already trimmed model. For example, our eye does not see in the infrared spectrum, and the ear does not detect vibrations below 16 Hz. This is the first transformation of the original phenomenon. In our model, our fantasy happens to bring what was not in the original phenomenon. We can tell the interlocutor about this phenomenon, using oral speech with all its limitations and peculiarities. This is the second transformation of the model. Finally, the interlocutor, in our words, decides to write about this phenomenon to his colleague in the messenger. This is the third and most likely the most dramatic transformation of the model in terms of information loss.
In the example described above, we observe a classical problem, to which the original “conceptual model” ( Boards B. Ya., Yakovlev S. A., System modeling ), by simplification, is transformed into another model while losing in detail.
Exactly the same thing happens in the world of events generated by software or hardware.
The explanation can serve this simplified picture already from our subject area:
- The first transformation of the model. An executable file was loaded into RAM, the OS began to carry out the instructions described in it. The operating system sends part of the information to the daemon / logging service (auditd, eventlog, etc.). If you do not include an extended audit of actions, then some of the information is not included in this daemon. But even with an extended audit, some of the information will still be discarded, because OS developers have decided that just this amount of information is enough to understand what is happening.
- The second transformation of the model. And now the daemon / service creates an event, writes information to the disk and here we understand that the length of the event string can be limited to a certain number of bytes. If the daemon / service maintains a structured log, then it contains some event schema with certain fields. What to do if there is so much information that it doesn’t fit in the “wired” scheme? That's right, most likely this information will be simply discarded.
Now what it looks like within our task.
We already have a simplified model (which has already lost a lot of details) of some phenomenon represented by a record in the log file — an event. SIEM reads this event, normalizes it by distributing data across the fields of its scheme. The number of fields in the scheme a priori cannot contain as many as is necessary to cover all possible semantics of all events from all sources, that is, at this step, the model is also transformed and data is lost.
It is important to understand that due to the presence of this problem, the expert, analyzing the logs in the SIEM or describing the correlation rule, sees not the initial event itself, but its at least twice distorted model, which has lost quite a lot of information. And, if the lost information is extremely important in investigating the incident and, as a result of writing the rule, it will have to be retrieved from somewhere. Finding the missing information to an expert is possible either by referring to the original source (raw event, memory dump, etc.), or by modeling the missing data in your head based on your experience, which is impossible to do directly from the correlation rules.
A good indicator of this problem is, if not strange, fields such as Customer device string, Datafield, or something else. These fields represent a kind of "dump" where, put the data that do not know where to put, or when all other suitable fields are simply filled.
The set of taxonomy fields, as a rule, reflects the model of the "world" as the SIEM developer sees the subject area. If the model is very “narrow”, then there will be a small number of fields in it and, when normalizing part of the events, they will simply be missed. This problem often has a SIEM with an initially fixed and dynamically non-expandable set of fields.
On the other hand, if there are too many fields, there are problems associated with a lack of understanding in which field it is necessary to put certain data of the original event. This situation entails the possibility of the emergence of semantic duplication, when semantically the same data of the original event fits immediately under several fields. This is often observed in solutions where the set of scheme fields can be dynamically expanded with any normalization module supported by a new source.
If there is a “combat” SIEM on hand, look at your events. How often do you use reserved additional fields (Custom device string, Datafield, etc.) during normalization? Many types of events with additional fields filled in indicate that you are observing the first problem. Now remember, or ask your colleagues, how often with the support of a new source, they had to add a new field, because the reserved ones were not enough? The answer to this question is an indicator of the second problem.
Event Normalization Methodology
It is important to remember who and how normalizes events, because It plays an important role. Some sources are supported directly by the developer of the SIEM solution, part of the integrator who implemented the SIEM for you, and part by yourself. It is here that the following problem awaits us: Each of the participants interprets the meaning of the fields of the event map in their own way and therefore normalizes differently. Thus, semantically identical given different participants can decompose into different fields. Of course, there are a number of fields, the name of which does not allow for a dual interpretation. Suppose src_ip or dst_ip, but even with them there are difficulties. For example, in network events, is it necessary to change src_ip to dst_ip when normalizing incoming and outgoing connections within one session?
Based on the above, it is necessary to create a clear methodology for supporting sources, within which it would be explicitly stated:
- What fields of the scheme are needed for.
- What data types to which fields correspond.
- What information is important to us within each type of event.
- What are the rules for filling the fields.
The object model of protection and its mutation
As part of the solution of the task, the object of protection is our automated system (AS). Yes, it is the AU in the definition of GOST 34.003-90 , with all its processes, people and technology. This is an important note, we will return to it later in the following articles.
The word "mutation" is not chosen here by chance. Let's remember that in biology, mutation is understood as persistent changes in the genome. What is the AU genome? As part of this series of articles under the AU genome, I will understand its architecture and structure. A "lasting change" - nothing more than the result of the daily work of system administrators, network engineers, information security engineers. Under the actions of these changes, the AU every minute passes from one state to another. Some states are characterized by a greater level of security, some less. But now for us it does not matter.
It is important to understand that the AU model is not static, all parameters of which are described in the technical and working documentation, but a living, constantly mutated object. SIEM, when building a model of the object of protection within itself, must take this into account and be able to update it promptly and promptly, keeping up with the rate of mutation. And, if we want to make the correlation rules “work out of the box”, it is necessary that they take into account these mutations and always operate with the most actual picture of the “world”.
Methodology for developing correlation rules
From the above “pyramid” it is clear that in developing the rules of correlation, we are forced to fight about all the problems that lie at lower levels. In the fight against these problems, the rules impart superfluous logic: additional filtering of events, checking for null values, converting data types and transforming this data (for example, extracting a domain name from the full name of a domain user), isolating information about who interacts with whom and within the event.
After all this, the rules are overgrown with such a number of sensible expressions, the search for substrings and regular expressions, that the logic of their work becomes clear only to their authors and that until the moment of their closest leave. Moreover, the constant changes of the automated system - mutations require regular updating of the rules to combat falls. Familiar picture?
Eventually
As part of this series of articles, we will try to understand how to make the correlation rules work out of the box.
To solve the problem we have to face the following problems:
- Data loss during the transformation of the “world” model at the stage of normalization.
- The lack of rosary defined methodology normalization.
- Constant mutation of the object of protection under the influence of people and processes.
- Lack of methodology for writing correlation rules.
Many of these problems lie in the plane of constructing the correct event scheme — the set of fields and the process of normalizing events — the foundation of the correlation rules. Another part of the problem is solved by organizational and methodological methods. If we manage to find a solution to these problems, then the concept of working out-of-the-box rules will give a wide positive effect and raise the expertise that manufacturers put at SIEM to a new level.
What's next? In the next article we will try to deal with the loss of data when transforming the “world” model and think about what the required set of fields for the problem - the scheme should look like.
Cycle of articles:
SIEM depths: out-of-box correlations. Part 1: Pure marketing or unsolvable problem? ( This article )
SIEM Depths: Out-of-Box Correlations. Part 2. The data scheme as a reflection of the model of the "world"
Depth of SIEM: correlations out of the box. Part 3.1. Categorization of events
Depth SIEM: out-of-box correlations. Part 3.2. SIEM Depth event normalization methodology
: out-of-box correlations. Part 4. System model as a context of correlation rules