Simple suffix tree
- Tutorial
 The suffix tree is a powerful structure that unexpectedly effectively solves myriads of complex search tasks on unstructured data arrays. Unfortunately, the well-known suffix tree construction algorithms (mainly the algorithm proposed by Esko Ukkonen) are quite complicated to understand and time-consuming to implement. Only relatively recently, in 2011, through the efforts of Dany Breslauer and Giuseppe Italiano, a relatively simple construction method was invented, which in fact is a simplified version of the algorithm of Peter Weiner, the man who invented suffix trees in 1973 . If you do not know what a suffix tree is or have always been afraid of it, then this is your chance to study it and at the same time master a relatively simple construction method.
The suffix tree is a powerful structure that unexpectedly effectively solves myriads of complex search tasks on unstructured data arrays. Unfortunately, the well-known suffix tree construction algorithms (mainly the algorithm proposed by Esko Ukkonen) are quite complicated to understand and time-consuming to implement. Only relatively recently, in 2011, through the efforts of Dany Breslauer and Giuseppe Italiano, a relatively simple construction method was invented, which in fact is a simplified version of the algorithm of Peter Weiner, the man who invented suffix trees in 1973 . If you do not know what a suffix tree is or have always been afraid of it, then this is your chance to study it and at the same time master a relatively simple construction method.Before proceeding to the description of the suffix tree, we will define the terminology. The input for the algorithm is a string s consisting of n characters s [0], s [1], ..., s [n-1]. Each character is a byte. Although, of course, everything described here will work for any other sequences: bits, double-byte Unicode characters, double-bit characters of DNA sequences and so on. In addition, we assume that s [n-1] is equal to the character 0, which is not found anywhere else in s. This last restriction serves only to simplify the narrative and, in fact, it is enough just to get rid of it. Lines of the form s [i..j] = s [i] s [i + 1] ... s [j], where i and j are some integers, are called, as usual, substrings. Substrings of the form s [i..n-1], where i is an integer, are called suffixes.
So, the main character.The suffix tree for string s is the minimum tree in terms of the number of vertices, each edge of which is marked with a non-empty substring s in such a way that each suffix s [i..n-1] can be read on the way from the root to some leaf and vice versa , each line read on the path from the root to some leaf is the suffix s. The easiest way to deal with this definition is for example (do not pay attention, for now, to pos, len and to):
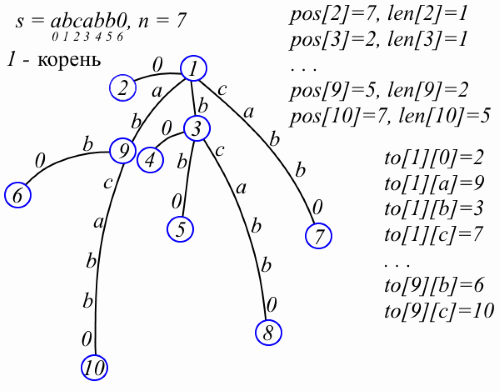
There are no more than 2n + 1 vertices in the suffix tree. You can verify this if you construct the tree by sequentially inserting suffixes: when you insert the next suffix, a new leaf and a vertex to which this leaf is attached can appear. Since s [n-1] is a special character, there are exactly n leaves in the suffix tree. We will number the vertices with integers. We will keep the father of vertex v in par [v]. The label on the edge from v to father v is stored as a pair of numbers: the length of the label len [v] and the position pos [v] immediately after this label in s, i.e. if the label is a string t, then t = s [pos [v] -len [v] .. pos [v] -1]. Let some vertex v have k children and t 1 , t 2 , ..., t k are the labels on the edges from v to children. Note that the first characters of the strings are t 1 , t 2 , ..., tk are pairwise different, which means references to children v can be stored in the map to [v], which displays the first character of the label in the corresponding offspring. I will avoid the object-oriented approach to describing structures in order to make the code shorter and to think “wow, what a compact code”. So, the suffix tree is represented as follows (now you can pay attention to pos, len, and to in the figure above):
int sz; //количество вершин в дереве
int pos[0..sz-1], len[0..sz-1], par[0..sz-1]; //par[v] – отец вершины v
std::map to[0..sz-1]; //to[v] – ссылки на детей вершины v
The first important property is that the suffix tree occupies O (n) memory.
A line written on the path from the root to the vertex v will be denoted by str (v); str (v) is used only in reasoning and is not explicitly stored anywhere.
Suffix tree examples
To get comfortable with the suffix tree and at the same time understand how to use it, consider a few examples.
Search for a substring in s
Perhaps the very first thing that comes to mind is to use the suffix tree to search for substrings. It’s quite simple to notice that string u is a substring of string s if and only if u can be read from the root of the suffix tree (because u = s [i..j] for some i and j and therefore the suffix s [i. .n-1] starts with u).
The number of different substrings in string s
Using the same reasoning, we can establish that each substring s corresponds to a certain position on the label of some edge of the suffix tree. So the number of different substrings is the number of such positions and it is equal to the sum len [v] over all vertices v except the root.
Data Compression LZ77
An example is more complicated. The idea of compressing LZ77 (google Lempel, Ziv) is simple and can be described with this pseudo-code:
for (int i = 0; i < n; i = j+1) //сжимаем строку s[0..n-1]
if (символ s[i] не встречался ещё в s[0..i-1]) {
j = i, записать в выходной файл символ s[i]; //точный формат записи зависит от реализации
} else {
j = max{j для которого найдётся d < i такое, что s[i..j] = s[d..d+j-i]};
d = позиция 0,1,…,i-1 такая, что s[d..d+j-i] = s[i..j];
записать в выходной файл пару чисел (j-i+1, i-d) //точный формат записи зависит от реализации
}
}
For example, the string “aababababaaab” will be encoded as “a (1,1) b (7,2) (3,10)” (note the “overlap” of the abababa lines). Of course, implementation details can vary greatly, but the basic idea is used in many compression algorithms. Using the suffix tree, you can compress s in a similar way in O (n). To do this, we supplement each vertex v of our tree with the field start [v] such that start [v] is equal to the smallest p for which s [p..p + | str (v) | -1] = str (v), where | str (v) | Is the length of str (v). It is clear that for leaves this value is easily calculated. For the remaining vertices, the start field is calculated by one traversal of the tree in depth, because start [v] = min {start [v 1 ], start [v 2 ], ..., start [v k ]}, where v 1 , v 2 , ..., v k- children v. Now, to calculate the next value of j in our compression algorithm, it is enough to read the string s [i..n-1] from the root until the current vertex v in the tree has start [v] <i; d can be chosen equal to the last such value start [v].
Building a suffix tree
I warn you in advance that despite the fact that the simplified Weiner algorithm is simpler than the Ukkonen algorithm and the classical Weiner algorithm, it is nevertheless still a non-trivial algorithm, and some effort must be made to understand it.
Overall plan. Prefix links
The algorithm starts from an empty tree and sequentially adds the suffixes s [n-1..n-1], s [n-2..n-1], ..., s [0..n-1] (just in case, that in the implementation under discussion, the extend function works correctly only if suffixes are added exactly in increasing order of lengths, starting with the shortest; that is, for example, the code “for (int i = n-3; i> = 0; i--) extend (i) "contains a bug):
for (int i = n-1; i >= 0; i--)
extend(i); //добавить в дерево суффикс s[i..n-1]
Thus, at the kth iteration of the loop, we have a suffix tree for the string s [n-k + 1..n-1] and add the suffix s [nk..n-1] to the tree. It is clear that adding a new longest suffix requires the insertion of one new leaf and, possibly, one new vertex that “splits” the old edge. The main problem is to find the position in the tree where the new sheet will be attached. To solve this problem, the suffix tree is supplemented with prefix links .
With each vertex v, we associate prefix links link [v] - a map that maps characters to vertex numbers as follows: for a symbol, link [v] [a] is defined if and only if there exists a vertex w in the tree such that str ( w) = a str (v) and in this case link [v] [a] = w. (If you were familiar with the classical Weiner algorithm, you noticed that our prefix links correspond to “explicit” classical prefix links, and “implicit” ones, it turns out, are not required at all; if you were familiar with the Ukkonen algorithm, you might notice that prefix links are reversed “suffix links”.) In the figure, prefix links are shown in red, and the rectangles contain symbols corresponding to the links (for the meaning of dummy vertex 0 see below).
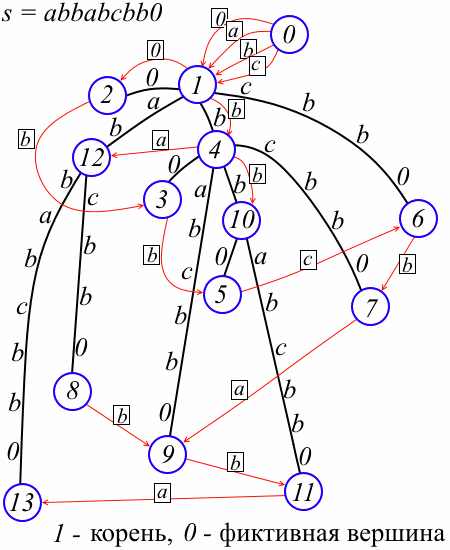
Thus, we have an additional structure:
std::map link[0..sz-1]; //префиксные ссылки
By definition, no more than one prefix link can lead to each vertex, whence we conclude that link occupies O (n) memory.
First, we discuss some technical nuances of the implementation presented here. The root of the tree is vertex 1, and 0 is a dummy vertex such that link [0] [a] = 1 for all characters a; in addition, par [1] = 0 and len [1] = 1. The dummy vertex does not carry any special semantic load, but allows you to handle some special cases in the same way. This will be explained in more detail below, but for now do not pay attention to it. We proceed to describe the algorithm for inserting a new suffix.
Algorithm
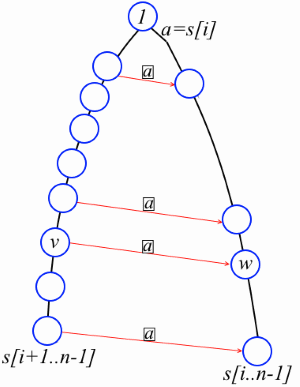 Lemma. Let i be a number from 0 to n-2. Consider the suffix tree of the string s [k..n-1], where k <= i. If w is a non-root vertex on the path from the root to the leaf corresponding to s [i..n-1], then on the path from the root to the leaf corresponding to s [i + 1..n-1], there is a vertex v such that s [i] str (v) = str (w) and link [v] [s [i]] = w (see the figure).
Lemma. Let i be a number from 0 to n-2. Consider the suffix tree of the string s [k..n-1], where k <= i. If w is a non-root vertex on the path from the root to the leaf corresponding to s [i..n-1], then on the path from the root to the leaf corresponding to s [i + 1..n-1], there is a vertex v such that s [i] str (v) = str (w) and link [v] [s [i]] = w (see the figure).Let us prove it. Denote str (w) = s [i] t. By the definition of a suffix tree, either w is a leaf or w has at least two descendants. If w is a leaf, then v is the leaf corresponding to the string s [i + 1..n-1]. Let w not be a leaf. Then there are some different symbols a and b such that to [w] [a] leads to one child w, and to [w] [b] to another. This means that s [i] ta and s [i] tb are substrings of s (at least one of them does not start at position i). Therefore, ta and tb are also substrings and there must be a vertex v in the tree such that str (v) = t. It is clear that v lies on the path to the sheet corresponding to s [i + 1..n-1], and, by the definition of prefix links, we have link [v] [s [i]] = w.
So, suppose we have a suffix tree for the string s [i + 1..n-1] and are going to add a sheet for the string s [i..n-1] and update the prefix links accordingly. See picture below. Denote by old the sheet corresponding to s [i + 1..n-1]. The “docking point” of the new sheet is the vertex w ', which may not have been created yet. By w we denote the vertex lying directly above w '(if w' is already in the tree, then w = w 'and in this case it is enough to just add a new leaf). For simplicity, we first consider the case when w is not a root. By the lemma, there is a vertex v on the path from old to the root such that link [v] [s [i]] = w.
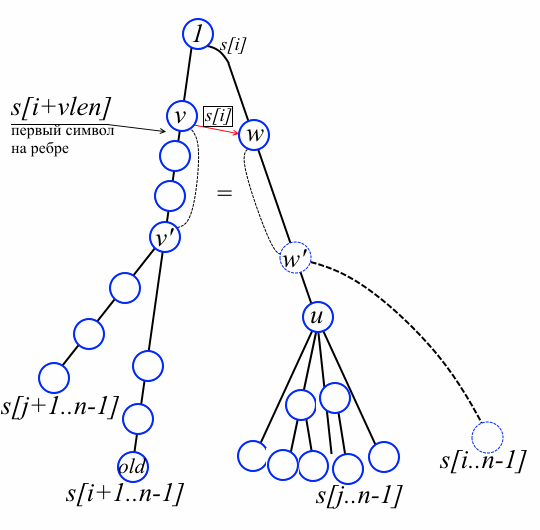
Fact 1. On the path from v to old, there are no v "'vertices such that link [v' '] [s [i]] is defined.Suppose, on the contrary, v '' is such a peak. Then the vertex link [v ''] [s [i]] is the ancestor of w 'and, at the same time, the descendant of w (by the definition of prefix links). But we chose w as the nearest peak from the docking point! Contradiction.
Our algorithm first of all finds v and w. At the same time, we compute the value | str (v) | +1 in the vlen variable and add all the vertices passed to the path stack - they will still come in handy. Note that at the end of the cycle s [i + vlen] is equal to the first character on the edge from v to offspring v on the path to old (see the figure above).
int v, vlen = n - i, old = sz – 1;//в нашей реализации old – это последняя вершина
for (v = old; !link[v].count(s[i]); v = par[v]) {
vlen -= len[v];
path.push(v);
}
int w = link[v][s[i]];
Fact 2. The vertex w 'is already present in the tree if and only if to [w] [s [i + vlen]] is not defined; in this case w = w '. If you meditate a little on the figure above and the remark about the meaning of the symbol s [i + vlen], this statement becomes obvious.
Fact 3. On the path from v to old, there is a vertex v 'such that s [i] str (v') = str (w '), even if w' does not exist yet.If w 'already exists in the tree, then the statement is obvious by fact 2 and v' = v. Suppose w 'has yet to be created. Denote u = to [w] [s [i + vlen]]. Choose an arbitrary leaf from the subtree with the root u; let this leaf correspond to the suffix s [j..n-1] for some j. The not yet inserted suffix s [i..n-1] and the suffix s [j..n-1] diverge at the "implicit" vertex w '. But the leaves corresponding to s [j + 1..n-1] and s [i + 1..n-1] are already represented in the tree and diverge at some vertex v '. It is clear that s [i] str (v ') = str (w'), which means that v 'lies in the path from v to old. At this point, it is worth looking at the figure above for the last time. We proceed to the main part of the algorithm.
Now that we have found w, our task is to find the docking point of a new sheet, i.e. in fact, we are looking for len [w '] and the vertex v'. In the case w = w ', it is enough to attach the sheet to w and draw a prefix link from old to this sheet. Consider the complex case when w! = W ', i.e. there is an edge from w by the symbol s [i + vlen]. We again denote u = to [w] [s [i + vlen]]. We sequentially get the vertices from the path stack until we find a vertex v 'such that s [i] str (v') = str (w '). How do we determine that we have found the right peak? Let v 1 , v 2 , ..., v k be the top vertices from the path stack with v k = v '(see the figure below). Denote by a p the first character on the edge following from v p to the descendant v pon the way to old. We define a 0 = s [i + vlen]. Let t be the label on the edge from w to u. The symbol t [len [v 1 ] + len [v 2 ] + ... + len [v p -1]] will be called the symbol corresponding to a p on t. Since w 'is the branch point of the suffix s [i..n-1] on the edge from w to u, the symbol a k is not equal to the corresponding symbol on t. On the other hand, for the same reason, for each p = 0,1, ..., k-1, the symbol a p is equal to the corresponding symbol on t. With a drawing, this reasoning will become clearer:
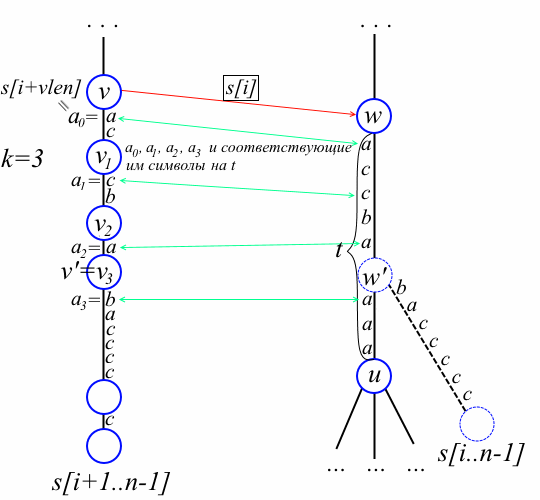
The remark obtained is the core of the simplified Weiner algorithm. Interestingly, it is enough for us to compare only the first character on the edges with the corresponding character on t, and not all the characters. Essentially, this is a simple observation - this is what Breslauer and Italiano noticed, but before, for some reason, no one had noticed. It remains to remember to draw a prefix link from v 'to w' and a prefix link from old to a new sheet. So, the algorithm inserts a new suffix s [i..n-1] as follows:
if (to[w].count(s[i + vlen])) { //если w != w’
int u = to[w][s[i + vlen]];
//sz – это новая вершина w’, которую мы создаём
//т.к. w!=w', условие s[pos[u] - len[u]] == s[i + vlen] на первой итерации цикла истинно
for (pos[sz] = pos[u] - len[u]; s[pos[sz]] == s[i + vlen]; pos[sz] += len[v]) {
v = path.top(); path.pop(); //очередной кандидат на v’
vlen += len[v];
}
Разбить ребро от w к u вершиной w’=sz; len[w’] = len[u]-(pos[u]-pos[sz])
link[v][s[i]] = sz; //суффиксная ссылка из v’ в w’
w = sz++; //устанавливаем w = w’ для вставки нового листа
}
//в этой точке переменная w содержит w'
link[old][s[i]] = sz; //суффиксная ссылка из old в новый лист sz
Присоединить лист sz к w; len[sz] = n – (i + vlen)
pos[sz++] = n; //pos для листьев всегда равен n
It remains to consider the special case when w is the root. This situation is completely similar, but some values are shifted by one. Of course, it would be possible to handle this case separately, but using a dummy vertex it is easier to do this and there is no need to write additional code. An important role at this point is played by the fact that par [1] = 0, len [1] = 1 and link [0] [a] = 1 for all characters a. Thus, the search cycle for the vertex v will necessarily end at the vertex 0, and the value len [1] = 1 will provide the necessary shift by one. It’s not difficult to understand the details and I will leave this as an exercise. I hope the secret meaning of the dummy peak on this should be cleared up. Combining everything together, we get the following solution:
void attach(int child, int parent, char c, int child_len) //вспомогательный метод
{
to[parent][c] = child;
len[child] = child_len;
par[child] = parent;
}
void extend(int i) //один шаг алгоритма; вызывать для i=n-1,n-2,...,0
{
int v, vlen = n - i, old = sz - 1;
for (v = old; !link[v].count(s[i]); v = par[v]) {
vlen -= len[v];
path.push(v);
} //по окончании цикла vlen = |str(v)|+1
int w = link[v][s[i]];
if (to[w].count(s[i + vlen])) { //если w != w’
int u = to[w][s[i + vlen]];
for (pos[sz] = pos[u]-len[u]; s[pos[sz]]==s[i + vlen]; pos[sz] += len[v]) {
v = path.top(); path.pop(); //очередной кандидат на v'
vlen += len[v];
}
attach(sz, w, s[pos[u] - len[u]], len[u] - (pos[u] - pos[sz])); //присоединить w'(=sz) к w
attach(u, sz, s[pos[sz]], pos[u] - pos[sz]); //присоединить u к w'(=sz)
w = link[v][s[i]] = sz++; //провести префиксную ссылку из v' в w'; установить w = w' для вставки нового листа
} //в этой точке переменная w содержит вершину w'
link[old][s[i]] = sz; //префиксная ссылка из старого листа к новому
attach(sz, w, s[i + vlen], n - (i + vlen)); //присоединить новый лист sz к вершине w'
pos[sz++] = n; //pos для листьев всегда равен n
}
void init()
{
len[1] = 1; pos[1] = -1; par[1] = 0; //важно, что par[1] = 0 и len[1] = 1 (!)
for (int c = 0; c < 256; c++)
link[0][c] = 1;//из вершины 0 префиксные ссылки по всем символам ведут в корень
}
Estimation of algorithm running time
In conclusion, we will understand why the whole described construction performs O (n) operations. The height of a vertex v is the number of vertices on the path from the root to v. Let me remind you that the step of the algorithm is to add a new suffix to the tree. Denote by h i the height of the vertex corresponding to the longest suffix at the ith step. Let k i be the number of vertices traversed from old to v at step i. How does the value of h i change ? If you look at the figure to the lemma once more, upon reflection, you will notice that h i <h i-1 - k i-1 + 2. The number of operations performed at the i-th step is proportional to k i , which means that as we only what they noticed, O (h i + 1 - h i+ 2). Hence it is obvious that the algorithm performs O (2n + (h 1 - h 2 ) + (h 2 - h 3 ) + ... + (h n-1 - h n )) = O (n) operations in total.
A small optimization note. Considering the access time to the map, the time of the Weiner algorithm (as well as Ukkonen) is O (n log m), where m is the number of different characters in the string. When the alphabet is very small, it is better to use arrays instead of maps to make Weiner truly linear.
In fairness, it is worth noting that the simplified Weiner algorithm (and classic and even more so) consumes about one and a half to two times more memory than Ukkonen. Tests also showed that the simplified Weiner works about 1.2 times slower (here it is slightly inferior to Ukkonen). Nevertheless, all these shortcomings are partly offset by the ease of implementation of Weiner and the lack of a large number of pitfalls.
Links in chronological order
P. Weiner. “Linear pattern matching algorithms” 1973 is Weiner's first article introducing a suffix tree and giving a linear algorithm.
E. McCreight. “A space economical suffix tree construction algorithm” 1976 is a more lightweight suffix tree construction algorithm.
E. Ukkonen. “On-line construction of suffix trees” 1995 - modification of the McCrate algorithm; the most popular modern algorithm.
D. Breslauer, G. Italiano. “Near real-time suffix tree construction via the fringe marked ancestor problem” 2013 (preliminary version in 2011) - the description of the simplified Weiner algorithm in this article takes one paragraph (remark on page 10), and everything else is devoted to another related problem.
PS Thanks to Misha Rubinchik and Oleg Merkuryev for their help in testing the algorithm and suggestions for improving the code.
PPS In conclusion, I quote
simple full implementation
//Для лучшей читаемости всё оформлено максимально просто, но в "полевых" условиях так писать не стоит.
//Помещайте всё внутри класса и выделяйте память по необходимости (врочем не мне вас учить).
#include
#include