OpenStack large-scale benchmarking: How we tested Mirantis OpenStack in SoftLayer
Posted by Oleg Gelbukh
It seems that one of the main issues that concern those involved in the cloud computing industry is the question of OpenStack's readiness for operation at the enterprise level under peak load. Common conversation topics include the stability and performance of OpenStack-based cloud services on a scale. But what does scale mean? What level of scale is applicable in the real world?
Our experience working with numerous OpenStack corporate clients shows that under a “large private cloud” we usually mean something numbering tens of thousands of virtual machines (VMs). Hundreds of users participating in hundreds of projects simultaneously manage these VMs. On such a scale, I think it is fair to say that the “private cloud”, in fact, is becoming a “virtual data center”.
A virtual data center has a number of significant advantages compared to a traditional physical one, not least of which is its flexibility. The period between receiving an order from a client and the availability of the requested infrastructure is reduced from a few days / hours to several minutes / seconds. On the other hand, you need to be sure of the stability of your IaaS platform under load.
We decided to evaluate the desired behavior of the Mirantis OpenStack platform under the load expected from it in such a virtual data center. Collaborating with our friends from IBM Softlayer, we created an infrastructure of 350 physical machines located in two places. To begin with, we wanted to establish a certain basic level under a service level agreement (SLA) for virtual data centers running on Mirantis OpenStack.
Obviously, size matters. But there were other questions regarding the OpenStack virtual data center in Softlayer, which we considered important to answer from the very beginning. For example:
• Can a cloud-based virtual data center serve hundreds of requests at once?
• Will the increase in the number of virtual servers in the virtual data center affect the user’s convenience?
To answer the first question, we needed to perform a series of tests with an increase in the number of simultaneously sent requests. The target of parallel processing at this stage of the benchmarking was set to 500. We approached the second question, specifying it in order to estimate how long server provisioning in our virtual data center will take, and, more importantly, how long it depends on the number existing servers.
Based on the above expectations, we developed the first set of benchmarks, the purpose of which is to test the infrastructure of Mirantis OpenStack Compute, a key component of the platform. Testing affected not only the Nova API and the scheduler, but also Compute agents working on the basis of hypervisor servers.
Since we carry out benchmark testing of the startup time, measuring the scalability of the OpenStack Compute service does not require creating any load inside the VM, therefore, you can use a flavor of the OpenStack platform with small resource requirements, a small way that you can load there, and without any or tasks performed on the VM. When using instance types defined by default for OpenStack, instance size does not have a significant impact on provisioning time. However, we needed to perform testing on real hardware in order to get a clear idea of the capabilities of the Nova Compute agent for processing requests under load.
The basic SLA parameters that we wanted to check are as follows:
• Dispersion of the loading time of virtual server instances, including the relationship between time and the number of virtual instances in the cloud database;
• Percentage of success of the loading process for our instances, in other words, how many requests out of 100 will fail for one reason or another.
As a target for this benchmark, we set 100 thousand virtual instances running in the same OpenStack cluster. With such a low-resource variety, our experiment can be compared with a specialized site for serving mobile applications. Another possible use case with such a workload is a test environment for a mobile application server with several thousand clients running non-independent embedded systems. We assumed that we could understand this with the help of several hundred servers generously provided to us by Softlayer for a limited period of time for use as a test bench.
We often hear the question: “How much hardware do you need?”. And often we jokingly respond to customers: "More." But it is clear that running hundreds of thousands of VMs requires sufficient hardware capacity. IBM Softlayer offers a fairly wide variety of configurations, and its employees were just like us, curious to see what OpenStack can provide at this level.
To determine the amount of resources required, we first set the type of instance, or variety, in terms of OpenStack: 1 virtual processor, 64MB of RAM and a 2GB hard drive (which is much smaller than, for example, the instance type m1.micro AWS). This is enough to load a Cirros test image.
Using an instance type with very modest resource requirements does not affect the test result, since for instance varieties / instance types specified in OpenStack by default, the instance size does not significantly affect provisioning time. The reason for this is that these varieties determine only the number of processors, the amount of RAM and the size of the files on the disk. These resources are typically provided with virtually zero dispersion depending on the size of the instance, because, unlike the AWS instance, which also provides additional services such as flexible block storage (EBS), OpenStack instances are isolated; creating short-term storage, in fact, is carried out by creating, for example, an empty file.
Total number of resources:
• 100,000 virtual processors (vCPU);
• 6250 Gb of random access memory;
• 200TB of disk space.
Therefore, we decided that a representative configuration of the computing server for this test would be a configuration with 4 physical cores (+4 for HT), 16Gb of RAM and 250GB of disk space. Since we are not going to allow any real load on the VM, we can easily redistribute the CPU in the ratio of 1:32 (twice as high as the overcommit rate set for OpenStack by default) and redistribute the RAM in the ratio of 1: 1.5 , which gives us a density equal to 250 virtual servers per physical node. With such non-standard redistribution coefficients, we only needed about 400 hardware servers to reach the target of 100 thousand VMs.
Knowing that the maximum load will be on our controllers, we set an advanced server configuration for them. Each controller had 128GB of RAM and a solid-state hard drive (SSD) for storing data, which allowed to accelerate the operation of the OpenStack state database based on the controller.
An interesting note: due to differences in the configuration of the Compute and Controller nodes, their provisioning was carried out in various SoftLayer data centers with a delay of 40ms between them; It will not be strange to expect that in a real cluster you can have exactly the same distributed configuration. Fortunately, due to the small delay between the Softlayer data centers, no significant influence of such a distributed architecture was observed during benchmarking.
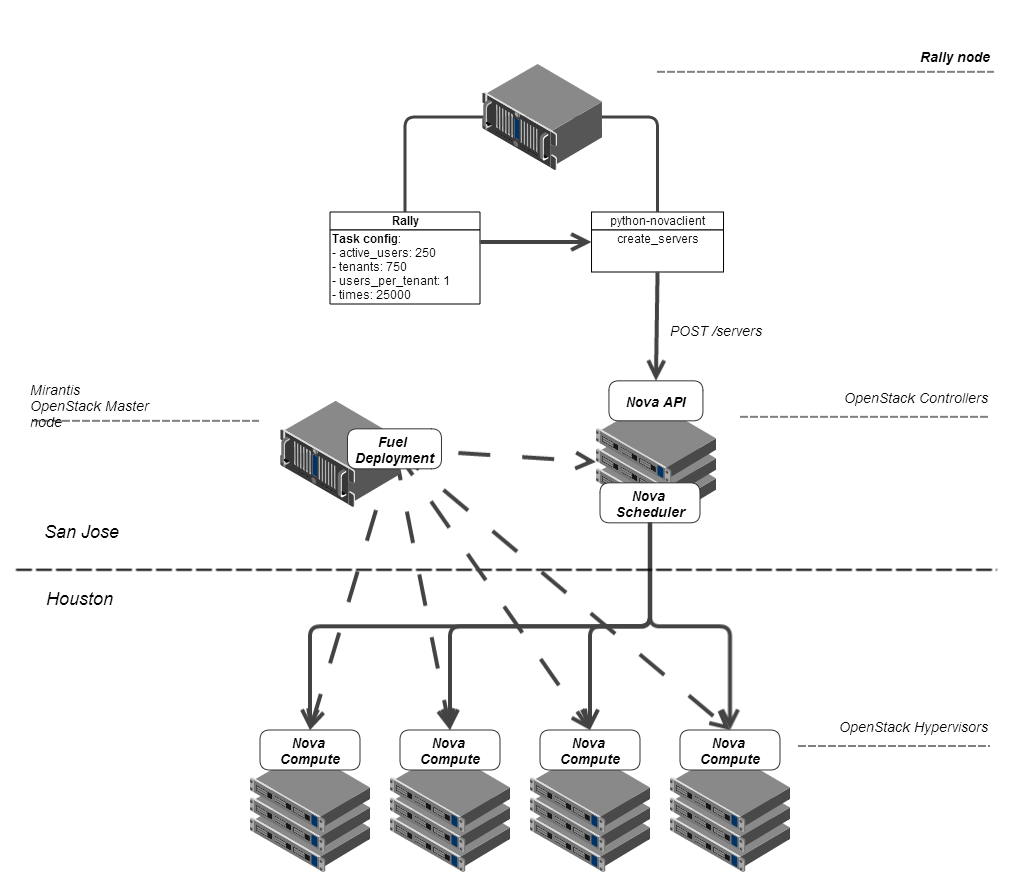
We used release 4.0 of the Mirantis OpenStack product , which includes OpenStack 2013.2 (Havana), and deployed it on servers provided by SoftLayer. To do this, we had to slightly change our Deployment Framework: since we could not upload Mirantis OpenStack ISO to SoftLayer, we simply copied the necessary code using rsync through a standard operating system image. After deployment, the cluster was ready for benchmarking.
Our configuration included only three OpenStack services: Compute (Nova), Image (Glance) and Identity (Keystone). This provided the basic functionality of the Compute service, sufficient for our use cases (testing the mobile platform).
To build the network, we used the Nova Network service in FlatDHCP mode with the Multi-host function enabled. In our simple use case (one private network, FlatDHCP network and no floating IPs), the functions are exactly the same as in Neutron (the Nova Network component, which has recently been restored from the “not recommended for use” status and returned to OpenStack upstream ).
During benchmark testing, we had to increase the values of some parameters of the default OpenStack configuration. The most important change is the connection pool size for the SQLAlchemy module (max_pool_size and max_overflow parameters in the nova.conf file). In all other aspects, we used the standard Mirantis OpenStack architecture of high availability, including a multi-host synchronous replication database (MySQL + Galera), a software load balancer for API services (haproxy) and corosync / pacemaker to ensure high availability at the level of IP
To actually perform the benchmark, we needed a testing tool; the logical choice was the Rally project as part of OpenStack . Rally automates test scripts in OpenStack, i.e. allows you to configure the steps that must be performed each time the test is performed, indicate the number of test starts, and also record the time it took to complete each request. With such functions, we could calculate the parameters that needed to be checked: the variance of the load time and the percentage of success.
We already had experience using Rally based on SoftLayer , which helped us a lot with this benchmark.
The reference configuration looks something like this:
{
"Execution": "continuous",
"config": {
"tenants": 500,
"users_per_tenant": 1,
"active_users": 250,
"times": 25000
},
"args": {
"image_id": "0aca7aff- b7d8-4176-a0b1-f498d9396c9f ”,
“ flavor_id ”: 1
}
}
The parameters in this configuration are as follows:
• execution - the operating mode of the benchmarking tool. If the value is “continuous”, the Rally workflow will issue the next request when the previous result is returned (or the timeout expires).
• tenants - the number of temporary Identity tenants (or projects, as they are now called in OpenStack) created in the OpenStack Identity service. This parameter reflects the number of projects that can correspond, for example, to versions of the tested mobile platform.
• users_per_tenant - the number of temporary end users created in each of the above temporary projects. Rally streams send real requests on behalf of users randomly selected from this list.
• active_users - the actual number of Rally worker threads. All these threads start simultaneously and start sending requests. This parameter reflects the number of users working with the cluster (in our case, creating instances) at any given time.
• times - the total number of requests sent during benchmarking. Based on this value, the percentage of success is determined.
• image_id and flavor_id - cluster-specific parameters used to start virtual servers. Rally uses the same image and variety for all servers in the reference iteration.
• nics - the number of networks to which each virtual server will be connected. By default, there is only one such network (this is the network specified for the project by default).
First, we set a stable speed for sending requests simultaneously. To do this, we created a set of reference configurations that differ only in two parameters — tenants and active_users — from 100 to 500. The number of VMs that needed to be started was 5000 or 25000. In order to save resources in the initial stages, we started with more A small cluster of 200 Compute servers plus 3 Controller servers.
The diagrams below show the dependence of the start time of a specific virtual server on the number of simultaneously executed requests.
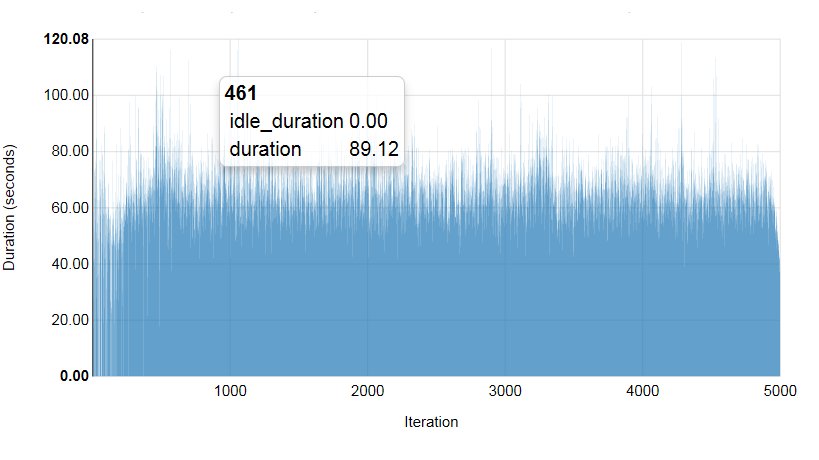
Test run 1.1. 100 concurrent sessions, 5000 VM
Total Success. (%) Min. (sec) Max. (sec) Average (sec) 90th percentile 95th percentile
5000 | 98.96 | 33.54 | 120.08 | 66.13 | 78.78 | 83.27
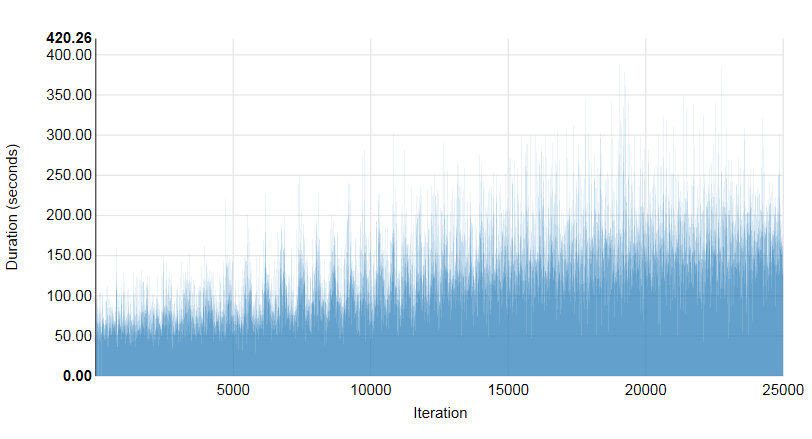
Test run 1.2. 250 concurrent sessions, 25,000 VM
total success. (%) Min. (sec) Max. (sec) Avg. (sec) 90th percentile 95th percentile
25000 | 99.96 | 26.83 | 420.26 | 130.25 | 201.1 | 226.04
A couple of times during the benchmarks, we encountered restrictions, but they were all eliminated by increasing the size of the connection pool in sqlalchemy (from 5 to 100 connections) and in haproxy (from 4000 to 16000 connections). In addition, several times Pacemaker erroneously detected a haproxy malfunction. The reason for this was the expired haproxy connection pool, which resulted in Pacemaker switching his virtual IP to another controller node. In both cases, the load balancer did not respond to failover. These problems were resolved by increasing the limiting number of compounds in haproxy.
The next step after this was to increase the number of VMs in the cloud to a target of 100,000. We set up a different set of configurations and ran Rally for it under test load with targets of 10,000, 25,000, 40,000, 50,000, 75,000 and 100,000 concurrent virtual servers. We found that the maximum stable level is 250 concurrent queries. At this stage, we added 150 more physical hosts to the cluster, the total number of Compute servers became 350 plus 3 Controller servers.
Based on the results, we made changes to the goals and reduced the target from 100,000 to 75,000 VMs. This allowed us to continue the experiment in the configuration of the 350 + 3 cluster.
At the established level of parallel execution, it took a total of more than 8 hours to deploy 75,000 virtual servers with the selected instance configuration. The diagram below shows the dependence of VM startup time on the number of running VMs during test execution.
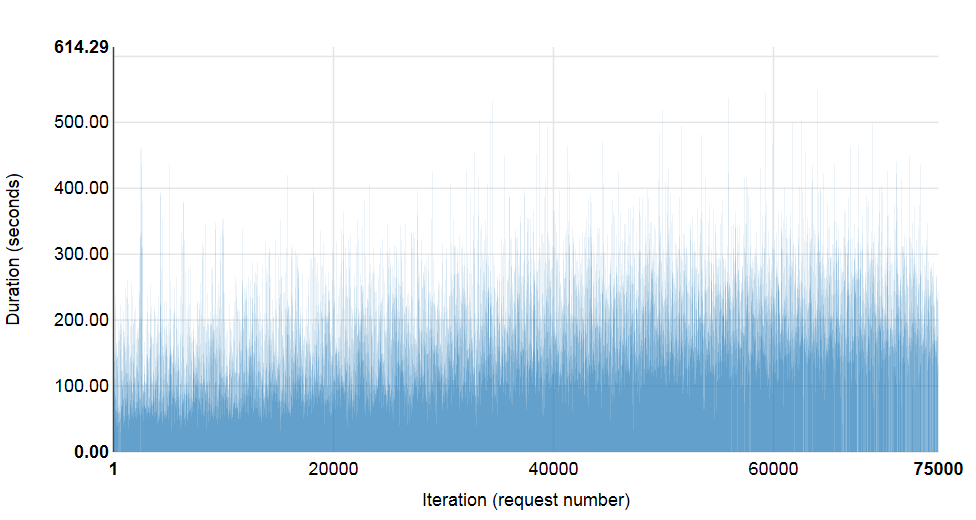
Test run 1.3. 500 concurrent sessions, 75,000 VM
Total Success. (%) Min. (sec) Max. (sec) Avg. (sec) 90th percentile 95th percentile
75000 | 98.57 | 23.63 | 614.29 | 197.6 | 283.93 | 318.96
As can be seen from the diagram, with 500 simultaneous connections, the average time per machine was less than 200 seconds, or an average of 250 VMs every 98.8 seconds.
The first stage of benchmarking allowed us to establish a basic level of expectations for SLA for a virtual data center configured for computing resources (unlike, for example, something that is resource intensive in terms of data storage and input / output operations). The Mirantis OpenStack platform is capable of simultaneously processing 500 requests and simultaneously supporting 250 requests to build a collection of 75,000 virtual server instances in one cluster. In the Compute architecture, virtual server instances do not assume the constant presence of attached blocks for virtual data storage, and they do not form complex network configurations. Please note that in order to be conservative, we did not endow the cluster with any OpenStack scalability features, such as cells, a modified scheduler, or dedicated clusters for OpenStack services or platform services (for example, a database or a queue). This benchmark is based on the standard Mirantis OpenStack architecture; any of the above modifications would raise productivity to an even higher level.
An important success factor, of course, was the quality of the IBM SoftLayer hardware and network infrastructure for benchmarking. Our results show that the Mirantis OpenStack platform can be used to control the operation of a large virtual data center using standard SoftLayer equipment. Although we did not measure the network parameters to estimate the load on the connections, we did not observe any impact. In addition, the quality of network connections between data centers in SoftLayer allowed us to easily build OpenStack clusters with multiple data centers.
At the next stage of the benchmarking project, we plan to use SoftLayer hardware with benchmark jobs running inside virtual server instances. We plan to set service level thresholds for disk and network I / O based on common workload profiles (web hosting, virtual desktop, build / development environment), and also evaluate the behavior of Mirantis OpenStack in each of these scenarios.
Original article in English .
It seems that one of the main issues that concern those involved in the cloud computing industry is the question of OpenStack's readiness for operation at the enterprise level under peak load. Common conversation topics include the stability and performance of OpenStack-based cloud services on a scale. But what does scale mean? What level of scale is applicable in the real world?
Our experience working with numerous OpenStack corporate clients shows that under a “large private cloud” we usually mean something numbering tens of thousands of virtual machines (VMs). Hundreds of users participating in hundreds of projects simultaneously manage these VMs. On such a scale, I think it is fair to say that the “private cloud”, in fact, is becoming a “virtual data center”.
A virtual data center has a number of significant advantages compared to a traditional physical one, not least of which is its flexibility. The period between receiving an order from a client and the availability of the requested infrastructure is reduced from a few days / hours to several minutes / seconds. On the other hand, you need to be sure of the stability of your IaaS platform under load.
Scaling Mirantis OpenStack based on Softlayer
We decided to evaluate the desired behavior of the Mirantis OpenStack platform under the load expected from it in such a virtual data center. Collaborating with our friends from IBM Softlayer, we created an infrastructure of 350 physical machines located in two places. To begin with, we wanted to establish a certain basic level under a service level agreement (SLA) for virtual data centers running on Mirantis OpenStack.
Obviously, size matters. But there were other questions regarding the OpenStack virtual data center in Softlayer, which we considered important to answer from the very beginning. For example:
• Can a cloud-based virtual data center serve hundreds of requests at once?
• Will the increase in the number of virtual servers in the virtual data center affect the user’s convenience?
To answer the first question, we needed to perform a series of tests with an increase in the number of simultaneously sent requests. The target of parallel processing at this stage of the benchmarking was set to 500. We approached the second question, specifying it in order to estimate how long server provisioning in our virtual data center will take, and, more importantly, how long it depends on the number existing servers.
Based on the above expectations, we developed the first set of benchmarks, the purpose of which is to test the infrastructure of Mirantis OpenStack Compute, a key component of the platform. Testing affected not only the Nova API and the scheduler, but also Compute agents working on the basis of hypervisor servers.
Since we carry out benchmark testing of the startup time, measuring the scalability of the OpenStack Compute service does not require creating any load inside the VM, therefore, you can use a flavor of the OpenStack platform with small resource requirements, a small way that you can load there, and without any or tasks performed on the VM. When using instance types defined by default for OpenStack, instance size does not have a significant impact on provisioning time. However, we needed to perform testing on real hardware in order to get a clear idea of the capabilities of the Nova Compute agent for processing requests under load.
The basic SLA parameters that we wanted to check are as follows:
• Dispersion of the loading time of virtual server instances, including the relationship between time and the number of virtual instances in the cloud database;
• Percentage of success of the loading process for our instances, in other words, how many requests out of 100 will fail for one reason or another.
As a target for this benchmark, we set 100 thousand virtual instances running in the same OpenStack cluster. With such a low-resource variety, our experiment can be compared with a specialized site for serving mobile applications. Another possible use case with such a workload is a test environment for a mobile application server with several thousand clients running non-independent embedded systems. We assumed that we could understand this with the help of several hundred servers generously provided to us by Softlayer for a limited period of time for use as a test bench.
Setting Up a Test Environment for OpenStack Benchmarking
We often hear the question: “How much hardware do you need?”. And often we jokingly respond to customers: "More." But it is clear that running hundreds of thousands of VMs requires sufficient hardware capacity. IBM Softlayer offers a fairly wide variety of configurations, and its employees were just like us, curious to see what OpenStack can provide at this level.
To determine the amount of resources required, we first set the type of instance, or variety, in terms of OpenStack: 1 virtual processor, 64MB of RAM and a 2GB hard drive (which is much smaller than, for example, the instance type m1.micro AWS). This is enough to load a Cirros test image.
Using an instance type with very modest resource requirements does not affect the test result, since for instance varieties / instance types specified in OpenStack by default, the instance size does not significantly affect provisioning time. The reason for this is that these varieties determine only the number of processors, the amount of RAM and the size of the files on the disk. These resources are typically provided with virtually zero dispersion depending on the size of the instance, because, unlike the AWS instance, which also provides additional services such as flexible block storage (EBS), OpenStack instances are isolated; creating short-term storage, in fact, is carried out by creating, for example, an empty file.
Total number of resources:
• 100,000 virtual processors (vCPU);
• 6250 Gb of random access memory;
• 200TB of disk space.
Therefore, we decided that a representative configuration of the computing server for this test would be a configuration with 4 physical cores (+4 for HT), 16Gb of RAM and 250GB of disk space. Since we are not going to allow any real load on the VM, we can easily redistribute the CPU in the ratio of 1:32 (twice as high as the overcommit rate set for OpenStack by default) and redistribute the RAM in the ratio of 1: 1.5 , which gives us a density equal to 250 virtual servers per physical node. With such non-standard redistribution coefficients, we only needed about 400 hardware servers to reach the target of 100 thousand VMs.
Knowing that the maximum load will be on our controllers, we set an advanced server configuration for them. Each controller had 128GB of RAM and a solid-state hard drive (SSD) for storing data, which allowed to accelerate the operation of the OpenStack state database based on the controller.
An interesting note: due to differences in the configuration of the Compute and Controller nodes, their provisioning was carried out in various SoftLayer data centers with a delay of 40ms between them; It will not be strange to expect that in a real cluster you can have exactly the same distributed configuration. Fortunately, due to the small delay between the Softlayer data centers, no significant influence of such a distributed architecture was observed during benchmarking.
OpenStack Details
We used release 4.0 of the Mirantis OpenStack product , which includes OpenStack 2013.2 (Havana), and deployed it on servers provided by SoftLayer. To do this, we had to slightly change our Deployment Framework: since we could not upload Mirantis OpenStack ISO to SoftLayer, we simply copied the necessary code using rsync through a standard operating system image. After deployment, the cluster was ready for benchmarking.
Our configuration included only three OpenStack services: Compute (Nova), Image (Glance) and Identity (Keystone). This provided the basic functionality of the Compute service, sufficient for our use cases (testing the mobile platform).
To build the network, we used the Nova Network service in FlatDHCP mode with the Multi-host function enabled. In our simple use case (one private network, FlatDHCP network and no floating IPs), the functions are exactly the same as in Neutron (the Nova Network component, which has recently been restored from the “not recommended for use” status and returned to OpenStack upstream ).
During benchmark testing, we had to increase the values of some parameters of the default OpenStack configuration. The most important change is the connection pool size for the SQLAlchemy module (max_pool_size and max_overflow parameters in the nova.conf file). In all other aspects, we used the standard Mirantis OpenStack architecture of high availability, including a multi-host synchronous replication database (MySQL + Galera), a software load balancer for API services (haproxy) and corosync / pacemaker to ensure high availability at the level of IP
Rally as a benchmarking tool
To actually perform the benchmark, we needed a testing tool; the logical choice was the Rally project as part of OpenStack . Rally automates test scripts in OpenStack, i.e. allows you to configure the steps that must be performed each time the test is performed, indicate the number of test starts, and also record the time it took to complete each request. With such functions, we could calculate the parameters that needed to be checked: the variance of the load time and the percentage of success.
We already had experience using Rally based on SoftLayer , which helped us a lot with this benchmark.
The reference configuration looks something like this:
{
"Execution": "continuous",
"config": {
"tenants": 500,
"users_per_tenant": 1,
"active_users": 250,
"times": 25000
},
"args": {
"image_id": "0aca7aff- b7d8-4176-a0b1-f498d9396c9f ”,
“ flavor_id ”: 1
}
}
The parameters in this configuration are as follows:
• execution - the operating mode of the benchmarking tool. If the value is “continuous”, the Rally workflow will issue the next request when the previous result is returned (or the timeout expires).
• tenants - the number of temporary Identity tenants (or projects, as they are now called in OpenStack) created in the OpenStack Identity service. This parameter reflects the number of projects that can correspond, for example, to versions of the tested mobile platform.
• users_per_tenant - the number of temporary end users created in each of the above temporary projects. Rally streams send real requests on behalf of users randomly selected from this list.
• active_users - the actual number of Rally worker threads. All these threads start simultaneously and start sending requests. This parameter reflects the number of users working with the cluster (in our case, creating instances) at any given time.
• times - the total number of requests sent during benchmarking. Based on this value, the percentage of success is determined.
• image_id and flavor_id - cluster-specific parameters used to start virtual servers. Rally uses the same image and variety for all servers in the reference iteration.
• nics - the number of networks to which each virtual server will be connected. By default, there is only one such network (this is the network specified for the project by default).
Benchmarking process
First, we set a stable speed for sending requests simultaneously. To do this, we created a set of reference configurations that differ only in two parameters — tenants and active_users — from 100 to 500. The number of VMs that needed to be started was 5000 or 25000. In order to save resources in the initial stages, we started with more A small cluster of 200 Compute servers plus 3 Controller servers.
The diagrams below show the dependence of the start time of a specific virtual server on the number of simultaneously executed requests.
Test run 1.1. 100 concurrent sessions, 5000 VM
Total Success. (%) Min. (sec) Max. (sec) Average (sec) 90th percentile 95th percentile
5000 | 98.96 | 33.54 | 120.08 | 66.13 | 78.78 | 83.27
Test run 1.2. 250 concurrent sessions, 25,000 VM
total success. (%) Min. (sec) Max. (sec) Avg. (sec) 90th percentile 95th percentile
25000 | 99.96 | 26.83 | 420.26 | 130.25 | 201.1 | 226.04
A couple of times during the benchmarks, we encountered restrictions, but they were all eliminated by increasing the size of the connection pool in sqlalchemy (from 5 to 100 connections) and in haproxy (from 4000 to 16000 connections). In addition, several times Pacemaker erroneously detected a haproxy malfunction. The reason for this was the expired haproxy connection pool, which resulted in Pacemaker switching his virtual IP to another controller node. In both cases, the load balancer did not respond to failover. These problems were resolved by increasing the limiting number of compounds in haproxy.
The next step after this was to increase the number of VMs in the cloud to a target of 100,000. We set up a different set of configurations and ran Rally for it under test load with targets of 10,000, 25,000, 40,000, 50,000, 75,000 and 100,000 concurrent virtual servers. We found that the maximum stable level is 250 concurrent queries. At this stage, we added 150 more physical hosts to the cluster, the total number of Compute servers became 350 plus 3 Controller servers.
Based on the results, we made changes to the goals and reduced the target from 100,000 to 75,000 VMs. This allowed us to continue the experiment in the configuration of the 350 + 3 cluster.
At the established level of parallel execution, it took a total of more than 8 hours to deploy 75,000 virtual servers with the selected instance configuration. The diagram below shows the dependence of VM startup time on the number of running VMs during test execution.
Test run 1.3. 500 concurrent sessions, 75,000 VM
Total Success. (%) Min. (sec) Max. (sec) Avg. (sec) 90th percentile 95th percentile
75000 | 98.57 | 23.63 | 614.29 | 197.6 | 283.93 | 318.96
As can be seen from the diagram, with 500 simultaneous connections, the average time per machine was less than 200 seconds, or an average of 250 VMs every 98.8 seconds.
Test results of Mirantis OpenStack based on Softlayer
The first stage of benchmarking allowed us to establish a basic level of expectations for SLA for a virtual data center configured for computing resources (unlike, for example, something that is resource intensive in terms of data storage and input / output operations). The Mirantis OpenStack platform is capable of simultaneously processing 500 requests and simultaneously supporting 250 requests to build a collection of 75,000 virtual server instances in one cluster. In the Compute architecture, virtual server instances do not assume the constant presence of attached blocks for virtual data storage, and they do not form complex network configurations. Please note that in order to be conservative, we did not endow the cluster with any OpenStack scalability features, such as cells, a modified scheduler, or dedicated clusters for OpenStack services or platform services (for example, a database or a queue). This benchmark is based on the standard Mirantis OpenStack architecture; any of the above modifications would raise productivity to an even higher level.
An important success factor, of course, was the quality of the IBM SoftLayer hardware and network infrastructure for benchmarking. Our results show that the Mirantis OpenStack platform can be used to control the operation of a large virtual data center using standard SoftLayer equipment. Although we did not measure the network parameters to estimate the load on the connections, we did not observe any impact. In addition, the quality of network connections between data centers in SoftLayer allowed us to easily build OpenStack clusters with multiple data centers.
Looking Ahead: Expanding OpenStack's Workload Range
At the next stage of the benchmarking project, we plan to use SoftLayer hardware with benchmark jobs running inside virtual server instances. We plan to set service level thresholds for disk and network I / O based on common workload profiles (web hosting, virtual desktop, build / development environment), and also evaluate the behavior of Mirantis OpenStack in each of these scenarios.
Original article in English .