How Discord simultaneously serves 2.5 million voice chats using WebRTC
- Transfer

From the very beginning, we planned engineering and product solutions in such a way that Discord would be well suited for voice chat while playing with friends. These solutions made it possible to scale the system strongly, with a small team and limited resources.
The article discusses the various technologies that Discord uses for audio / video chats.
For clarity, the whole group of users and channels we will call “group” (guild) - in the client they are called “servers”. Instead, the term “server” here refers to our server infrastructure.
Main principles
Each audio / video chat in Discord supports many participants. We watched a thousand people talk in turns in large group chats. Such support requires a client-server architecture because the peer-to-peer network becomes prohibitively expensive as the number of participants increases.
Routing network traffic through Discord servers also ensures that your IP address is never visible - and no one will launch a DDoS attack. Routing through servers has other advantages: for example, moderation. Administrators can quickly turn off audio and video offenders.
Client architecture
Discord works on many platforms.
- Web (Chrome / Firefox / Edge, etc.)
- Standalone application (Windows, MacOS, Linux)
- Phone (iOS / Android)
We can support all these platforms in only one way: through the reuse of WebRTC code . This specification for real-time communications includes network, audio, and video components. The standard is adopted by the World Wide Web Consortium and the Internet Engineering Group . WebRTC is available in all modern browsers and as a native library for embedding in applications.
Audio and video in Discord runs on WebRTC. Thus, the browser application relies on the WebRTC implementation in the browser. However, applications for desktops, iOS and Android use a single multimedia C ++ engine, built on top of their own WebRTC library, specially adapted to the needs of our users. This means that some functions in the application work better than in the browser. For example, in our native applications we can:
- Bypass the volume muted in Windows by default, when all applications are automatically muted when using the headset . This is undesirable when you and your friends go to the raid and coordinate actions in the Discord chat.
- Use your own volume control instead of the global operating system mixer.
- Process the original audio data to detect voice activity and broadcast audio and video in games.
- Reduce bandwidth and CPU consumption during periods of silence — even in the most numerous voice chats at any one time, only a few people speak at a time.
- Provide push-to-talk system-wide functionality.
- Send additional information along with audio-video packages (for example, the priority indicator in the chat).
Having your own version of WebRTC means frequent updates for all users: this is a time consuming process that we try to automate. However, these efforts are paying off with specific features for our players.
In Discord, voice and video communication is initiated by entering a voice channel or a call. That is, the connection is always initiated by the client - this reduces the complexity of the client and server parts, as well as increases resistance to errors. In the event of infrastructure failure, participants can simply reconnect to the new internal server.
Under our control
Control of the native library allows you to implement some functions differently than in the browser-based implementation of WebRTC.
First, WebRTC relies on the Session Description Protocol ( SDP ) to negotiate audio / video between participants (up to 10 KB for each packet exchange). In its own library, the lower level API from WebRTC (
webrtc::Call) is used to create both the inbound and outbound streams . When connected to a voice channel, there is a minimal exchange of information. This is the address and port of the backend server, encryption method, keys, codec and stream identification (about 1000 bytes).webrtc::AudioSendStream* createAudioSendStream(
uint32_t ssrc,
uint8_t payloadType,
webrtc::Transport* transport,
rtc::scoped_refptr<webrtc::AudioEncoderFactory> audioEncoderFactory,
webrtc::Call* call){
webrtc::AudioSendStream::Config config{transport};
config.rtp.ssrc = ssrc;
config.rtp.extensions = {{"urn:ietf:params:rtp-hdrext:ssrc-audio-level", 1}};
config.encoder_factory = audioEncoderFactory;
const webrtc::SdpAudioFormat kOpusFormat = {"opus", 48000, 2};
config.send_codec_spec =
webrtc::AudioSendStream::Config::SendCodecSpec(payloadType, kOpusFormat);
webrtc::AudioSendStream* audioStream = call->CreateAudioSendStream(config);
audioStream->Start();
return audioStream;
}In addition, WebRTC uses Interactive Connectivity Establishment ( ICE ) to determine the best route between members . Since we have each client connects to the server, we do not need ICE. This allows you to provide a much more reliable connection if you are behind NAT, and also to keep your IP address secret from other participants. Clients periodically ping so that the firewall maintains an open connection.
Finally, WebRTC uses the Secure Real-time Transport Protocol ( SRTP ) to encrypt media. Encryption keys are established using Datagram Transport Layer Security ( DTLS ) protocol based on standard TLS. The built-in WebRTC library allows you to implement your own transport layer using
webrtc::TransportAPI. Instead of DTLS / SRTP, we decided to use Salsa20 faster encryption . In addition, we do not send audio data during periods of silence — a frequent occurrence, especially in large chats. This leads to significant savings in bandwidth and CPU resources, however, both the client and the server should be ready at any time to stop receiving data and rewrite the sequence numbers of the audio / video packages.
Since the web application uses the browser-based implementation of the WebRTC API , SDP, ICE, DTLS, and SRTP cannot be abandoned here. The client and server exchange all the necessary information (less than 1200 bytes when exchanging packets) - and an SDP session is established for the clients based on this information. Backend is responsible for eliminating the differences between desktop and browser applications.
Backend architecture
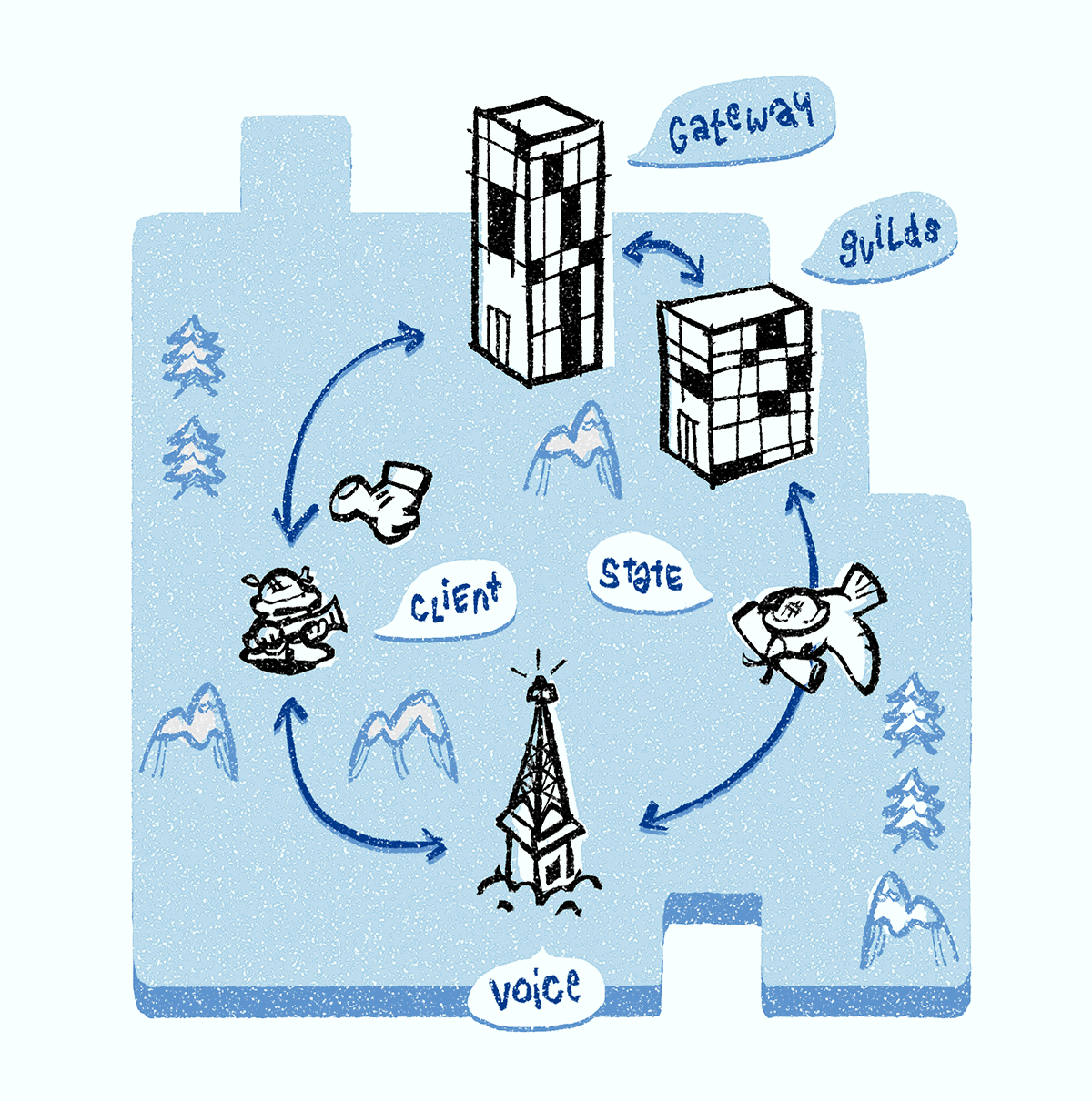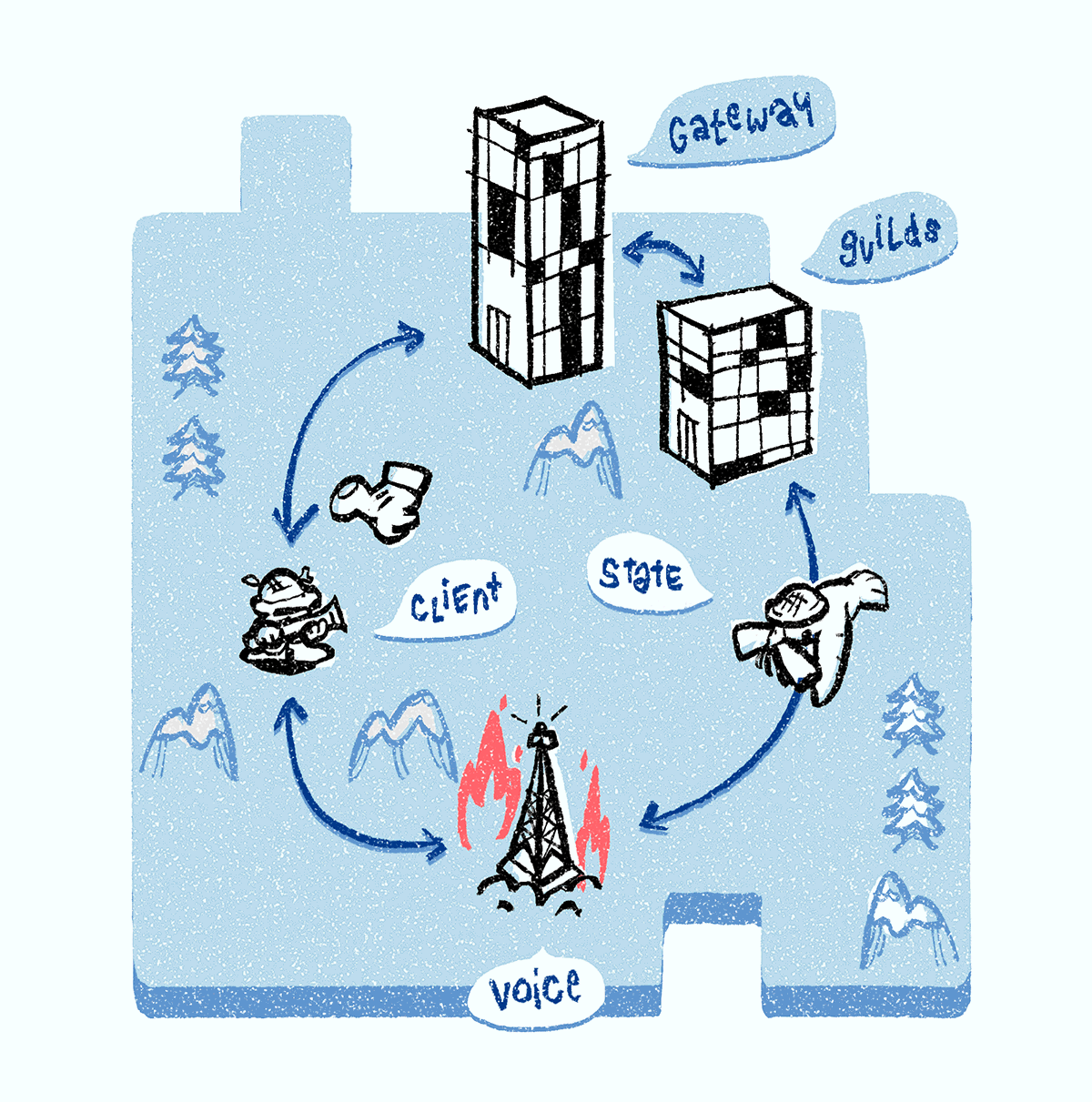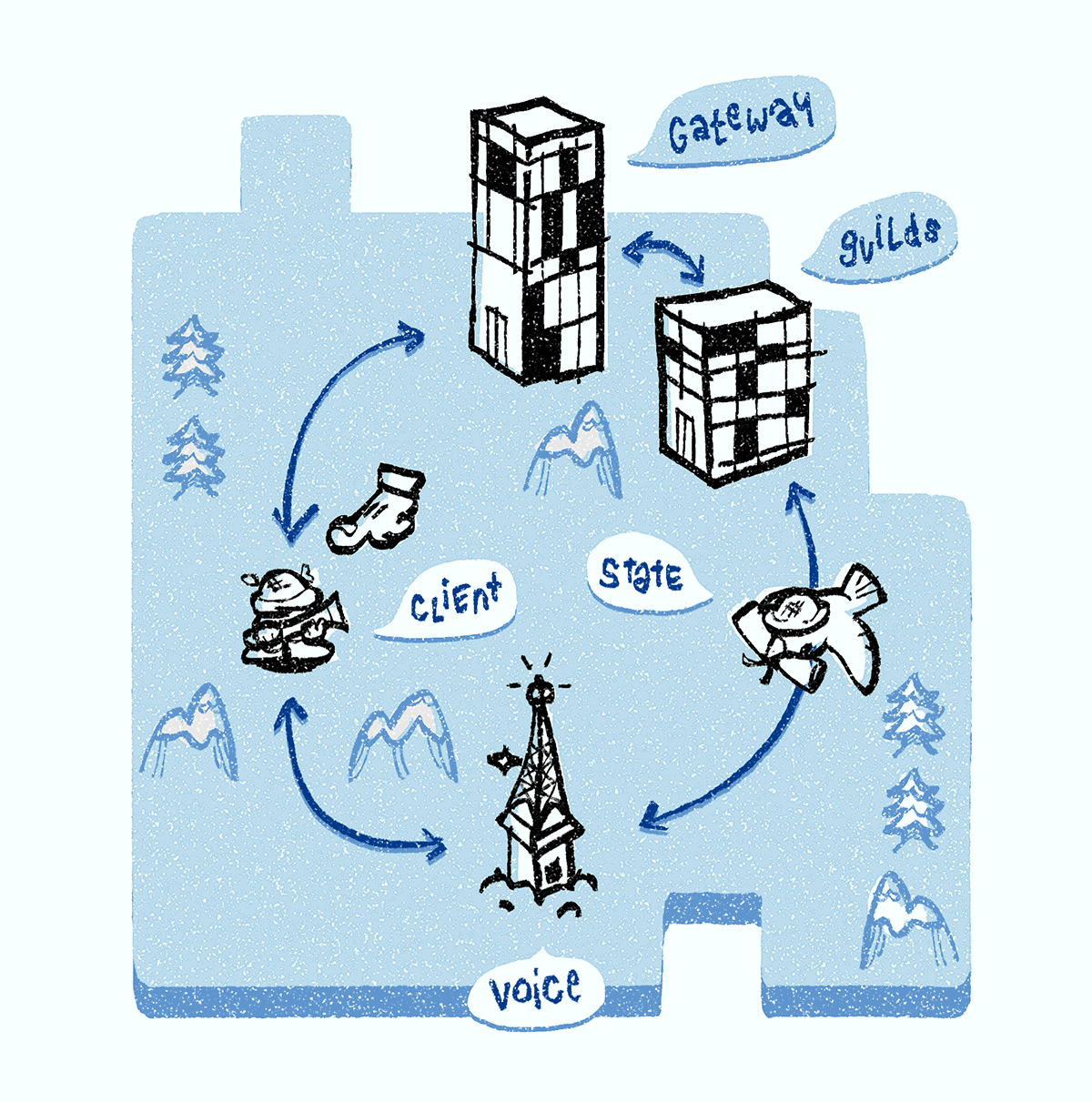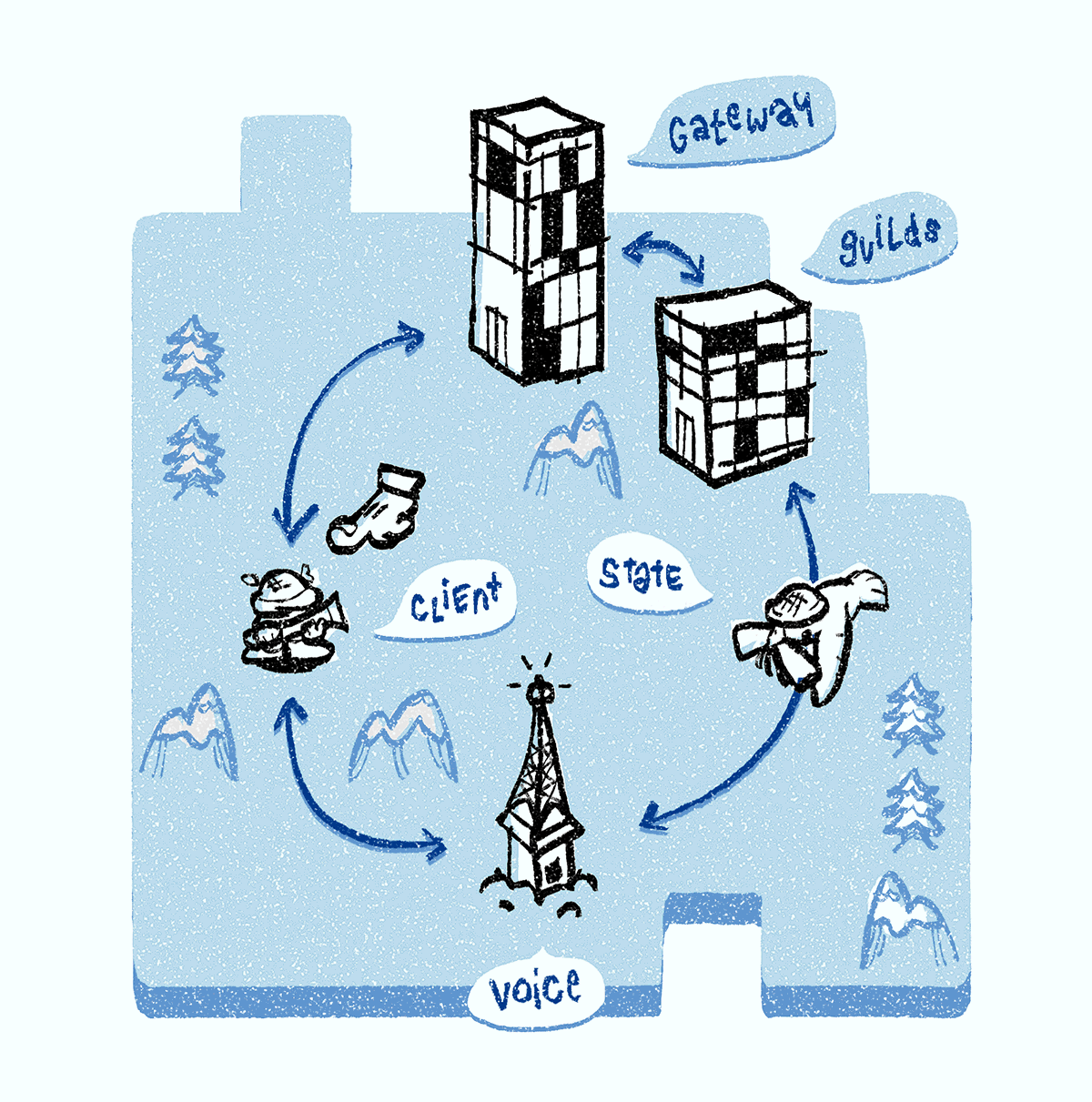
There are several voice chat services on the backend, but we will focus on three: Discord Gateway, Discord Guilds and Discord Voice. All of our signal servers are written in Elixir , which allows you to reuse code repeatedly.
When you are online, your client supports WebSocket connection to the gateway Discord Gateway (we call it the gateway WebSocket connection). Through this connection, your client receives events related to groups and channels, text messages, presence packets, and so on.
When connected to a voice channel, the connection status is displayed as a voice status object . The client updates this object through a gateway connection.
defmodule VoiceStates.VoiceState do
@type t :: %{
session_id: String.t(),
user_id: Number.t(),
channel_id: Number.t() | nil,
token: String.t() | nil,
mute: boolean,
deaf: boolean,
self_mute: boolean,
self_deaf: boolean,
self_video: boolean,
suppress: boolean
}
defstruct session_id: nil,
user_id: nil,
token: nil,
channel_id: nil,
mute: false,
deaf: false,
self_mute: false,
self_deaf: false,
self_video: false,
suppress: falseendWhen you connect to a voice channel, you are assigned one of the Discord Voice servers. He is responsible for the transmission of sound to each channel participant. All voice channels in a group are assigned to one server. If you're the first to chat, the Discord Guilds server is responsible for assigning the Discord Voice server to the whole group using the process described below.
Purpose of Discord Voice Server
Each Discord Voice server periodically reports its status and load. This information is placed on the service discovery system (we use etcd ), as discussed in the previous article .
Discord Guilds Server monitors the service discovery system and assigns the group the least used Discord Voice server in the region. When selected, all voice status objects (also supported by the Discord Guilds server) are transferred to the Discord Voice server so that it can configure audio / video redirection. Customers are notified of the selected Discord Voice server. Then the client opens the second WebSocket connection to the voice server (we call it voiceWebSocket), which is used to set up media forwarding and speech indication.
When the client displays Awaiting Endpoint status , it means that the Discord Guilds server is looking for the best Discord Voice server. The Voice Connected message means that the client successfully exchanged UDP packets with the selected Discord Voice server.
The Discord Voice server contains two components: a signaling module and a multimedia relay unit, called a selective forwarding unit ( SFU ). The signaling module fully controls the SFU and is responsible for the generation of flow identifiers and encryption keys, the redirection of speech indicators, etc.
Our SFU (in C ++) is responsible for directing audio and video traffic between channels. It is developed on its own: for our specific case, the SFU provides maximum performance and, thus, the greatest savings. When moderators violate (mute the server), their audio packs are not processed. SFU also works as a bridge between native and browser applications: it implements transport and encryption for both the browser and native applications, converting the packets during transmission. Finally, SFU is responsible for handling the RTCP protocol , which is used to optimize video quality. SFU collects and processes RTCP reports from recipients - and notifies senders which band is available for video transmission.
fault tolerance
Since we only have Discord Voice servers directly from the Internet, we’ll talk about them.
The signal module continuously monitors the SFU. If it fails, it is instantly restarted with a minimum pause in service (several lost packets). The status of the SFU is restored by the signal module without any interaction with the client. Although SFU crashes are rare, we use the same mechanism to upgrade SFU without interruption of service.
When the Discord Voice server crashes, it does not respond to the ping - and is removed from the service discovery system. The client also notices a server crash due to a broken WebSocket voice connection, then it requests ping of the voice servervia a gateway websocket connection. The Discord Guilds server confirms the failure, consults with the service discovery system, and assigns the group a new Discord Voice server. Then Discord Guilds send all voice status objects to a new voice server. All clients receive a notification about the new server and connect to it to start the multimedia setup.
Quite often, Discord Voice servers fall under DDoS (we see this by a rapid increase in incoming IP packets). In this case, we perform the same procedure as in the event of a server failure: remove it from the service discovery system, select a new server, transfer all voice state objects to it, and notify clients of the new server. When the DDoS attack subsides, the server returns to the service discovery system.
If the group owner decides to choose a new region for a voice, we perform a very similar procedure. Discord Guilds Server chooses the best available voice server in a new region by consulting with a service discovery system. Then he translates all voice state objects into it and notify clients of the new server. Clients break the current WebSocket connection to the old Discord Voice server and create a new connection to the new Discord Voice server.
Scaling
The entire Discord Gateway, Discord Guilds and Discord Voice infrastructure supports horizontal scaling. Discord Gateway and Discord Guilds work in the Google cloud.
We have more than 850 voice servers in 13 regions (located in more than 30 data centers) worldwide. This infrastructure provides greater redundancy in case of failures in data centers and DDoS. We work with several partners and use our physical servers in their data centers. Just recently added the region of South Africa. Thanks to engineering efforts in both the client and server architecture, Discord is now able to serve simultaneously more than 2.6 million users of voice chat with outgoing traffic of more than 220 Gbit / s and 120 million packets per second.
What's next?
We constantly monitor the quality of voice communication (metrics come from the client side to the backend servers). In the future, this information will help in the automatic detection and elimination of degradation.
Although we launched video chat and screencasts a year ago, but now they can only be used in personal messages. Compared to sound, video requires significantly more CPU power and throughput. The challenge is to balance the amount of bandwidth and CPU / GPU resources used to ensure the best video quality, especially when the group of gamers in the channel is on different devices. The solution can be Scalable Video Coding (SVC) technology , an extension of the H.264 / MPEG-4 AVC standard.
Screencasts require even more bandwidth than video, due to higher FPS and resolution than a regular webcam. We are currently working on supporting hardware video encoding in a desktop application.