Collective approval costs
- Transfer
This is a brief digression in the current series of articles on how to avoid introducing services for various entities. An interesting conversation at dinner led to thoughts that I decided to record.
In 1967, Jean Amdahl presented an argument against parallel computing. He argued that productivity growth is limited, since only part of the task is parallelizable. The size of the rest of the "sequential part" is different in different tasks, but it is always there. This argument became known as Amdal's law.
If you plot the "acceleration" of the task depending on the number of parallel processors allocated to it, you will see the following:
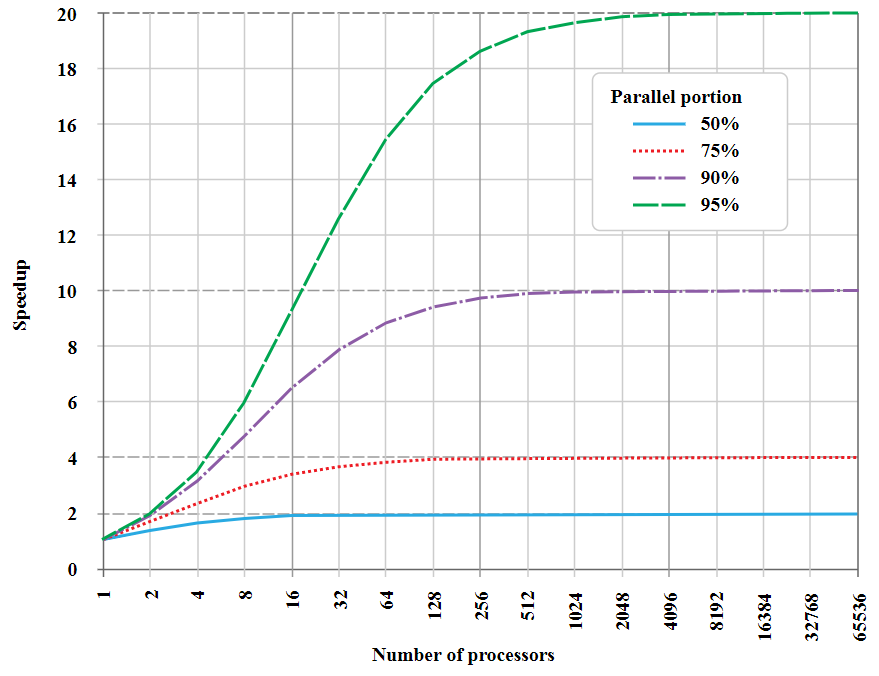
This is an asymptotic graph for a fragment that cannot be parallelized (the "sequential part"), so there is an upper limit for maximum acceleration
Amdal’s law is interesting that in 1969 there were actually very few multiprocessor systems. The formula is based on another principle: if the sequential part in the problem is zero, then this is not one task, but several.
Neil Gunter expanded Amdahl's law on the basis of observations of the measurements of performance of many cars and brought universal scaling law (Universal Scalability Law, USL). It uses two parameters: one for “competition” (which is similar to the sequential part), and the second for “inconsistency” (incoherence). Inconsistency correlates with the time spent on restoring consistency, that is, a common world view of different processors.
In a single CPU, negotiation overhead occurs due to caching. When one kernel changes a cache line, it tells other kernels to extract that line from the cache. If everyone needs the same string, they spend time loading it from the main memory. (This is a slightly simplified description ... but in a more precise formulation, there is still the cost of coordination).
At all nodes of the database, there are matching costs due to matching algorithms and preserving the sequence of data. The penalty is paid when the data changes (as in the case of transactional databases) or when reading data in the case of finally agreed upon repositories.
If you plot the USL plot depending on the number of processors, the following green line will
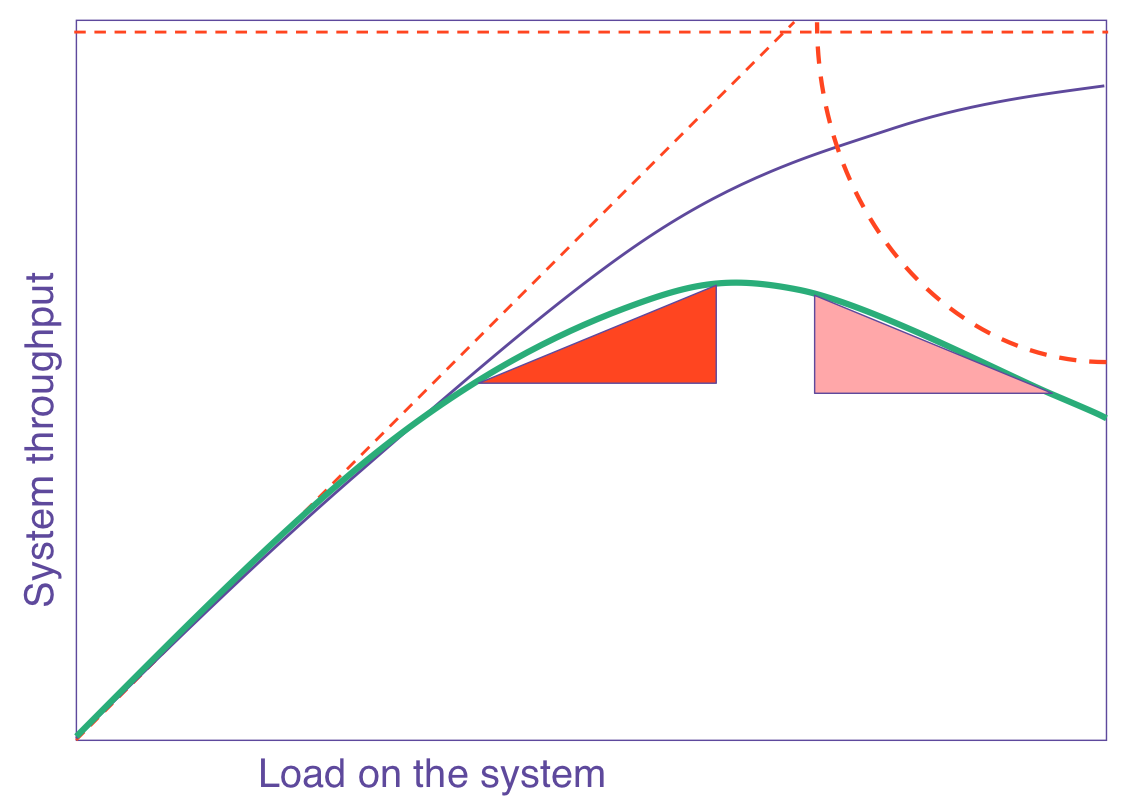
appear : The purple line shows what Amdahl’s law would have predicted.
Pay attention that the green line reaches its peak and then decreases. This means that there is a certain number of nodes at which performance is maximum. Add more processors - and performance decreases . I saw this in real load testing.
People often want to increase the number of processors and improve performance. This can be done in two ways:
Let's try an analogy. If the computational “task” is a project, then the number of people in the project can be represented as the number of “processors” performing the work.
In this case, the sequential part is a piece of work that can be done only sequentially, step by step. This may be a topic for a future article, but now we are not interested in the essence of the consistent part.
It seems that we see a direct analogy with the costs of coordination. Regardless of the time that team members spend on restoring a common world view, the costs of reconciliation are present.
For five people in a room, these costs are minimal. Five minutes of drawing with a marker on the board once a week or so.
For a large team in several time zones, a fine can grow and be formalized. Documents and walkthroughs. Presentations for the team and so on.
In some architectures, reconciliation is not so important. Imagine a team with employees on three continents, but each is working on one service that uses data in a strictly defined format and creates data in a strictly defined format. They do not need consistency regarding changes in processes, but consistency is needed regarding any changes in formats.
Sometimes tools and languages can change the costs of negotiation. One of the arguments in favor of static typing is that it helps to interact in a team. In essence, types in code are the mechanism for translating changes to the model of the world. In a dynamically typed language, we either need secondary artifacts (unit tests or chat messages), or we need to create boundaries where some departments very rarely restore consistency with others.
All these methods are aimed at reducing the costs of coordination. Recall that excessive scaling causes a decrease in throughput. So if you have high negotiation costs and too many people, then the team as a whole is slower. I saw teams where it seemed we could cut half the people and work twice as fast. USL and reconciliation costs now help you understand why this is happening - it’s not just garbage collection. It is about reducing the overhead of the exchange of mental models.
In The Loop of Fear, I referred to code bases where developers knew about the need for large-scale changes, but were afraid to accidentally harm. This means that the overblown team never reachedconsistency. It seems that after a loss, consistency is very difficult to restore. This means that it is impossible to ignore the costs of coordination.
In my opinion, USL explains the interest in microservices. By splitting a large system into smaller and smaller parts, which are independently deployed, you reduce the successive part of the work. In a large system with a large number of participants, the consistent part depends on the amount of effort required for integration, testing and deployment. The advantage of microservices is that they do not need integration work, integration testing, or a delay in synchronized deployment.
But the costs of negotiation mean that you may not get the desired acceleration. Perhaps, here the analogy is a bit tight, but I think that we can consider changes in the interface between microservices as requiring reconciliation between the teams. If this is too much, then you will not get the desired benefits from microservices.
My suggestion: look at the architecture used, language, tools, and command. Think about where time is lost to restore consistency, when people make changes to the system model of the world.
Look for breaks . Gaps between internal system boundaries and splits within the team.
Use the environment to communicate changes so that the alignment process takes place for everyone, not individually.
Look at the communication of your team. How much time and effort does it take to ensure consistency? Maybe make small changes and reduce the need for it?
Amdal's Law
In 1967, Jean Amdahl presented an argument against parallel computing. He argued that productivity growth is limited, since only part of the task is parallelizable. The size of the rest of the "sequential part" is different in different tasks, but it is always there. This argument became known as Amdal's law.
If you plot the "acceleration" of the task depending on the number of parallel processors allocated to it, you will see the following:
This is an asymptotic graph for a fragment that cannot be parallelized (the "sequential part"), so there is an upper limit for maximum acceleration
From Amdal to USL
Amdal’s law is interesting that in 1969 there were actually very few multiprocessor systems. The formula is based on another principle: if the sequential part in the problem is zero, then this is not one task, but several.
Neil Gunter expanded Amdahl's law on the basis of observations of the measurements of performance of many cars and brought universal scaling law (Universal Scalability Law, USL). It uses two parameters: one for “competition” (which is similar to the sequential part), and the second for “inconsistency” (incoherence). Inconsistency correlates with the time spent on restoring consistency, that is, a common world view of different processors.
In a single CPU, negotiation overhead occurs due to caching. When one kernel changes a cache line, it tells other kernels to extract that line from the cache. If everyone needs the same string, they spend time loading it from the main memory. (This is a slightly simplified description ... but in a more precise formulation, there is still the cost of coordination).
At all nodes of the database, there are matching costs due to matching algorithms and preserving the sequence of data. The penalty is paid when the data changes (as in the case of transactional databases) or when reading data in the case of finally agreed upon repositories.
USL effect
If you plot the USL plot depending on the number of processors, the following green line will
appear : The purple line shows what Amdahl’s law would have predicted.
Pay attention that the green line reaches its peak and then decreases. This means that there is a certain number of nodes at which performance is maximum. Add more processors - and performance decreases . I saw this in real load testing.
People often want to increase the number of processors and improve performance. This can be done in two ways:
- Reduce the sequential part
- Reduce reconciliation costs
USL in human collectives?
Let's try an analogy. If the computational “task” is a project, then the number of people in the project can be represented as the number of “processors” performing the work.
In this case, the sequential part is a piece of work that can be done only sequentially, step by step. This may be a topic for a future article, but now we are not interested in the essence of the consistent part.
It seems that we see a direct analogy with the costs of coordination. Regardless of the time that team members spend on restoring a common world view, the costs of reconciliation are present.
For five people in a room, these costs are minimal. Five minutes of drawing with a marker on the board once a week or so.
For a large team in several time zones, a fine can grow and be formalized. Documents and walkthroughs. Presentations for the team and so on.
In some architectures, reconciliation is not so important. Imagine a team with employees on three continents, but each is working on one service that uses data in a strictly defined format and creates data in a strictly defined format. They do not need consistency regarding changes in processes, but consistency is needed regarding any changes in formats.
Sometimes tools and languages can change the costs of negotiation. One of the arguments in favor of static typing is that it helps to interact in a team. In essence, types in code are the mechanism for translating changes to the model of the world. In a dynamically typed language, we either need secondary artifacts (unit tests or chat messages), or we need to create boundaries where some departments very rarely restore consistency with others.
All these methods are aimed at reducing the costs of coordination. Recall that excessive scaling causes a decrease in throughput. So if you have high negotiation costs and too many people, then the team as a whole is slower. I saw teams where it seemed we could cut half the people and work twice as fast. USL and reconciliation costs now help you understand why this is happening - it’s not just garbage collection. It is about reducing the overhead of the exchange of mental models.
In The Loop of Fear, I referred to code bases where developers knew about the need for large-scale changes, but were afraid to accidentally harm. This means that the overblown team never reachedconsistency. It seems that after a loss, consistency is very difficult to restore. This means that it is impossible to ignore the costs of coordination.
USL and microservices
In my opinion, USL explains the interest in microservices. By splitting a large system into smaller and smaller parts, which are independently deployed, you reduce the successive part of the work. In a large system with a large number of participants, the consistent part depends on the amount of effort required for integration, testing and deployment. The advantage of microservices is that they do not need integration work, integration testing, or a delay in synchronized deployment.
But the costs of negotiation mean that you may not get the desired acceleration. Perhaps, here the analogy is a bit tight, but I think that we can consider changes in the interface between microservices as requiring reconciliation between the teams. If this is too much, then you will not get the desired benefits from microservices.
What to do with it?
My suggestion: look at the architecture used, language, tools, and command. Think about where time is lost to restore consistency, when people make changes to the system model of the world.
Look for breaks . Gaps between internal system boundaries and splits within the team.
Use the environment to communicate changes so that the alignment process takes place for everyone, not individually.
Look at the communication of your team. How much time and effort does it take to ensure consistency? Maybe make small changes and reduce the need for it?