Make frontend “backend” again
Nikolai Ryzhikov proposed his own version of the answer to the question of why it is so difficult to develop a user interface. Using the example of his project, he will show that the use of some ideas from the backend on the front end affects both the reduction in the complexity of development and the testability of the front end.
The material is based on the report of Nikolai Ryzhikov at the spring conference of HolyJS 2018 Piter .
At the moment, Nikolai Ryzhikov is working in the Health-IT sector to create medical information systems. Member of the St. Petersburg community of functional programmers FPROG. An active member of the Online Clojure community, a member of the standard for the exchange of medical information HL7 FHIR. Engaged in programming for 15 years.
- I was always tormented by the question: why was the graphical UI always difficult to do? Why has it always caused a lot of questions?
Today I will try to speculate on whether it is possible to effectively develop a user interface. Can we reduce the complexity of its development.
Let's define what efficiency is. From the point of view of developing a user interface, efficiency implies:
There is a very good definition:
After this definition, you can put anything you like - spending less time, less effort. For example, “if you write less code, admit fewer bugs” and achieve the same goal. In general, we spend a lot of energy in vain. And efficiency is a high enough goal - to get rid of these losses and do only what is needed.
In my opinion, complexity is the main problem in development.
Fred Brooks (Fred Brooks) in the distant 1986 wrote an article called “No silver bullet”. In it, he reflects on the software. In hardware, progress is leaps and bounds, and with software everything is much worse. The main question of Fred Brooks - can there be such a technology that will accelerate us immediately by an order of magnitude? And he gives a pessimistic answer, stating that in software it is impossible to achieve this, explaining his position. I highly recommend reading this article.
A friend of mine said that programming a UI is such a “dirty problem.” You can not sit down once and come up with the right option so that the problem will be solved forever. In addition, over the past 10 years, the complexity of development has only increased.
We started developing a medical information system 12 years ago. First with flash. Then we looked at what Gmail started doing. We liked it and we wanted to go to JavaScript with HTML.
In fact, then we were well ahead of our time. We took a dojo, and in fact we had all the same thing as it is now. There were components well licked into dojo widgets, there was a modular build system and require that Google Clojure Compiler mined and minified (RequireJS and CommonJS didn't even smell then).
Everything worked out. We looked at Gmail, were inspired, thought that everything was fine. At the beginning we wrote only the patient card reader. Then they gradually moved to automating other workflows in the hospital. And everything became difficult. In a team like professionals - but each feature began to creak. This feeling appeared 12 years ago - and it still does not leave me.
We did a system certification, and it was necessary to write a patient portal. This is such a system where the patient can go and see their medical data.
Our backend was then written on Ruby on Rails. Despite the fact that the Ruby on Rails community is not very large, it has had a huge impact on the industry. All your package managers, GitHub, Git, automatic makeups, etc. came from the small passionary community.
The essence of the challenge we faced was that it was necessary to implement the patient portal in two weeks. And we decided to try the Rails way - to do everything on the server. Such a classic web 2.0. And they did - really did it in two weeks.
We were ahead of the whole planet: we did SPA, we had a REST API, but for some reason it was inefficient. Some features could already make units, because only they were able to contain all this complexity of components, interrelationships of the backend with the front-end. And when we took the Rails way - a bit outdated by our standards, the features suddenly began to rivet. The average developer started rolling out a feature in a few days. And we even began to write simple tests.
On this basis, I actually still have a trauma: there are still questions. When we switched from Java to Rails on the backend, development efficiency increased by about 10 times. But when we scored on the SPA, the effectiveness of the development also increased significantly. How so?
Let's start with another question: why do we make a single page application, why do we believe in it?
We just say: you need to do so - and we do. And very rarely question it. Is the REST API and SPA architecture correct? Is it really suitable for the case where we use it? We do not think.
On the other hand, there are outstanding reverse examples. Everyone enjoys github. Did you know that GitHub is not a single page application? GitHub is the usual “rail” application that is rendered on the server, and where there are few widgets. Has anyone suffered from this? I think three people. The rest did not even notice. This did not affect the user in any way, but at the same time, we somehow have to pay for the development of other applications 10 times more (and strength, and complexity, etc.). Another example is Basecamp. Twitter was once just a Rails application.
In fact, there are so many Rails applications. This was partly determined by the DHH genius (David Heinemeier Hansson, creator of Ruby on Rails). He was able to create a tool focused on business, which allowed him to immediately do what was needed, without being distracted by technical problems.
When we used the Rails way, there was, of course, a lot of black magic. Gradually developing, we switched from Ruby to Clojure, practically retaining the same efficiency, but making everything an order of magnitude easier. And it was beautiful.
Over time, new trends began to appear in the front end.
We completely ignored Backbone, because the dojo application we wrote before was even more sophisticated than what Backbone offered.
Then came Angular. It was quite an interesting “ray of light” - in terms of efficiency, Angular is very good. You take the average developer, and he rivet feature. But from the point of view of simplicity, Angular brings a bunch of problems - it is opaque, complex, there is a watch, optimization, etc.
React appeared, which brought a bit of simplicity (at least, the straightness of the render, which at the expense of Virtual DOM allows us to just redraw, just understand and just write) every time. But from the point of view of efficiency, to be honest, React has significantly tilted us back.
The worst thing is that in 12 years nothing has changed. We are still doing the same as now. It's time to think - something is wrong here.
Fred Brooks says that there are two problems in software development. Of course, he sees the main problem in complexity, but divides it into two groups:
The question is, what is the balance between them. This is exactly what we are discussing now.
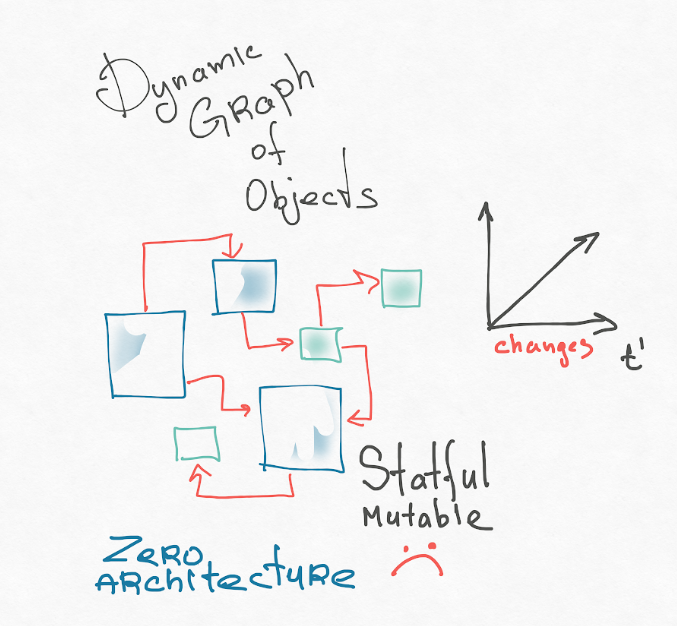
I think the first reason is our mental model of the application. React, components are a purely OOP approach. Our system is a dynamic graph of interconnected mutable objects. Turing-complete types constantly generate nodes of this graph, some nodes disappear. Have you ever tried to present your application in your head? This is scary! I usually represent an OOP application like this:

I recommend reading the theses of Roy Fielding (author of REST-architecture). His dissertation is called Architectural Styles and the Design of Network-based Software. At the very beginning there is a very good introduction, where he tells how to get to the architecture in general, and introduces concepts: it breaks the system into components and connections between these components. It has a “zero” architecture, where all components can potentially be connected to all. This is architectural chaos. This is our object representation of the user interface.
Roy Fielding recommends searching and imposing a set of constraints, because it is the set of constraints that determines your architecture.
Probably the most important thing is that the restrictions are the friends of the architect. Look for these real limitations and design a system for them. Because freedom is evil. Freedom means that you have a million options from which you can choose, and no criteria by which you can determine whether the choice was right. Look for restrictions and build on them.
There is an excellent article called OUT OF THE TAR PIT (“Easier Resin Pit”), in which the guys after Brooks decided to analyze what exactly contributes to the complexity of the application. They came to the disappointing conclusion that the mutable, spread over the state system is the main source of complexity. Here you can explain it purely combinatorially - if you have two cells, and each of them may contain (or not) a ball, how many states are possible? - Four.
If three cells - 2 3 , if 100 cells - 2 100. If you submit your application and understand how state is smeared, you will realize that there are an infinite number of possible states of your system. If you are not limited by this, it is too difficult. And the human brain is weak; this has already been proven by various studies. We are able to keep in mind up to three elements at the same time. Some say seven, but even for this the brain uses a hack. Therefore, complexity is really a problem for us.
I recommend reading this article, where the guys come to the conclusion that something must be done with this mutable state. For example, there are relational databases, there you can remove the entire mutable state. And the rest is done in a purely functional style. And they just come up with the idea of such functional-relational programming.
Thus, the problem comes from the fact that:
All this is too hard for the poor human brain. Let's think about what we can do with these two problems - the lack of restrictions in the architecture (graph of mutable objects) and the transition to distributed systems that are so complex that academics still puzzle how to do them correctly (at the same time condemning ourselves to these torments in the simplest business applications)?
If we write the backend in the same style as we are creating the UI, there will be the same “bloody mess”. We will spend as much time on it. So really once tried to do. Then gradually began to impose restrictions.
The first great backend invention is the database.
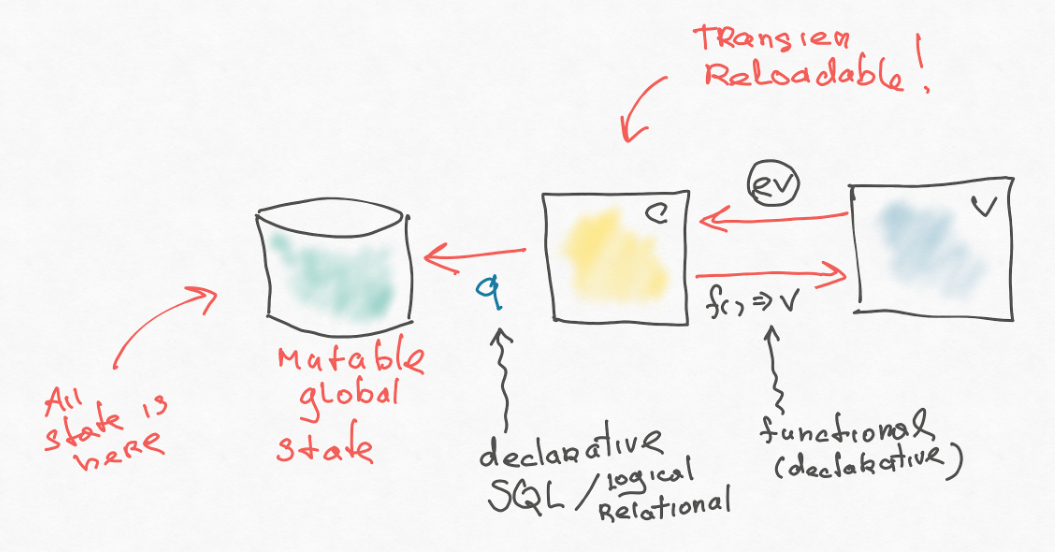
At first, in the program, the entire state hung where it was unclear, and it was difficult to manage it. Over time, the developers came up with a database and removed the entire state there.
The first interesting difference of the database is that the data there are not some objects with their behavior, this is pure information. There are tables or some other data structures (for example, JSON). They have no behavior, and this is also very important. Because behavior is an interpretation of information, and there can be many interpretations. And the basic facts - they remain basic.
Another important point is that above this database we have a query language, for example, SQL. In terms of limitations, in most cases SQL is not a turing-complete language, it is simpler. On the other hand, it is declarative - more expressive, because in SQL you say “what” and not “how”. For example, when you combine two tables in SQL, SQL itself decides how to effectively perform this operation. When you are looking for something, he selects an index for you. You never explicitly indicate this. If you try to combine something in JavaScript, you have to write a bunch of code for it.
Here, again, it is important that we have imposed restrictions and now we go to this base through a more simple and expressive language. Redistributed complexity.
After the backend entered the database, the application became stateless. This leads to interesting effects - now we, for example, can not be afraid to update the application (in memory in the application layer we don’t have a state hanging, which will disappear if the application restarts). For a stateless application layer, this is a good feature and a great limitation. Overlay it if you can. Moreover, an old application can be pulled on a new application, because the facts and their interpretation are not related things.
From this point of view, objects and classes are terrible, because they stick together behavior and information. Information is richer, it lives longer. Bases and facts go through code written in Delphi, Perl or JavaScript.
When the backend came to such an architecture, everything became much simpler. The “golden” era of Web 2.0 has arrived. You could get something from the database, template the data (a pure function) and return the HTML that is sent to the browser.
On the back end, we learned how to write fairly complex applications. And most applications are written in this style. But as soon as the backend takes a step to the side - into uncertainty - the problems begin again.
People began to think about it and came up with the idea of throwing out OOP and rituals.
What are our systems actually doing? They take information from somewhere - from the user, from another system and the like - put it into the base, transform it, somehow check it. From the database they take it out with cunning queries (analytical or synthetic) and return it. It's all. And it is important to understand. From this point of view, simulations are a very wrong and bad concept.
It seems to me, in general, the whole PLO was actually born from the UI. People tried to simulate and simulate the user interface. They saw a certain graphic object on the monitor and thought: it would be nice to simulate it in our runtime, along with its properties, etc. This whole story is very closely intertwined with the PLO. But simulation is the most straightforward and naive way to solve the problem. Interesting things are done when you step aside. From this point of view, it is more important to separate information from behavior, get rid of these strange objects, and everything will become much simpler: your web server receives an HTTP string, returns an HTTP response string. If you add a base to the equation, you’ll get a clean function: the server accepts the base and the request, returns the new base and the answer (the data is entered - the data is output).
Along the way of this simplification, functionals threw another ⅔ of baggage that had accumulated on the back end. He was not needed, it was just a ritual. We are still not a game dev - we do not need the patient and the doctor to somehow live in runtime, move and track their coordinates. Our information model is something else. We do not simulate medicine, sales or something else. We are creating something new at the junction. For example, Uber does not simulate the behavior of operators and machines - it introduces a new information model. In our field, we also create something new, so you can feel freedom.
Do not necessarily try to simulate completely - create.
It's time to tell exactly how you can throw everything. And here I want to mention Clojure Script. In fact, if you know JavaScript, you know Clojure. In Clojure, we do not add features to JavaScript, but remove them.
As a result, we still have functions and data structures over which we operate, as well as primitives. Here is the whole Clojure. And on it you can do the same thing that you do in other languages, where there are many unnecessary tools that no one knows how to use.
How do we get to Lisp via AST? Here is the classic expression:
If we try to write it AST, for example, in the form of an array, where the head is the type of the node, and what's next is a parameter, we will get something like this (we are trying to write it in Java Script):
Now let's throw out extra quotes, minus can be replaced by
And in Lisp, we all write it this way. We can check that this is a pure mathematical function (my emacs is connected to the browser; I throw the script there, it’s there the eval command and sends me back to emacs - you see the value after the symbol
We can also declare a function:
Or an anonymous function. Perhaps it looks a bit scary:
Her type is a JavaScript function:
We can call it by passing it a parameter:
That is all that we do - we write AST, which is then either compiled into JS or bytecode, or interpreted.
Clojure is hosted language. Therefore, it takes primitives from the parent runtime, that is, in the case of Clojure Script we will have JavaScript types:
This is how regexps are written:
The functions we have are functions:
Next we need some composite types.
This can be read as if you would create an object in JavaScript:
Clojure calls this hashmap. This is a container in which values lie. If square brackets are used, then this is called a vector - this is your array:
Any information we write hashmaps and vectors.
Strange names with a colon (
Clojure provides hundreds of functions that allow you to operate with these generic data structures and primitives. We can add, add new keys. At the same time, we have copying semantics everywhere, that is, every time we get a new copy. First you need to get used to it, because it will not be possible to save something as before, somewhere in a variable, and then change this value. Your calculation should always be straightforward - all arguments must be passed to the function explicitly.
This leads to an important thing. In functional languages, a function is an ideal component, because it receives everything explicitly at the input. No hidden links diverging through the system. You can take a function from one place, transfer it to another, and use it there.
In Clojure, we have excellent equality operations by value, even for complex compound types:
And this operation is cheap due to the fact that the cunning immutable structures can be compared simply by reference. Therefore, even a hashmap with millions of keys can be compared in one operation.
By the way, the guys from React just copied the Clojure implementation and made immutable JS.
Even in Clojure there are a lot of operations, for example, to get something on the nested path in a hashmap:
Put something in a hashmap along the nested path:
Update any value:
Select only a specific key:
The same with the vector:
There are hundreds of operations from the base library that allow you to operate on these data structures. There is an interop with the host. You need to get used to it a bit:
There is every sugar, to walk on chain-am:
I can take a JS date and return a year from it:
Rich Hickey - the creator of Clojure - severely limited us. We really have nothing else, so we do everything through the generic data structure. For example, when we write SQL, we usually write it with a data structure. If you look carefully, you will see that it is just a hashmap in which something is nested. Then there is some function that translates all this into a SQL string:
Routings we also write data structures and impose data structures:
So we discussed Clojure. But earlier I mentioned that the database was a great achievement in the backend. If you look at what is happening now in the frontend, we will see that the guys are using the same pattern - they enter the database in the User Interface (in a single page-application).
Bases are entered in the elm-architecture, in the Clojure-script re-frame, and even in some limited form in flux and redux (here you need to install additional plugins to throw requests). Elm architecture, re-frame and flux were launched at about the same time and borrowed from each other. We write on re-frame. Next, I'll tell you a little how it works.

From the view-hee we have an event crashes (this is a bit like redux), which is caught by a certain controller. The controller we call event-handler. An event-handler emits an effect, which is also someone interpreted by a data structure.
One type of effect is to update the database. That is, it takes the current value of the database and returns a new one. We also have such a thing as subscription - an analogue of requests on the backend. That is, these are some reactive queries that we can throw to this database. These reactive requests we subsequently gang on view-shku. In the case of react, we seem to completely redraw, and if the result of this query has changed, this is convenient.
React is present only somewhere at the very end, but in general the architecture is in no way connected with it. It looks something like this:

Here what is missing is added, for example, in redux.
First, we separate the effects. The application on the frontend is not independent. He has a kind of backend - a kind of, “source of true.” The application must constantly write something there and read something from there. Worse, if he has several backends to which it should go. In the simplest implementation, you could do it right in the action creater, in your controller, but this is bad. Therefore, the guys from the re-frame introduce an additional level of indirection: a kind of data structure flies out of the controller, telling you what to do. And this message has a handler that does the dirty work. This is a very important introduction, which we will discuss later.
It is also important (they sometimes forget about it) - there must be some ground-facts in the database. Everything else can be derived from the database - and this is usually done by the requests, they transform the data - they do not add new information, but structure the existing one in the right way. We need this query. In redux, in my opinion, this now provides reselect, and in our re-frame it is out of the box (built-in).
Look at the scheme of our architecture. We reproduced a small backend (in the style of Web 2.0) with a base, controller, view. The only thing added is reactivity. This is very similar to MVC, except that everything is in one place. Once upon a time, the early MVCs created their own model for each widget, but here everything is folded into one base. In principle, you can synchronize with the backend from the controller through the effect, you can come up with a more generic-like look so that the base works like a proxy to the backend. There is even some kind of generic algorithm: you write to your local database, and it synchronizes with the main one.
Now, in most cases, the base is just an object to which we write something in redux. But in principle, you can imagine that further it will develop into a full-fledged database with a rich query language. Maybe with some generic sync. For example, there is a datomic - a logical database triple-store, which is chased right in the browser. You raise it and put there your entire state. Datomic has a fairly rich query language, comparable in power to SQL, and somewhere even winning. Another example - Google wrote lovefield. Everything will move somewhere there.
Next, I will explain why we need reactive subscription.
Now we get the first naive perception - we got the user from the backend, put it in the database and then we need to draw it. At the time of rendering, there is a lot of definite logic, but we mix it up with rendering, with presentation. If we immediately take on drawing this user, we will have a big tricky piece that does something with Virtual DOM and something else. And it is mixed with the logical model of our view.
A very important concept that needs to be understood: because of the complexity of the UI, it also needs to be modeled. It is necessary to separate the way he draws (as he imagines) from his logical model. Then the logical model will be more stable. It can not be burdened with dependence on a specific framework - Angular, React or VueJS. The model is the usual first class citizen in your runtime. Ideally, if it's just some data and a set of functions above it.

That is, from the backend model (subject) we can get a view model, in which, without using any rendering yet, we can recreate the logical model. If there is any kind of menu or something like that, all this can be done in the view model.
Why are we doing all this?
I met good tests on the UI only where there is a staff of 10 testers.
Usually there is no UI testing. Therefore, we are trying to push this logic out of the components in the view model. The absence of tests is a very bad sign, indicating that there is something wrong, somehow all is badly structured.
Why is UI difficult to test? Why did the guys on the backend learn how to test their code, provided huge coverage and it really helps to live with the backend code? Why is the UI wrong? Most likely, we are doing something wrong. And everything that I described above really moved us towards testability.
If you look closely, the part of our architecture that contains the controller, subscription, and database is in no way connected even with JS. That is, it is some kind of model that operates with just data structures: we add them somewhere, somehow transform them, remove the query. Through effects, we have cut off interaction with the outside world. And this piece is completely portable. You can write it on the so-called cljc - this is a common subset between Clojure Script and Clojure, which behaves the same way there and there. We can just cut this piece from the frontend and put it in the JVM - where the backend lives. Then we can write another effect in the JVM, which directly hits the end-point - pulls the router without any transformations of the http-shnoy line, parsing, etc.
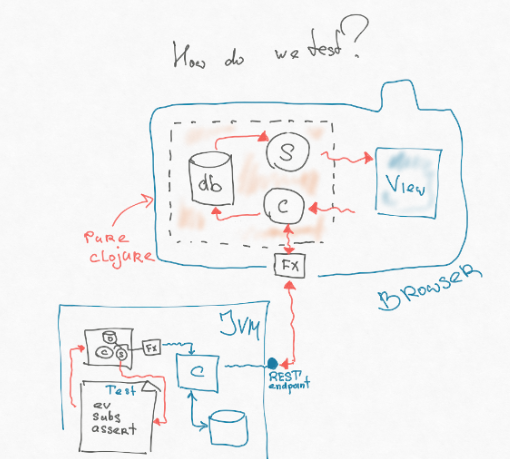
As a result, we can write a very simple test - the same functional integral test, which the guys write on the back end. We throw a certain event, it throws an effect that directly hits the endpoint on the back end. That returns something to us, puts in base, subscription is calculated, and in subscription logical view lies (we to the maximum put logic of the user interface there). We will see this view.
Thus, we can test 80% of the code on the backend, while all the tools for backend development are available to us. We can recreate a certain situation in the database using fixtures or some factories.
For example, we have a new patient or something unpaid, etc. We can go through a bunch of possible combinations.
Thus, we can overcome the second problem - the distributed system. Because the contract between the systems is precisely the main sore point, because these are two different runtimes, two different systems: the backend has changed something, and something broke on the front end (we can’t be sure that this will not happen).
Here is how it looks in practice. This is a backend helper that cleared the base and wrote some world into it:
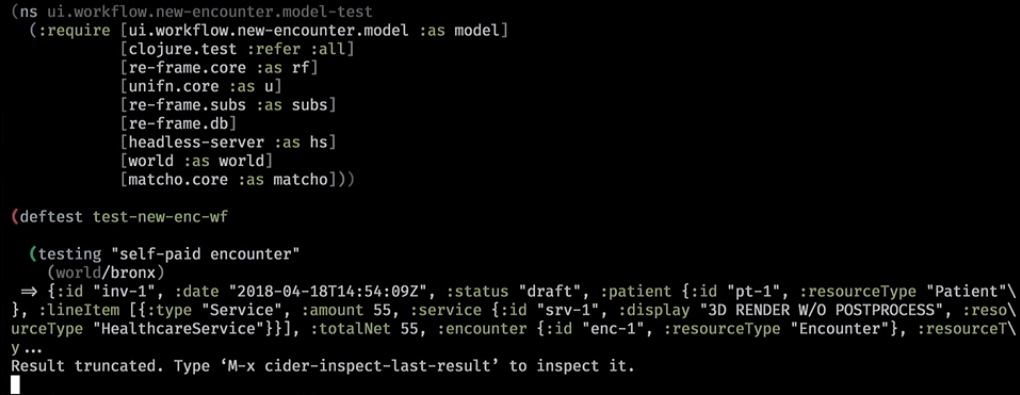
Next we throw the subscription:

Usually the URL completely defines the page and some event rushes - you are now on such a page with a set of parameters. Here we entered the new workflow and our subscription returned:

Behind the scenes, he went to the base, got something, put it in our UI-base. Subscription on it worked and derived from it the logical View model.
We initialized it. And here is our logical model:

Even without looking at the User interface, we can guess what will be drawn on this model: some kind of warning will come, some patient information will lie, encounters and a set of references (this is a workflow widget that leads the front desk on certain steps when the patient arrives).
Here we come up with a more complex world. We made some payments and also tested them after initialization:
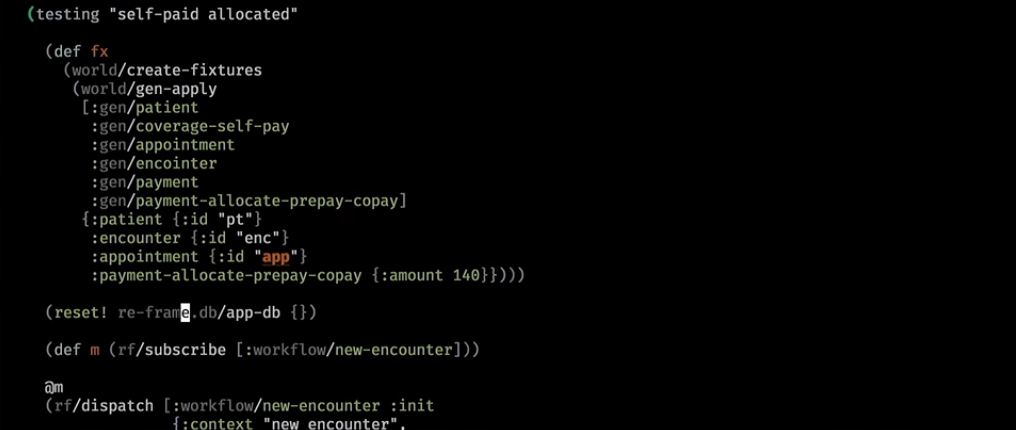
If he has already paid for the visit, he will see this in the user interface:

We run the tests, set it to CI. Sync between the backend and the front-end will already be guaranteed by tests, and not by an honest word.
We entered tests six months ago, and we really liked it. There remains the problem of blurred logic. The smarter the business application behaves, the more information it needs for some steps. If you try to run some kind of workflow from the real world there, depending on everything will appear: for every user interface you need to get something from different parts of the base on the backend. If we write accounting systems, this can not be avoided. In the end, as I said, all the logic is spread.
With the help of such tests, we can create the illusion at least at dev-time - at the time of development - that we, like in the old days web 2.0, are sitting on the server in the same runtime and everything is comfortable.
There was another crazy idea (it has not yet been implemented). Why not drop this part on the backend at all? Why not get away from the distributed application right now? Let this subscription and our view model be generated on the backend? There base is available, all synchronously. Everything is simple and clear.
The first plus that I see in this is that we will have control in one place. We just simplify everything at once compared to our distributed application. Tests become simple, double validations disappear. The fashionable world of interactive multi-user systems is opening (if two users have come to the same form, we tell them about it; they will be able to edit it at the same time).
An interesting feature appears: having entered the backend and session prospects, we can understand who is currently in the system and what it is doing. This is a bit like a game dev, where servers do something like this. There the world lives on the server, and the frontend only renders. As a result, we can get some thin client.
On the other hand, it creates a challenge. We will have to have a statefull server on which these sessions live. If we have several app servers, it will be necessary to balance the load somehow or replicate the session. However, there is a suspicion that this problem is less than the number of advantages that we get.
Therefore, I come back to the main slogan: there are many types of applications that can be written not distributed, to throw out complexity from them. And you can get a multiple increase in efficiency, if you once again revise the basic tenets on which we relied in the development.
The material is based on the report of Nikolai Ryzhikov at the spring conference of HolyJS 2018 Piter .
At the moment, Nikolai Ryzhikov is working in the Health-IT sector to create medical information systems. Member of the St. Petersburg community of functional programmers FPROG. An active member of the Online Clojure community, a member of the standard for the exchange of medical information HL7 FHIR. Engaged in programming for 15 years.
- I was always tormented by the question: why was the graphical UI always difficult to do? Why has it always caused a lot of questions?
Today I will try to speculate on whether it is possible to effectively develop a user interface. Can we reduce the complexity of its development.
What is efficiency?
Let's define what efficiency is. From the point of view of developing a user interface, efficiency implies:
- development speed,
- number of bugs
- the amount of money spent ...
There is a very good definition:
Efficiency is to do more by spending less
After this definition, you can put anything you like - spending less time, less effort. For example, “if you write less code, admit fewer bugs” and achieve the same goal. In general, we spend a lot of energy in vain. And efficiency is a high enough goal - to get rid of these losses and do only what is needed.
What is complexity?
In my opinion, complexity is the main problem in development.
Fred Brooks (Fred Brooks) in the distant 1986 wrote an article called “No silver bullet”. In it, he reflects on the software. In hardware, progress is leaps and bounds, and with software everything is much worse. The main question of Fred Brooks - can there be such a technology that will accelerate us immediately by an order of magnitude? And he gives a pessimistic answer, stating that in software it is impossible to achieve this, explaining his position. I highly recommend reading this article.
A friend of mine said that programming a UI is such a “dirty problem.” You can not sit down once and come up with the right option so that the problem will be solved forever. In addition, over the past 10 years, the complexity of development has only increased.
12 years ago ...
We started developing a medical information system 12 years ago. First with flash. Then we looked at what Gmail started doing. We liked it and we wanted to go to JavaScript with HTML.
In fact, then we were well ahead of our time. We took a dojo, and in fact we had all the same thing as it is now. There were components well licked into dojo widgets, there was a modular build system and require that Google Clojure Compiler mined and minified (RequireJS and CommonJS didn't even smell then).
Everything worked out. We looked at Gmail, were inspired, thought that everything was fine. At the beginning we wrote only the patient card reader. Then they gradually moved to automating other workflows in the hospital. And everything became difficult. In a team like professionals - but each feature began to creak. This feeling appeared 12 years ago - and it still does not leave me.
Rails way + jQuery
We did a system certification, and it was necessary to write a patient portal. This is such a system where the patient can go and see their medical data.
Our backend was then written on Ruby on Rails. Despite the fact that the Ruby on Rails community is not very large, it has had a huge impact on the industry. All your package managers, GitHub, Git, automatic makeups, etc. came from the small passionary community.
The essence of the challenge we faced was that it was necessary to implement the patient portal in two weeks. And we decided to try the Rails way - to do everything on the server. Such a classic web 2.0. And they did - really did it in two weeks.
We were ahead of the whole planet: we did SPA, we had a REST API, but for some reason it was inefficient. Some features could already make units, because only they were able to contain all this complexity of components, interrelationships of the backend with the front-end. And when we took the Rails way - a bit outdated by our standards, the features suddenly began to rivet. The average developer started rolling out a feature in a few days. And we even began to write simple tests.
On this basis, I actually still have a trauma: there are still questions. When we switched from Java to Rails on the backend, development efficiency increased by about 10 times. But when we scored on the SPA, the effectiveness of the development also increased significantly. How so?
Why was web 2.0 effective?
Let's start with another question: why do we make a single page application, why do we believe in it?
We just say: you need to do so - and we do. And very rarely question it. Is the REST API and SPA architecture correct? Is it really suitable for the case where we use it? We do not think.
On the other hand, there are outstanding reverse examples. Everyone enjoys github. Did you know that GitHub is not a single page application? GitHub is the usual “rail” application that is rendered on the server, and where there are few widgets. Has anyone suffered from this? I think three people. The rest did not even notice. This did not affect the user in any way, but at the same time, we somehow have to pay for the development of other applications 10 times more (and strength, and complexity, etc.). Another example is Basecamp. Twitter was once just a Rails application.
In fact, there are so many Rails applications. This was partly determined by the DHH genius (David Heinemeier Hansson, creator of Ruby on Rails). He was able to create a tool focused on business, which allowed him to immediately do what was needed, without being distracted by technical problems.
When we used the Rails way, there was, of course, a lot of black magic. Gradually developing, we switched from Ruby to Clojure, practically retaining the same efficiency, but making everything an order of magnitude easier. And it was beautiful.
12 years have passed
Over time, new trends began to appear in the front end.
We completely ignored Backbone, because the dojo application we wrote before was even more sophisticated than what Backbone offered.
Then came Angular. It was quite an interesting “ray of light” - in terms of efficiency, Angular is very good. You take the average developer, and he rivet feature. But from the point of view of simplicity, Angular brings a bunch of problems - it is opaque, complex, there is a watch, optimization, etc.
React appeared, which brought a bit of simplicity (at least, the straightness of the render, which at the expense of Virtual DOM allows us to just redraw, just understand and just write) every time. But from the point of view of efficiency, to be honest, React has significantly tilted us back.
The worst thing is that in 12 years nothing has changed. We are still doing the same as now. It's time to think - something is wrong here.
Fred Brooks says that there are two problems in software development. Of course, he sees the main problem in complexity, but divides it into two groups:
- substantial complexity that comes from the task itself. It simply does not throw out, because it is part of the task.
- random complexity - this is the one that we bring, trying to solve this problem.
The question is, what is the balance between them. This is exactly what we are discussing now.
Why does the User Interface hurt so much?
I think the first reason is our mental model of the application. React, components are a purely OOP approach. Our system is a dynamic graph of interconnected mutable objects. Turing-complete types constantly generate nodes of this graph, some nodes disappear. Have you ever tried to present your application in your head? This is scary! I usually represent an OOP application like this:
I recommend reading the theses of Roy Fielding (author of REST-architecture). His dissertation is called Architectural Styles and the Design of Network-based Software. At the very beginning there is a very good introduction, where he tells how to get to the architecture in general, and introduces concepts: it breaks the system into components and connections between these components. It has a “zero” architecture, where all components can potentially be connected to all. This is architectural chaos. This is our object representation of the user interface.
Roy Fielding recommends searching and imposing a set of constraints, because it is the set of constraints that determines your architecture.
Probably the most important thing is that the restrictions are the friends of the architect. Look for these real limitations and design a system for them. Because freedom is evil. Freedom means that you have a million options from which you can choose, and no criteria by which you can determine whether the choice was right. Look for restrictions and build on them.
There is an excellent article called OUT OF THE TAR PIT (“Easier Resin Pit”), in which the guys after Brooks decided to analyze what exactly contributes to the complexity of the application. They came to the disappointing conclusion that the mutable, spread over the state system is the main source of complexity. Here you can explain it purely combinatorially - if you have two cells, and each of them may contain (or not) a ball, how many states are possible? - Four.
If three cells - 2 3 , if 100 cells - 2 100. If you submit your application and understand how state is smeared, you will realize that there are an infinite number of possible states of your system. If you are not limited by this, it is too difficult. And the human brain is weak; this has already been proven by various studies. We are able to keep in mind up to three elements at the same time. Some say seven, but even for this the brain uses a hack. Therefore, complexity is really a problem for us.
I recommend reading this article, where the guys come to the conclusion that something must be done with this mutable state. For example, there are relational databases, there you can remove the entire mutable state. And the rest is done in a purely functional style. And they just come up with the idea of such functional-relational programming.
Thus, the problem comes from the fact that:
- First, we do not have a good fixed user interface model. Component approaches lead us to existing hell. We do not impose any restrictions, we smear a mutable state, as a result, the complexity of the system at some point simply presses us;
- secondly, if we write a classic backend - frontend application, this is already a distributed system. And the first rule of distributed systems - do not create distributed systems (First Law of Distributed Object Design: Don't distribute your objects - by Martin Fowler), because you immediately increase the complexity by an order of magnitude. Whoever wrote any integration, understands that as soon as you enter into intersystem interaction, all project estimates can be multiplied by 10. But we just forget about it and go to distributed systems. This was probably the main consideration when we switched to Rails, returning all control to the server.
All this is too hard for the poor human brain. Let's think about what we can do with these two problems - the lack of restrictions in the architecture (graph of mutable objects) and the transition to distributed systems that are so complex that academics still puzzle how to do them correctly (at the same time condemning ourselves to these torments in the simplest business applications)?
How did the backend evolve?
If we write the backend in the same style as we are creating the UI, there will be the same “bloody mess”. We will spend as much time on it. So really once tried to do. Then gradually began to impose restrictions.
The first great backend invention is the database.
At first, in the program, the entire state hung where it was unclear, and it was difficult to manage it. Over time, the developers came up with a database and removed the entire state there.
The first interesting difference of the database is that the data there are not some objects with their behavior, this is pure information. There are tables or some other data structures (for example, JSON). They have no behavior, and this is also very important. Because behavior is an interpretation of information, and there can be many interpretations. And the basic facts - they remain basic.
Another important point is that above this database we have a query language, for example, SQL. In terms of limitations, in most cases SQL is not a turing-complete language, it is simpler. On the other hand, it is declarative - more expressive, because in SQL you say “what” and not “how”. For example, when you combine two tables in SQL, SQL itself decides how to effectively perform this operation. When you are looking for something, he selects an index for you. You never explicitly indicate this. If you try to combine something in JavaScript, you have to write a bunch of code for it.
Here, again, it is important that we have imposed restrictions and now we go to this base through a more simple and expressive language. Redistributed complexity.
After the backend entered the database, the application became stateless. This leads to interesting effects - now we, for example, can not be afraid to update the application (in memory in the application layer we don’t have a state hanging, which will disappear if the application restarts). For a stateless application layer, this is a good feature and a great limitation. Overlay it if you can. Moreover, an old application can be pulled on a new application, because the facts and their interpretation are not related things.
From this point of view, objects and classes are terrible, because they stick together behavior and information. Information is richer, it lives longer. Bases and facts go through code written in Delphi, Perl or JavaScript.
When the backend came to such an architecture, everything became much simpler. The “golden” era of Web 2.0 has arrived. You could get something from the database, template the data (a pure function) and return the HTML that is sent to the browser.
On the back end, we learned how to write fairly complex applications. And most applications are written in this style. But as soon as the backend takes a step to the side - into uncertainty - the problems begin again.
People began to think about it and came up with the idea of throwing out OOP and rituals.
What are our systems actually doing? They take information from somewhere - from the user, from another system and the like - put it into the base, transform it, somehow check it. From the database they take it out with cunning queries (analytical or synthetic) and return it. It's all. And it is important to understand. From this point of view, simulations are a very wrong and bad concept.
It seems to me, in general, the whole PLO was actually born from the UI. People tried to simulate and simulate the user interface. They saw a certain graphic object on the monitor and thought: it would be nice to simulate it in our runtime, along with its properties, etc. This whole story is very closely intertwined with the PLO. But simulation is the most straightforward and naive way to solve the problem. Interesting things are done when you step aside. From this point of view, it is more important to separate information from behavior, get rid of these strange objects, and everything will become much simpler: your web server receives an HTTP string, returns an HTTP response string. If you add a base to the equation, you’ll get a clean function: the server accepts the base and the request, returns the new base and the answer (the data is entered - the data is output).
Along the way of this simplification, functionals threw another ⅔ of baggage that had accumulated on the back end. He was not needed, it was just a ritual. We are still not a game dev - we do not need the patient and the doctor to somehow live in runtime, move and track their coordinates. Our information model is something else. We do not simulate medicine, sales or something else. We are creating something new at the junction. For example, Uber does not simulate the behavior of operators and machines - it introduces a new information model. In our field, we also create something new, so you can feel freedom.
Do not necessarily try to simulate completely - create.
Clojure = JS--
It's time to tell exactly how you can throw everything. And here I want to mention Clojure Script. In fact, if you know JavaScript, you know Clojure. In Clojure, we do not add features to JavaScript, but remove them.
- We throw out the syntax - there is no syntax in Clojure (in Lisp). In ordinary language, we write some code, which is then parsed and it turns out AST, which is compiled and executed. In Lisp, we immediately write AST, which can be executed - interpreted or compiled.
- We throw out mutability. Clojure has no mutable objects or arrays. Each operation generates, as it were, a new copy. However, this copy is very cheap. That's so cleverly done so that it is cheap. And it allows us to work, as in mathematics, with values. We do not change anything - we generate something new. Safe, easy.
- We throw out classes, play games with prototypes, etc. This is just not there.
As a result, we still have functions and data structures over which we operate, as well as primitives. Here is the whole Clojure. And on it you can do the same thing that you do in other languages, where there are many unnecessary tools that no one knows how to use.
Examples
How do we get to Lisp via AST? Here is the classic expression:
(1 + 2) - 3If we try to write it AST, for example, in the form of an array, where the head is the type of the node, and what's next is a parameter, we will get something like this (we are trying to write it in Java Script):
[‘minus’,
[‘plus’,
1,
2],
3]
Now let's throw out extra quotes, minus can be replaced by
-, and plus by +. Drop the commas, which in Lisp are whitespace. We get the same AST:
(- (+12) 3)
And in Lisp, we all write it this way. We can check that this is a pure mathematical function (my emacs is connected to the browser; I throw the script there, it’s there the eval command and sends me back to emacs - you see the value after the symbol
=>):
(- (+12) 3) => 0We can also declare a function:
(defn xplus [a b]
(+ a b))
((fn [x y] (* x y)) 12) => 2Or an anonymous function. Perhaps it looks a bit scary:
(type xplus)
Her type is a JavaScript function:
(type xplus) => #object[Function]
We can call it by passing it a parameter:
(xplus12)
That is all that we do - we write AST, which is then either compiled into JS or bytecode, or interpreted.
(defn mymin [a b]
(if (a > b) b a))
Clojure is hosted language. Therefore, it takes primitives from the parent runtime, that is, in the case of Clojure Script we will have JavaScript types:
(type1) => #object[Number]
(type "string") => #object[String]
This is how regexps are written:
(type #"^Cl.*$") => #object[RegExp]
The functions we have are functions:
(type (fn [x] x)) => #object[Function]
Next we need some composite types.
(def user {:name"niquola":address {:city"SPb"}
:profiles [{:type"github":link"https://….."}
{:type"twitter":link"https://….."}]
:age37}
(type user)
This can be read as if you would create an object in JavaScript:
(def user {name: "niquola"
…
Clojure calls this hashmap. This is a container in which values lie. If square brackets are used, then this is called a vector - this is your array:
(def user {:name"niquola":address {:city"SPb"}
:profiles [{:type"github":link"https://….."}
{:type"twitter":link"https://….."}]
:age37} => #’intro/user
(type user)
Any information we write hashmaps and vectors.
Strange names with a colon (
:name) are so-called characters: constant strings, which are created in order to use them as keys in hashmaps. In different languages they are called differently - symbols, something else. But it can be perceived simply as a constant string. They are quite effective - you can write long titles and not spend a lot of resources on it, because they are interned (i.e. they do not repeat).Clojure provides hundreds of functions that allow you to operate with these generic data structures and primitives. We can add, add new keys. At the same time, we have copying semantics everywhere, that is, every time we get a new copy. First you need to get used to it, because it will not be possible to save something as before, somewhere in a variable, and then change this value. Your calculation should always be straightforward - all arguments must be passed to the function explicitly.
This leads to an important thing. In functional languages, a function is an ideal component, because it receives everything explicitly at the input. No hidden links diverging through the system. You can take a function from one place, transfer it to another, and use it there.
In Clojure, we have excellent equality operations by value, even for complex compound types:
(= {:a1} {:a1}) => true
And this operation is cheap due to the fact that the cunning immutable structures can be compared simply by reference. Therefore, even a hashmap with millions of keys can be compared in one operation.
By the way, the guys from React just copied the Clojure implementation and made immutable JS.
Even in Clojure there are a lot of operations, for example, to get something on the nested path in a hashmap:
(get-in user [:address:city])
Put something in a hashmap along the nested path:
(assoc-in user [:address:city] "LA") => {:name"niquola",
:address {:city"LA"},
:profiles
[{:type"github", :link"https://….."}
{:type"twitter", :link"https://….."}],
:age37}
Update any value:
(update-in user [:profiles0:link] (fn [old] (str old "+++++")))
Select only a specific key:
(select-keys user [:name:address])
The same with the vector:
(def clojurists [{:name "Rich"}
{:name "Micael"}])
(first clojurists)
(second clojurists) => {:name "Michael"}
There are hundreds of operations from the base library that allow you to operate on these data structures. There is an interop with the host. You need to get used to it a bit:
(js/alert "Hello!") => nil
</csource>
По команде выше у меня в браузер бросилось "Привет".
Я могу получить location от window:
<source lang="clojure">
(.-location js/window)
There is every sugar, to walk on chain-am:
(.. js/window -location -href) => "http://localhost:3000/#/billing/dashboard"
(.. js/window -location -host) => "localhost:3000"
I can take a JS date and return a year from it:
(let [d (js/Date.)]
(.getFullYear d)) => 2018Rich Hickey - the creator of Clojure - severely limited us. We really have nothing else, so we do everything through the generic data structure. For example, when we write SQL, we usually write it with a data structure. If you look carefully, you will see that it is just a hashmap in which something is nested. Then there is some function that translates all this into a SQL string:
{select [:*]
:from [:users]
:where [:= :id"user-1"]} => {:select [:*], :from [:users], :where [:= :id"user-1"]}
Routings we also write data structures and impose data structures:
{"users" {:get {:handler:users-list}}
:get {:handler:welcome-page}}
[:div.row
[:div {:on-click #(.log js/console "Hello")}
"User "]]
DB to UI
So we discussed Clojure. But earlier I mentioned that the database was a great achievement in the backend. If you look at what is happening now in the frontend, we will see that the guys are using the same pattern - they enter the database in the User Interface (in a single page-application).
Bases are entered in the elm-architecture, in the Clojure-script re-frame, and even in some limited form in flux and redux (here you need to install additional plugins to throw requests). Elm architecture, re-frame and flux were launched at about the same time and borrowed from each other. We write on re-frame. Next, I'll tell you a little how it works.
From the view-hee we have an event crashes (this is a bit like redux), which is caught by a certain controller. The controller we call event-handler. An event-handler emits an effect, which is also someone interpreted by a data structure.
One type of effect is to update the database. That is, it takes the current value of the database and returns a new one. We also have such a thing as subscription - an analogue of requests on the backend. That is, these are some reactive queries that we can throw to this database. These reactive requests we subsequently gang on view-shku. In the case of react, we seem to completely redraw, and if the result of this query has changed, this is convenient.
React is present only somewhere at the very end, but in general the architecture is in no way connected with it. It looks something like this:
Here what is missing is added, for example, in redux.
First, we separate the effects. The application on the frontend is not independent. He has a kind of backend - a kind of, “source of true.” The application must constantly write something there and read something from there. Worse, if he has several backends to which it should go. In the simplest implementation, you could do it right in the action creater, in your controller, but this is bad. Therefore, the guys from the re-frame introduce an additional level of indirection: a kind of data structure flies out of the controller, telling you what to do. And this message has a handler that does the dirty work. This is a very important introduction, which we will discuss later.
It is also important (they sometimes forget about it) - there must be some ground-facts in the database. Everything else can be derived from the database - and this is usually done by the requests, they transform the data - they do not add new information, but structure the existing one in the right way. We need this query. In redux, in my opinion, this now provides reselect, and in our re-frame it is out of the box (built-in).
Look at the scheme of our architecture. We reproduced a small backend (in the style of Web 2.0) with a base, controller, view. The only thing added is reactivity. This is very similar to MVC, except that everything is in one place. Once upon a time, the early MVCs created their own model for each widget, but here everything is folded into one base. In principle, you can synchronize with the backend from the controller through the effect, you can come up with a more generic-like look so that the base works like a proxy to the backend. There is even some kind of generic algorithm: you write to your local database, and it synchronizes with the main one.
Now, in most cases, the base is just an object to which we write something in redux. But in principle, you can imagine that further it will develop into a full-fledged database with a rich query language. Maybe with some generic sync. For example, there is a datomic - a logical database triple-store, which is chased right in the browser. You raise it and put there your entire state. Datomic has a fairly rich query language, comparable in power to SQL, and somewhere even winning. Another example - Google wrote lovefield. Everything will move somewhere there.
Next, I will explain why we need reactive subscription.
Now we get the first naive perception - we got the user from the backend, put it in the database and then we need to draw it. At the time of rendering, there is a lot of definite logic, but we mix it up with rendering, with presentation. If we immediately take on drawing this user, we will have a big tricky piece that does something with Virtual DOM and something else. And it is mixed with the logical model of our view.
A very important concept that needs to be understood: because of the complexity of the UI, it also needs to be modeled. It is necessary to separate the way he draws (as he imagines) from his logical model. Then the logical model will be more stable. It can not be burdened with dependence on a specific framework - Angular, React or VueJS. The model is the usual first class citizen in your runtime. Ideally, if it's just some data and a set of functions above it.
That is, from the backend model (subject) we can get a view model, in which, without using any rendering yet, we can recreate the logical model. If there is any kind of menu or something like that, all this can be done in the view model.
What for?
Why are we doing all this?
I met good tests on the UI only where there is a staff of 10 testers.
Usually there is no UI testing. Therefore, we are trying to push this logic out of the components in the view model. The absence of tests is a very bad sign, indicating that there is something wrong, somehow all is badly structured.
Why is UI difficult to test? Why did the guys on the backend learn how to test their code, provided huge coverage and it really helps to live with the backend code? Why is the UI wrong? Most likely, we are doing something wrong. And everything that I described above really moved us towards testability.
How do we do tests?
If you look closely, the part of our architecture that contains the controller, subscription, and database is in no way connected even with JS. That is, it is some kind of model that operates with just data structures: we add them somewhere, somehow transform them, remove the query. Through effects, we have cut off interaction with the outside world. And this piece is completely portable. You can write it on the so-called cljc - this is a common subset between Clojure Script and Clojure, which behaves the same way there and there. We can just cut this piece from the frontend and put it in the JVM - where the backend lives. Then we can write another effect in the JVM, which directly hits the end-point - pulls the router without any transformations of the http-shnoy line, parsing, etc.
As a result, we can write a very simple test - the same functional integral test, which the guys write on the back end. We throw a certain event, it throws an effect that directly hits the endpoint on the back end. That returns something to us, puts in base, subscription is calculated, and in subscription logical view lies (we to the maximum put logic of the user interface there). We will see this view.
Thus, we can test 80% of the code on the backend, while all the tools for backend development are available to us. We can recreate a certain situation in the database using fixtures or some factories.
For example, we have a new patient or something unpaid, etc. We can go through a bunch of possible combinations.
Thus, we can overcome the second problem - the distributed system. Because the contract between the systems is precisely the main sore point, because these are two different runtimes, two different systems: the backend has changed something, and something broke on the front end (we can’t be sure that this will not happen).
Demonstration
Here is how it looks in practice. This is a backend helper that cleared the base and wrote some world into it:
Next we throw the subscription:
Usually the URL completely defines the page and some event rushes - you are now on such a page with a set of parameters. Here we entered the new workflow and our subscription returned:
Behind the scenes, he went to the base, got something, put it in our UI-base. Subscription on it worked and derived from it the logical View model.
We initialized it. And here is our logical model:
Even without looking at the User interface, we can guess what will be drawn on this model: some kind of warning will come, some patient information will lie, encounters and a set of references (this is a workflow widget that leads the front desk on certain steps when the patient arrives).
Here we come up with a more complex world. We made some payments and also tested them after initialization:
If he has already paid for the visit, he will see this in the user interface:
We run the tests, set it to CI. Sync between the backend and the front-end will already be guaranteed by tests, and not by an honest word.
Back to backend?
We entered tests six months ago, and we really liked it. There remains the problem of blurred logic. The smarter the business application behaves, the more information it needs for some steps. If you try to run some kind of workflow from the real world there, depending on everything will appear: for every user interface you need to get something from different parts of the base on the backend. If we write accounting systems, this can not be avoided. In the end, as I said, all the logic is spread.
With the help of such tests, we can create the illusion at least at dev-time - at the time of development - that we, like in the old days web 2.0, are sitting on the server in the same runtime and everything is comfortable.
There was another crazy idea (it has not yet been implemented). Why not drop this part on the backend at all? Why not get away from the distributed application right now? Let this subscription and our view model be generated on the backend? There base is available, all synchronously. Everything is simple and clear.
The first plus that I see in this is that we will have control in one place. We just simplify everything at once compared to our distributed application. Tests become simple, double validations disappear. The fashionable world of interactive multi-user systems is opening (if two users have come to the same form, we tell them about it; they will be able to edit it at the same time).
An interesting feature appears: having entered the backend and session prospects, we can understand who is currently in the system and what it is doing. This is a bit like a game dev, where servers do something like this. There the world lives on the server, and the frontend only renders. As a result, we can get some thin client.
On the other hand, it creates a challenge. We will have to have a statefull server on which these sessions live. If we have several app servers, it will be necessary to balance the load somehow or replicate the session. However, there is a suspicion that this problem is less than the number of advantages that we get.
Therefore, I come back to the main slogan: there are many types of applications that can be written not distributed, to throw out complexity from them. And you can get a multiple increase in efficiency, if you once again revise the basic tenets on which we relied in the development.
If you like the report, pay attention: a new HolyJS will take place on November 24-25 in Moscow , and there will also be many interesting things there. Already known information about the program - on the website , and tickets can be purchased there.