Bubble Sort and All-All-All

Everyone knows very well that from the class of exchange sortings the fastest method is the so-called quick sort . Dissertations are written about her, many articles on Habré are devoted to her, on her basis they come up with complex hybrid algorithms. But today we are not talking about quick sort , but about another exchange method - the good old bubble sorting and its improvements, modifications, mutations and varieties.
Practical exhaust from these methods is not so hot, and many habrappolzov all this took place in the first class. Therefore, the article is addressed to those who have just become interested in the theory of algorithms and are taking the first steps in this direction.
image: bubbles
Today let's talk about the simplest sorting exchanges.
If anyone is interested, I’ll say that there are other classes - sorting by selection , sorting by inserts , sorting by merging , sorting by distribution , hybrid sorting and parallel sorting . By the way, there are also esoteric sortings . These are various fake, fundamentally unrealizable, comic and other pseudo-algorithms, about which I will somehow write a couple of articles in the IT-humor hub.
But this has nothing to do with today's lecture; now we are only interested in simple sortings of exchanges. There are many exchanges sortings themselves (I know more than a dozen), so we will consider the so-called bubble sortingand some others, closely interconnected with it.
I will warn in advance that almost all of the above methods are very slow and there will be no in-depth analysis of their time complexity. Some are faster, some are slower, but, roughly speaking, we can say that on average O ( n 2 ). Also, I see no reason to clutter up the article with implementations in any programming language. Those interested can easily find code examples on Rosetta , Wikipedia, or elsewhere.
But back to sorting exchanges. Ordering occurs as a result of multiple sequential enumeration of the array and comparison of pairs of elements with each other. If the compared items are not sorted relative to each other, then we swap them. The only question is how to bypass the array exactly and by what principle to select pairs for comparison.
Let's start not with the reference bubble sort, but with an algorithm called ...
Silly sort
Sorting is really stupid. We look through the array from left to right and compare the neighbors along the way. If we meet a pair of mutually unsorted elements, we swap them and return to square one, that is, to the very beginning. We go through again, check the array, if we meet again the “wrong” pair of neighboring elements, then we swap places and again we start all over again. We continue until the array is slowly sorted out. “So any fool knows how to sort” - you say, and you will be absolutely right. That is why sorting was called "stupid." In this lecture, we will consistently improve and modify this method. Now he has the time complexity O ( n 3 ), having made one correction, we will bring it to O (

n 2 ), then we’ll speed it up a little more, then another, and in the end we will get O ( n log n ) - and this will not be “Quick Sort” at all!
We’ll add a single improvement to the stupid sort. Having discovered two adjacent unsorted elements during the passage and exchanging their places, we will not roll back to the beginning of the array, but calmly continue to bypass it to the very end.
In this case, before us is nothing but everyone’s known ...
Bubble Sort
Or sorting by simple exchanges . Immortal classics of the genre. The principle of action is simple: we go around the array from beginning to end, simultaneously swapping the unsorted neighboring elements. As a result of the first pass, the maximum element “pops up” to the last place. Now again we go around the unsorted part of the array (from the first element to the penultimate) and change the path of the unsorted neighbors. The second largest element will be in the penultimate place. Continuing in the same vein, we will bypass the ever-decreasing unsorted part of the array, pushing the found maxima to the end. If we push the highs not only to the end, but also to transfer the lows to the beginning, then we get ...

Shaker sort
She is sorting by mixing , she is cocktail sorting . The process begins as in a "bubble": squeeze a maximum to the very backyards. After that, turn around 180 0 and go in the opposite direction, while already rolling to the beginning is not a maximum, but a minimum. Having sorted the first and last elements in the array, we do somersault again. Going back and forth several times, in the end we finish the process, being in the middle of the list. Shaker sorting works a little faster than bubble sorting, because maxima and minima alternately migrate along the array in the right directions. Improvements, as they say, are obvious.

As you can see, if we approach the search process creatively, pushing heavy (light) elements to the ends of the array is faster. Therefore, the craftsmen proposed to bypass the list another non-standard “road map”.
Even odd sort
This time we will not scurry about the array back and forth, but again we will return to the idea of a planned round-trip from left to right, but only take a wider step. On the first pass, we compare the elements with the odd key with the neighbors staying in even places (the 1st one is compared with the 2nd, then the 3rd with the 4th, the 5th with the 6th and so on). Then, on the contrary, we compare / change “even in counting” elements with “odd” ones. Then again “odd-even”, then again “odd-even”. The process stops when, after two successive passes through the array (“odd-even” and “even-odd”), no exchange occurred. So, sorted.

In the usual “bubble” during each pass, we systematically squeeze the current maximum at the end of the array. If you skip along even and odd indices, then immediately all the more or less large elements of the array are simultaneously pushed to the right by one position in one run. It turns out faster.
We will analyze the last abbreviation * for Sortuvannya bulbashka ** - Sortuvannya rowing ***. This method orders very smartly, O ( n 2 ) is its worst complexity. On average, in time we have O ( n log n ), and the best one, you won’t even believe it, is O ( n) That is, a very worthy competitor to all kinds of "quick sorts" and this, mind you, without the use of recursion. However, I promised that today we won’t go into cruising speeds, we shut up and go directly to the algorithm.

Turtles are to blame
A little background. In 1980, Vlodzimezh Dobosievich explained why the bubble and its derivatives sorting work so slowly. This is all because of the turtles . Turtles are small items that are at the end of the list. As you may have noticed, the bubble sortings are oriented to “rabbits” (not to be confused with “grandmothers” of Babushkin), which are large elements in the beginning of the list. They are very briskly moving to the finish line. But the slow reptiles at the start creep reluctantly. You can customize the tortillas with a comb .
image: guilty turtle
Sort hairbrush
In the "bubble", "shaker" and "odd-even", when iterating over the array, neighboring elements are compared. The main idea of the “comb” is to initially take a sufficiently large distance between the compared elements and narrow the distance down to the minimum as the array is ordered. Thus, we are combing the array, as it were, gradually smoothing it into ever more neat strands. It is better to take the initial gap between the compared elements not anyhow, but taking into account a special value called the reduction factor , the optimal value of which is approximately 1.247. First, the distance between the elements is equal to the size of the array divided by the reduction factor

(the result, of course, is rounded to the nearest integer). Then, having passed the array with this step, we again divide the step by the reduction factor and go through the list again. This continues until the difference in indices reaches unity. In this case, the array is sorted out with a regular bubble.
Experimentally and theoretically, the optimal value of the reduction factor was established :
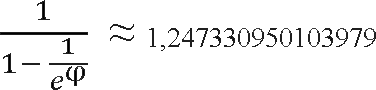
When this method was invented, few people paid attention to it at the junction of the 70s and 80s. A decade later, when programming was no longer the concern of IBM scientists and engineers, and was already gaining an avalanche of mass character, the method was rediscovered, researched and popularized in 1991 by Stephen Lacy and Richard Box.
That's actually all that I wanted to tell you about bubble sorting and its ilk.
- Notes
* abbreviation ( Ukrainian ) - improvement
** Sortuvannya bulbashka ( Ukrainian ) - Sorting with a bubble
*** Sortuvannya rowing ( Ukrainian ) - Sorting comb
Only registered users can participate in the survey. Please come in.
What algorithms from this article did you already know?
- 57.1% Stupid Sort 772
- 91.2% Bubble Sort 1234
- 39.7% Shaker Sort 538
- 15.4% Even-odd sorting 209
- 17% Sorting the comb 231