OpenMP Application Performance Profiling
OpenMP is perhaps the most common model of parallel programming on threads, on systems with shared memory. They appreciate it for high-level parallel constructions (in comparison with programming system threads) and support by different compiler manufacturers. But this post is not about the OpenMP standard itself, there are a lot of materials about it on the network.
Parallelizing computations on OpenMP for the sake of performance, about which, in fact, the article. More specifically, about measuring performance with Intel VTune Amplifier XE. Namely, how to get information about:
- Retrieving the profile of an entire OpenMP application
- Profile of selected parallel OpenMP regions (CPU time, hot functions, etc.)
- Balancing work within a separate parallel OpenMP region
- Parallel / Serial Balance
- Granularity level of parallel tasks
- Synchronization, latency, and control transfers between threads
Launching OpenMP Application Profiling
To profile an OpenMP program, you will need VTune Amplifier XE 2013 Update 4 or later. An application is better to build Composer XE 2013 Update 2 or later. Analysis of older OpenMP implementations from Intel or from other manufacturers (GCC and Microsoft OpenMP) is also possible, but less useful information will be collected, because VTune Amplifier XE will not be able to recognize their parallel regions.
All steps described in this article are valid for Windows and Linux. The above examples were tested on Linux.
If you compiler is older than Intel's package Composer XE 2013 SP1, you can set the KMP_FORKJOIN_FRAMES environment variable to 1. This can be done in the VTune Amplifier dialog «User-defined Environment Variables» in the project properties, well or manually:
#
export KMP_FORKJOIN_FRAMES=1To get complete information about source files with parallel regions, compile with the -parallel-source-info = 2 option. For my examples, I used this compilation line:
#
icc -openmp -O3 -g -parallel-source-info=2 omptest.cpp work.cpp -o omptestEverything else does not differ from the analysis of a regular application: we launch VTune Amplifier, create a project, point out our application and start profiling:
Introducing OpenMP Parallel Regions
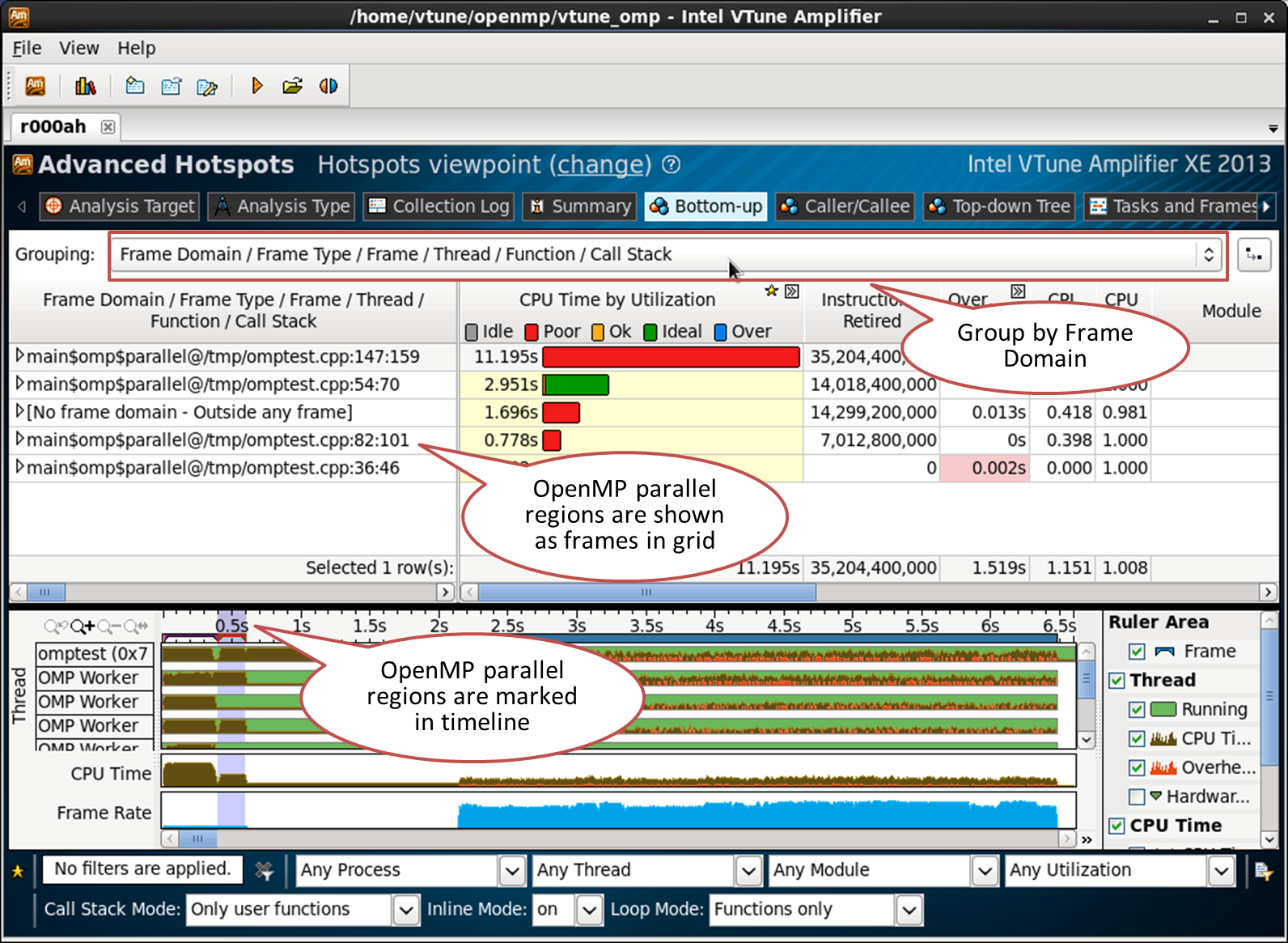
OpenMP parallel regions are represented in VTune Amplifier XE as frame domains. Frames are a sequence of non-overlapping run times of an application. Those. it is possible to break the entire program run time into stages: for example, stage 1 (initialization), stage 2 (work), stage 3 (completion). These stages can be represented by three frames. Frames are often referred to in graphical applications - the idea is the same, but the concept of a frame is wider in VTune Amplifier. Frames are global and not tied to specific threads.
Each parallel OpenMP region is shown as a separate frame domain. It is identified by the source file and line numbers. A domain frame denotes a region in the source code. Every challenge in this region is a frame. Frame - the period from the point of separation (or start) of the threads (fork) to the point of their reunion (join). The number of frames is not related to the number of threads and the size of tasks.
The pseudo code below contains two parallel constructs of OpenMP, two regions. Each of them will be recognized as a domain frame in the VTune Amplifier XE profile, so there will be two domain frames:
intmain(){
#pragma omp parallel for // frame domain #1, frame count: 1for (int i=0; i < NUM_ITERATIONS; i++)
{
do_work();
}
for (int j=0; j<4; j++)
{
#pragma omp parallel for // frame domain #2, frame count: 4for (int i=0; i < NUM_ITERATIONS; i++)
{
do_work();
}
}
}The first domain frame is called only once. Therefore, frame domain # 1 will have only 1 frame, even if the body of the parallel loop is executed immediately by 16 threads. The second parallel region (frame domain # 2) is launched from the loop sequentially 4 times. For each iteration, a parallel construct is invoked, with corresponding starts and terminations of the threads. Therefore, frame domain # 2 will have 4 frames in the VTune Amplifier XE profile.
Parallel regions are recognized if the program uses the Intel OpenMP runtime. To see them, as a result of VTune Amplifier XE, switch to the Bottom-up tab and select the grouping by “Frame Domain / Frame Type ...”:
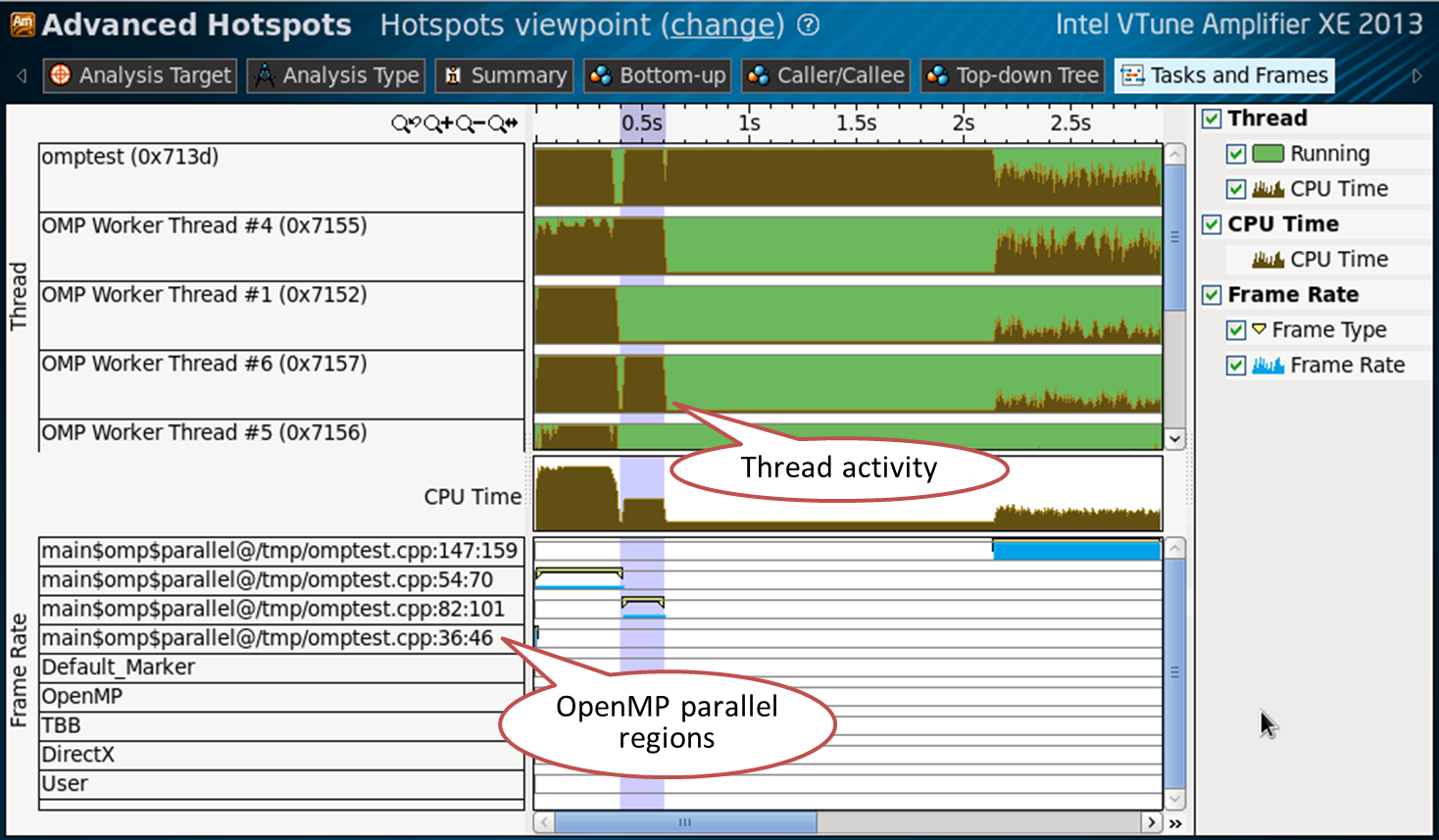
Parallel OpenMP regions and their corresponding flow activity can also be seen in the Tasks and Frames tab:
Sequential region
All the time, the CPU spent outside parallel regions is assembled into a frame domain called “[No frame domain - Outside any frame]”. This allows you to evaluate the sequential part of your code:

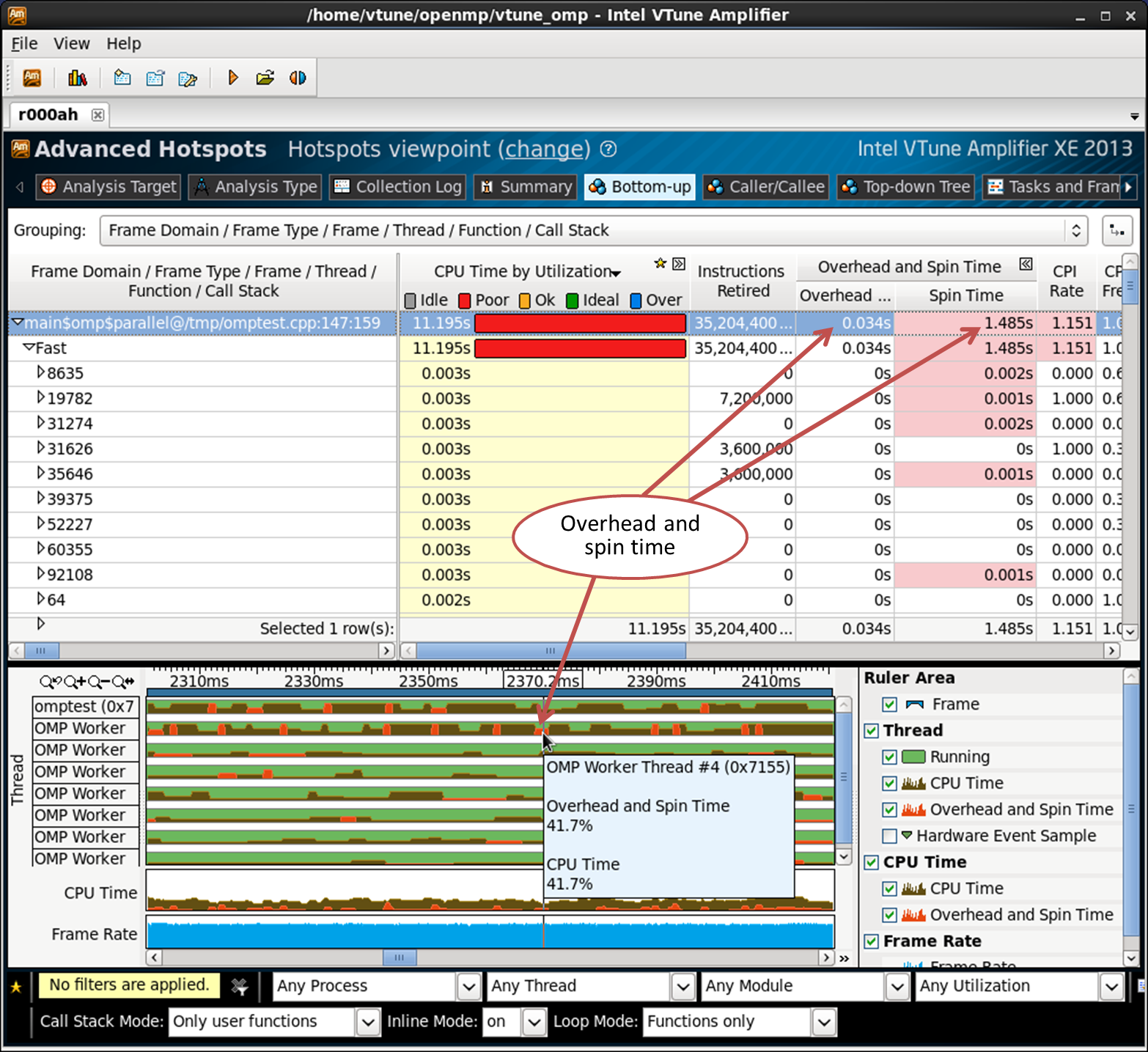
Overhead and active waiting (overhead and spin time)
OpenMP overhead time is the time spent executing internal runtime procedures related to thread management, work distribution, scheduling, synchronization, etc. This time spent not on useful calculations, but on the internal functions of the library. Active Spin Time — The time that the CPU has been running. This can happen, for example, if the synchronization object makes a poll call, instead of going into the idle state, it will spin while it waits. OpenMP streams can also spin this way, for example, on the synchronization barrier.
Overhead and active waiting are caught by known function names and call sequences that spend CPU time. Some internal OpenMP functions control threads, tasks, etc., so the time spent in them is related to overhead. The active waiting time is also determined by the functions that implement the “torsion”.
Overhead and active waiting are defined for Intel OpenMP, GCC and Microsoft OpenMP runtimes, Intel Threading Building Blocks and Intel Cilk Plus.
Scenario 1: Perfectly balanced parallel region
In my simple example, the parallel region in omptest.cpp on line 54 is a good case. Look at the Bottom-up tab, grouped by “Frame Domain / Frame Type / Frame / Thread / Function / Call Stack”:
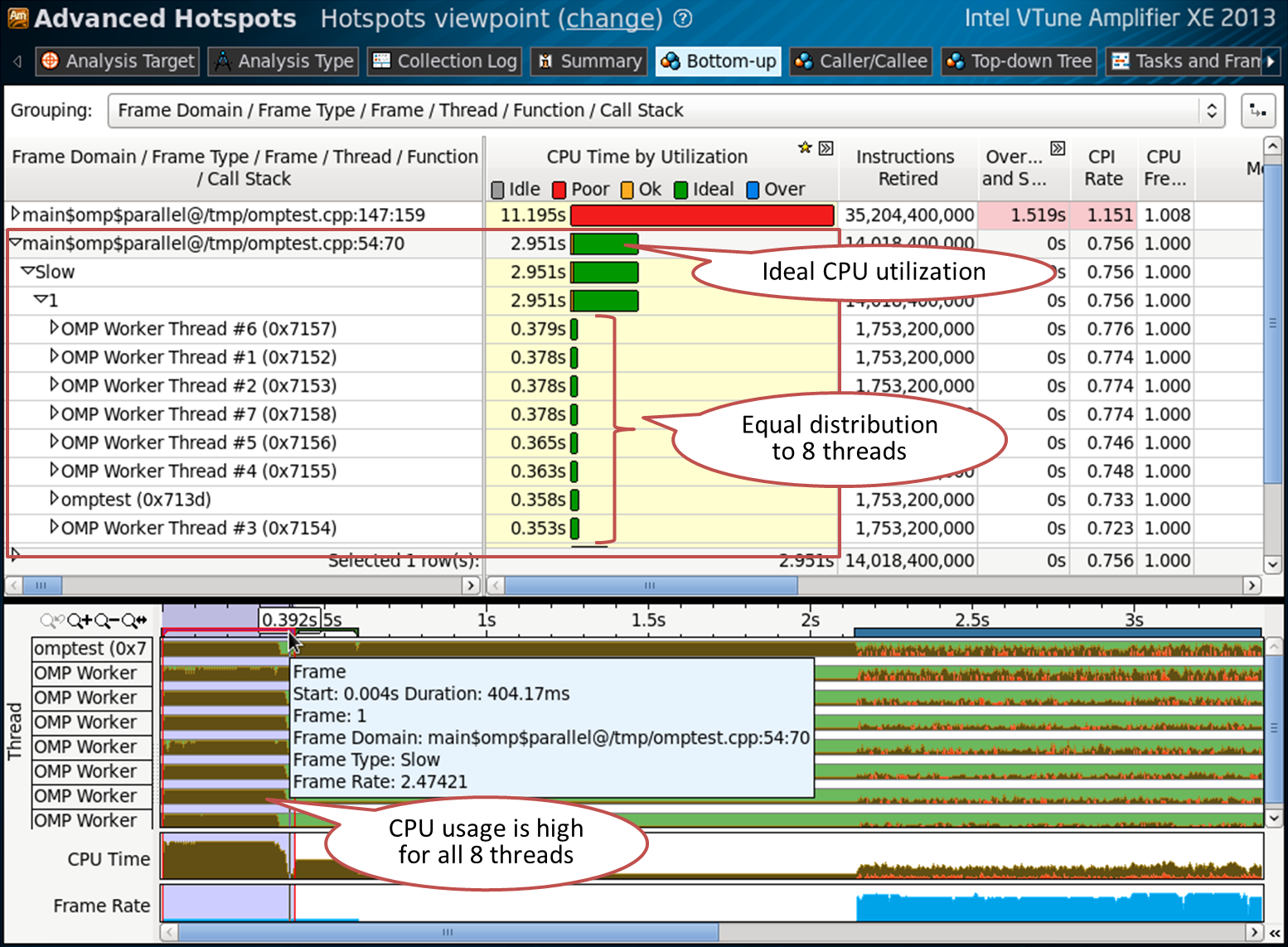
The domain frame contains only one frame, which means that the parallel region was called only once. Opening the details in the table shows 8 threads. This is good for a 4-core Hyper Threading machine on which the test was conducted. The CPU is well loaded (green color of the CPU time bar), all 8 threads are busy in this region and perform almost the same amount of work. This parallel region is marked on the timeline, which also shows high CPU utilization for all eight threads. This does not mean that everything is perfect - for example, there may be cache misses or insufficient use of SIMD instructions. But no problems with OpenMP streams and work balance were found.
The code from the example on line 54:
#pragma omp parallel for schedule(static,1) // line 54for (intindex = 0 ; index < oloops ; index++)
{
double *a, *b, *c, *at ;
int ick ;
a = ga + index*84 ;
c = gc + index*84 ;
fillmat (a) ;
ick = work (a, c,gmask) ;
if (ick > 0)
{
printf("error ick failed\n") ;
exit(1) ;
}
}Scenario 2: Unbalanced Parallel Region
The region on line 82 is not so balanced. It uses only 4 threads out of 8 available, the remaining 4 are waiting. This is also reflected in the processor load level (red color):
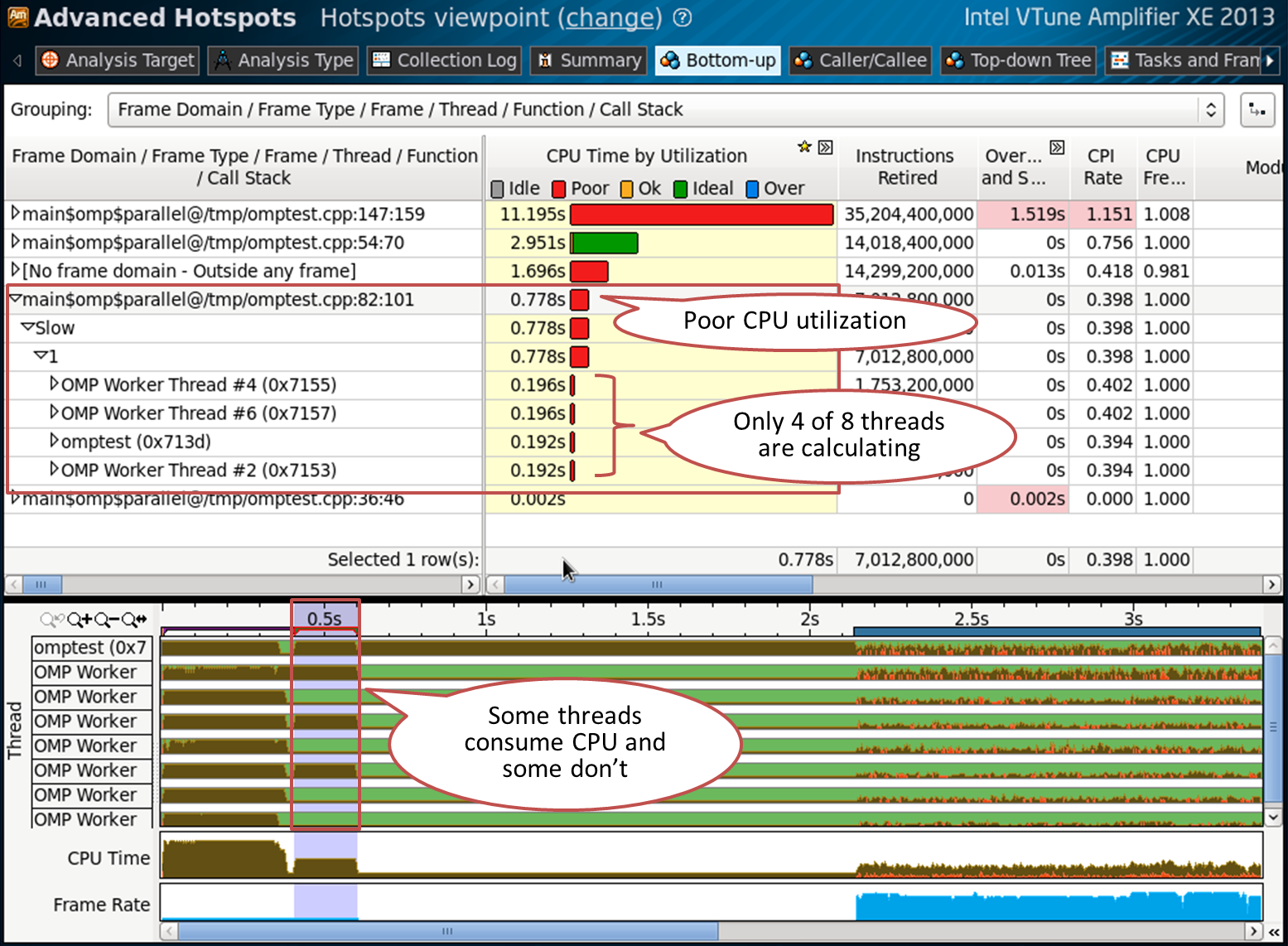
Code on line 82 (we just turned off every second iteration):
#pragma omp parallel for schedule(static,1) // line 82for (intindex = 0 ; index < oloops ; index++)
{
double *a, *b, *c, *at ;
int ick ;
if (index%2 == 0)
{
a = ga + index*84 ;
c = gc + index*84 ;
fillmat (a) ;
ick = work (a, c, gmask) ;
if (ick > 0)
{
printf("error ick failed\n") ;
exit(1) ;
}
}
}Scenario 3: Granularity Issues
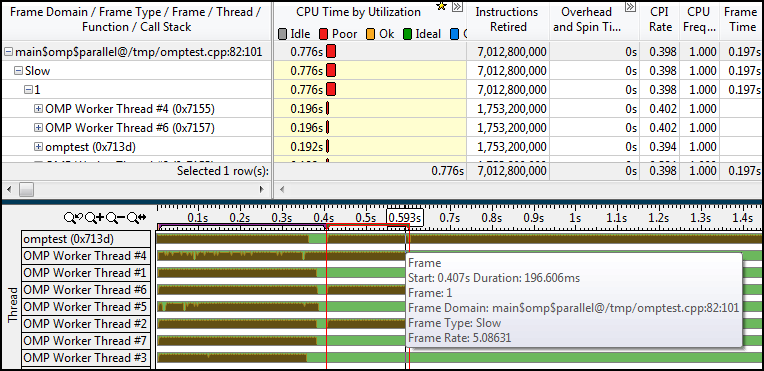
The previous examples had one frame domain and one frame. The region on line 147 contains many frames:
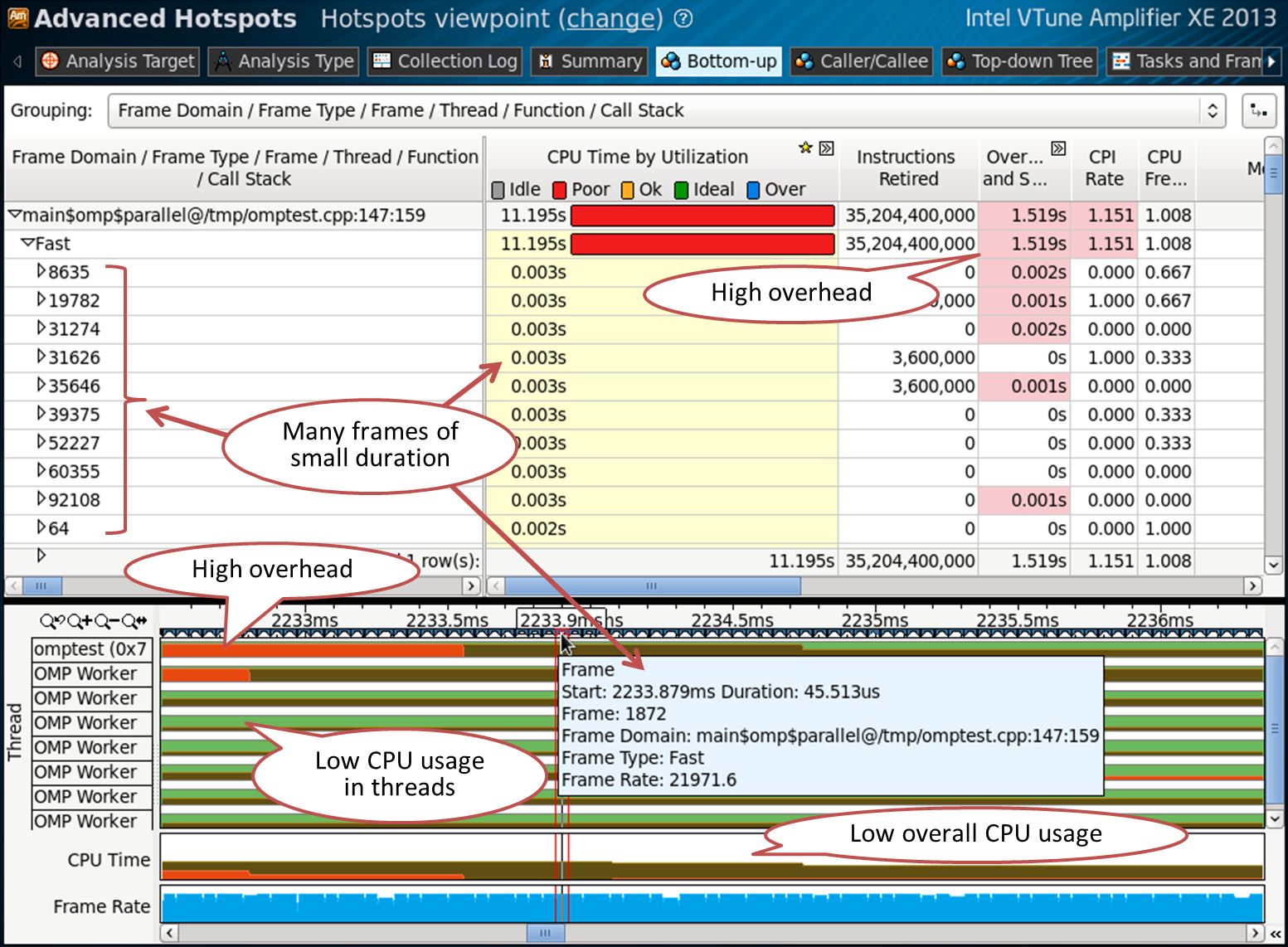
This means that the parallel region has been called multiple times. The CPU time of each frame is very short - this can also be seen in the pop-up window when you hover over the frame in the timeline. This suggests that the granularity is too high, in the sense that we too often run very short parallel OpenMP regions. From this we get a lot of overhead and low CPU utilization.
Code on line 147:
for (q = 0 ; q < LOOPS ; q++)
{
#pragma omp parallel for schedule(static,1) firstprivate(tcorrect) lastprivate(tcorrect) // line147for (intindex = 0 ; index < oloops ; index++)
{
double *la, *lc;
int lq,lmask ;
la = ga + index*84 ;
lc = gc + index*84 ;
lq = q ;
lmask = gmask ;
ick = work1(ga, gc, lq,lmask) ;
if (ick == VLEN) tcorrect++ ;
}
}Scenario 4: Sync Objects and Timeouts
Waiting on a synchronization object can be a serious performance bottleneck. For a complete picture of the synchronizations and expectations in your application, collect the “Locks and Waits” analysis. Before starting, enable the “Analyze user tasks” and “Analyze Intel runtimes and user synchronization” checkboxes in the settings of the new analysis.
The Bottom-up panel will show you a list of synchronization objects sorted by timeout:
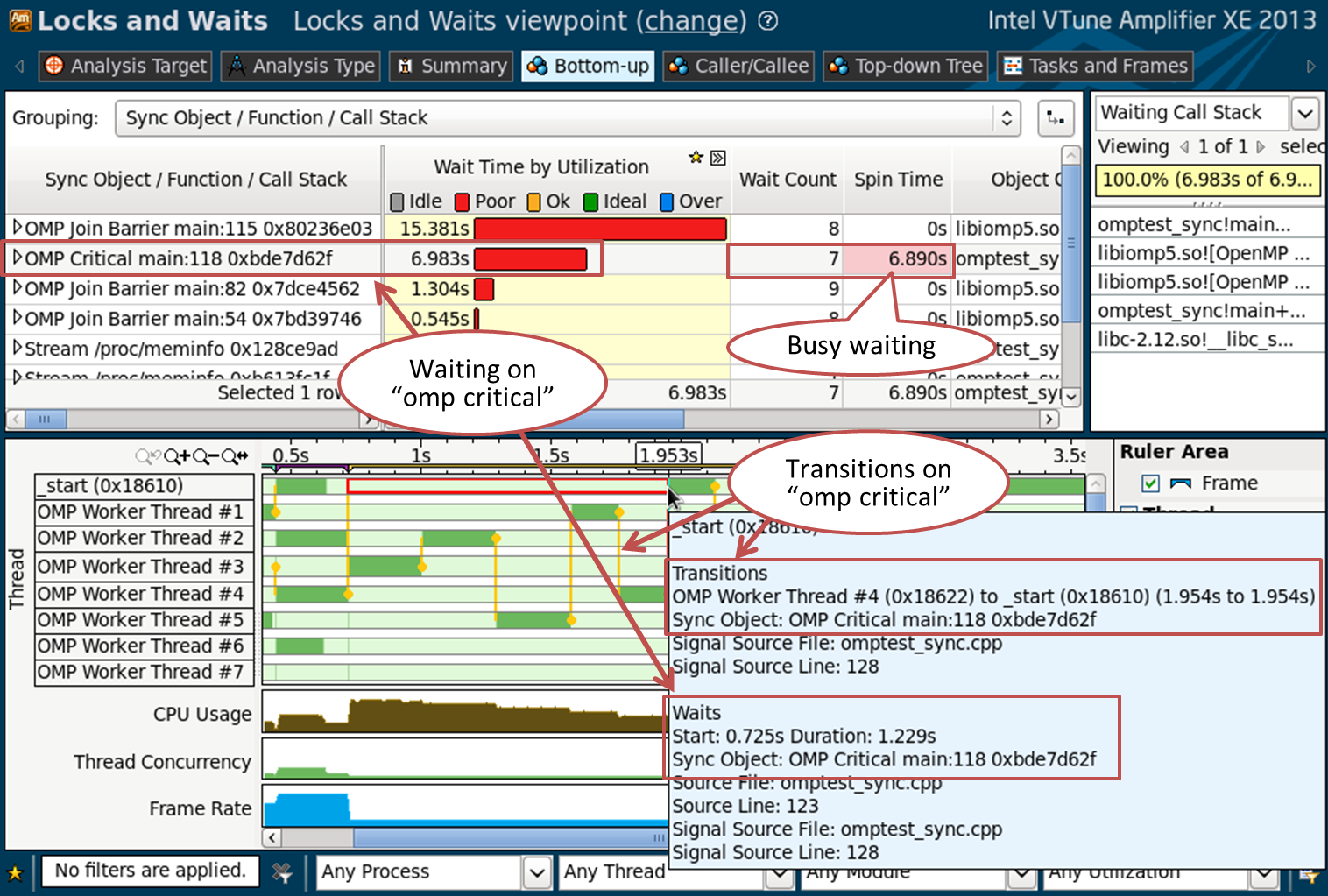
VTune Amplifier XE can recognize OpenMP synchronization primitives, such as the omp critical construct, or the synchronization barriers used inside the OpenMP runtime. You can see how much time is spent waiting and how it is distributed: many short duration expectations, or several long expectations. VTune Amplifier XE indicates whether the thread was waiting actively (spin waiting), or really went into a standby state. The timeline provides a picture of transitions - vertical yellow lines. From them you can understand what flows intercepted the synchronization object, how often, what kind of object it was, how long they waited, etc.
Code on line 118:
#pragma omp parallel for schedule(static,1)
for (int index = 0; index < oloops ; index++)
{
#pragma omp critical (my_sync) // line 118
{
double *a, *b, *c, *at ;
int ick ;
a = ga + index*84 ;
c = gc + index*84 ;
fillmat (a) ;
ick = work (a, c,gmask) ;
if (ick > 0)
{
printf("error ick failed\n") ;
exit(1) ;
}
}
}Summary
Intel VTune Amplifier XE gives you the opportunity to look deep inside the OpenMP application. You can evaluate the balance of serial and parallel code, and how the program behaves in each parallel region. Intel VTune Amplifier XE can help you find problems with load balancing between OpenMP streams, granularity issues, estimate overhead and understand the timing pattern. Linking detailed statistics on processor usage to a specific OpenMP region will allow you to better understand the behavior of your application. You can get the most detailed information using the Intel OpenMP runtime, but profiling of other implementations is also possible (GCC and Microsoft OpenMP).