Automation against chaos

The modern development of IT technology has allowed to curb huge data streams.
The business has a variety of tools: CRM, ERP, BPM, accounting systems, or at most simply Excel and Word.
Companies are also different. Some consist of many separate branches. In this case, the business has the problem of data synchronization in the zoo IT systems. Moreover, the branches differ vendors or software versions. And frequent changes in reporting requirements from the management company trigger bouts of uncontrolled “joy” in the field.
This story is about a project in which I happened to face the chaos that needed to be systematized and automated. A modest budget and tight deadlines limited the use of most industrial solutions, but opened up scope for creativity.
Universal format
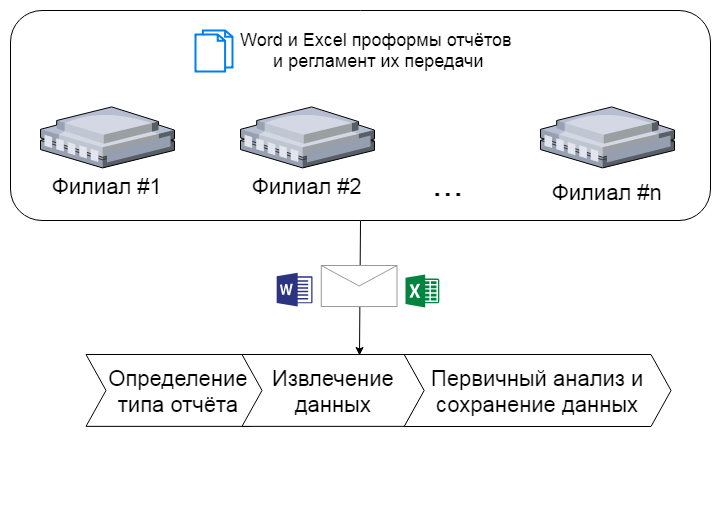
The customer set the task of collecting data for reports from all branches of the company. To understand the scale of a disaster, there are dozens of systems, among which both samopisnye and monsters like SAP, and, of course, 1C - where without him.
In one report, data from: accounting, repairmen, PR managers, MES, meteorologists could cross.
Prior to the start of the project, the main part of the data was sent to the parent company via email in the form of Word / Excel attachments. Then the process resembled the sunset manually: the data were processed by specially trained people and entered into a couple of systems. The result of the work were dozens of reports, on the basis of which management decisions were taken.
On the choice of the approach, we pushed the format of the files being sent, namely xlsx / docx. Even the “ancient” systems in the branches didn’t support the unloading of data into these formats, well, or in extreme cases, copy-paste was not canceled.
Our plan was stubborn:
- we describe the structure of each report and the rules for its transmission;
- We lower the requirements for setting up systems for sending documents by email in accordance with the regulations. Where there are no systems - sending, as before, by hands;
- develop a program that:
- selects certain documents from incoming mail;
- extracts data from them;
- writes the extracted data to the database, as well as “beats the hands” of the violators of the regulations.
Implementation
Organizational matters
At the stage of collecting and formalizing the requirements for the structure and regulations of data transfer, it turned out that there was no description of the structure of the reports, at all. Everything was stored in the heads of some of the employees and was transmitted as word-of-mouth by Russian folk tales. But the real problems started later - when setting up the exchange of data.
Problem one
The difference in the structure of documents from the reference and data quality. The reports sometimes did not agree on the amounts, the columns were mixed up or had incorrect names. The problem was mainly observed in the branches, where the data were driven in manually.
The solution is the introduction of a three-step test:
- Creating Excel reference documents with a rigid structure, means of Excel itself. In such documents, only data entry cells were available. On which checks were additionally superimposed: type, convergence of amounts, etc.
- Checks when extracting data from the report. For example, comparison of the current date and date in the paragraph of the Word document or arithmetic checks for data from an Excel document (if they cannot be specified in the document itself).
- In-depth data analysis after collection. For example, the detection of significant deviations in key indicators in comparison with previous periods.
Problem two
Systematic violation of the data transfer schedule or unscrupulous attempts at sabotage: “We never even sent data to anyone, but here you are with yours ...”, “Yes, I sent everything on time, this ping is probably bad.”
The solution is feedback. The system automatically notifies the responsible persons in the branch, in case of violation of the schedule. Later, the feedback subsystem was screwed to the input data quality control system and to the final reports generation system, so that the branch immediately received a summary of its data and comparison with its “neighbors”.
Subsystems developed
- The document types configurator with which you can quickly describe:
- signs to identify the document;
- transfer regulations;
- data extraction algorithm;
- other attributes like a code path that checks and stores data.
- Recipient of the mail, moving attachments to an isolated storage (sandbox) and storing the accompanying information about the letter;
- Attachment parser, which defines document types and extracts data from them.

Configurator
Historically, all documents with data come to the general mail, where it is full of other important and not very letters. Signs are needed by which the necessary documents will be determined. The name of the document or the text in the email body is all unreliable and inconvenient for the sender. Therefore, it was decided that the report will be determined only by the content of the document. In addition, you need to unambiguously determine what kind of report contains a document.
By brainstorming, the horse-radish thought up how many signs to identify the document: the text color in the cell, the font and so on. But the most correct was the sign of the presence of a substring in a certain cell “slot” or an array of cells for Excel and a paragraph or heading for Word. For the “slot,” simple formal logic was added: “equal”, “unequal”, “greater”, “less”, etc. Example for Excel: in the A2-E4 range, the cell text should be equal to “Daily equipment load summary”.

Similarly, the document area is set up in which you need to search for the beginning and end of the data (approx. End search conditions: 2 blank lines in a row).

A list of other useful settings: a list of allowed senders, the type of document (Excel / Word) and the path to export data.
At the output we get a JSON structure (template) describing the report.
Mail recipient
The mail reader, which places all documents from attachments in the sandbox, saves the attributes of the letter and puts the documents in the task queue for parsing.
There are 2 security questions here:
- What if the data is sent to another branch?
- What if data is sent by intruders?
The first question is solved by checking the email address of the sending branch and the branch specified in the report body.
The second is using SPF .
Attachment parser
Almost all libraries for parsing Word and Excel have serious limitations on the supported versions, so first you need to convert the document. Libre Office solves this problem on the top five.
After conversion:
- we remove the array of templates according to basic features from the configurator (Word / Excel, sender ...);
- we run the document with the remaining templates;
- If the template is found, we retrieve the data and transfer it to the repository.
Total
We made it!
After two months of painstaking work, the head office began to regularly receive data for reports from all branches. Moreover, the quality and completeness of the data was unprecedentedly different from what it was before, and the released human resources paid for the project costs by the end of the year.
For ourselves, we learned that integration is not always painful and highlighted the main aspects of success:
- we did not climb inside the systems in the branches;
- formalized and approved a single structure of reports and the rules for their transfer;
- created output formats for all systems that are generally available in the form of Excel and Word documents;
- Chose the most common method of data delivery - email.
And two main disadvantages:
- Low speed data delivery.
- The size of the data packet should not exceed the size of a regular email attachment.