The basics of data analysis in python using pandas + sklearn
Good afternoon, dear readers. In today's post, I will continue my series of articles on data analysis in python using the Pandas module and describe one of the options for using this module in conjunction with the scikit-learn machine learning module . The work of this bundle will be shown on the example of the task of rescued from the Titanic. This task is very popular among people just starting to engage in data analysis and machine learning .
So the essence of the task is to use the machine learning methods to build a model that would predict whether a person would be saved or not. 2 files are attached to the task:
As it was written above, for the analysis you will need the Pandas and scikit-learn modules. With Pandas, we’ll do an initial analysis of the data, and sklearn will help you calculate the predictive model. So, for starters, load the necessary modules:
In addition, explanations are given for some fields:
> So, the task is formed and we can begin to solve it.
First, load the test sample and see how it looks:
It can be assumed that the higher the social status, the greater the likelihood of salvation. Let's check this by looking at the number of survivors and drowned depending on the classes. To do this, build the following summary:
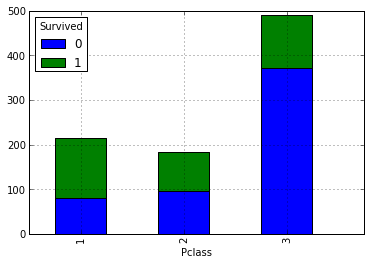
Our above assumption is that the higher the passengers' social status, the higher their probability of salvation. Now let's take a look at how the number of relatives affects the fact of salvation:
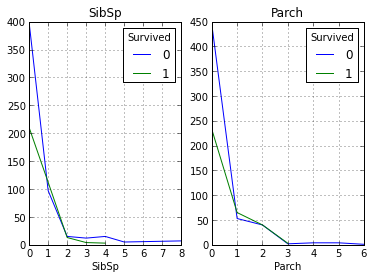
As can be seen from the graphs, our assumption was again confirmed, and of the people with more than 1 relatives, not many were saved.
Now we will discuss for data, which are the numbers of cabins. Theoretically, there may not be data on user cabins, so let's look at how much this field is filled in:
As a result, a total of 204 entries and 890 were filled, on the basis of this we can conclude that this field can be omitted during analysis.
The next field, which we will analyze field with age ( of Age ). Let's see how much it is filled:
This field is almost complete (714 non-empty entries), but there are empty values that are not defined. Let's give it a value equal to the median by age of the entire sample. This step is needed to more accurately build the model:
We have to deal with the fields Ticket , Embarked , Fare , Name . Let's look at the Embarked field, where the port of embarkation is located and check if there are any passengers whose port is not specified:
So we had 2 such passengers. Let's assign these passengers the port in which the village has the most people:
Well, we figured out one more field and now we still have fields with the name of the passenger, ticket number and ticket price.
In fact, we need only the price ( Fare ) from these three fields , because to some extent, we determine the ranking inside the classes of the Pclass field . That is, for example, people within the middle class can be divided into those who are closer to the first (upper) class, and who are closer to the third (lower). We’ll check this field for empty values and if any, replace the price with the median of the price from all samples:
In our case, there are no empty entries.
In turn, the ticket number and name of the passenger will not help us, since this is just reference information. The only reason they can come in handy is to determine which of the passengers are potentially relatives, but since people who have relatives have hardly survived (as shown above), these data can be neglected.
Now, after deleting all the unnecessary fields, our set looks like this:
A preliminary analysis of the data is completed, and according to its results we got a certain sample, which contains several fields and it would seem that we could proceed to the construction of the model, if not one “but”: our data contains not only numerical, but also textual data.
Therefore, before building a model, you need to encode all of our text values.
You can do this manually, or you can use the sklearn.preprocessing module . Let's use the second option.
You can encode a list with fixed values using the LabelEncoder () object. The essence of this function is that at the input it receives a list of values that must be encoded, at the output there is a list of classes whose indices are the codes of the elements of the list supplied to the input.
As a result, our initial data will look like this:
Now we need to write code to bring the verification file to the form we need. To do this, you can simply copy the pieces of code that were above (or just write a function to process the input file):
The code described above performs almost the same operations that we did with the training sample. The difference is that a line has been added to process the Fare field if it is suddenly not filled.
Well, the data is processed and you can start building the model, but first you need to decide how we will check the accuracy of the resulting model. For this test, we will use the sliding control and ROC-curves . We will perform the verification on the training sample, after which we apply it to the test one.
So, let's look at a few machine learning algorithms:
Download the libraries we need:
To begin with, it is necessary to divide our training sample into the indicator that we are investigating, and its defining signs:
Now our training set looks like this:
Теперь разобьем показатели полученные ранее на 2 подвыборки(обучающую и тестовую) для расчет ROC кривых (для скользящего контроля этого делать не надо, т.к. функция проверки это делает сама. В этом нам поможет функция train_test_split модуля cross_validation:
В качестве параметров ей передается:
На выходе функция выдает 4 массива:
Далее представлены перечисленные методы с наилучшими параметрами подобранные опытным путем:
Now we will check the obtained models using the sliding control. To do this, we need to function vocpolzovatsya cross_val_score
Let's look at the graph of the average cross-validation test scores for each model:
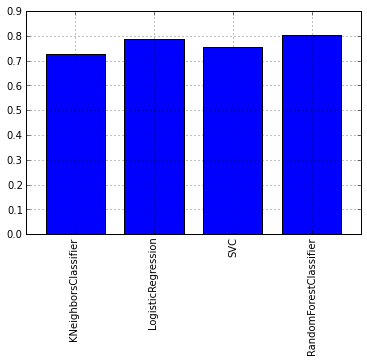
As you can see from the graph, the RandomForest algorithm showed itself best. Now let's take a look at the graphs of ROC-curves to assess the accuracy of the classifier. We will draw graphs using the matplotlib library :
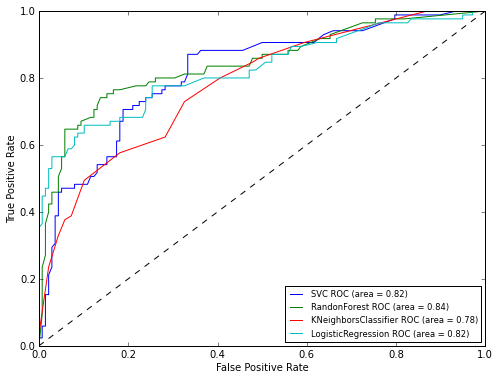
As can be seen from the results of the ROC analysis, the best result was again shown by RandomForest. Now it remains only to apply our model to the test sample:
In this article I tried to show how you can use the pandas package in conjunction with the sklearn machine learning package . The resulting model with a submission on Kaggle showed an accuracy of 0.77033. In the article, I wanted to show more precisely the work with the toolkit and the progress of the study, rather than the construction of a detailed algorithm, as for example in this series of articles.
Formulation of the problem
So the essence of the task is to use the machine learning methods to build a model that would predict whether a person would be saved or not. 2 files are attached to the task:
- train.csv - data set on the basis of which the model will be built ( training set )
- test.csv - data set for model verification
As it was written above, for the analysis you will need the Pandas and scikit-learn modules. With Pandas, we’ll do an initial analysis of the data, and sklearn will help you calculate the predictive model. So, for starters, load the necessary modules:
In addition, explanations are given for some fields:
- PassengerId - passenger ID
- Survival - the field in which the person is saved (1) or not (0)
- Pclass - contains socio-economic status:
- tall
- average
- low
- Name - passenger name
- Sex - passenger gender
- Age - age
- SibSp - contains information on the number of relatives of the 2nd order (husband, wife, brothers, sets)
- Parch - contains information about the number of relatives on board the 1st order (mother, father, children)
- Ticket - ticket number
- Fare - ticket price
- Cabin - cabin
- Embarked - port of landing
- C - Cherbourg
- Q - Queenstown
- S - Southampton
Input Analysis
> So, the task is formed and we can begin to solve it.
First, load the test sample and see how it looks:
from pandas import read_csv, DataFrame, Series
data = read_csv('Kaggle_Titanic/Data/train.csv')| PassengerId | Survived | Pclass | Name | Sex | Age | Sibsp | Parch | Ticket | Far | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen harris | male | 22 | 1 | 0 | A / 5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th ... | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON / O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.0500 | NaN | S |
It can be assumed that the higher the social status, the greater the likelihood of salvation. Let's check this by looking at the number of survivors and drowned depending on the classes. To do this, build the following summary:
data.pivot_table('PassengerId', 'Pclass', 'Survived', 'count').plot(kind='bar', stacked=True)Our above assumption is that the higher the passengers' social status, the higher their probability of salvation. Now let's take a look at how the number of relatives affects the fact of salvation:
fig, axes = plt.subplots(ncols=2)
data.pivot_table('PassengerId', ['SibSp'], 'Survived', 'count').plot(ax=axes[0], title='SibSp')
data.pivot_table('PassengerId', ['Parch'], 'Survived', 'count').plot(ax=axes[1], title='Parch')
As can be seen from the graphs, our assumption was again confirmed, and of the people with more than 1 relatives, not many were saved.
Now we will discuss for data, which are the numbers of cabins. Theoretically, there may not be data on user cabins, so let's look at how much this field is filled in:
data.PassengerId[data.Cabin.notnull()].count()As a result, a total of 204 entries and 890 were filled, on the basis of this we can conclude that this field can be omitted during analysis.
The next field, which we will analyze field with age ( of Age ). Let's see how much it is filled:
data.PassengerId[data.Age.notnull()].count()This field is almost complete (714 non-empty entries), but there are empty values that are not defined. Let's give it a value equal to the median by age of the entire sample. This step is needed to more accurately build the model:
data.Age = data.Age.median()We have to deal with the fields Ticket , Embarked , Fare , Name . Let's look at the Embarked field, where the port of embarkation is located and check if there are any passengers whose port is not specified:
data[data.Embarked.isnull()]| PassengerId | Survived | Pclass | Name | Sex | Age | Sibsp | Parch | Ticket | Far | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 62 | 1 | 1 | Icard, Miss. Amelie | female | 28 | 0 | 0 | 113572 | 80 | B28 | NaN |
| 830 | 1 | 1 | Stone, Mrs. George Nelson (Martha Evelyn) | female | 28 | 0 | 0 | 113572 | 80 | B28 | NaN |
So we had 2 such passengers. Let's assign these passengers the port in which the village has the most people:
MaxPassEmbarked = data.groupby('Embarked').count()['PassengerId']
data.Embarked[data.Embarked.isnull()] = MaxPassEmbarked[MaxPassEmbarked == MaxPassEmbarked.max()].index[0]
Well, we figured out one more field and now we still have fields with the name of the passenger, ticket number and ticket price.
In fact, we need only the price ( Fare ) from these three fields , because to some extent, we determine the ranking inside the classes of the Pclass field . That is, for example, people within the middle class can be divided into those who are closer to the first (upper) class, and who are closer to the third (lower). We’ll check this field for empty values and if any, replace the price with the median of the price from all samples:
data.PassengerId[data.Fare.isnull()]In our case, there are no empty entries.
In turn, the ticket number and name of the passenger will not help us, since this is just reference information. The only reason they can come in handy is to determine which of the passengers are potentially relatives, but since people who have relatives have hardly survived (as shown above), these data can be neglected.
Now, after deleting all the unnecessary fields, our set looks like this:
data = data.drop(['PassengerId','Name','Ticket','Cabin'],axis=1)| Survived | Pclass | Sex | Age | Sibsp | Parch | Far | Embarked |
|---|---|---|---|---|---|---|---|
| 0 | 3 | male | 28 | 1 | 0 | 7.2500 | S |
| 1 | 1 | female | 28 | 1 | 0 | 71.2833 | C |
| 1 | 3 | female | 28 | 0 | 0 | 7.9250 | S |
| 1 | 1 | female | 28 | 1 | 0 | 53.1000 | S |
| 0 | 3 | male | 28 | 0 | 0 | 8.0500 | S |
Input preprocessing
A preliminary analysis of the data is completed, and according to its results we got a certain sample, which contains several fields and it would seem that we could proceed to the construction of the model, if not one “but”: our data contains not only numerical, but also textual data.
Therefore, before building a model, you need to encode all of our text values.
You can do this manually, or you can use the sklearn.preprocessing module . Let's use the second option.
You can encode a list with fixed values using the LabelEncoder () object. The essence of this function is that at the input it receives a list of values that must be encoded, at the output there is a list of classes whose indices are the codes of the elements of the list supplied to the input.
from sklearn.preprocessing import LabelEncoder
label = LabelEncoder()
dicts = {}
label.fit(data.Sex.drop_duplicates()) #задаем список значений для кодирования
dicts['Sex'] = list(label.classes_)
data.Sex = label.transform(data.Sex) #заменяем значения из списка кодами закодированных элементов
label.fit(data.Embarked.drop_duplicates())
dicts['Embarked'] = list(label.classes_)
data.Embarked = label.transform(data.Embarked)As a result, our initial data will look like this:
| Survived | Pclass | Sex | Age | Sibsp | Parch | Far | Embarked |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 1 | 28 | 1 | 0 | 7.2500 | 2 |
| 1 | 1 | 0 | 28 | 1 | 0 | 71.2833 | 0 |
| 1 | 3 | 0 | 28 | 0 | 0 | 7.9250 | 2 |
| 1 | 1 | 0 | 28 | 1 | 0 | 53.1000 | 2 |
| 0 | 3 | 1 | 28 | 0 | 0 | 8.0500 | 2 |
Now we need to write code to bring the verification file to the form we need. To do this, you can simply copy the pieces of code that were above (or just write a function to process the input file):
test = read_csv('Kaggle_Titanic/Data/test.csv')
test.Age[test.Age.isnull()] = test.Age.mean()
test.Fare[test.Fare.isnull()] = test.Fare.median() #заполняем пустые значения средней ценой билета
MaxPassEmbarked = test.groupby('Embarked').count()['PassengerId']
test.Embarked[test.Embarked.isnull()] = MaxPassEmbarked[MaxPassEmbarked == MaxPassEmbarked.max()].index[0]
result = DataFrame(test.PassengerId)
test = test.drop(['Name','Ticket','Cabin','PassengerId'],axis=1)
label.fit(dicts['Sex'])
test.Sex = label.transform(test.Sex)
label.fit(dicts['Embarked'])
test.Embarked = label.transform(test.Embarked)
The code described above performs almost the same operations that we did with the training sample. The difference is that a line has been added to process the Fare field if it is suddenly not filled.
| Pclass | Sex | Age | Sibsp | Parch | Far | Embarked |
|---|---|---|---|---|---|---|
| 3 | 1 | 34.5 | 0 | 0 | 7.8292 | 1 |
| 3 | 0 | 47.0 | 1 | 0 | 7.0000 | 2 |
| 2 | 1 | 62.0 | 0 | 0 | 9.6875 | 1 |
| 3 | 1 | 27.0 | 0 | 0 | 8.6625 | 2 |
| 3 | 0 | 22.0 | 1 | 1 | 12.2875 | 2 |
Construction of classification models and their analysis
Well, the data is processed and you can start building the model, but first you need to decide how we will check the accuracy of the resulting model. For this test, we will use the sliding control and ROC-curves . We will perform the verification on the training sample, after which we apply it to the test one.
So, let's look at a few machine learning algorithms:
Download the libraries we need:
from sklearn import cross_validation, svm
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
import pylab as pl
To begin with, it is necessary to divide our training sample into the indicator that we are investigating, and its defining signs:
target = data.Survived
train = data.drop(['Survived'], axis=1) #из исходных данных убираем Id пассажира и флаг спасся он или нет
kfold = 5 #количество подвыборок для валидации
itog_val = {} #список для записи результатов кросс валидации разных алгоритмов
Now our training set looks like this:
| Pclass | Sex | Age | Sibsp | Parch | Far | Embarked |
|---|---|---|---|---|---|---|
| 3 | 1 | 28 | 1 | 0 | 7.2500 | 2 |
| 1 | 0 | 28 | 1 | 0 | 71.2833 | 0 |
| 3 | 0 | 28 | 0 | 0 | 7.9250 | 2 |
| 1 | 0 | 28 | 1 | 0 | 53.1000 | 2 |
| 3 | 1 | 28 | 0 | 0 | 8.0500 | 2 |
Теперь разобьем показатели полученные ранее на 2 подвыборки(обучающую и тестовую) для расчет ROC кривых (для скользящего контроля этого делать не надо, т.к. функция проверки это делает сама. В этом нам поможет функция train_test_split модуля cross_validation:
ROCtrainTRN, ROCtestTRN, ROCtrainTRG, ROCtestTRG = cross_validation.train_test_split(train, target, test_size=0.25)
В качестве параметров ей передается:
- Массив параметров
- Массив значений показателей
- Соотношение в котором будет разбита обучающая выборка (в нашем случае для тестового набора будет выделена 1/4 часть данных исходной обучающей выборки)
На выходе функция выдает 4 массива:
- Новый обучающий массив параметров
- тестовый массив параметров
- Новый массив показателей
- тестовый массив показателей
Далее представлены перечисленные методы с наилучшими параметрами подобранные опытным путем:
model_rfc = RandomForestClassifier(n_estimators = 70) #в параметре передаем кол-во деревьев
model_knc = KNeighborsClassifier(n_neighbors = 18) #в параметре передаем кол-во соседей
model_lr = LogisticRegression(penalty='l1', tol=0.01)
model_svc = svm.SVC() #по умолчанию kernek='rbf'
Now we will check the obtained models using the sliding control. To do this, we need to function vocpolzovatsya cross_val_score
scores = cross_validation.cross_val_score(model_rfc, train, target, cv = kfold)
itog_val['RandomForestClassifier'] = scores.mean()
scores = cross_validation.cross_val_score(model_knc, train, target, cv = kfold)
itog_val['KNeighborsClassifier'] = scores.mean()
scores = cross_validation.cross_val_score(model_lr, train, target, cv = kfold)
itog_val['LogisticRegression'] = scores.mean()
scores = cross_validation.cross_val_score(model_svc, train, target, cv = kfold)
itog_val['SVC'] = scores.mean()
Let's look at the graph of the average cross-validation test scores for each model:
DataFrame.from_dict(data = itog_val, orient='index').plot(kind='bar', legend=False)
As you can see from the graph, the RandomForest algorithm showed itself best. Now let's take a look at the graphs of ROC-curves to assess the accuracy of the classifier. We will draw graphs using the matplotlib library :
pl.clf()
plt.figure(figsize=(8,6))
#SVC
model_svc.probability = True
probas = model_svc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('SVC', roc_auc))
#RandomForestClassifier
probas = model_rfc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('RandonForest',roc_auc))
#KNeighborsClassifier
probas = model_knc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('KNeighborsClassifier',roc_auc))
#LogisticRegression
probas = model_lr.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('LogisticRegression',roc_auc))
pl.plot([0, 1], [0, 1], 'k--')
pl.xlim([0.0, 1.0])
pl.ylim([0.0, 1.0])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.legend(loc=0, fontsize='small')
pl.show()
As can be seen from the results of the ROC analysis, the best result was again shown by RandomForest. Now it remains only to apply our model to the test sample:
model_rfc.fit(train, target)
result.insert(1,'Survived', model_rfc.predict(test))
result.to_csv('Kaggle_Titanic/Result/test.csv', index=False)
Conclusion
In this article I tried to show how you can use the pandas package in conjunction with the sklearn machine learning package . The resulting model with a submission on Kaggle showed an accuracy of 0.77033. In the article, I wanted to show more precisely the work with the toolkit and the progress of the study, rather than the construction of a detailed algorithm, as for example in this series of articles.